CCKS2023-面向金融领域的主体事件检测-亚军方案分享
赛题分析
大赛地址
https://tianchi.aliyun.com/competition/entrance/532098/introduction?spm=a2c22.12281925.0.0.52b97137bpVnmh
任务描述
主体事件检测是语言文本分析和金融领域智能应用的重要任务之一,如在金融风控领域往往会对公司主体进行风险事件的检测。基于句子粒度的上下文进行公司事件检测,事件包含事件类型和主体要素(即公司主体),句中可能存在多个事件,多个公司主体且每个公司都可能存在多个事件类型标签,并且各类型标注样本分布不均匀,部分类型样本量较少,我们希望检测出文本中包含的所有主体事件。本次评测任务的文本语料来自于互联上的公开新闻、报告。
数据描述
输入 :一段文本X
输出 :文本X中所有的事件类型及对应的公司主体
示例 :
输入:{"text_id": "123456", "text": "播州城投多次被列为被执行人,同时涉及一系列诉讼案件并多次被纳入失信被执行人名单;由于公司债务逾期规模大,区域债务负担重, 7月母公司遵义道桥建设(集团)有限公司("遵义道桥")开始进行债务重组并将银行类债权延期 10年"}
输出:{"text_id": "123456", "events": [{"type":"被列为失信被执行人" ,"entity":"播州城投"} , {"type": "债务违约","entity": "播州城投"}, {"type": "债务重组", "entity": "遵义道桥建设(集团)有限公司"}, {"type": "债务重组", "entity": "遵义道桥"}]}
方案陈述
整体方案的模型架构
结构图如下所示:

-
传统模型:主要依赖传统的信息抽取方法来做,包括 bert+crf、 bert+span 和 bert+global pointer等方案;
-
LLMs:依赖已经预训练好的大模型,包括 mt5、mt0、Ziya-LLaMA、 chatglm 等,微调方式包括全量指令微调以及基于 Lora 的指令微调;
-
后处理:针对预测的数据进行异常符、原文修正、大小写修正、繁体 简体修正等;
-
融合:采用加权投票融合;
