什么是 NLP (自然语言处理)
NLP(自然语言处理)到底是做什么?

NLP 的全称是 Natural Language Processing,翻译成中文称作:自然语言处理。它是计算机和人工智能的一个重要领域。顾名思义,该领域研究如何处理自然语言。
自然语言就是我们人类市场交流所使用的语音和字符系统。就目前而言,NLP所研究的对象,以字符系统——也就是我们通常说的“文字”——为主。
为什么要处理自然语言?
为什么要处理文字呢?因为有需求啊!
我们用文字描述事物、经历和思想。形成的文献资料,除了被阅读,往往还需要进行很多其他操作。
比如,被翻译成其他语种;对内容进行摘要;在其中查找某个问题的答案;或者,了解其中提到了哪些人事物,以及它们之间的关系如何,等等。

虽然所有这些需求,都可以通过人工阅读文献来解决,但“浩如烟海”的文献量导致人工文字处理的产能严重不足。
NLP 的发展历程
上世纪 40 年代计算机被发明,用机器而非人力来处理信息成为可能。早在 1950 年代,自然语言处理就已经成为了计算机科学的一个研究领域。
不过一直到 1980 年代,NLP 系统是以一套复杂的人工订制规则为基础,计算机只是机械地执行这些规则,或者做一些诸如字符匹配,词频统计之类的简单计算。

1980年代末期,机器学习的崛起为 NLP 引入了新的思路。刚性的文字处理人工规则日益被柔性的、以概率为基础的统计模型所替代。
近些年来,随着深度学习的发展,各类神经网络也被引入 NLP 领域,成为了解决问题的技术。
这里要注意了:自然语言处理(NLP)指以计算机为工具解决一系列现实中和自然语言相关的问题,机器学习、深度学习是解决这些问题的具体手段。 当我们关注 NLP 这一领域时,要分清本末,要做的事情是本,做事的方式方法是末。如果神经网络能够解决我们的问题,我们当然应该采用,但并不是只要去解决问题,就一定要用神经网络。
常见的 NLP 任务
NLP 要处理的问题纷繁复杂,而且每一个问题都要结合相应场景和具体需求才好讨论。
不过这些问题也有相当多的共性,基于这些共性,我们将千奇百怪的待解决 NLP 问题抽象为若干任务。

例如:分词、词嵌入、新词发现、拼写提示、词性标注、实体抽取、关系抽取、事件抽取、实体消歧、公指消解、文本分类、机器翻译、自动摘要、阅读理解等等,都是常见的 NLP 任务。
从 NLP 任务到技术实现
针对这些任务,NLP 研究人员探索出了很多方法,这些方法又对应于不同类型的技术。
在工作中,当我们遇到问题的时候,往往需要先将其对应到一个或多个任务,再在该任务的常用实现方法中选取一种适合我们使用的来执行任务。
【举个例子】:我们要基于若干文献构建一个知识图谱,知识图谱的两大核心要素是实体和关系,那么当然首先我们面临的任务就是从这些文献中抽取实体和关系。
实体抽取是一项非常常见的 NLP 任务,实现它的方法有多种,大体而言分为两个方向:
i)基于实体名字典进行字符匹配抽取;
ii)用序列预测模型进行抽取。
序列预测模型又可以选用机器学习模型,比如条件随机场(CRF);或选用神经网络,比如 CRF+LSTM,或 CRF+BERT等。
具体选哪种方法呢?那就要看我们需要抽取的实体类型、文献类型和文献量了。
如果现在是从少量专业文献(例如论文、说明书、研究报告等)中抽取一些列专业名词表示的实体,那么用字典匹配方便直接代价小,可以一试。
如果是要从海量的各类文献中抽取一些通用的实体,那么借助模型则可能效果更佳。
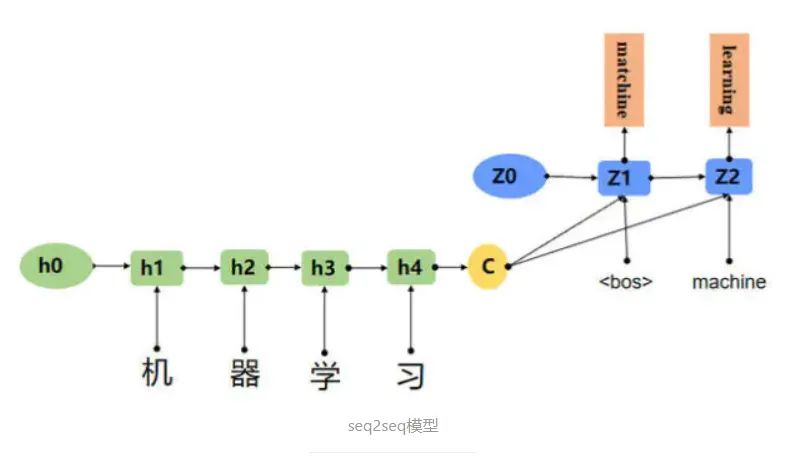
具体用机器学习模型还是神经网络呢?这又和我们拥有的标注数据与计算资源有关,如果不差钱,想标多少数据,想训练多大模型都不在乎,上神经网络自然可以追求高准确率,但如果资源捉襟见肘,可能机器学习模型更加实用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!