【LLM 论文阅读】NEFTU N E: LLM微调的免费午餐
指令微调的局限性
指令微调对于训练llm的能力至关重要,而模型的有用性在很大程度上取决于我们从小指令数据集中获得最大信息的能力。在本文中,我们提出在微调正向传递的过程中,在训练数据的嵌入向量中添加随机噪声,论文实验显示这个简单的技巧可以提高指令微调的效果,通常有很大的优势,而不需要额外的计算或数据开销。
NEFTune虽然简单,但对下游的会话质量有很大的影响。当像LLaMA-2-7B这样的原始LLM被噪声嵌入所微调时,AlpacaEval从29.8%提高到64.7%(图1),令人印象深刻地提高了约35个百分点。NEFTune可以实现在会话任务上惊人的性能跳跃,同时在事实问题回答基线上保持性能,这种技术似乎是LLM微调的免费午餐。

代码仓库:https://github.com/neelsjain/NEFTune
论文链接:https://arxiv.org/abs/2310.05914
NEFTune原理
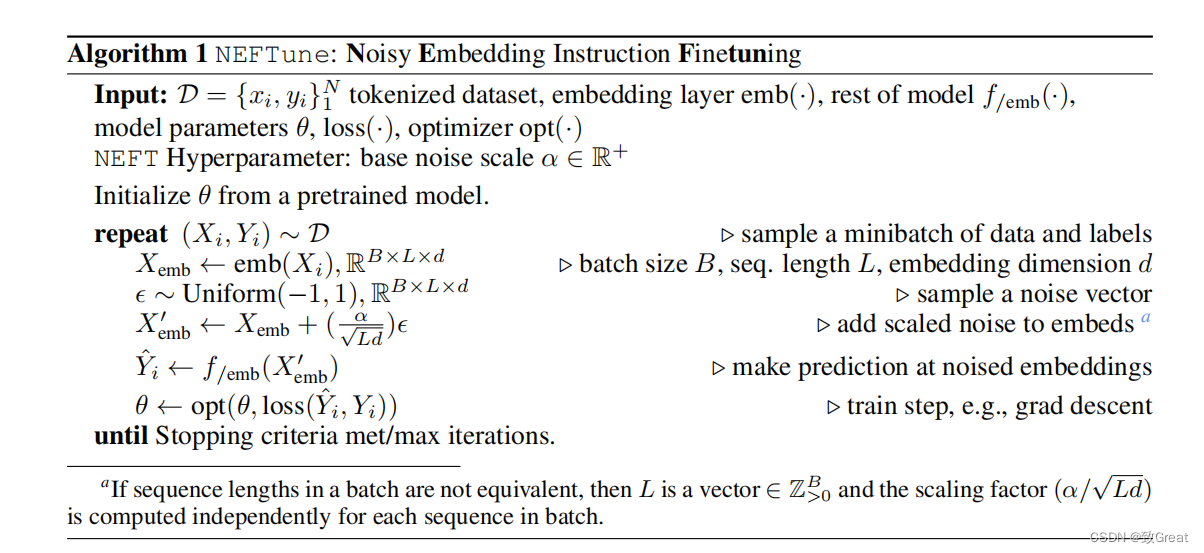
指令模型是在由指令和响应对组成的数据集上进行训练的。
NEFTune的每一步都首先从数据集中采样一条指令,并将其标记转换为嵌入向量。
然后,NEFTune通过向嵌入中添加一个随机噪声向量来脱离标准训练。
噪声通过采样iid均匀分布产生,每个样本都在范围内[?1,1],然后将整个噪声向量缩放为
α
/
L
d
α/\sqrt{Ld}
α/Ld?,其中L为序列长度,d为嵌入维数,α为可调参数。
for step_count in range(start_step_count, args.max_steps):
train_loss = 0
for _ in range(accumulation_steps):
try:
data = next(epoch_iterator)
except StopIteration:
sampler.set_epoch(sampler.epoch + 1)
dataloader = dataloader_full
epoch_iterator = iter(dataloader)
data = next(epoch_iterator)
if args.neftune_alpha is not None:
if isinstance(model, torch.distributed.fsdp.fully_sharded_data_parallel.FullyShardedDataParallel):
embed_device = model._fsdp_wrapped_module.model.embed_tokens.weight.device
embeds_init = model._fsdp_wrapped_module.model.embed_tokens.forward(data['input_ids'].to(embed_device))
### add noise to embeds
input_mask = data['attention_mask'].to(embeds_init) # B x L
input_lengths = torch.sum(input_mask, 1) # B
noise_ = torch.zeros_like(embeds_init).uniform_(-1,1)
delta = noise_ * input_mask.unsqueeze(2)
dims = input_lengths * embeds_init.size(-1)
mag = args.neftune_alpha / torch.sqrt(dims)
delta = (delta * mag.view(-1, 1, 1)).detach()
data['inputs_embeds'] = delta + embeds_init
data['input_ids'] = None
### add noise to embeds
out = model(**data)
(out.loss/accumulation_steps).backward()
train_loss += out.loss.item()/accumulation_steps
model.clip_grad_norm_(args.max_grad_norm
实验结果
- NEFTune提高了文本质量

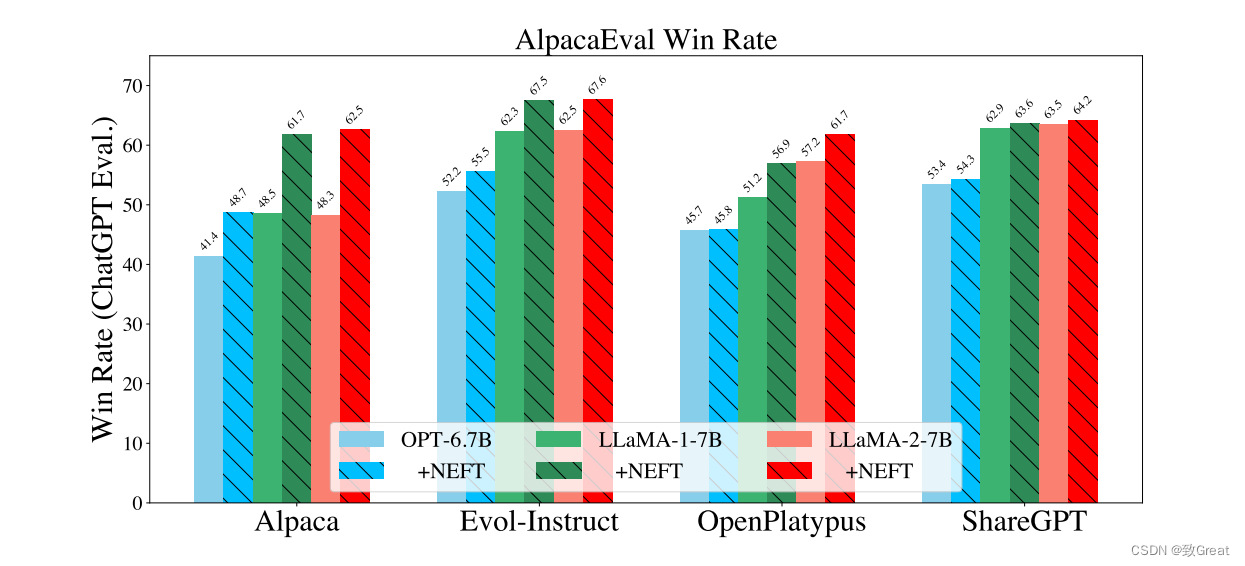
从表1中,我们可以看到7B尺度的所有数据集的增加,平均增加了15.1%,这表明NEFT训练显著提高了对话能力和回答质量。此外,我们可以从图2中看到,我们也看到了对旧模型的改进,如LLaMA-1和OPT。有趣的是,根据ChatGPT,我们看到ShareGPT的改进不如其他数据集改进。然而,这并没有反映在GPT-4的评估中。
从表2中我们可以看到,在NEFTune加入70B参数模型后,WinRate从75.03%上升到88.81%(+13.78%)
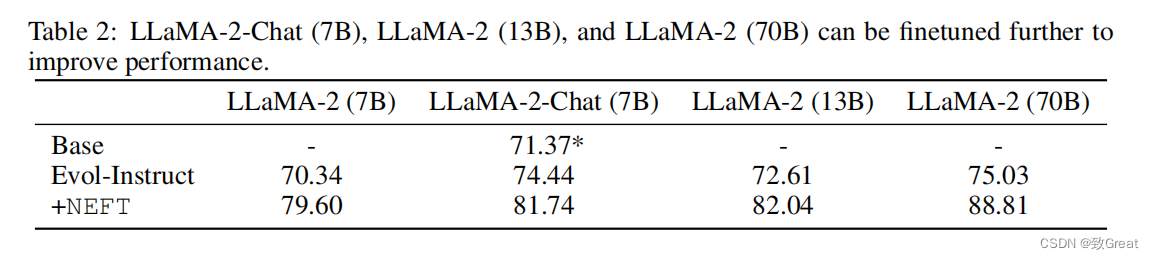
- NEFTune可以改进Chat模型
从表2中,我们可以看到,在Evol-指令上进一步对LLaMA-2 Chat进行微调(7B)可以将LLaMA-2聊天的性能提高3%。这个模型已经被广泛地调整了,使用了多轮的RLHF。然而,在NEFTune中,我们看到了相当大的额外性能增长10%,尽管我们注意到这个检查点模型的一些功能可能会受到影响,比如它避免输出有毒行为的能力。
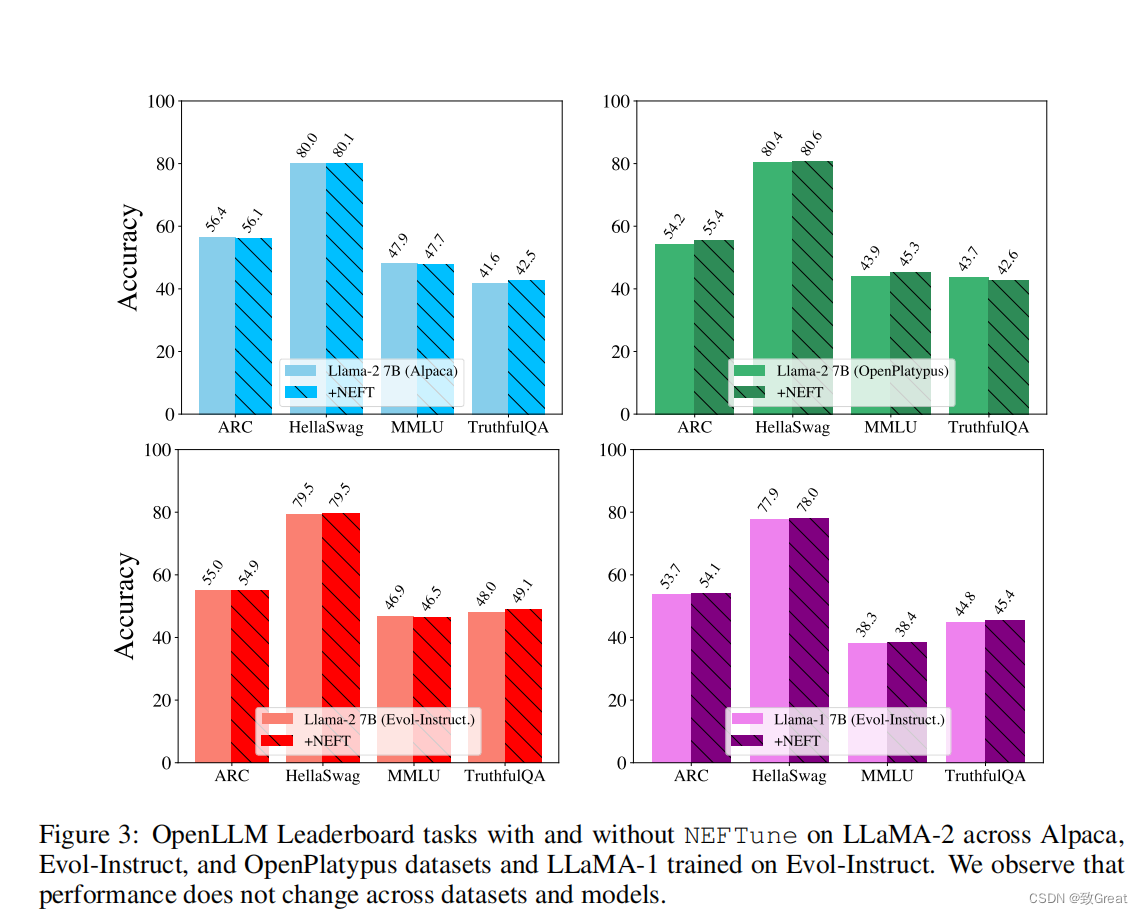
- 基础能力的影响
一个潜在的担忧是,NEFTune会牺牲其他能力为代价来提高会话能力,但是比较微小。我们评估了OpenLLM排行榜任务,使用LMEval利用MMLU、ARC、HellaSwag和真实QA。这些基准让我们得以评测模型知识、推理和真实性。图3显示了分数保持稳定,NEFTune保留了模型功能。
