记录菜鸟图片抓取代码
2023-12-23 22:27:54
# -*- conding:utf-8 -*-
import requests
from urllib import parse
import re
import random
import os
import time
class CaiNiaoImageSpider(object):
def __init__(self):
self.url = 'https://www.sucai999.com/pic/cate/{}.html?page={}'
self.headers = {'User-Agent': 'Mozilla/4.0'}
# 获取图片的方法
def get_image(self, url, pathname, page):
res = requests.get(url, headers=self.headers)
res.encoding = 'utf-8'
html = res.text
pattern = re.compile('data-src="(.*?)"', re.S)
image_link_list = pattern.findall(html)
# 参数1:类型路径 参数2:抓取第几页的
directory = 'D:/workspace/images/{}/{}'.format(pathname, page)
if not os.path.exists(directory):
os.makedirs(directory)
# 调用保存的方法
i = 1
for img_link in image_link_list:
filename = '{}/{}.jpg'.format(directory, i)
print(filename, '下载成功')
self.save_image(img_link, filename)
i += 1
def save_image(self, image_link, filename):
html = requests.get(image_link, headers=self.headers).content
with open(filename, 'wb') as f:
f.write(html)
def run(self):
pathname = input("请输入保存路径名称:")
t = input("请输入图片类型编号")
page = input("请输入需要第几页的数据")
url = self.url.format(t, page)
self.get_image(url, pathname, page)
time.sleep(random.randint(2, 3))
if __name__ == '__main__':
start = time.time()
spider = CaiNiaoImageSpider()
spider.run()
end = time.time()
print('下载成功,共耗时:%.2f' % (end - start))
说明:
run方法中 :
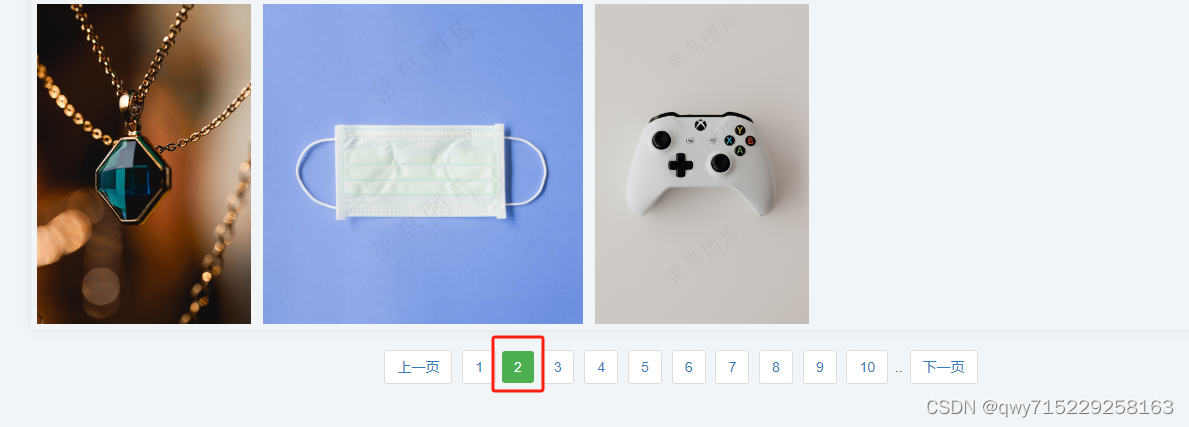
*pathname = input(“请输入保存路径名称:”)*为自定义名称,如下图中的名称:

t = input(“请输入图片类型编号”) 为路径中的编号:

*page = input(“请输入需要第几页的数据”)*为路径中的页面码或底部导航页面:

文章来源:https://blog.csdn.net/qwy715229258163/article/details/135175388
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!