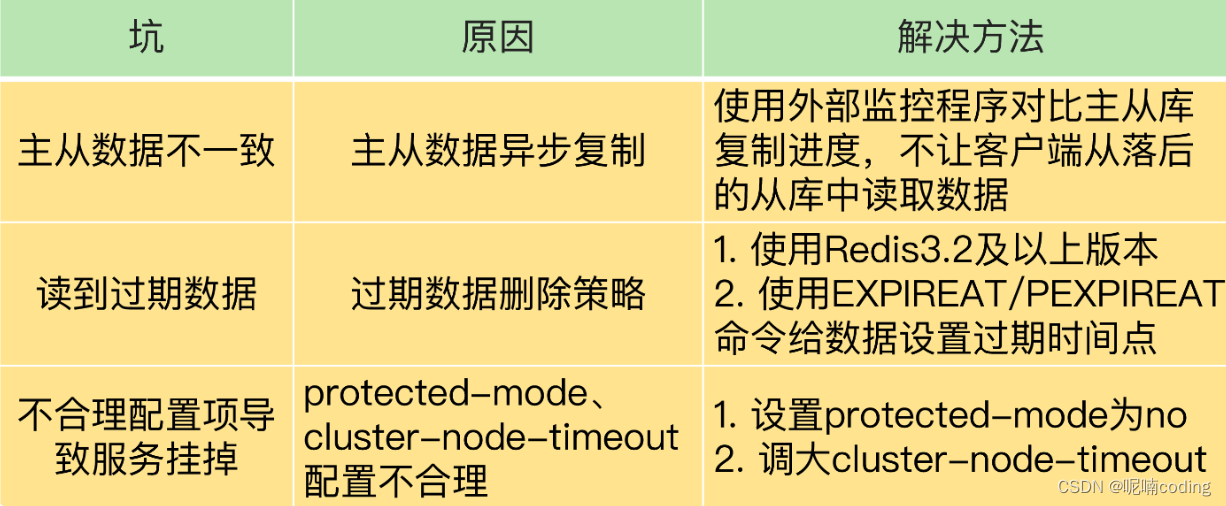
redis 主从同步和故障切换的几个坑
数据不一致
当我们从节点读取一个数据时,和主节点读取的数据不一致,这是因为主从同步的命令是异步进行的,一般情况下是主从同步延迟导致的,为什么会延迟,
主要二个原因
1、网络状态不好
2、网络没问题,从节点执行耗时命令,之前的命令在排队,没有执行到
对于 1,我们要检查网络状态,在硬件网络尽量把主从机器部署在一起,对于 2 ,可以开发一个监控主从复制进度的程序,及时的把主从复制进度大于一定差值的客户端移除,当复制进度赶上时,再增加进去
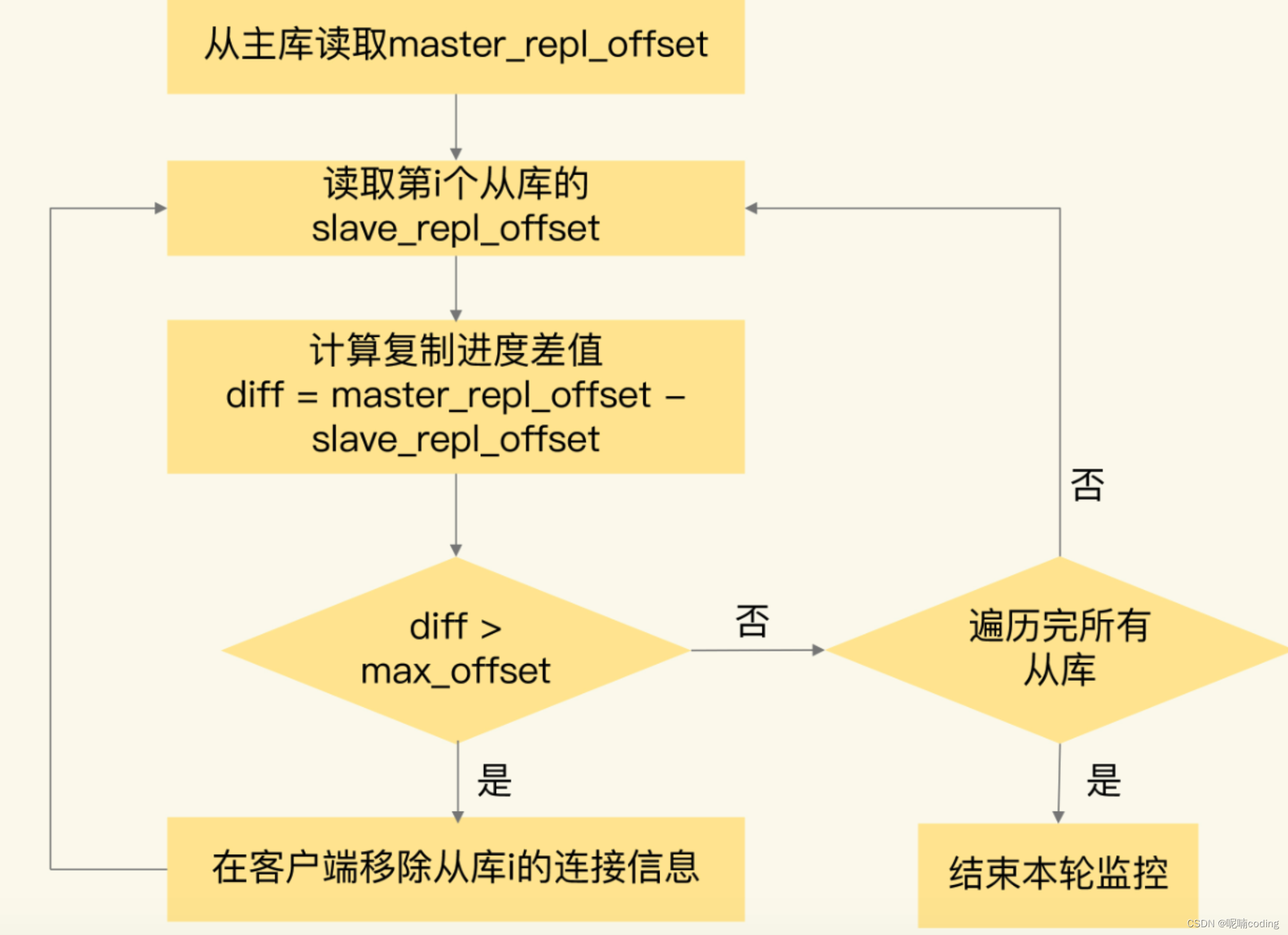
数据不一致是不可避免的,我们尽量缩小不一致的时间,或者重要数据直接读主库
客户端读取到过期数据
我们使用主从集群时,有时后设置的过期时间是 12.00.00,但是 12:00:01 时,在从节点还是可以读取到数据, 这个和 redis 过期策略有关系
redis,过期策略有 2 种,主动删除和定期删除,
- 主动删除是惰性的,当客户端读取主节点时,判断数据过期,不会返回,主节点不会读取到过期时间,但是从节点 不会自动删除,会返回过期数据,这个和版本有关系,3.2 之前会,之后不会再返回过期数据
- 定期删除是被动的,定时100ms的,但是不会删除所有过期数据,会随机选择一定的数据,不断的进行删除,保证 redis 的性能,所以会有一部分数据是过期但是还存在
如果使用 3.2 之后,会返回吗,看使用的命令
- expire和 pexpire ,设置的是从命令开始计算的存活时间 ,当主从延迟是,一个命令是 60s,主节点 12.00 执行,从节点延迟了,12.01 执行,过期时间就会不一致,怎么解决的,使用下个命令
