YOLOv8改进 | 2023主干篇 | EfficientViT替换Backbone(高效的视觉变换网络)
一、本文介绍
本文给大家带来的改进机制是EfficientViT(高效的视觉变换网络),EfficientViT的核心是一种轻量级的多尺度线性注意力模块,能够在只使用硬件高效操作的情况下实现全局感受野和多尺度学习。本文带来是2023年的最新版本的EfficientViT网络结构,论文题目是'EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction'这个版本的模型结构(这点大家需要注意以下)。同时本文通过介绍其模型原理,然后手把手教你添加到网络结构中去,最后提供我完美运行的记录,如果大家运行过程中的有任何问题,都可以评论区留言,我都会进行回复。亲测在小目标检测和大尺度目标检测的数据集上都有大幅度的涨点效果(mAP直接涨了大概有0.1左右)
推荐指数:?????
涨点效果:?????
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备????
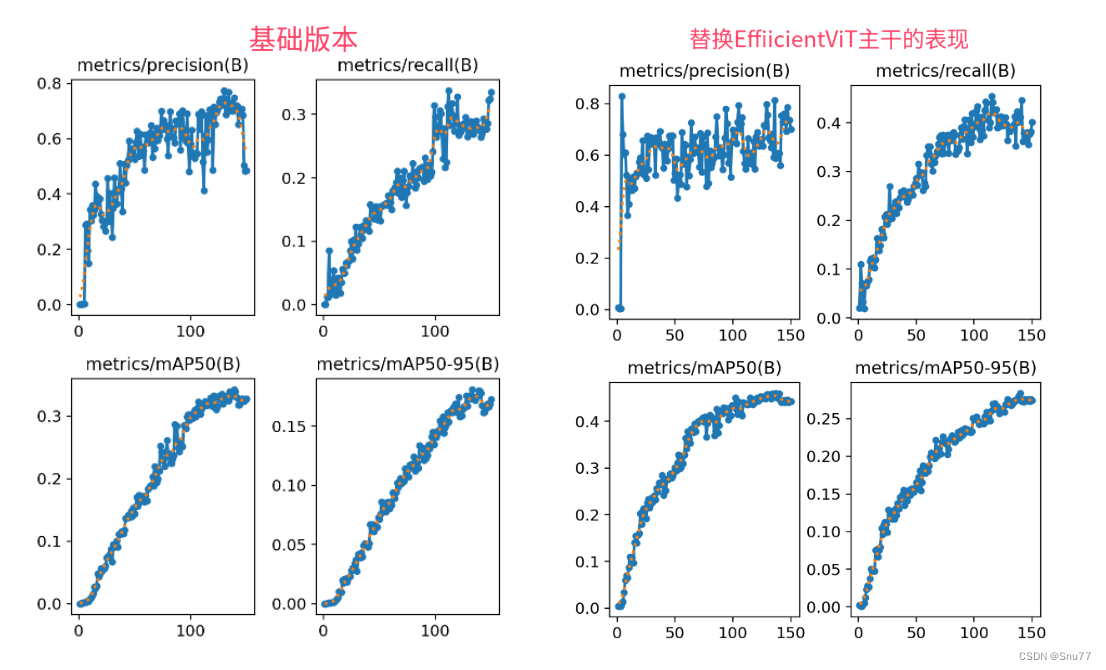
训练结果对比图->??
这次试验我用的数据集大概有七八百张照片训练了150个epochs,虽然没有完全拟合但是效果有很高的涨点幅度,所以大家可以进行尝试毕竟不同的数据集上效果也可能差很多,同时我在后面给了多种yaml文件大家可以分别进行实验来检验效果。
可以看到这个涨点幅度mAP直接涨了大概有0.1左右。
目录
二、EfficientViT模型原理

论文地址:官方论文地址
代码地址:官方代码地址
 ?
?
