【机器学习】040_理解偏差与方差
一、定义
偏差:衡量预测值与真实值之间的关系——指预测值和真实值之间差值
方差:衡量预测值之间的关系,与真实值无关——指各个预测值之间的离散程度
误差 =?偏差 +?方差
· 高偏差——模型欠拟合;
· 高方差——模型过拟合;
训练模型时,既要避免高偏差,又要避免高方差。
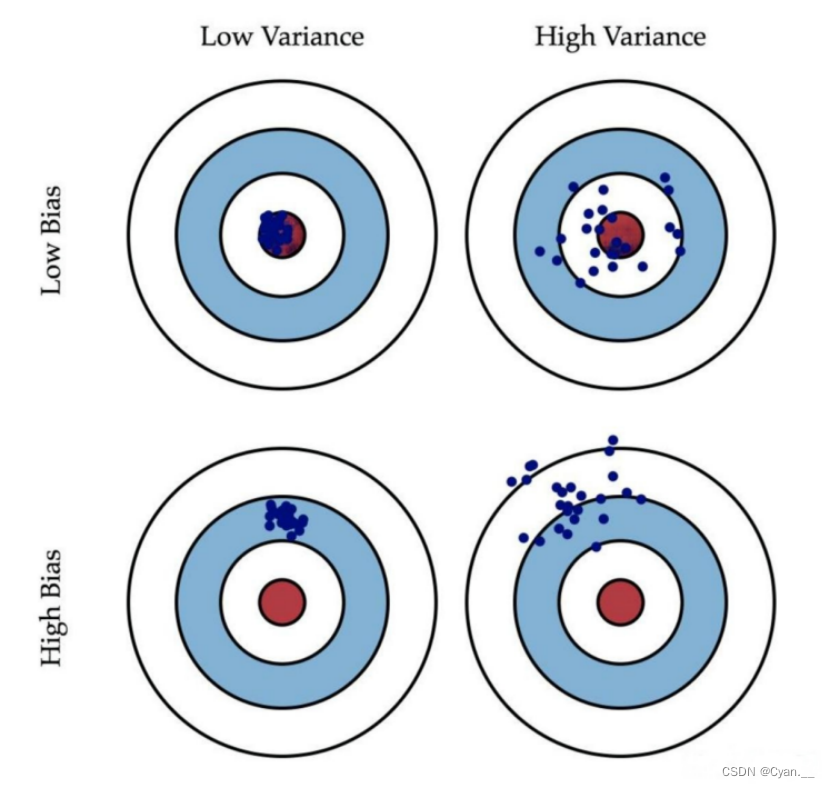
可以利用如下图所示的打靶模型更好地理解偏差和方差:
二、学习曲线(反映模型出于偏差还是方差)
通过学习曲线,将训练集误差和交叉验证集误差作为训练集实例数量(m)的函数,绘制图表反映
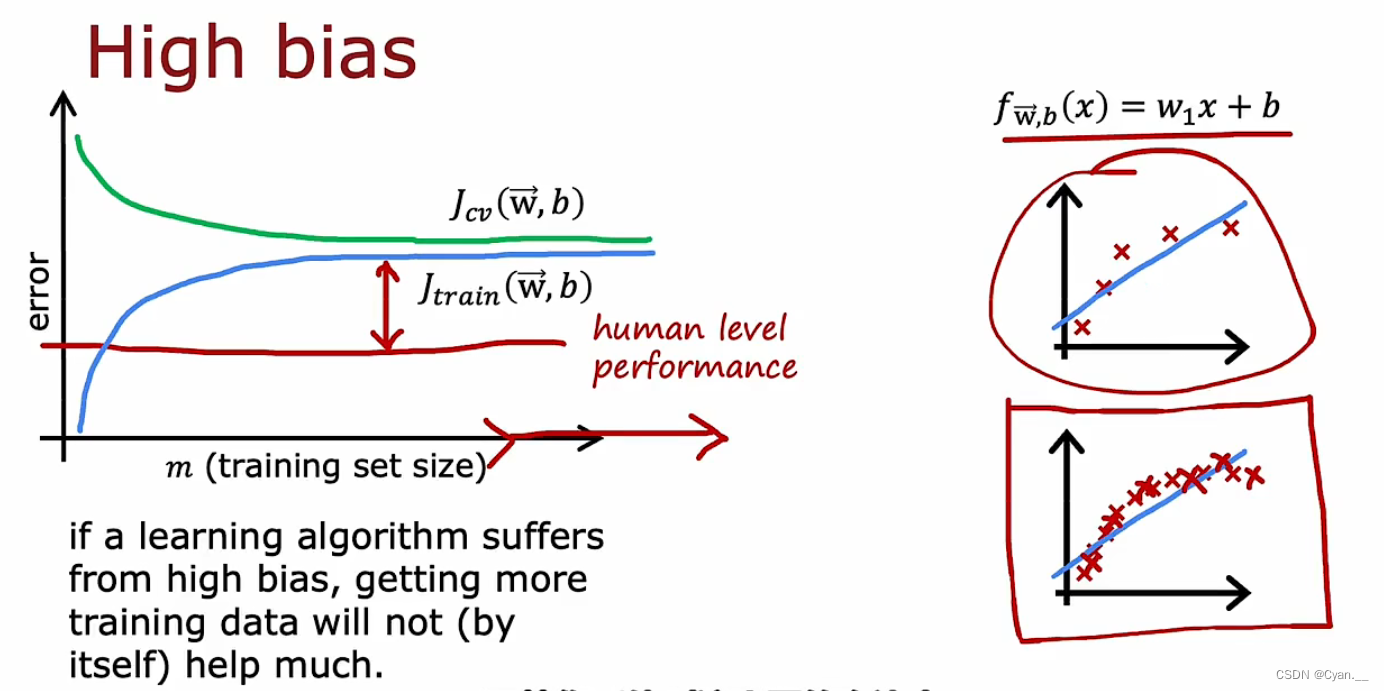
· 当模型欠拟合时,训练误差和交叉验证误差都较大,且在增大到一定程度后趋于平坦。这两部分的误差值往往是大于human?level?performance的。增加数据集的数据量,往往不会有太大帮助。

·?当模型过拟合时,训练误差较小(精度很高),但是交叉验证误差较大。通过增加数据集大小,使用更多数据,可以有效减小交叉验证误差。因而,提高数据量有助于解决过拟合。
