【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(2) -重启策略与手动恢复
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
本文介绍了Flink 在程序中设置重启策略、手动重启查看checkpoint的state恢复以及通过savepoint手动恢复,其中包含详细的验证步骤与验证结果。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本文依赖hadoop环境、kafka环境、flink集群环境好用。
本专题分为以下几篇文章:
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(1) - checkpoint配置及实现
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(2) -重启策略与手动恢复
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例 - 完整版
关于Flink checkpoint的更多介绍参考文章:
9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
三、示例:程序中设置重启策略
本示例是将数据sink到kafka中,因flink在kafka的实现过程中出现不同的版本,故本示例给出了2个不同的版本实现。
1、演示代码
该代码包含四种重启策略,根据自己的情况进行验证即可。
本示例着重验证了固定次数重启策略。
2、maven依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
3、实现(Flink 1.13.6版本)
1)、序列化
package org.datastreamapi.checkpoint.serialization;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
* @author alanchan
*
*/
/**
* kafka sink tuple的序列化实现
*
* @author alanchan
*
*/
public class AlanKafkaSerializationSchema_Tuple implements KafkaSerializationSchema<Tuple2<String, Integer>> {
String topic;
public AlanKafkaSerializationSchema_Tuple(String topic) {
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(Tuple2<String, Integer> element, Long timestamp) {
return new ProducerRecord(topic, (element.f0 + ":" + element.f1).getBytes());
}
}
2)、实现
package org.datastreamapi.checkpoint;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import org.datastreamapi.checkpoint.serialization.AlanKafkaSerializationSchema_Tuple;
/**
* @author alanchan
*
*/
public class TestCheckpointRestartStrategyDemo {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "alanchan");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// checkpoint
env.enableCheckpointing(1000);
env.setStateBackend(new FsStateBackend("hdfs://server1:8020//flinktest/flinkckp"));
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 配置重启策略:
// 1、配置了Checkpoint的情况下,默认是Integer.MAX_VALUE次重启并自动恢复
// 2、单独配置无重启策略RestartStrategies.noRestart()
// 3、固定延迟重启RestartStrategies.fixedDelayRestart