下面依次介绍每个方案的细节。
传统方案之bert-crf
crf这么基础的内容这里就不说了,用的就是原生的crf,没有进行魔改,需要说明一点的就是,这个任务中同一个公司主体如果有多个事件类型,crf这个方案是解决不了的,好在这个任务中这种一个公司主体对应多个事件类型的情况不多。
传统方案之bert-span
上文也说了,这个任务中存在一个公司主体对应多个事件类型的情况,为了兼容这种情况,我对原来的span编码解码框架稍稍进行了魔改,结构图如下:
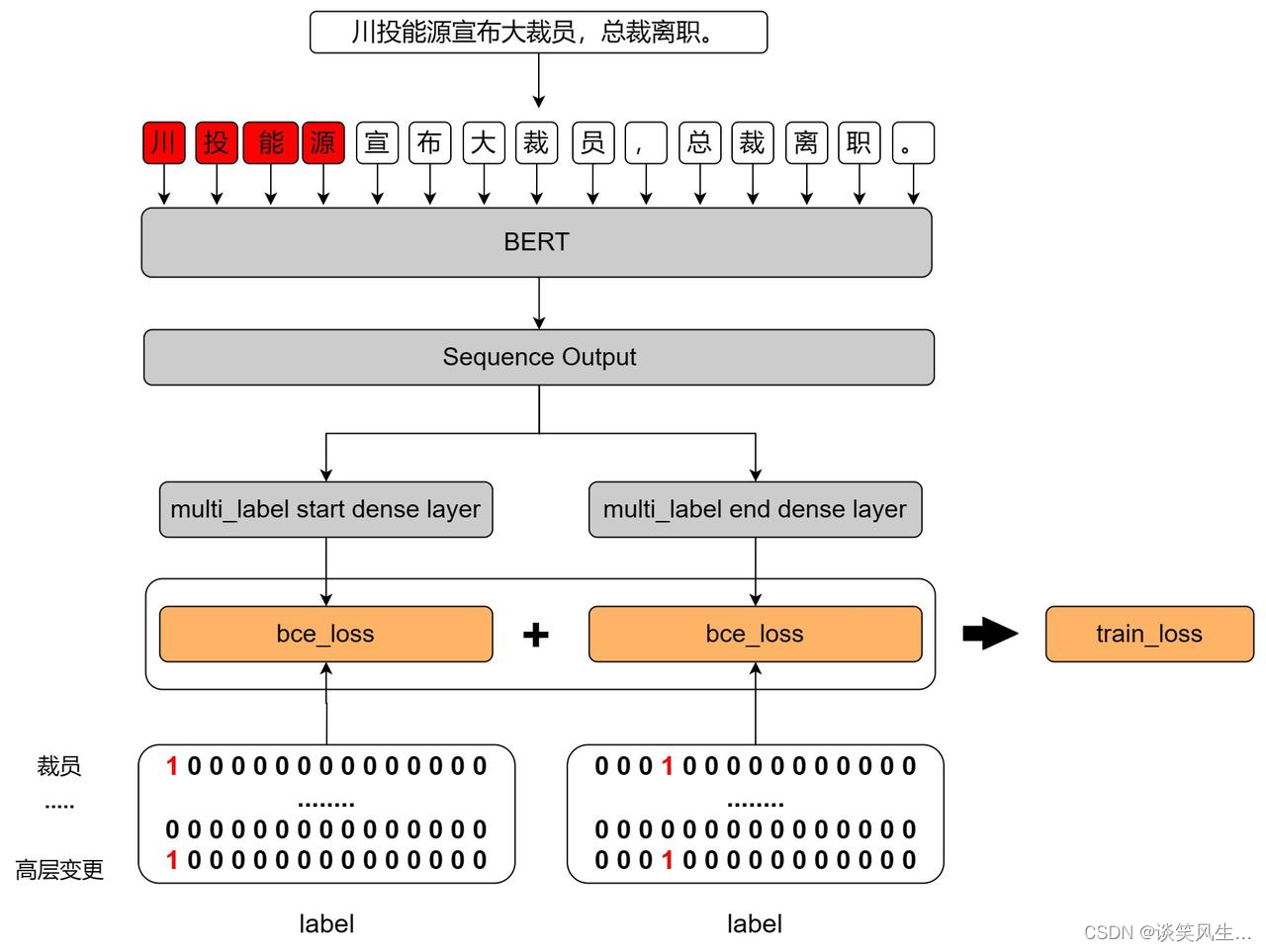
原生的span结构以双指针的形式替代 CRF 模块,可以解决实体嵌套 问题,首尾指针可以截取一个实体,首位指针的类型指代这个截取的实体的标签类型,但是在本次任务中,为了解决一个公司主体对应多个事件类型的情况,我们改变了首尾指针的形式,融入多标签的思想,基于多标签的span指针可以轻松实现一个实体(公司主体)指向多个类型(事件类型)。
传统方案之bert-gp
gp用的就是苏剑林原生的方案,没有进行改动,所以呢,我也不想废话了,估计你们也不想听我废话,你们直接看苏神的讲解吧。苏剑林科学空间:https://spaces.ac.cn/archives/8265
大模型(LLM)方案
本次任务我们将大模型用在了事件检测任务上,主要尝试了mt5、chatglm、以及llma模型,训练方式是全参数微调和Lora微调。
指令构造
指令 1:
使用自然语言抽取二元组,请从句子中抽取出所有的事件类型及对应的公司主体, 句中可能存在多个事件、多个公司主体且每个公司都可能存在多个事件类型标签,最后以 (公司主体,事件类型)的形式回答。
例子:
"instruction":"使用自然语言抽取二元组,请从句子中抽取出所有的事件类型 及对应的公司主体,句中可能存在多个事件、多个公司主体且每个公司都可能存在多个事 件类型标签,最后以(公司主体,事件类型)的形式回答。","input":"而在此之前,从 2013 开始至 2018 年连续 5 年时间,苏州银行的核心一级资本充足率、一级资本充足率 均在下降,资本充足率在 2015 年出现回升后也再度连续三年下降","output":"(苏州 银行,资本充足不足)