2.1??EfficientViT的基本原理
EfficientViT是一种高效的视觉变换网络,专为处理高分辨率图像而设计。它通过创新的多尺度线性注意力机制来提高模型的性能,同时减少计算成本。这种模型优化了注意力机制,使其更适合于硬件实现,能够在多种硬件平台上,包括移动CPU、边缘GPU和云GPU上实现快速的图像处理。相比于传统的高分辨率密集预测模型,EfficientViT在保持高性能的同时,大幅提高了计算效率。
我们可以将EfficientViT的基本原理概括为以下几点:
1. 多尺度线性注意力机制:EfficientViT采用了一种新型的多尺度线性注意力机制,这种方法旨在提高模型处理高分辨率图像时的效率和效果。
2. 轻量级和硬件高效操作:与传统的高分辨率密集预测模型不同,EfficientViT通过轻量级和硬件高效的操作来实现全局感受野和多尺度学习,这有助于降低计算成本。
3. 显著的性能提升和速度加快:在多种硬件平台上,包括移动CPU、边缘GPU和云GPU,EfficientViT实现了相比之前的模型显著的性能提升和加速。
2.2?多尺度线性注意力机制
多尺度线性注意力机制是一种轻量级的注意力模块,用于提高处理高分辨率图像时的效率。它旨在通过简化的操作来实现全局感受野和多尺度学习,这对于高分辨率密集预测尤其重要。这种注意力机制在保持硬件效率的同时,能够有效捕获长距离依赖关系,是高分辨率视觉识别任务的理想选择。
下图展示了EfficientViT的构建模块,左侧是EfficientViT的基本构建块,包括多尺度线性注意力模块和带有深度卷积的前馈网络(FFN+DWConv)。右侧详细展示了多尺度线性注意力,它通过聚合邻近令牌来获得多尺度的Q/K/V令牌。
 ?
?
在通过线性投影层得到Q/K/V令牌之后,使用轻量级的小核卷积生成多尺度令牌,然后通过ReLU线性注意力对这些多尺度令牌进行处理。最后,这些输出被联合起来,送入最终的线性投影层以进行特征融合。这种设计旨在以计算和存储效率高的方式捕获上下文信息和局部信息。
2.3?轻量级和硬件高效操作
EfficientViT中的轻量级和硬件高效操作主要指的是在模型中采用了简化的注意力机制和卷积操作,这些设计使得EfficientViT能够在各种硬件平台上高效运行。具体来说,模型通过使用多尺度线性注意力和深度卷积的前馈网络,以及在注意力模块中避免使用计算成本高的Softmax函数,实现了既保持模型性能又显著减少计算复杂性的目标。这些操作包括使用多尺度线性注意力机制来替代传统的Softmax注意力,以及采用深度可分离卷积(Depthwise Convolution)来减少参数和计算量。
下图为大家展示的是EfficientViT的宏观架构:
 ?
?