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, // 最多重启3次数
Time.of(5, TimeUnit.SECONDS) // 重启时间间隔
));
// 4、失败率重启策略RestartStrategies.failureRateRestart
// 如果2分钟内job失败不超过3三次,,自动重启,, 每次间隔10s (如果2分钟内程序失败超过(含)3次,则程序退出)
// env.setRestartStrategy(RestartStrategies.failureRateRestart(3, // 每个测量时间间隔最大失败次数
// Time.of(2, TimeUnit.MINUTES), // 失败率测量的时间间隔
// Time.of(10, TimeUnit.SECONDS) // 两次连续重启的时间间隔
// ));
// Source
DataStream<String> linesDS = env.socketTextStream("192.168.10.42", 9999);
// Transformation
DataStream<Tuple2<String, Integer>> wordTuple = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(",");
for (String word : words) {// vx:alanchanchn
if (word.equals("vx:alanchanchn")) {
System.out.println("出现了敏感词。。。。。。。。。。不能出现微信号:alanchanchn。");
throw new Exception("出现了敏感词。。。。。。。。。。。不能出现微信号:alanchanchn。");
}
out.collect(Tuple2.of(word, 1));
}
}
});
DataStream<Tuple2<String, Integer>> sumResult = wordTuple.keyBy(t -> t.f0).sum(1);
// sink
sumResult.print();
Properties props = new Properties();
props.setProperty("bootstrap.servers", "server1:9092");
props.setProperty("transaction.timeout.ms", "3000");
String topic = "t_kafkasink";
// FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("flink_kafka", new SimpleStringSchema(), props);
FlinkKafkaProducer<Tuple2<String, Integer>> kafkaSink = new FlinkKafkaProducer<>(topic, new AlanKafkaSerializationSchema_Tuple(topic), props,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
sumResult.addSink(kafkaSink);
// 5.execute
env.execute();
}
}
3)、验证
验证实际上分为3部分,即应用程序控制台、kafka输出和hdfs上的checkpoint。
由于本示例仅仅是为了演示重启策略,故其他的两个部分不再赘述。
5> (alanchan,1)
5> (alanchanchn,1)
5> (alanchan,2)
13> (alan,1)
5> (chan,1)
11> (chn,1)
出现了敏感词。。。。。。。。。。不能出现微信号。
11> (chn,2)
5> (alanchan,3)
5> (alanchanchn,2)
11> (chn,2)
10> (vx:alanchanchn,1)
5> (alanchan,3)
5> (alanchanchn,2)
出现了敏感词。。。。。。。。。。不能出现微信号。
11> (chn,3)
5> (alanchan,4)
5> (alanchanchn,3)
出现了敏感词。。。。。。。。。。不能出现微信号。
出现了敏感词。。。。。。。。。。不能出现微信号。
5> (alanchan,4)
11> (chn,3)
5> (alanchanchn,3)
Exception in thread "main" org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
# 应用程序出现了异常并退出
4、实现(Flink 1.17.0版本)
1)、序列化
