【ModelScope】从入门到进阶

计算机视觉任务
| 任务(Task)中文 | 任务(Task)英文 | 任务说明 |
|---|---|---|
| 单标签图像分类 | image-classification | 对图像中的不同特征根据类别进行区分 |
| 通用图像分割 | image-segmentation | 识别图像主体与图像背景进行分离 |
| 文字检测 | ocr-detection | 将图像中的文字检测出来并返回检测点坐标位置 |
| 人像美肤 | skin-retouching | 对图像中的人像皮肤进行细节美化 |
| 风格迁移 | image-style-transfer | 对图像或视频的色彩风格进行另一种风格转化 |
| 图像翻译 | image-to-image-translation | 将一张图片上的文字翻译成目标语言并生成新的图片 |
| 以图生图 | image-to-image-generation | 根据输入图像生成新的类似图像 |
| 搜索推荐 | image-search | 根据输入图像进行范围匹配 |
| 审核评估 | image-evaluation | 对图像进行解析并自动给出一个评估信息 |
| 视频处理 | video-processing | 对视频信息进行自动运算处理 |
| 视频检测 | video-detection | 对视频信息进行内容解析 |
| 视频分割 | video-segmentation | 对视频信息进行背景和主体分离 |
| 视频生成 | video-generation | 对视频进行解析匹配视频信息进行生成 |
| 视频编辑 | video-editing | 对视频进行解析转化为可编辑状态 |
| 视频表征 | video-embedding | 对视频特征进行多模态匹配 |
| 视频检索 | video-search | 对视频解析根据规则提取部分信息 |
| 视频审核评估 | video-evaluation | 根据规则对视频解析并给出评估结果 |
| 视频文本识别 | video-ocr | 对视频中的文字内容进行识别 |
| 视频到文本 | video-captioning | 将视频中的音频转化为文本信息 |
| 三维重建 | 3d-reconstruction | 对三维模型解析并重新构建 |
| 三维识别 | 3d-recognition | 对三维模型进行识别并进行标注 |
| 三维编辑 | 3d-editing | 对三维模型解析转化为可编辑状态 |
| 驱动交互 | 3d-driven | 对三维模型解析转为为动态效果 |
| 渲染呈现 | 3d-rendering | 对三维模型进行渲染并以图像展示 |
| 虚拟试衣 | virtual-try-on | 给定模特图片和衣服图片,合成模特穿上给定衣服的图片 |
| 文字识别 | ocr-recognition | 将图像中的文字识别出来并返回文本内容 |
| 人脸检测 | face-detection | 对图像中的人脸进行检测并返回人脸坐标位置 |
| 人脸识别 | face-recognition | 对矫正对齐后的人脸图像提取特征向量 |
| 人体检测 | human-detection | 对图像中的人体关键点进行检测并返回关键点标签与坐标位置 |
| 人物交互关系 | human-object-interaction | 对图像中的肢体关键点和物品进行检测和识别对坐标信息进行处理 |
| 人脸生成 | face-image-generation | 对图像中的人脸进行区域位置检测并生成虚拟人脸 |
| 多标签图像分类 | image-multilabel-classification | 解析图像特征支持多个类别区分 |
| 通用目标检测 | image-object-detection | 对输入图像中的较通用物体定位及类别判断 |
| 目标检测-自动驾驶场景(行人、车辆、交通标注等) | image-object-detection-autopilot | 对自动驾驶中的场景进行目标检测,图像中的人、车辆及交通信息等进行实时解析并进行标注(行人、车辆、交通标注) |
| 目标检测-自动驾驶场景(车道线) | image-object-detection-laneline | 对自动驾驶中的场景进行目标检测,图像中的人、车辆及交通信息等进行实时解析并进行标注(车道线) |
| 人像抠图 | portrait-matting | 对输入的图像将人体部分抠出并对背景进行透明化处理 |
| 人像增强 | image-portrait-enhancement | 对图像中的人像主体进行细节增强 |
| 图像超分辨 | image-super-resolution | 对图像进行倍数放大且不丢失画面质量 |
| 图像上色 | image-colorization | 对黑白图像进行区域解析并对其进行类别上色 |
| 图像颜色增强 | image-color-enhancement | 对图像中色彩值进行解析并对其进行规则处理 |
| 图像降噪 | image-denoising | 对图像中的噪点进行处理降低 |
| 人像卡通化 | image-portrait-stylization | 对输入的图像进行卡通化处理,实现风格变化 |
| 图像表征 | image-embedding | 对输入图像特征进行多模态匹配 |
| 直播商品类目识别 | live-category | 实时解析识别直播画面中的商品类别进行信息展示 |
| 行为识别 | action-recognition | 对视频中的动作行为进行识别并返回类型 |