EfficientViT的宏观架构包括一个标准的后端骨干网络和头部/编码器-解码器设计。EfficientViT模块被插入到骨干网络的第三和第四阶段。这种设计遵循了常见的做法,即将来自最后三个阶段(P2, P3, 和 P4)的特征送入头部,并采用加法来融合这些特征,以简化和提高效率。头部设计简单,由几个MBConv块和输出层组成。在这个框架中,EfficientViT通过提供一种新的轻量级多尺度注意力机制,能够高效处理高分辨率的图像,同时保持对不同硬件平台的适应性。
2.4?显著的性能提升和速度加快
显著性能提升和速度加快主要是指模型在各种硬件平台上,相对于以前的模型,在图像处理任务中表现出了更好的效率和速度。这得益于EfficientViT在设计上的优化,如多尺度线性注意力和深度可分离卷积等。这些改进使得模型在处理高分辨率任务时,如城市景观(Cityscapes)数据集,能够在保持性能的同时大幅减少计算延迟。在某些应用中,EfficientViT与现有最先进模型相比,提供了多达数倍的GPU延迟降低,这些优化使其在资源受限的设备上具有很高的实用性。
三、EfficienViT的完整代码
import torch.nn as nn
import torch
from inspect import signature
from timm.models.efficientvit_mit import val2tuple, ResidualBlock
from torch.cuda.amp import autocast
import torch.nn.functional as F
class LayerNorm2d(nn.LayerNorm):
def forward(self, x: torch.Tensor) -> torch.Tensor:
out = x - torch.mean(x, dim=1, keepdim=True)
out = out / torch.sqrt(torch.square(out).mean(dim=1, keepdim=True) + self.eps)
if self.elementwise_affine:
out = out * self.weight.view(1, -1, 1, 1) + self.bias.view(1, -1, 1, 1)
return out
REGISTERED_NORM_DICT: dict[str, type] = {
"bn2d": nn.BatchNorm2d,
"ln": nn.LayerNorm,
"ln2d": LayerNorm2d,
}
# register activation function here
REGISTERED_ACT_DICT: dict[str, type] = {
"relu": nn.ReLU,
"relu6": nn.ReLU6,
"hswish": nn.Hardswish,
"silu": nn.SiLU,
}
class FusedMBConv(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size=3,
stride=1,
mid_channels=None,
expand_ratio=6,
groups=1,
use_bias=False,
norm=("bn2d", "bn2d"),
act_func=("relu6", None),
):
super().__init__()
use_bias = val2tuple(use_bias, 2)
norm = val2tuple(norm, 2)
act_func = val2tuple(act_func, 2)
mid_channels = mid_channels or round(in_channels * expand_ratio)
self.spatial_conv = ConvLayer(
in_channels,
mid_channels,
kernel_size,
stride,
groups=groups,
use_bias=use_bias[0],
norm=norm[0],
act_func=act_func[0],
)
self.point_conv = ConvLayer(
mid_channels,
out_channels,
1,
use_bias=use_bias[1],
norm=norm[1],
act_func=act_func[1],
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.spatial_conv(x)
x = self.point_conv(x)
return x
class DSConv(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size=3,
stride=1,
use_bias=False,
norm=("bn2d", "bn2d"),
act_func=("relu6", None),
):
super(DSConv, self).__init__()
use_bias = val2tuple(use_bias, 2)
norm = val2tuple(norm, 2)
act_func = val2tuple(act_func, 2)
self.depth_conv = ConvLayer(
in_channels,
in_channels,
kernel_size,
stride,
groups=in_channels,
norm=norm[0],
act_func=act_func[0],
use_bias=use_bias[0],
)
self.point_conv = ConvLayer(
in_channels,
out_channels,
1,
norm=norm[1],
act_func=act_func[1],
use_bias=use_bias[1],
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.depth_conv(x)
x = self.point_conv(x)
return x
class MBConv(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size=3,
stride=1,
mid_channels=None,
expand_ratio=6,
use_bias=False,
norm=("bn2d", "bn2d", "bn2d"),
act_func=("relu6", "relu6", None),
):
super(MBConv, self).__init__()
use_bias = val2tuple(use_bias, 3)
norm = val2tuple(norm, 3)
act_func = val2tuple(act_func, 3)
mid_channels = mid_channels or round(in_channels * expand_ratio)