package org.datastreamapi.checkpoint.serialization;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.java.tuple.Tuple2;
/**
* @author alanchan
*
*/
public class KafkaValueSerializationSchema_Tuple implements SerializationSchema<Tuple2<String, Integer>> {
@Override
public byte[] serialize(Tuple2<String, Integer> element) {
return (element.f0 + ":" + element.f1).getBytes();
}
}
2)、实现
package org.datastreamapi.checkpoint;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import org.datastreamapi.checkpoint.serialization.AlanKafkaSerializationSchema_Tuple;
import org.datastreamapi.checkpoint.serialization.KafkaValueSerializationSchema_Tuple;
/**
* @author alanchan
*
*/
public class TestCheckpointRestartStrategyDemo2 {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "alanchan");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// checkpoint
env.enableCheckpointing(1000);
env.setStateBackend(new FsStateBackend("hdfs://server1:8020//flinktest/flinkckp"));
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, // 最多重启3次数
Time.of(5, TimeUnit.SECONDS) // 重启时间间隔
));
// Source
DataStream<String> linesDS = env.socketTextStream("192.168.10.42", 9999);
// Transformation
DataStream<Tuple2<String, Integer>> wordTuple = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(",");
for (String word : words) {// vx:alanchanchn
if (word.equals("vx:alanchanchn")) {
System.out.println("出现了敏感词。。。。。。。。。。不能出现微信号:alanchanchn。");
throw new Exception("出现了敏感词。。。。。。。。。。。不能出现微信号:alanchanchn。");
}
out.collect(Tuple2.of(word, 1));
}
}
});
DataStream<Tuple2<String, Integer>> sumResult = wordTuple.keyBy(t -> t.f0).sum(1);
// sink
sumResult.print();
String topic = "t_kafkasink";
KafkaSink<Tuple2<String, Integer>> kafkaSink = KafkaSink.<Tuple2<String, Integer>>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic(topic)
.setValueSerializationSchema(new KafkaValueSerializationSchema_Tuple())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
sumResult.sinkTo(kafkaSink);
// 5.execute
env.execute();
}
}
3)、验证
略。参考Flink 1.13.6版本验证内容。
四、示例:手动重启-检验checkpoint
使用【三、示例:程序中设置重启策略】的例子,将该应用程序打包并上传至flink集群。
