gpt3、gpt2与gpt1区别
?参考:深度学习:GPT1、GPT2、GPT-3_HanZee的博客-CSDN博客
Zero-shot Learning / One-shot Learning-CSDN博客
GPT1、GPT2、GPT3、InstructGPT-CSDN博客?
目录
????????GPT-2 模型由多层单向transformer的解码器部分构成,本质上是自回归模型,自回归的意思是指,每次产生新单词后,将新单词加到原输入句后面,作为新的输入句。
????????自监督学习:从未标记的数据中构建训练集,并通过模型自动生成标签或目标来进行训练。
gpt2与gpt1区别
1.模型架构上变得更大,参数量达到了1.5B,数据集改为百万级别的WebText,Bert当时最大的参数数量为0.34B,但是作者发现模型架构与数据集都扩大的情况下,与同时期的Bert的优势并不大。
2.gpt2 pre-training方法与gpt1一致,但在做下游任务时,不再进行微调,只进行简单的Zero-Shot,就能与同时期微调后的模型性能相差不大。
Zero-Shot(零次学习),成品模型对于训练集中没有出现过的类别,能自动创造出相应的映射: XX -> YY。利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
????????GPT-2在训练样本中加入了下游任务的相关描述(即增加文本提示,后来被称为Prompt),利用预训练过程中获得的语言理解和生成能力,根据提示来生成符合特定任务要求的输出。
Zero-Shot表现在GPT2中:
????????例如,在文本分类任务中,当用户给出一个任务描述时(分类 每个类别分别是什么什么样),GPT-2可以根据该描述直接将文本分为不同的类别,而无需针对特定类别进行微调。
????????同样地,对于问答系统,GPT-2可以根据问题和相关上下文信息来生成回答,而无需在特定的问答数据集上进行微调。


3.在模型结构上,调整了每个block Layer Normalization的位置。
将layer normalization放到每个sub-block之前,并在最后一个块后再增加一个layer normalization

?gpt3与gpt2区别
????????GPT3 可以理解为 GPT2 的升级版,使用了 45TB 的训练数据,拥有 175B 的参数量
GPT3 主要提出了两个概念:
????????情景(in-context)学习:在被给定的几个任务示例或一个任务说明的情况下,模型应该能通过简单预测来补全任务中的其他示例。即,情境学习要求预训练模型要对任务本身进行理解。情境学习就是对模型进行引导,教会它应当输出什么内容,比如翻译任务可以采用输入:请把以下英文翻译为中文:Today is a good day。
????????情境学习分为三类:Zero-shot, one-shot and few-shot。GPT3 打出的口号就是“告别微调的 GPT3”,它可以通过不使用一条样例的 Zero-shot、仅使用一条样例的 One-shot 和使用少量样例的 Few-shot 来完成推理任务。下面是对比微调模型和 GPT3 三种不同的样本推理形式图。
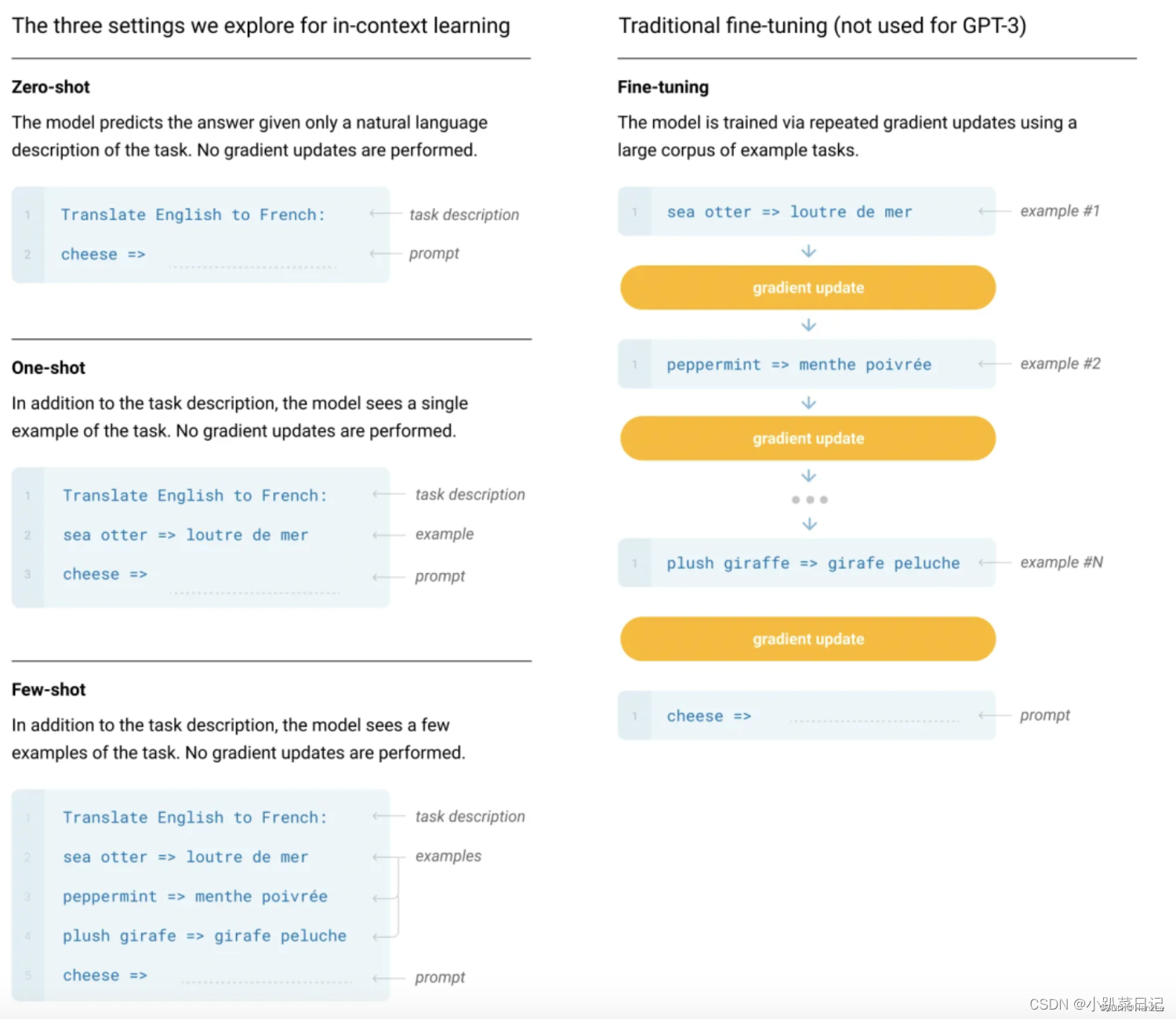
下游任务:
本文聚焦于系统分析同一下游任务不同设置下,模型情境学习能力的差异:
Fine-tuning(FT) :利用成千上万的下游任务标注数据来更新预训练模型中的权重。缺点:每个新的下游任务都需要大量的标注预料,模型不能在样本外推预测时具有好效果,说明FT导致模型的泛化性降低。
Few-Shot(FS):模型在测试阶段可以得到少量的下游任务示例作为限制条件,但是不允许更新预训练模型中的权重。FS的主要优点是并不需要大量的下游任务数据。FS的主要缺点是不仅与fine-tune的SOTA模型性能差距较大且仍需要少量的下游任务数据。
One-Shot(1S):这种方式与人类沟通的方式最相似。
Zero-Shot(0S):0S的方式是非常具有挑战的,即使是人类有时候也难以仅依赖任务描述而没有示例的情况下理解一个任务。但0S设置下的性能是最与人类的水平具有可比性的。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!