self.inverted_conv = ConvLayer(
in_channels,
mid_channels,
1,
stride=1,
norm=norm[0],
act_func=act_func[0],
use_bias=use_bias[0],
)
self.depth_conv = ConvLayer(
mid_channels,
mid_channels,
kernel_size,
stride=stride,
groups=mid_channels,
norm=norm[1],
act_func=act_func[1],
use_bias=use_bias[1],
)
self.point_conv = ConvLayer(
mid_channels,
out_channels,
1,
norm=norm[2],
act_func=act_func[2],
use_bias=use_bias[2],
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.inverted_conv(x)
x = self.depth_conv(x)
x = self.point_conv(x)
return x
class EfficientViTBlock(nn.Module):
def __init__(
self,
in_channels: int,
heads_ratio: float = 1.0,
dim=32,
expand_ratio: float = 4,
norm="bn2d",
act_func="hswish",
):
super(EfficientViTBlock, self).__init__()
self.context_module = ResidualBlock(
LiteMLA(
in_channels=in_channels,
out_channels=in_channels,
heads_ratio=heads_ratio,
dim=dim,
norm=(None, norm),
),
IdentityLayer(),
)
local_module = MBConv(
in_channels=in_channels,
out_channels=in_channels,
expand_ratio=expand_ratio,
use_bias=(True, True, False),
norm=(None, None, norm),
act_func=(act_func, act_func, None),
)
self.local_module = ResidualBlock(local_module, IdentityLayer())
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.context_module(x)
x = self.local_module(x)
return x
class ResBlock(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size=3,
stride=1,
mid_channels=None,
expand_ratio=1,
use_bias=False,
norm=("bn2d", "bn2d"),
act_func=("relu6", None),
):
super().__init__()
use_bias = val2tuple(use_bias, 2)
norm = val2tuple(norm, 2)
act_func = val2tuple(act_func, 2)
mid_channels = mid_channels or round(in_channels * expand_ratio)
self.conv1 = ConvLayer(
in_channels,
mid_channels,
kernel_size,
stride,
use_bias=use_bias[0],
norm=norm[0],
act_func=act_func[0],
)
self.conv2 = ConvLayer(
mid_channels,
out_channels,
kernel_size,
1,
use_bias=use_bias[1],
norm=norm[1],
act_func=act_func[1],
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.conv1(x)
x = self.conv2(x)
return x
class LiteMLA(nn.Module):
r"""Lightweight multi-scale linear attention"""
def __init__(
self,
in_channels: int,
out_channels: int,
heads: int or None = None,
heads_ratio: float = 1.0,
dim=8,
use_bias=False,
norm=(None, "bn2d"),
act_func=(None, None),
kernel_func="relu6",
scales: tuple[int, ...] = (5,),
eps=1.0e-15,
):
super(LiteMLA, self).__init__()
self.eps = eps
heads = heads or int(in_channels // dim * heads_ratio)
total_dim = heads * dim
use_bias = val2tuple(use_bias, 2)
norm = val2tuple(norm, 2)
act_func = val2tuple(act_func, 2)
self.dim = dim
self.qkv = ConvLayer(
in_channels,
3 * total_dim,
1,
use_bias=use_bias[0],
norm=norm[0],
act_func=act_func[0],
)
self.aggreg = nn.ModuleList(
[
nn.Sequential(
nn.Conv2d(
3 * total_dim,
3 * total_dim,
scale,
padding=get_same_padding(scale),
groups=3 * total_dim,
bias=use_bias[0],
),
nn.Conv2d(3 * total_dim, 3 * total_dim, 1, groups=3 * heads, bias=use_bias[0]),
)
for scale in scales
]
)
self.kernel_func = build_act(kernel_func, inplace=False)
self.proj = ConvLayer(
total_dim * (1 + len(scales)),
