Zookeeper的学习笔记
Zookeeper概念
Zookeeper是一个树形目录服务,简称zk。
Zookeeper是一个分布式的、开源的分布式应用程序的协调服务
Zookeeper提供主要的功能包括:配置管理,分布式锁,集群管理
Zookeeper命令操作
zk数据模型

zk中的每一个节点都被称为:ZNode,每个节点上都会保存自己的数据和节点信息。节点可以拥有子节点,同时也允许少量(1MB)数据存储在该节点之下
节点可以分为四大类:
- PERSISTENT 持久化节点
- EPHEMERAL 临时节点:-e
- PERSISTENT_SEQUENTIAL持久化顺序节点:-s
- EPHEMERAL_SEQUENTIAL临时顺序节点:-es
zk服务端命令
启动zk服务
./zkServer.sh start
zk查看zk服务状态
./zkServer.sh status
停止zk服务
./zkServer.sh stop
重启zk服务
./zkServer.sh restart
zk客户端命令
zkCli.sh连接ZooKeeper服务命令
./zkCli.sh [-server ip地址:2181] (如果是连接本机zk服务,可以省略[]中的内容)
查看zk中的节点
ls /[节点名称]
创建节点方法
create [节点类型] /父节点 [存储信息] (存储信息可以不写)
临时节点创建 -e(服务器关闭,下次连接就会删除)
顺序节点创建 -s
临时顺序节点创建 -es
查看节点存储信息的方法
get /目录
ls -s 是查询结点状态信息
设置节点数据
set /目录 存储信息
删除节点
delete /目录(只能删除空目录)
deleteall /目录(有子结点也可以删除)
在创建节点时,如果没有指定存储数据,那么默认存储的数据是当前服务器的ip地址
Curator介绍
CUrator是Zookeeper的Java客户端库,常见的Zookeeper Java API有三种:
- 原生Java API
- ZkClient
- Curator
相较于原生Java API,Curator使用较为简单,其次,高版本的Curator可以向下兼容zk,但zk无法向下兼容Curator
Curator API常用操作
连接zk服务
一共有两种连接客户端的方式,一种是通过newClient(),一种是通过Builder链式编程创建客户端对象
@Test
public void test() throws Exception {
//指定重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
//第一种连接zk方式
/*
参数1:指定需要连接的zk地址与端口,如果是集群模式,使用,分隔开
参数2:会话超时时间
参数3:连接超时时间
参数4:重试策略
*/
CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.116.131:2181", 60 * 1000, 15 * 1000, retryPolicy);
client.start();
//第二种连接方式,可以指定namespace,其实是指定根目录(此后该客户端对象的curd操作都会在指定的根目录下进行)
CuratorFramework client2 = CuratorFrameworkFactory.builder().connectString("192.168.116.131:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("zmt").build();
client2.start();
}创建节点
创建节点默认创建节点类型为持久化,返回结果为路径,如果不指定节点存储类型,那么默认存储客户端的ip地址
@Test
public void testCreate() throws Exception {
//如果不指定参数2,那么该节点的存储数据为客户端的ip地址
String path = client.create().forPath("/app1","zhangsan".getBytes());
System.out.println(path);
//我们可以通过指定withMode来确定需要创建的节点类型,参数为枚举类
client.create().withMode(CreateMode.EPHEMERAL).forPath("/app2");
//创建多级节点,创建父结点,如果需要
client.create().creatingParentsIfNeeded().forPath("/app3/p1");
}查询节点
我们可以查询节点的存储信息,也可以查询节点的子节点信息,也可以查询节点的状态信息
@Test
public void testGet() throws Exception {
//获取节点存储信息
byte[] data = client.getData().forPath("/app1");
System.out.println(new String(data));
//获取子节点信息
List<String> list = client.getChildren().forPath("/app3");
System.out.println(list);
//获取节点状态信息
Stat status = new Stat();
client.getData().storingStatIn(status).forPath("/app1");
System.out.println(status);
}修改节点
因为可能存在多个客户端连接同一个zookeeper,因此可能会出现修改节点数据时,其他节点也在修改的问题,因此为了避免出现同时修改同一个数据的情况发生,我们应该先获取数据的版本,然后修改数据时根据数据的版本是否一致再决定是否进行修改。
@Test
public void testSetForVersion() throws Exception {
int version;
Stat stat = new Stat();
client.getData().storingStatIn(stat).forPath("/app1");
version = stat.getVersion();
System.out.println(version);
client.setData().withVersion(version).forPath("/app1","lisi".getBytes());
}删除节点
一般我们都要添加guaranteed()方法来避免网络问题产生的删除失败的问题
@Test
public void testDelete() throws Exception {
//删除单个节点
client.delete().forPath("/app1");
//删除多级节点
client.delete().deletingChildrenIfNeeded().forPath("/app3");
//删除失败进行重试,直到删除成功
//比如说网络不好,导致删除失败,可以重复进行删除
client.delete().guaranteed().forPath("/app2");
//删除回调
client.delete().guaranteed().inBackground(new BackgroundCallback() {
//执行回调方法
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("节点被删除");
System.out.println(event);