| 短视频内容分类 | video-category | 解析短视频语义进行场景分类 |
| 目标跟踪及重识别 | reid-and-tracking | 可对图片和视频进行目标识别可重复识别 |
| 增强/虚拟现实 | ar-vr | 对vr图像信息进行画面增强 |
| 人体2D关键点 | body-2d-keypoints | 检测图像中人体2D关键点位置 |
| 商品图片特征 | product-retrieval-embedding | 对商品图像进行表征向量提取 |
| 视频场景分割 | movie-scene-segmentation | 输入一段长视频,算法将其分割成不同的场景子视频 |
| 人脸表情识别 | facial-expression-recognition | 识别图像中人脸的表情 |
| 手部2D关键点 | hand-2d-keypoints | 检测图像中手部21点关键点坐标 |
| 视频摘要 | video-summarization | 输入一段长视频,算法找出其中的一些关键片段进行拼接,输出拼接的短的摘要视频 |
| 人脸2D关键点 | face-2d-keypoints | 检测图像中人脸106点关键点坐标和人脸朝向姿态角 |
| 行人重识别 | image-reid-person | 输入包含人的图片,输出图片的特征向量 |
| 3D人体关键点 | body-3d-keypoints | 检测视频中人体姿态的3D关键点坐标 |
| 视频单目标跟踪 | video-single-object-tracking | 输入视频和第一帧目标位置,在所有视频帧中预测该目标位置 |
| 行为检测 | action-detection | 检测视频中发生的行为动作,并给出动作的时空位置 |
| 人群密度估计 | crowd-counting | 输入一张图片,输出图片内有多少人 |
| 卡证检测矫正 | card-detection | 检测输入图片中是否存在卡证,并定位其角点,根据角点将卡证矫正为正视图 |
| 全身关键点检测 | human-wholebody-keypoint | 检测图片中全身关键点坐标,包括人脸关键点,骨骼关键点、脚步关键点和手势关键点,共计133点 |
| 视频目标检测 | video-object-detection | 任务的输入输出类型及数据格式 |
| 语义分割 | semantic-segmentation | 图像显著性,预测图中每个像素的重要程度 |
| 人体美型 | image-body-reshaping | 给定一张人物图像(半身或全身),无需任何额外输入,端到端地实现对人物身体区域(肩部,腰部,腿部等)的自动化美型处理 |
| 目标检测-自动驾驶场景 | image-object-detection-auto | 检测自动驾驶场景图片的目标,包括车辆,行人等 |
| 图像填充 | image-inpainting | 输入一张图片;同时用户根据该图片,自定义地可以进行在线绘制任意形状的mask;最终输出恢复、补全后的图像 |
| 视频修复 | video-inpainting | 对视频中指定的区域和帧范围,进行视频修复 |
| 2D手势语义识别 | hand-static | 对图片中的人手动作的语义进行识别 |
| 人脸情绪识别 | face-emotion | 对图片中的人的情绪进行识别 |
| 人脸人体人手三合一检测 | face-human-hand-detection | 对图片中的人脸、人体、人手进行检测 |
| 通用商品分割 | product-segmentation | 对图片中的商品进行分割 |
| 商品显著性分割 | shop-segmentation | 对商品图像进行显著性分割 |
| 文本指导的图像分割 | text-driven-segmentation | 根据文本对图像进行分割 |
| 动物识别 | animal-recognition | 对图片中的动物主体的进行识别 |
| 视频文本表征 | video-multi-modal-embedding | 输入任意视频和文本pair,输出相应的视频-文本pair特征,和相应得分 |
| 自然语言引导的视频摘要 | language-guided-video-summarization | 输入一段长视频和N句英文描述,算法找出其中和英文描述相关的一些关键片段进行拼接,输出拼接的短的摘要视频 |
| 文本指导的视频目标分割 | referring-video-object-segmentation | 通过用户输入的文本描述(英文)从输入视频中分割出指定的物体,支持一次性输入两个物体描述 |
| 万物识别 | general-recognition | 对图片中的物体主体的进行识别 |
模型加载
加载模型需要两个关键信息:1.模型id 2.模型版本
from modelscope.models import Model
model = Model.from_pretrained('damo/nlp_structbert_word-segmentation_chinese-base', revision='v1.0.1')?如果想下载大本地指定目录的话,使用下面这行代码
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('damo/nlp_structbert_word-segmentation_chinese-base', cache_dir='path/to/local/dir')?模型推理
使用pipeline方法加载模型进行推理
pipeline构造函数