out_channels,
1,
use_bias=use_bias[1],
norm=norm[1],
act_func=act_func[1],
)
@autocast(enabled=False)
def relu_linear_att(self, qkv: torch.Tensor) -> torch.Tensor:
B, _, H, W = list(qkv.size())
if qkv.dtype == torch.float16:
qkv = qkv.float()
qkv = torch.reshape(
qkv,
(
B,
-1,
3 * self.dim,
H * W,
),
)
qkv = torch.transpose(qkv, -1, -2)
q, k, v = (
qkv[..., 0 : self.dim],
qkv[..., self.dim : 2 * self.dim],
qkv[..., 2 * self.dim :],
)
# lightweight linear attention
q = self.kernel_func(q)
k = self.kernel_func(k)
# linear matmul
trans_k = k.transpose(-1, -2)
v = F.pad(v, (0, 1), mode="constant", value=1)
kv = torch.matmul(trans_k, v)
out = torch.matmul(q, kv)
out = torch.clone(out)
out = out[..., :-1] / (out[..., -1:] + self.eps)
out = torch.transpose(out, -1, -2)
out = torch.reshape(out, (B, -1, H, W))
return out
def forward(self, x: torch.Tensor) -> torch.Tensor:
# generate multi-scale q, k, v
qkv = self.qkv(x)
multi_scale_qkv = [qkv]
device, types = qkv.device, qkv.dtype
for op in self.aggreg:
if device.type == 'cuda' and types == torch.float32:
qkv = qkv.to(torch.float16)
x1 = op(qkv)
multi_scale_qkv.append(x1)
multi_scale_qkv = torch.cat(multi_scale_qkv, dim=1)
out = self.relu_linear_att(multi_scale_qkv)
out = self.proj(out)
return out
@staticmethod
def configure_litemla(model: nn.Module, **kwargs) -> None:
eps = kwargs.get("eps", None)
for m in model.modules():
if isinstance(m, LiteMLA):
if eps is not None:
m.eps = eps
def build_kwargs_from_config(config: dict, target_func: callable) -> dict[str, any]:
valid_keys = list(signature(target_func).parameters)
kwargs = {}
for key in config:
if key in valid_keys:
kwargs[key] = config[key]
return kwargs
def build_norm(name="bn2d", num_features=None, **kwargs) -> nn.Module or None:
if name in ["ln", "ln2d"]:
kwargs["normalized_shape"] = num_features
else:
kwargs["num_features"] = num_features
if name in REGISTERED_NORM_DICT:
norm_cls = REGISTERED_NORM_DICT[name]
args = build_kwargs_from_config(kwargs, norm_cls)
return norm_cls(**args)
else:
return None
def get_same_padding(kernel_size: int or tuple[int, ...]) -> int or tuple[int, ...]:
if isinstance(kernel_size, tuple):
return tuple([get_same_padding(ks) for ks in kernel_size])
else:
assert kernel_size % 2 > 0, "kernel size should be odd number"
return kernel_size // 2
def build_act(name: str, **kwargs) -> nn.Module or None:
if name in REGISTERED_ACT_DICT:
act_cls = REGISTERED_ACT_DICT[name]
args = build_kwargs_from_config(kwargs, act_cls)
return act_cls(**args)
else:
return None
class ConvLayer(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size=3,
stride=1,
dilation=1,
groups=1,
use_bias=False,
dropout=0,
norm="bn2d",
act_func="relu",
):
super(ConvLayer, self).__init__()
padding = get_same_padding(kernel_size)
padding *= dilation
self.dropout = nn.Dropout2d(dropout, inplace=False) if dropout > 0 else None
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=(kernel_size, kernel_size),
stride=(stride, stride),
padding=padding,
dilation=(dilation, dilation),
groups=groups,
bias=use_bias,
)
self.norm = build_norm(norm, num_features=out_channels)