}
}).forPath("/app4");
}Watch事件监听
zk运行用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,zk服务端会将事件通知到感兴趣的客户端上去,该机制是zk实现分布式协调服务的重要特性。
zk中引入了Watch机制来实现了发布订阅功能,能够让多个订阅者同时监听某一个对象,当一个对象自身状态发生变化时,会通知所有的订阅者
zk提供了3种Watcher:
- NodeCache:只监听一个特定结点
- PathChildrenCache:监控一个Znode的子节点
- TreeCache:前两个结合,监听自己和自己所有子节点
NodeCache的简单使用
@Test
public void testNodeCache() throws Exception {
NodeCache nodeCache = new NodeCache(client, "/app1");
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("节点发生变化");
//获取节点变化后的值
byte[] data = nodeCache.getCurrentData().getData();
System.out.println(new String(data));
}
});
nodeCache.start();
while (true){
}
}PathChildrenCache的简单使用
@Test
public void testChildrenCache() throws Exception {
PathChildrenCache pathChildrenCache = new PathChildrenCache(client, "/", true);
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework curatorFramework, PathChildrenCacheEvent pathChildrenCacheEvent) throws Exception {
System.out.println("节点发生变化");
System.out.println(pathChildrenCacheEvent);
PathChildrenCacheEvent.Type type = pathChildrenCacheEvent.getType();
if (type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)){
//如果是update事件
byte[] data = pathChildrenCacheEvent.getData().getData();
System.out.println(new String(data));
}
}
});
pathChildrenCache.start();
while (true) {
}
}TreeCache的简单使用
@Test
public void testTreeCache() throws Exception {
TreeCache treeCache = new TreeCache(client,"/");
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework curatorFramework, TreeCacheEvent treeCacheEvent) throws Exception {
System.out.println("数据发生变化");
System.out.println(treeCacheEvent);
}
});
treeCache.start();
while (true) {
}
}分布式锁
作用于多个JVM环境,保证多线程安全。
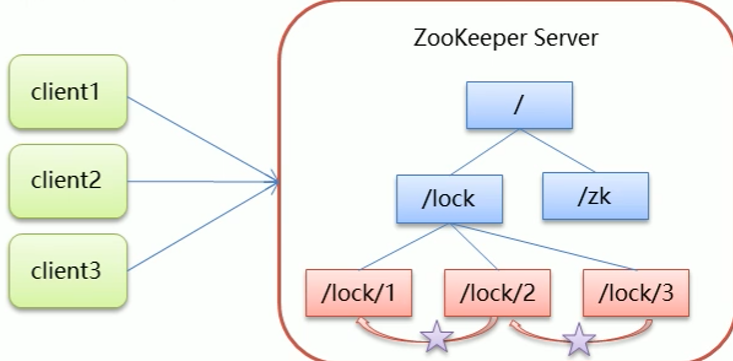
实现分布式锁的原理:当客户端要获取锁时,创建节点,使用完锁,删除该节点
- 客户端获取锁时,在lock节点下创建临时顺序结点
- 然后客户端获取lock下面所有的子节点,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完后把节点删除
- 如果不是最小的结点,说明此时自己还没有获取到锁,此时客户端需要找到比自己小的哪个结点,同时对其注册事件监听器,监听删除事件。
- 如果比自己小一个的结点被删除,则客户端的Watcher会收到通知,此时再次判断自己的结点是否最小,如果不是,重复以上步骤
采取临时节点是为了避免客户端在获取到锁之后处理业务时宕机,当客户端宕机之后,会话结束,临时节点会自动删除
Curator实现分布式锁API
一共有五种方案:
- 分布式排他锁
- 分布式可重入排他锁
- 分布式读写锁
- 将多个锁作为单个实体管理的容器
- 共享信号量
一个简单的售票案例
public class Ticket12306 implements Runnable {
//模拟十张票
private int num = 10;
//分布式可重入式锁
private InterProcessMutex lock;
public Ticket12306() {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 2);
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("192.168.116.131:2181")
.connectionTimeoutMs(60*1000)
.sessionTimeoutMs(15*1000)
.retryPolicy(retryPolicy)
.build();
client.start();
lock = new InterProcessMutex(client, "/lock");
}
@Override
public void run() {
while (true) {
try {
lock.acquire(3, TimeUnit.SECONDS);
if (num > 0) {
Thread.sleep(100);
System.out.println(Thread.currentThread().getName() + "出售了一张票:" + num);
num--;
}
} catch (Exception e) {
System.out.println("我出错了??");
e.printStackTrace();
} finally {
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}测试?
public class TestTicket {
@Test
public void testTicket() throws Exception {
Ticket12306 ticket = new Ticket12306();
Thread t1 = new Thread(ticket, "携程");
Thread t2 = new Thread(ticket, "飞猪");
t1.start();
t2.start();
while(true){
}
}
}实现分布式锁的核心代码如下
new 一个锁类型对象lock
lock.acquire()//获取锁
需要上锁的功能
lock.release();//释放锁
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!