task: 任务名称,必填
model: 模型名称或模型实例,可选。不填时使用该任务默认模型
preprocessor: 预处理器实例,可选。不填时使用模型配置文件中的预处理器
device: 运行设备,可选。值为cpu, cuda, gpu, gpu:X or cuda:X,默认gpu
device_map: 模型参数到运行设备的映射,可选,不可与device同时配置。值为auto, balance, balanced_low_0, sequential或映射dictpipeline调用时参数
batch_size: 批量推理的mini-batch大小,可选。不传时不进行批量推理pipeline基本用法
创建pipeline对象
from modelscope.pipelines import pipeline
word_segmentation = pipeline('word-segmentation')?输入推理数据
input_str = '今天天气不错,适合出去游玩'
print(word_segmentation(input_str))结果
# 输出
{'output': '今天 天气 不错 , 适合 出去 游玩'}输入多条推理数据
?pipeline对象也支持传入多个样本列表输入,返回对应输出列表,每个元素对应输入样本的返回结果。多条文本的推理方式是输入data在pipeline内部用迭代器单条处理后append到同一个返回List中。
inputs = ['今天天气不错,适合出去游玩','这本书很好,建议你看看']
print(word_segmentation(inputs))
# 输出
[{'output': ['今天', '天气', '不错', ',', '适合', '出去', '游玩']}, {'output': ['这', '本', '书', '很', '好', ',', '建议', '你', '看看']}]?模型训练
?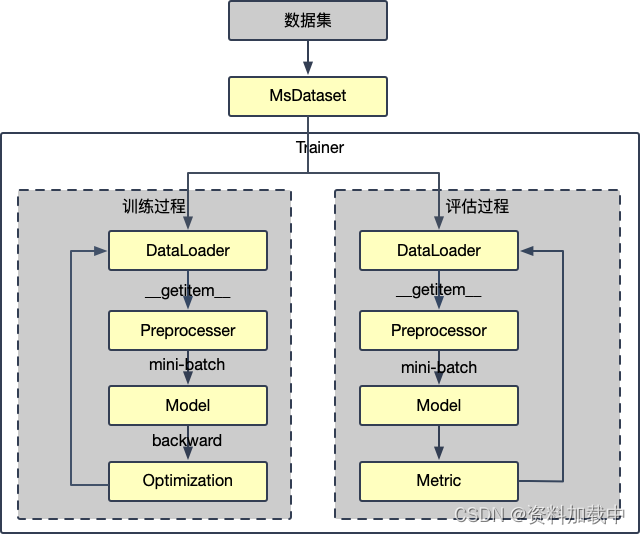
ModelScope的模型训练步骤如下:
- 使用MsDataset加载数据集
- 编写cfg_modify_fn方法,按需修改部分参数
- 构造trainer,开始训练
- 【训练后步骤】进行模型评估
- 【训练后步骤】使用训练后的模型进行推理
?PyTorch模型的训练使用EpochBasedTrainer(及其子类),该类会根据配置文件实例化模型、预处理器、优化器、指标等模块。因此训练模型的重点在于修改出合理的配置,其中用到的各组件都是ModelScope的标准模块。
?trainer的重要构造参数
model: 模型id、模型本地路径或模型实例,必填
cfg_file: 额外的配置文件,可选。如果填写,trainer会使用这个配置进行训练
cfg_modify_fn: 读取配置后trainer调用这个回调方法修改配置项,可选。如果不传就使用原始配置
train_dataset: 训练用的数据集,调用训练时必传
eval_dataset: 评估用的数据集,调用评估时必传
optimizers: 自定义的(optimizer、lr_scheduler),可选,如果传入就不会使用配置文件中的
seed: 随机种子
launcher: 支持使用pytorch/mpi/slurm开启分布式训练
device: 训练用设备。可选,值为cpu, gpu, gpu:0, cuda:0等,默认gpu?模型训练示例
文本分类
# structbert的backbone,该模型没有有效分类器,因此使用前需要finetune(微调)
model_id = 'damo/nlp_structbert_backbone_base_std'使用MsDataset加载数据集
加载官方数据集
from modelscope.msdatasets import MsDataset
# 载入训练数据,数据格式类似于{'sentence1': 'some content here', 'sentence2': 'other content here', 'label': 0}
train_dataset = MsDataset.load('clue', subset_name='afqmc', split='train')
# 载入评估数据
eval_dataset = MsDataset.load('clue', subset_name='afqmc', split='validation')?加载自己的数据集
from modelscope.msdatasets import MsDataset
# 载入训练数据
train_dataset = MsDataset.load('/path/to/my_train_file.txt')
# 载入评估数据
eval_dataset = MsDataset.load('/path/to/my_eval_file.txt')
更多方法参考:数据集使用指南
编写cfg_modify_fn方法,按需修改部分参数
?建议首先查看模型的配置文件,并查看需要额外修改的参数:
from modelscope.utils.hub import read_config
# 上面的model_id
config = read_config(model_id)
print(config.pretty_text)?一般的配置文件中,在训练时需要修改的参数一般分为:
1.预处理器参数
# 使用该模型适配的预处理器sen-sim-tokenizer
cfg.preprocessor.type='sen-sim-tokenizer'
