通用基础模型+提示词是否能胜过微调模型?医学案例研究
2023-12-14 09:00:13
论文链接在末尾
摘要
通用基础模型,如GPT-4,在各种领域和任务中展现出令人惊讶的能力。然而,普遍存在这样一种假设,即它们在没有专业知识深度训练的情况下无法达到专业能力。例如,迄今为止对医学竞赛基准的大多数探索都利用了领域特定的训练,正如在BioGPT和Med-PaLM等项目上所示。我们基于先前对GPT-4在医学挑战基准上的专业能力的研究,而无需特殊培训。
与故意使用简单提示突显模型开箱即用的能力不同,我们进行了对提示工程的系统探索以提高性能。我们发现,提示创新可以释放更深层次的专业能力,并表明GPT-4轻松超越了先前在医学问答数据集上的领先结果。我们探索的提示工程方法是通用的,不特定使用领域专业知识,消除了对专业策划内容的需求。我们的实验设计在提示工程过程中仔细控制了过拟合。
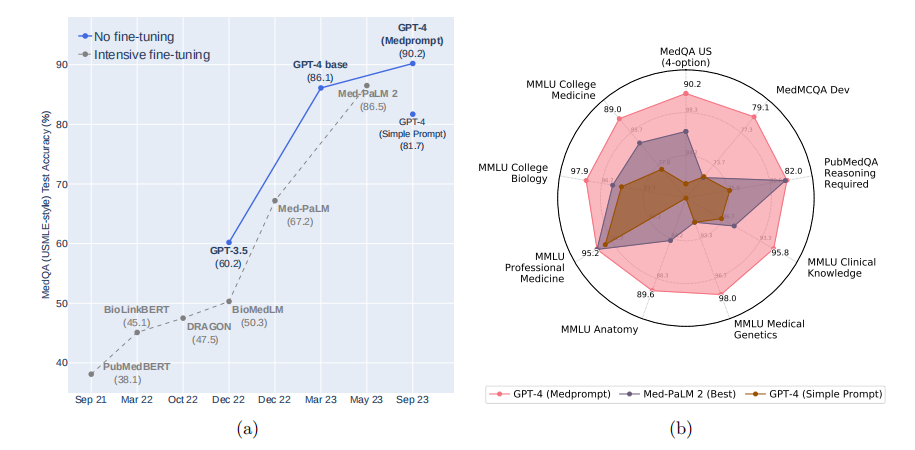
作为研究的总结,我们推出了Medprompt,基于若干提示策略的组合。Medprompt极大地增强了GPT-4的性能,并在MultiMedQA套件的所有九个基准数据集上取得了最先进的结果。该方法在调用模型的数量上远远优于Med-PaLM 2等最先进的专业模型。使用Medprompt引导GPT-4在MedQA数据集(USMLE考试)上实现了27%的错误率降低,超过了迄今为止使用专业模型实现的最佳方法,并首次达到了90%的得分。超越医学挑战问题,我们展示了Medprompt在泛化到其他领域方面的能力,并通过对电气工程、机器学习、哲学、会计、法律、护理和临床心理学的能力考试策略的研究提供了证据,证明了该方法的广泛适用性。
1介绍
文章来源:https://blog.csdn.net/artistkeepmonkey/article/details/134891325
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!