数据库分区分表
分区分表
为什么要分库分表
软件时代,传统应用都有这样一个特点:访问量、数据量都比较小,单库单表都完全可以支撑整个业务。随着互联网的发展和用户规模的迅速扩大,对系统的要求也越来越高。因此传统的MySQL单库单表架构的性能问题就暴露出来了。而有下面几个因素会影响数据库性能:
- 数据量
MySQL单库数据量在5000万以内性能比较好,超过阈值后性能会随着数据量的增大而变弱。MySQL单表的数据量是500w-1000w之间性能比较好,超过1000w性能也会下降。
- 磁盘
因为单个服务的磁盘空间是有限制的,如果并发压力下,所有的请求都访问同一个节点,肯定会对磁盘IO造成非常大的影响。
- 数据库连接
数据库连接是非常稀少的资源,如果一个库里既有用户、商品、订单相关的数据,当海量用户同时操作时,数据库连接就很可能成为瓶颈。
为了提升性能,所以我们必须要解决上述几个问题,那就有必要引进分库分表,当然除了分库分表,还有别的解决方案,就是NoSQL和NewSQL,NoSQL主要是MongoDB等,NewSQL则以TiDB为代表。
分库分表有垂直切分和水平切分两种。
垂直切分(按照功能模块)
? 将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数据库 workDB、商品数据库 payDB、用户数据库 userDB、日志数据库 logDB 等,分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
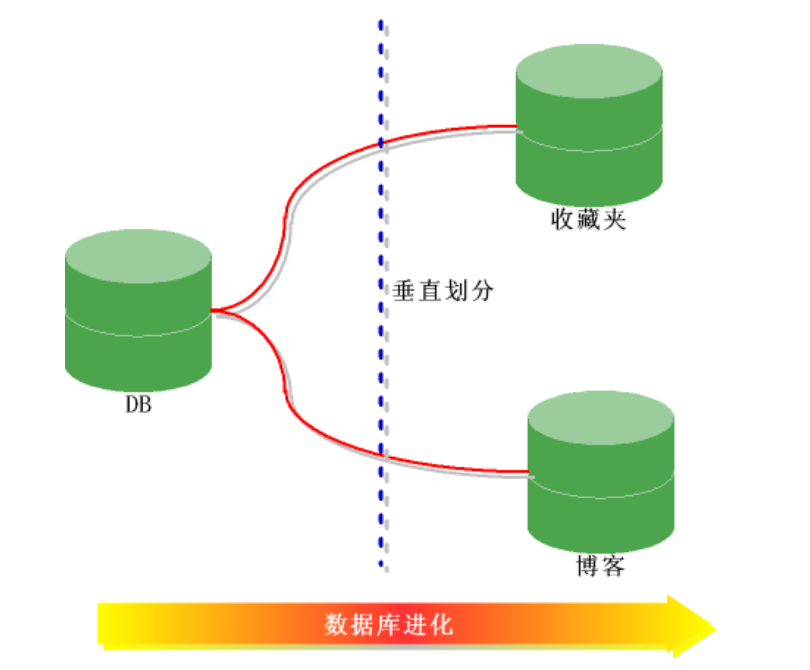
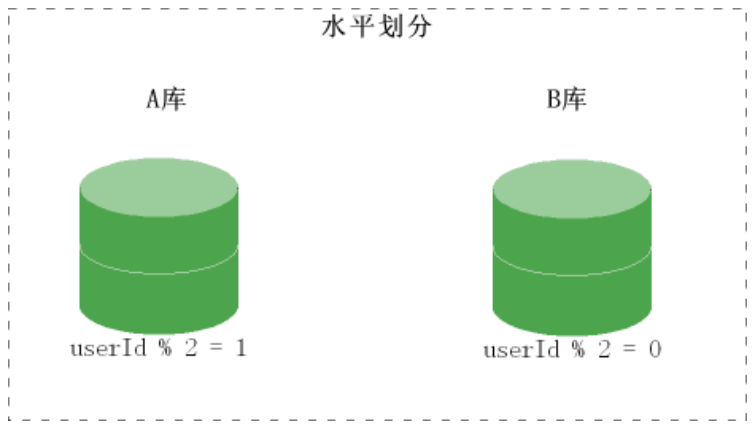
水平切分(按照规则划分存储)
? 当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如 userID 散列,进行划分,然后存储到多个结构相同的表,和不同的库上。
分库分表常用中间件
目前应用比较多的基本有以下几种,
-
TDDL
-
Sharding-jdbc
-
Mycat
-
Cobar
TDDL
淘宝团队开发的,属于 client 层方案。支持基本的 crud 语法和读写分离,但不支持 join、多表查询等语法。
Sharding-jdbc
当当开源的,属于 client 层方案,目前已经更名为 ShardingSphere。SQL 语法支持也比较多,没有太多限制,支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务)。
Cobar
阿里 b2b 团队开发和开源的,属于 proxy 层方案,就是介于应用服务器和数据库服务器之间。应用程序通过 JDBC 驱动访问 Cobar 集群,Cobar 根据 SQL 和分库规则对 SQL 做分解,然后分发到 MySQL 集群不同的数据库实例上执行。
Mycat
基于 Cobar 改造的,属于 proxy 层方案,支持的功能完善,社区活跃。