# 预处理器输入的dict中,句子1的key,参考上文加载数据集中的afqmc的格式
cfg.preprocessor.first_sequence = 'sentence1'
# 预处理器输入的dict中,句子2的key
cfg.preprocessor.second_sequence = 'sentence2'
# 预处理器输入的dict中,label的key
cfg.preprocessor.label = 'label'
# 预处理器需要的label和id的mapping
cfg.preprocessor.label2id = {'0': 0, '1': 1}?某些模态中,预处理的参数需要根据数据集修改(比如NLP一般需要修改,而CV一般不需要修改),后续可以查看ModelCard或各任务最佳实践中各任务训练的详细描述。
2.模型参数
# num_labels是该模型分类数
cfg.model.num_labels = 2?3.任务参数
# 修改task类型为'text-classification'
cfg.task = 'text-classification'
# 修改pipeline名称,用于后续推理
cfg.pipeline = {'type': 'text-classification'}?4.训练参数
# 设置训练epoch
cfg.train.max_epochs = 5
# 工作目录
cfg.train.work_dir = '/tmp'
# 设置batch_size
cfg.train.dataloader.batch_size_per_gpu = 32
cfg.evaluation.dataloader.batch_size_per_gpu = 32
# 设置learning rate
cfg.train.optimizer.lr = 2e-5
# 设置LinearLR的total_iters,这项和数据集大小相关
cfg.train.lr_scheduler.total_iters = int(len(train_dataset) / cfg.train.dataloader.batch_size_per_gpu) * cfg.train.max_epochs
# 设置评估metric类
cfg.evaluation.metrics = 'seq-cls-metric'?使用cfg_modify_fn将上述配置修改应用起来:
# 这个方法在trainer读取configuration.json后立即执行,先于构造模型、预处理器等组件
def cfg_modify_fn(cfg):
cfg.preprocessor.type='sen-sim-tokenizer'
cfg.preprocessor.first_sequence = 'sentence1'
cfg.preprocessor.second_sequence = 'sentence2'
cfg.preprocessor.label = 'label'
cfg.preprocessor.label2id = {'0': 0, '1': 1}
cfg.model.num_labels = 2
cfg.task = 'text-classification'
cfg.pipeline = {'type': 'text-classification'}
cfg.train.max_epochs = 5
cfg.train.work_dir = '/tmp'
cfg.train.dataloader.batch_size_per_gpu = 32
cfg.evaluation.dataloader.batch_size_per_gpu = 32
cfg.train.dataloader.workers_per_gpu = 0
cfg.evaluation.dataloader.workers_per_gpu = 0
cfg.train.optimizer.lr = 2e-5
cfg.train.lr_scheduler.total_iters = int(len(train_dataset) / cfg.train.dataloader.batch_size_per_gpu) * cfg.train.max_epochs
cfg.evaluation.metrics = 'seq-cls-metric'
# 注意这里需要返回修改后的cfg
return cfg构造trainer,开始训练
首先,配置训练所需参数:
from modelscope.trainers import build_trainer
# 配置参数
kwargs = dict(
model=model_id,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
cfg_modify_fn=cfg_modify_fn)
trainer = build_trainer(default_args=kwargs)
trainer.train()?需要注意,数据由trainer从dataloader取数据的时候调用预处理器进行处理。
进行模型评估
可选地,在训练后可以进行额外数据集的评估。用户可以单独调用evaluate方法对模型进行评估:
from modelscope.msdatasets import MsDataset
# 载入评估数据
eval_dataset = MsDataset.load('clue', subset_name='afqmc', split='validation')
from modelscope.trainers import build_trainer
# 配置参数
kwargs = dict(