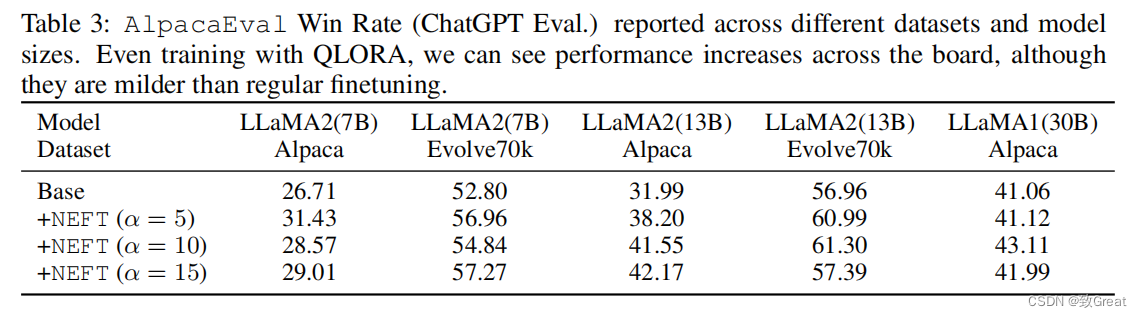
- NEFTune对QLORA有效
论文表明,NEFTune还通过使用量化低等级适配器(QLORA)进行训练,提高了在受限资源环境下的性能。对于30B,论文将有效批处理规模增加一倍,并将学习率提高一半。表3显示,当使用QLORA进行训练时,在所有研究的模型大小和数据集中,空间性能都有所提高。然而,性能的提高没有全面微调的明显。这可能是因为需要不同的超参数(即微调周期的数量),或者因为量化到4位。
- 一个定性的例子
在这里,论文展示了一个来自LLaMA-2的含NEFT的羊驼的定性例子。我们从这个例子中可以看到,羊驼产生的回复更短,只给出了量子计算的一个非常基本的定义,提到了量子位元、叠加、纠缠和增加的复杂计算。在Alpaca-NEFT回复中,该模型提供了一个更流畅的答案,对这些主题,更清晰的解释了叠加和量子纠缠,并提到了潜在的应用。我们认为这个例子代表了由NEFT引起的各种变化。

结论
NEFTune的成功指出了算法和正则化器在LLM训练中的重要性被忽视。与多年来一直在研究正则化和过拟合的计算机视觉社区不同,LLM社区倾向于使用标准化的训练循环,而不是泛化。在这种环境下,LLM的研究人员已经专注于数据集和模型缩放作为前进的主要路径。考虑到NEFTune的一致性收益,以及在小指令数据集上的过拟合的倾向,似乎正则化值得在LLM设置中重新加入。
论文的研究有几个局限性:
- 采用AlpacaEval作为llm教学遵循能力的中心指标,它受到单一法官(GPT-4)偏见的影响。
- 此外,由于有限的计算资源,无法验证在多个数据集的更大的70B变体上的成功,不得不对大多数NEFTune运行依赖固定的超参数,而不是扫描。
- 最后,尽管我们进行了实证研究,但我们尚未确定NEFTune工作的原因。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!