self.act = build_act(act_func)
def forward(self, x: torch.Tensor) -> torch.Tensor:
if self.dropout is not None:
x = self.dropout(x)
device, type = x.device, x.dtype
choose = False
if device.type == 'cuda' and type == torch.float32:
x = x.to(torch.float16)
choose = True
x = self.conv(x)
if self.norm:
x = self.norm(x)
if self.act:
x = self.act(x)
if choose:
x = x.to(torch.float16)
return x
class IdentityLayer(nn.Module):
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x
class OpSequential(nn.Module):
def __init__(self, op_list: list[nn.Module or None]):
super(OpSequential, self).__init__()
valid_op_list = []
for op in op_list:
if op is not None:
valid_op_list.append(op)
self.op_list = nn.ModuleList(valid_op_list)
def forward(self, x: torch.Tensor) -> torch.Tensor:
for op in self.op_list:
x = op(x)
return x
class EfficientViTBackbone(nn.Module):
def __init__(
self,
width_list: list[int],
depth_list: list[int],
in_channels=3,
dim=32,
expand_ratio=4,
norm="ln2d",
act_func="hswish",
) -> None:
super().__init__()
self.width_list = []
# input stem
self.input_stem = [
ConvLayer(
in_channels=3,
out_channels=width_list[0],
stride=2,
norm=norm,
act_func=act_func,
)
]
for _ in range(depth_list[0]):
block = self.build_local_block(
in_channels=width_list[0],
out_channels=width_list[0],
stride=1,
expand_ratio=1,
norm=norm,
act_func=act_func,
)
self.input_stem.append(ResidualBlock(block, IdentityLayer()))
in_channels = width_list[0]
self.input_stem = OpSequential(self.input_stem)
self.width_list.append(in_channels)
# stages
self.stages = []
for w, d in zip(width_list[1:3], depth_list[1:3]):
stage = []
for i in range(d):
stride = 2 if i == 0 else 1
block = self.build_local_block(
in_channels=in_channels,
out_channels=w,
stride=stride,
expand_ratio=expand_ratio,
norm=norm,
act_func=act_func,
)
block = ResidualBlock(block, IdentityLayer() if stride == 1 else None)
stage.append(block)
in_channels = w
self.stages.append(OpSequential(stage))
self.width_list.append(in_channels)
for w, d in zip(width_list[3:], depth_list[3:]):
stage = []
block = self.build_local_block(
in_channels=in_channels,
out_channels=w,
stride=2,
expand_ratio=expand_ratio,
norm=norm,
act_func=act_func,
fewer_norm=True,
)
stage.append(ResidualBlock(block, None))
in_channels = w
for _ in range(d):
stage.append(
EfficientViTBlock(
in_channels=in_channels,
dim=dim,
expand_ratio=expand_ratio,
norm=norm,
act_func=act_func,
)
)
self.stages.append(OpSequential(stage))
self.width_list.append(in_channels)
self.stages = nn.ModuleList(self.stages)
@staticmethod
def build_local_block(
in_channels: int,
out_channels: int,
stride: int,
expand_ratio: float,
norm: str,
act_func: str,
fewer_norm: bool = False,
) -> nn.Module:
if expand_ratio == 1:
block = DSConv(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
use_bias=(True, False) if fewer_norm else False,
norm=(None, norm) if fewer_norm else norm,
act_func=(act_func, None),
)
else:
block = MBConv(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
expand_ratio=expand_ratio,