# 由于使用的模型训练后的目录,因此不需要传入cfg_modify_fn
model='/tmp/output',
eval_dataset=eval_dataset)
trainer = build_trainer(default_args=kwargs)
trainer.evaluate()?或者,也可以调用predict方法将预测结果保存下来,以供后续打榜:
from modelscope.msdatasets import MsDataset
import numpy as np
# 载入评估数据
eval_dataset = MsDataset.load('clue', subset_name='afqmc', split='test').to_hf_dataset()
from modelscope.trainers import build_trainer
def cfg_modify_fn(cfg):
# 预处理器在mini-batch中留存冗余字段
cfg.preprocessor.val.keep_original_columns = ['sentence1', 'sentence2']
# 预测数据集没有label,将对应key置空
cfg.preprocessor.val.label = None
return cfg
kwargs = dict(
model='damo/nlp_structbert_sentence-similarity_chinese-tiny',
work_dir='/tmp',
cfg_modify_fn=cfg_modify_fn,
# remove_unused_data会将上述keep_original_columns的列转为attributes
remove_unused_data=True)
trainer = build_trainer(default_args=kwargs)
def saving_fn(inputs, outputs):
with open(f'/tmp/predicts.txt', 'a') as f:
# 通过attribute取冗余值
sentence1 = inputs.sentence1
sentence2 = inputs.sentence2
predictions = np.argmax(outputs['logits'].cpu().numpy(), axis=1)
for sent1, sent2, pred in zip(sentence1, sentence2, predictions):
f.writelines(f'{sent1}, {sent2}, {pred}\n')
trainer.predict(predict_datasets=eval_dataset,
saving_fn=saving_fn)使用训练后的模型进行推理
训练完成以后,文件夹中会生成推理用的模型配置,可以直接用于pipeline:
- {work_dir}/output:训练完成后,存储模型配置文件,及最后一个epoch/iter的模型参数(配置中需要指定CheckpointHook)
- {work_dir}/output_best:最佳模型参数时,存储模型配置文件,及最佳的模型参数(配置中需要指定BestCkptSaverHook)
from modelscope.pipelines import pipeline
pipeline_ins = pipeline('text-classification', model='/tmp/output')
pipeline_ins(('这个功能可用吗', '这个功能现在可用吗'))此外,ModelScope也会存储*.pth文件,用于后续继续训练、训练后验证、训练后推理。一般一次存储会存储两个pth文件:
- epoch_*.pth 存储模型的state_dict,output/output_best的bin文件是此文件的硬链接
- epoch_*_trainer_state.pth,存储trainer的state_dict
在继续训练场景时,只需要加载模型的pth文件,trainer的pth文件会被同时读取。
用户也可以手动link某个pth文件到output/output_best,实现使用任意一个存储节点的推理
pth的文件名格式如下:
- epoch_{n}/iter_{n}.pth(如epoch_3.pth):?每interval个epoch/iter周期存储(配置中需要指定CheckpointHook)
- best_epoch{n}_{metricname}{m}.pth(如best_iter13_accuracy22.pth):取得最佳模型参数时存储(配置中需要指定BestCkptSaverHook)
# 用于继续训练
trainer.train(checkpoint_path=os.path.join(self.tmp_dir, 'iter_3.pth'))
# 用于训练后评估
trainer.evaluate(checkpoint_path=os.path.join(self.tmp_dir, 'iter_3.pth'))
# 用于训练后推理并通过saving_fn存储预测的label为文件
trainer.predict(checkpoint_path=os.path.join(self.tmp_dir, 'iter_3.pth'),
predict_datasets=some_dataset,
saving_fn=some-saving-fn)参考链接:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!