常见分表、分库常用策略
-
平均进行分配hash(object)%N(适用于简单架构)。
-
按照权重进行分配且均匀轮询。
-
按照业务进行分配。
-
按照一致性hash算法进行分配(适用于集群架构,在集群中节点的添加和删除不会造成数据丢失,方便数据迁移)。
全局ID生成策略
自动增长列
优点:数据库自带功能,有序,性能佳。缺点:单库单表无妨,分库分表时如果没有规划,ID可能重复。
解决方案,一个是设置自增偏移和步长。
-
假设总共有 10 个分表
-
级别可选: SESSION(会话级), GLOBAL(全局)
-
SET @@SESSION.autoincrementoffset = 1; ## 起始值, 分别取值为 1~10
-
SET @@SESSION.autoincrementincrement = 10; ## 步长增量
如果采用该方案,在扩容时需要迁移已有数据至新的所属分片。
另一个是全局ID映射表。
-
在全局 Redis 中为每张数据表创建一个 ID 的键,记录该表当前最大 ID;
-
每次申请 ID 时,都自增 1 并返回给应用;
-
Redis 要定期持久至全局数据库。
UUID(128位)
在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。通常平台会提供生成UUID的API。
UUID 由4个连字号(-)将32个字节长的字符串分隔后生成的字符串,总共36个字节长。形如:550e8400-e29b-41d4-a716-446655440000。
UUID 的计算因子包括:以太网卡地址、纳秒级时间、芯片ID码和许多可能的数字。UUID 是个标准,其实现有几种,最常用的是微软的 GUID(Globals Unique Identifiers)。
-
优点:简单,全球唯一;
-
缺点:存储和传输空间大,无序,性能欠佳。
COMB(组合)
组合 GUID(10字节) 和时间(6字节),达到有序的效果,提高索引性能。
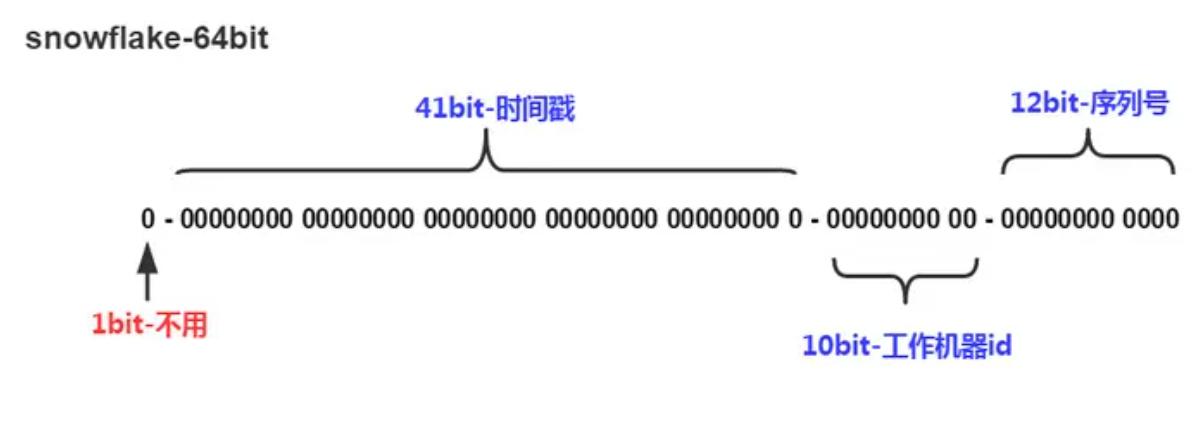
Snowflake(雪花) 算法
Snowflake 是 Twitter 开源的分布式 ID 生成算法,其结果为 long(64bit) 的数值。其特性是各节点无需协调、按时间大致有序、且整个集群各节点单不重复。该数值的默认组成如下(符号位之外的三部分允许个性化调整):
-
1bit: 符号位,总是 0(为了保证数值是正数)。
-
41bit: 毫秒数(可用 69 年);
-
10bit: 节点ID(5bit数据中心 + 5bit节点ID,支持 32 * 32 = 1024 个节点)
-
12bit: 流水号(每个节点每毫秒内支持 4096 个 ID,相当于 409万的 QPS,相同时间内如 ID 遇翻转,则等待至下一毫秒)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!