use_bias=(True, True, False) if fewer_norm else False,
norm=(None, None, norm) if fewer_norm else norm,
act_func=(act_func, act_func, None),
)
return block
def forward(self, x: torch.Tensor) -> dict[str, torch.Tensor]:
outputs = []
for stage_id, stage in enumerate(self.stages):
x = stage(x)
if x.device.type == 'cuda':
x = x.to(torch.float16)
outputs.append(x)
return outputs
def efficientvit_backbone_b0(**kwargs) -> EfficientViTBackbone:
backbone = EfficientViTBackbone(
width_list=[3, 16, 32, 64, 128],
depth_list=[1, 2, 2, 2, 2],
dim=16,
**build_kwargs_from_config(kwargs, EfficientViTBackbone),
)
return backbone
def efficientvit_backbone_b1(**kwargs) -> EfficientViTBackbone:
backbone = EfficientViTBackbone(
width_list=[3, 32, 64, 128, 256],
depth_list=[1, 2, 3, 3, 4],
dim=16,
**build_kwargs_from_config(kwargs, EfficientViTBackbone),
)
return backbone
def efficientvit_backbone_b2(**kwargs) -> EfficientViTBackbone:
backbone = EfficientViTBackbone(
width_list=[3, 48, 96, 192, 384],
depth_list=[1, 3, 4, 4, 6],
dim=32,
**build_kwargs_from_config(kwargs, EfficientViTBackbone),
)
return backbone
def efficientvit_backbone_b3(**kwargs) -> EfficientViTBackbone:
backbone = EfficientViTBackbone(
width_list=[3, 64, 128, 256, 512],
depth_list=[1, 4, 6, 6, 9],
dim=32,
**build_kwargs_from_config(kwargs, EfficientViTBackbone),
)
return backbone
四、手把手教你添加EfficienViT网络结构
这个主干的网络结构添加起来算是所有的改进机制里最麻烦的了,因为有一些网略结构可以用yaml文件搭建出来,有一些网络结构其中的一些细节根本没有办法用yaml文件去搭建,用yaml文件去搭建会损失一些细节部分(而且一个网络结构设计很多细节的结构修改方式都不一样,一个一个去修改大家难免会出错),所以这里让网络直接返回整个网络,然后修改部分 yolo代码以后就都以这种形式添加了,以后我提出的网络模型基本上都会通过这种方式修改,我也会进行一些模型细节改进。创新出新的网络结构大家直接拿来用就可以的。下面开始添加教程->
(同时每一个后面都有代码,大家拿来复制粘贴替换即可,但是要看好了不要复制粘贴替换多了)
修改一
我们复制网络结构代码到“ultralytics/nn/modules”目录下创建一个py文件复制粘贴进去 ,我这里起的名字是EfficientV2。

修改二
找到如下的文件"ultralytics/nn/tasks.py" 在开始的部分导入我们的模型如下图。

from .modules.EfficientV2 import efficientvit_backbone_b0,efficientvit_backbone_b1,efficientvit_backbone_b2,efficientvit_backbone_b3修改三?
添加如下一行代码

修改四
找到七百多行大概把具体看图片,按照图片来修改就行,添加红框内的部分,注意没有()只是函数名。

elif m in {efficientvit_backbone_b0, efficientvit_backbone_b1, efficientvit_backbone_b2, efficientvit_backbone_b3}:
m = m()
c2 = m.width_list # 返回通道列表
backbone = True修改五?
下面的两个红框内都是需要改动的。?
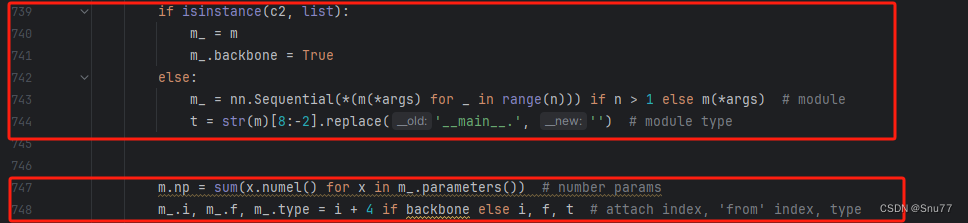
if isinstance(c2, list):
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, type修改六?
如下的也需要修改,全部按照我的来。

代码如下把原先的代码替换了即可。?
save.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
if len(c2) != 5:
ch.insert(0, 0)
else:
ch.append(c2)修改七
修改七和前面的都不太一样,需要修改前向传播中的一个部分,?已经离开了parse_model方法了。
可以在图片中开代码行数,没有离开task.py文件都是同一个文件。 同时这个部分有好几个前向传播都很相似,大家不要看错了,是70多行左右的!!!,同时我后面提供了代码,大家直接复制粘贴即可,有时间我针对这里会出一个视频。

代码如下->
def _predict_once(self, x, profile=False, visualize=False):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
if len(x) != 5: # 0 - 5
x.insert(0, None)
for index, i in enumerate(x):
if index in self.save:
y.append(i)
else:
y.append(None)
x = x[-1] # 最后一个输出传给下一层
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x到这里就完成了修改部分,但是这里面细节很多,大家千万要注意不要替换多余的代码,导致报错,也不要拉下任何一部,都会导致运行失败,而且报错很难排查!!!很难排查!!!?
五、EfficientViT2023yaml文件
复制如下yaml文件进行运行!!!?