因而,通过数据量增大对模型精度的影响,可以间接反映出模型误差是出于偏差还是方差。
三、解决高偏差与高方差
高偏差:
1. 增加特征
获得更多的特征
增加多项式特征
2. 减少正则化程度
高方差:
1. 增加训练数据
2. 减少特征数量
3. 增大正则化程度
事实证明,大型神经网络是低偏差模型机器,换句话说,神经网络越大越能适配训练数据集;
因此,通过以下循环,可以不断解决高偏差和高方差:
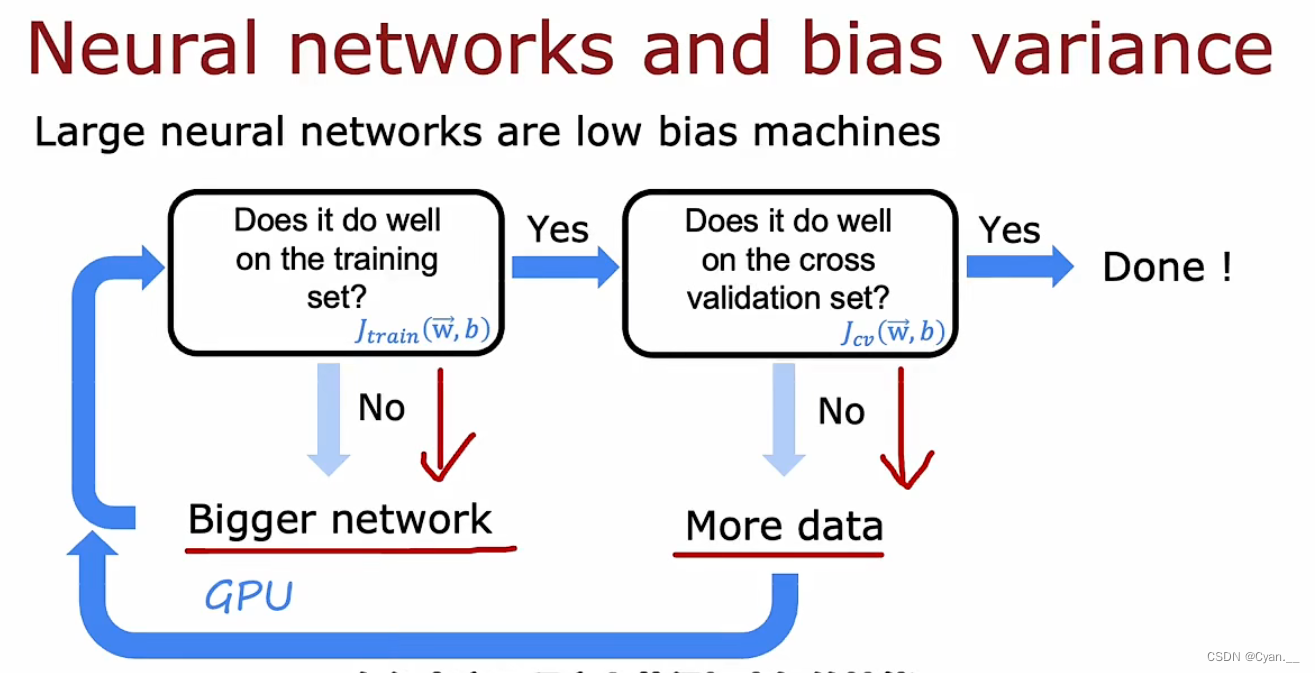
· 首先将模型在训练集上训练,看训练误差的大小;如果训练误差过大就使用更大的神经网络,知道训练误差足够小为止。构建更大的神经网络,往往需要消耗GPU算力。
·?然后在交叉验证集上训练模型获得交叉验证误差。如果交叉验证误差过大则增大数据量,再次返回最初重新进行循环,不断进行直到交叉验证误差也足够小为止。获取更多的数据量,往往需要大量原始数据和访问大量数据应用的支撑。
事实证明,具有良好正则化的大型神经网络通常与较小的神经网络一样好或更好——适当地对大型神经网络进行正则化,就能够减小过拟合现象的发生。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!