OpenCL学习笔记(一)开发环境搭建(win10+vs2019)
前言
异构编程开发,在高性能编程中有重要的,笔者本次只简单介绍下,如何搭建简单的开发环境,可以供有需要的小伙伴们开发测试使用
一、获取opencl的sdk库
1.使用cuda库
若本机有Nvidia的显卡,在安装cuda库后,可以直接在安装目录下找到对应库文件
CUDA下载地址:CUDA Toolkit - Free Tools and Training | NVIDIA Developer


本地版的包比较大,网络版的需要安装时联网下载
建议直接安装最新版本,并在安装前删除的版本
注:需要先安装显卡驱动
安装完成后,可以直接在安装目录下找到库文件,以下是64位库、32位库、include文件



2.使用opencl-sdk预编译库
可以到opencl官网上,直接下载已经编译好的预编译库
下载地址:Releases · KhronosGroup/OpenCL-SDK · GitHub
笔者写文档时,最新发布日期是2023.04.17
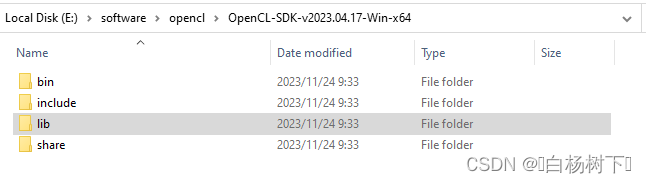
下载后,直接解压就可以得到库文件和include文件 ,如下图所示
二、编写cmake文件
set(include_paths
# "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.3/include"
{opencl_dir}/OpenCL-SDK-v2023.04.17-Win-x64/include
)
set(link_paths
#"C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.3/lib/x64"
{opencl_dir}/OpenCL-SDK-v2023.04.17-Win-x64/lib
)
set(link_libs
OpenCL.lib
)
add_executable(opencltest
main.cpp
)
target_include_directories(opencltest PRIVATE
${include_paths}
)
target_link_directories(opencltest PRIVATE
${link_paths}
)
target_link_libraries(opencltest
${link_libs}
)
cmake文件比较简单,就是直接引入对应opencl库
要注意一点,CUDA的默认安装目录有空格,需要把整个目录放入引号中
三、运行示例
const int N = 1024; // 矩阵大小
const size_t size = N * N * sizeof(float);
int main() {
// 初始化输入矩阵
float* A = new float[N * N];
float* B = new float[N * N];
for (int i = 0; i < N * N; i++) {
A[i] = 1.0f;
B[i] = 2.0f;
}
// 初始化OpenCL环境
cl_platform_id platform;
clGetPlatformIDs(1, &platform, NULL);
cl_device_id device;
clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
cl_context context = clCreateContext(NULL, 1, &device, NULL, NULL, NULL);
cl_command_queue queue = clCreateCommandQueueWithProperties(context, device, 0, NULL);
// 创建OpenCL内存缓冲区
cl_mem bufferA = clCreateBuffer(context, CL_MEM_READ_ONLY, size, NULL, NULL);
cl_mem bufferB = clCreateBuffer(context, CL_MEM_READ_ONLY, size, NULL, NULL);
cl_mem bufferC = clCreateBuffer(context, CL_MEM_WRITE_ONLY, size, NULL, NULL);
// 将输入数据传输到OpenCL缓冲区
clEnqueueWriteBuffer(queue, bufferA, CL_TRUE, 0, size, A, 0, NULL, NULL);
clEnqueueWriteBuffer(queue, bufferB, CL_TRUE, 0, size, B, 0, NULL, NULL);
// 创建OpenCL程序对象
const char* source = "__kernel void add_matrices(__global const float* A, __global const float* B, __global float* C) { int id = get_global_id(0); C[id] = A[id] + B[id]; }";
cl_program program = clCreateProgramWithSource(context, 1, &source, NULL, NULL);
clBuildProgram(program, 1, &device, NULL, NULL, NULL);
cl_kernel kernel = clCreateKernel(program, "add_matrices", NULL);
// 设置OpenCL内核参数
clSetKernelArg(kernel, 0, sizeof(cl_mem), &bufferA);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &bufferB);
clSetKernelArg(kernel, 2, sizeof(cl_mem), &bufferC);
// 启动内核
size_t globalWorkSize[2] = { N, N };
clEnqueueNDRangeKernel(queue, kernel, 2, NULL, globalWorkSize, NULL, 0, NULL, NULL);
// 读取结果数据
clEnqueueReadBuffer(queue, bufferC, CL_TRUE, 0, size, A, 0, NULL, NULL);
// 清理OpenCL资源
clReleaseMemObject(bufferA);
clReleaseMemObject(bufferB);
clReleaseMemObject(bufferC);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseCommandQueue(queue);
clReleaseContext(context);
// 打印结果
std::cout << "Result: " << A[0] << std::endl;
delete[] A;
delete[] B;
int a;
std::cin >> a;
return 0;
}整个程序比较简单,若是运行正常,可以直接打印出结果
注:运行前,需要安装好对应的显卡驱动
后记
本文件是使用最简单的方法搭建opencl开发环境
笔者没有AMD显卡的设备,所以未测试相关
若本地是使用的intel集成显卡,使用官方的sdk,也可以找到对应的设备
android系统,笔者未来得及测试,若不想自己编译库,需要自己在android设备上查找下opencl库,目录可能是在/system/vendor/lib/libOpenCL.so。若未找到,可能不支持。若有时间,笔者需要另写一篇文档记录下
由于不同厂家是独立实现的,具体运行时,可能有些结果会有出入,需要具体测试;若不是使用官方的sdk,一个厂家的库,可能只能检测到自家设备。
使用厂家的库,经常也会缺少部分封闭库,如C++封装库
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!