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, efficientvit_backbone_b0, []] # 4
- [-1, 1, SPPF, [1024, 5]] # 5
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6
- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4
- [-1, 3, C2f, [512]] # 8
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9
- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3
- [-1, 3, C2f, [256]] # 11 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] # 12
- [[-1, 8], 1, Concat, [1]] # 13 cat head P4
- [-1, 3, C2f, [512]] # 14 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 15
- [[-1, 5], 1, Concat, [1]] # 16 cat head P5
- [-1, 3, C2f, [1024]] # 17 (P5/32-large)
- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
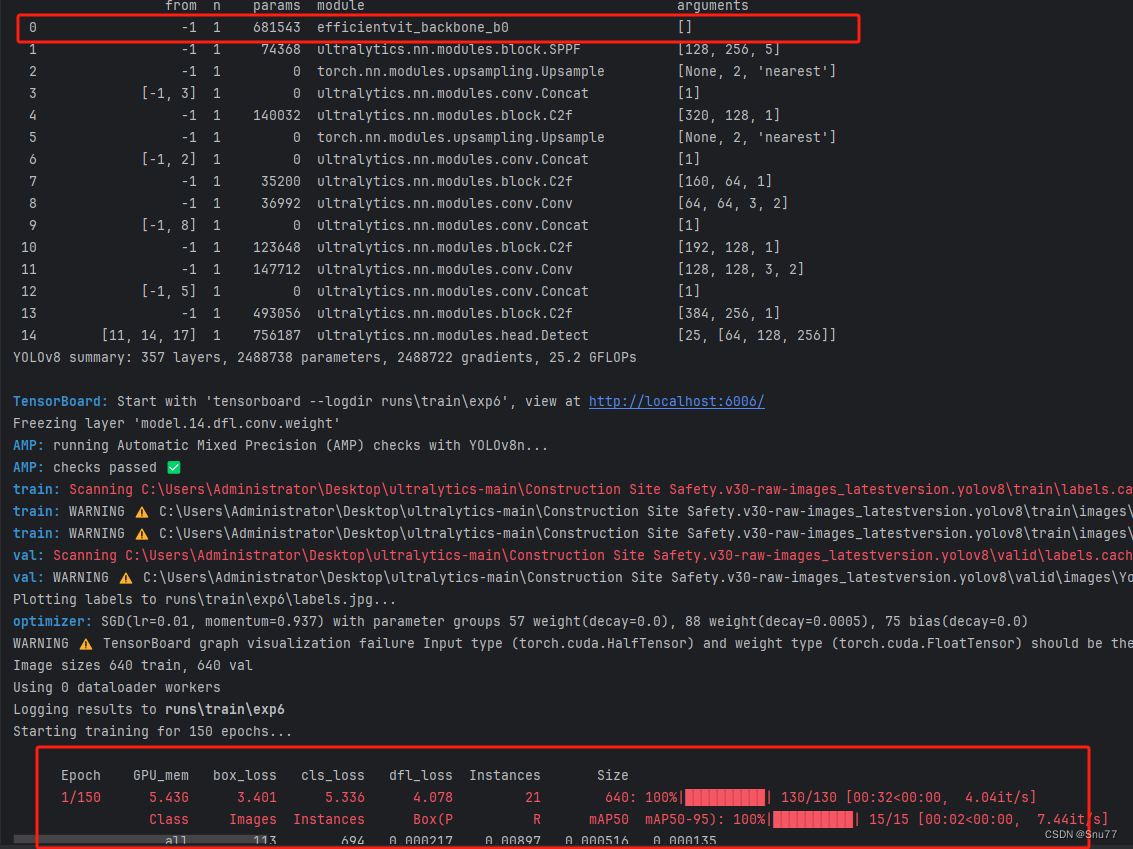
六、成功运行记录?
下面是成功运行的截图,已经完成了有1个epochs的训练,图片太大截不全第2个epochs了。?
七、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!