- expireat 和 pexpireat ,直接把数据的过期时间设置为一个具体的时间点,这个就可以保证不会读取到过期数据了
EXPIRE testkey 60 替换为 EXPIREAT testkey 1603501200
这个问题是可以解决的
不合理的命令导致服务挂掉
protected-mode 配置项
作用是哨兵实例是否可以被其他实例访问,配置为 yes 时,只能本地访问 ,当其他哨兵服务器在其他节点时,无法通信,主库故障时无法判断,也无法切换,建议配置为 no ,bind 其他实例地址
protected-mode no
bind 192.168.10.3 192.168.10.4 192.168.10.5
cluster-node-timeout 配置项
这个配置项设置了 Redis Cluster 中实例响应心跳消息的超时时间
当我们在 Redis Cluster 集群中为每个实例配置了“一主一从”模式时,如果主实例发生故障从实例会切换为主实例,受网络延迟和切换操作执行的影响,切换时间可能较长,就会导致实例的心跳超时(超出 cluster-node-timeout)。实例超时后,就会被 Redis Cluster 判断为异常。而 Redis Cluster 正常运行的条件就是,有半数以上的实例都能正常运行。
所以,如果执行主从切换的实例超过半数,而主从切换时间又过长的话,就可能有半数以上的实例心跳超时,从而可能导致整个集群挂掉。所以,我建议你将 cluster-node-timeout 调大些(例如 10 到 20 秒)
总结
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!