指令 2:
这是一个金融实体抽取的任务,请从以下句子抽取公司主体以及相应的事件类 型,按(公司主体,事件类型)的形式回答。
例子:
这是一个金融实体抽取的任务,请从以下句子抽取公司主体以及相应的事件类 型,按(公司主体,事件类型)的形式回答。 例子:"instruction":"这是一个金融实体抽取的任务,请从以下句子抽取公司主体 以及相应的事件类型,按(公司主体,事件类型)的形式回答。","input":"而在此之 前,从 2013 开始至 2018 年连续 5 年时间,苏州银行的核心一级资本充足率、一级资 本充足率均在下降,资本充足率在 2015 年出现回升后也再度连续三年下降 ","output":"(苏州银行,资本充足不足)
微调
mt5、mt0 以及 umt5 经过多语种预训练,对于这个任务 也适配,在 large 模型,可以模型并行来训练, 在 xl 以及 xxl 模 型,需要基于 deepspeed 对模型参数进行切分来提高模型训练速度, xxl 模型,在 A100 卡上,全量微调。
Lora 指令微调:当前中文模型包括 chatglm、ziya-llama、ZhiXi (智 析)
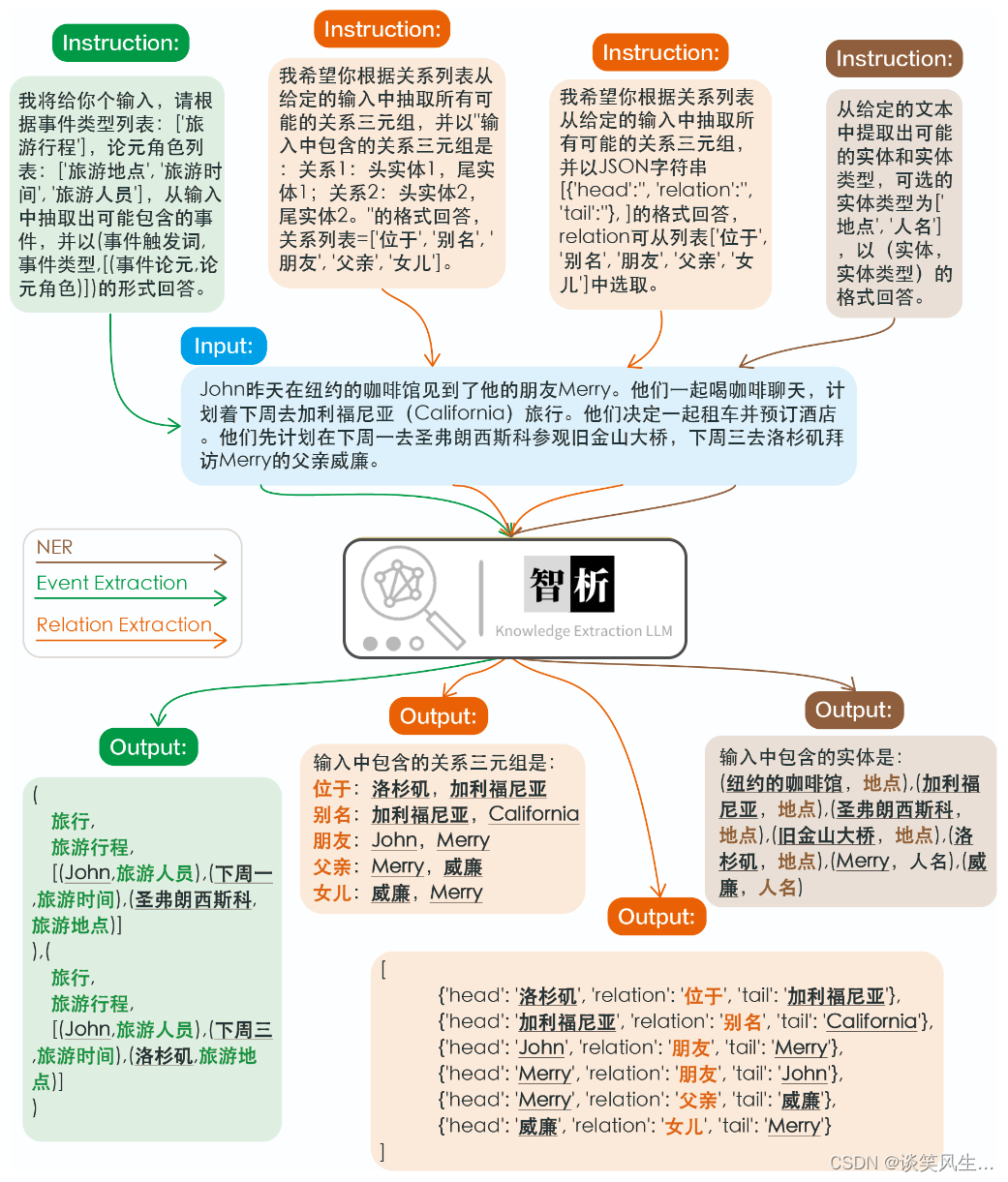
本次基于大模型做事件检测任务部分参考如下范例:
总结
本次赛道任务,我们总结如下:
-
在数据层面,我们做了一些数据增广,聚合相同事件类型下所有公司主体,随机替换同个类型的公司 实体进行数据生成;
-
在传统方案上(crf、span、gp),我们通过一些手段(fgm、pgd、swa、ema、r-drop、multi-drop等)增强了模型的泛化性和鲁棒性;
-
选择了多种的编码框架,crf是序列标记,span是指针抽取,gp是片段排列,LLM是基于指令的生成式,每一种框架都有自己的优势和短板,融合起来增益良多;
最后值得一提的是,通过本次任务,大模型(LLM)虽然参数大很多,训练时间长很多,但是单个大模型的效果并没有比传统方案的效果好,从性价比上甚至处于劣势,但是差异大,不同框架之间差异大,融合效果提升很多。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!