关于maven打包以及Flink集群提交任务参考该专栏的文章。1、Flink1.12.7或1.13.5详细介绍及本地安装部署、验证
1、maven打包
mvn package -Dmaven.test.skip=true
2、上传打包后的jar
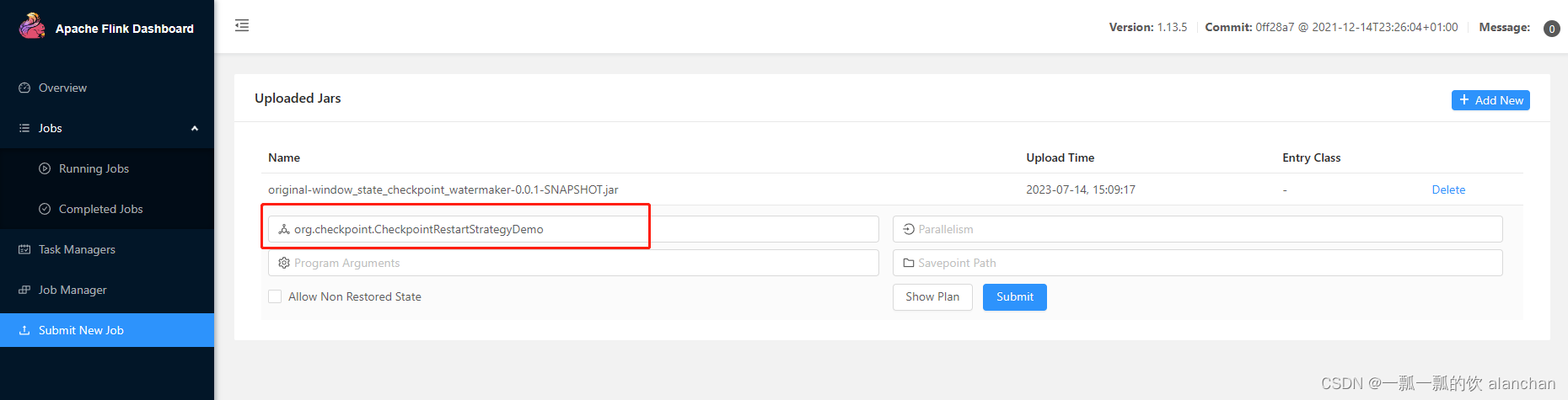
上传地址:http://server1:8081/#
上传成功后的界面,并设置运行主类,即main函数所在的类
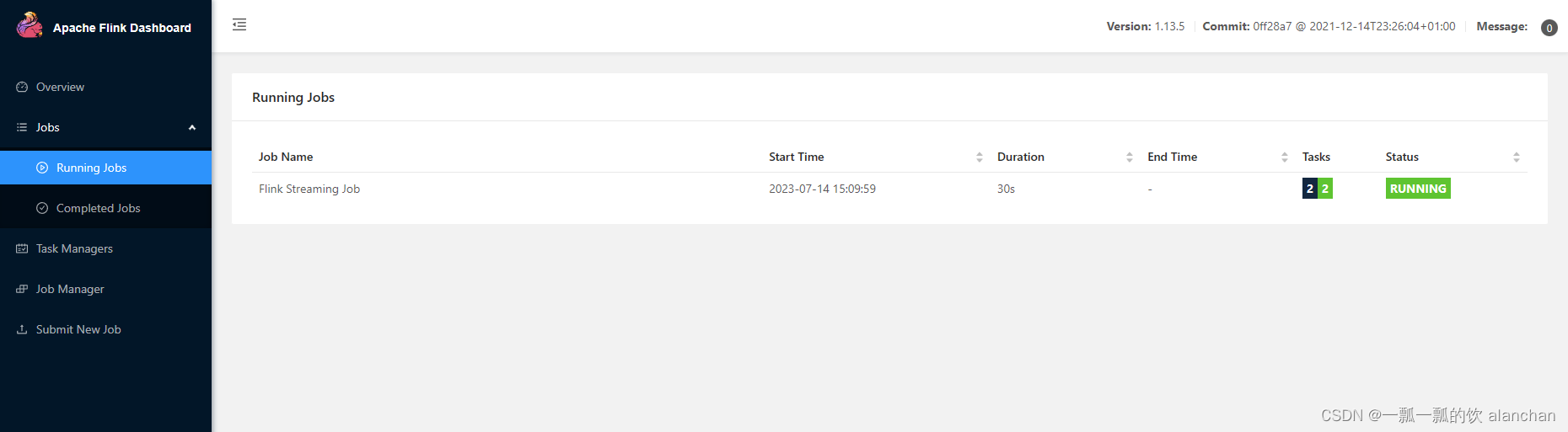
上传成功后,任务处于运行状态

3、验证程序功能
验证方式与上面在开发工具中验证一致,即在nc中输入数据,观察kafka中的输出。
验证关键点:是否自动重启了
- 输入数据
[root@server2 ~]# nc -lk 9999
aa,
bb,aa
cc,bb,aa,a
dd
aa
cc
- kafka控制台输出
aa:1
bb:1
aa:2
dd:1
aa:3
cc:1
aa:4
bb:2
4、手工恢复
在恢复点填入checkpoint对应的文件进行恢复。
本示例的地址为:hdfs://server2:8020/flinktest/flinkckp/0f93e35e25c3fb87ee8ce3d6393d6344/chk-129

填写完毕后提交任务,成功后进入如下页面
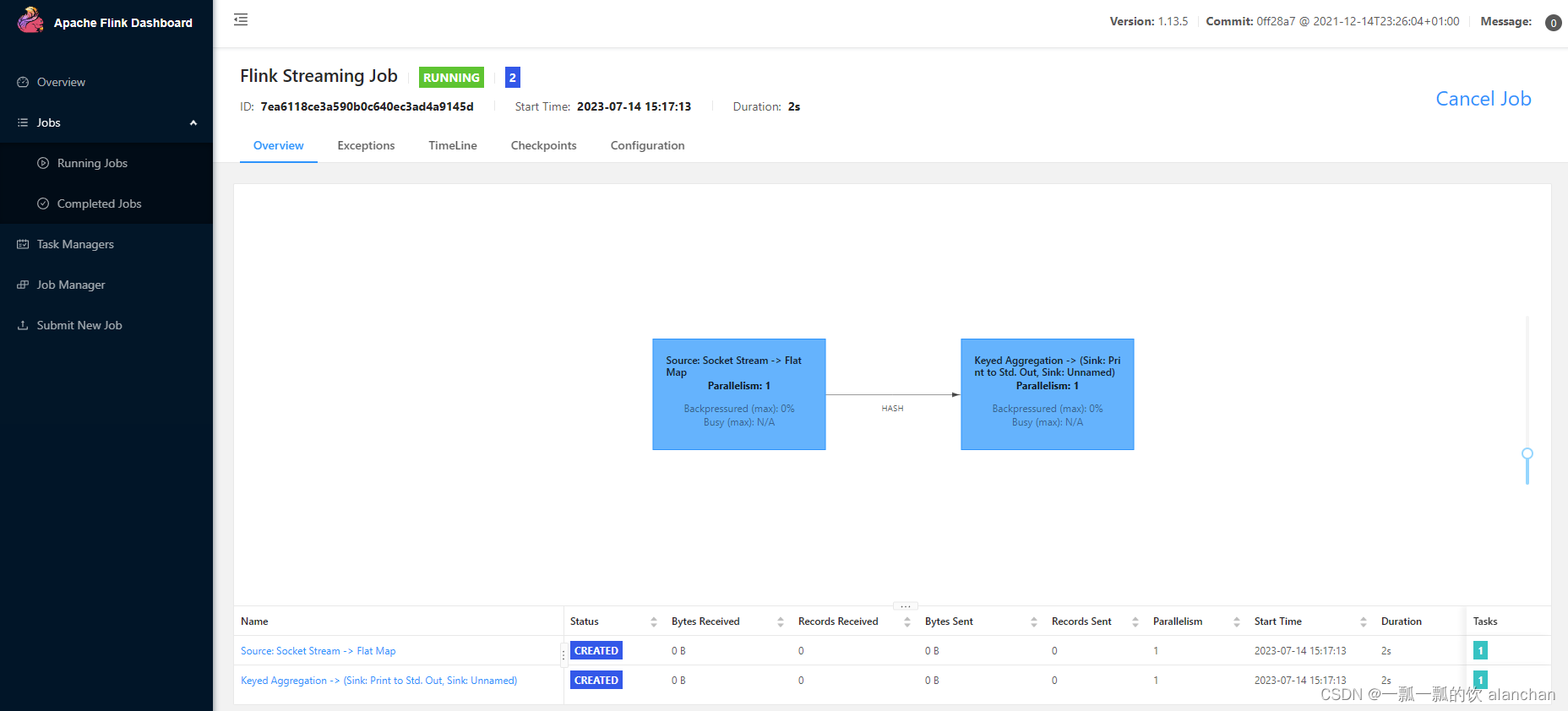
5、验证
再次验证,即关键之前计算的结果是否存在以及输入相同的键值,是否在原来的基础上累加。
- nc输入
[root@server2 ~]# nc -lk 9999
dd
bb
aa
a
- kafka控制台输出
dd:2
aa:4
bb:3
cc:2
以上完成了checkpoint的手工启动验证,实际生产中可能是系统自动完成的,不需要人工启动。如因非程序原因需要自动启动的话,比如系统重启等外界因素,一般使用手工的启动,人为的设置savepoint。
下面一节将介绍savepoint部分。
五、示例:通过savepoint手动恢复
在实际生产中,如要对集群进行停机维护/扩容…那么这时候需要执行一次Savepoint也就是执行一次手动的Checkpoint(也就是手动的发一个barrier栅栏),程序的所有状态都会被执行快照并保存,当维护/扩容完毕之后,可以从上一次Savepoint的目录中进行恢复。
本示例以flink提交任务的session模式进行演示
# 启动yarn session
/usr/local/flink-1.13.5/bin/yarn-session.sh -n 2 -tm 1024 -s 1 -d
# 运行job-会自动执行Checkpoint
/usr/local/flink-1.13.5/bin/flink run --class org.checkpoint.CheckpointRestartStrategyDemo /usr/local/bigdata/testdata/original-window_state_checkpoint_watermaker-0.0.1-SNAPSHOT.jar
# 手动创建savepoint--相当于手动做了一次Checkpoint
# 225125bc4ddf3f69190ebcb8e82e428f是当前任务的id
/usr/local/flink-1.13.5/bin/flink savepoint 225125bc4ddf3f69190ebcb8e82e428f hdfs://server1:8020//flinktest/flinkckp
# 停止job
/usr/local/flink-1.13.5/bin/flink cancel 225125bc4ddf3f69190ebcb8e82e428f
# 重新启动job,手动加载savepoint数据
# savepoint-702b87-0a11b997fa70 是创建savepoint时系统自动生成的checkpoint文件名称
/usr/local/flink-1.13.5/bin/flink run -s hdfs://server1:8020/flinktest/savepoint/savepoint-702b87-0a11b997fa70 --class org.checkpoint.CheckpointRestartStrategyDemo /usr/local/bigdata/testdata/original-window_state_checkpoint_watermaker-0.0.1-SNAPSHOT.jar
# 停止yarn session
# 关闭方式很多,比如kill或界面上中止等
以上,本文介绍了Flink 在程序中设置重启策略、手动重启查看checkpoint的state恢复以及通过savepoint手动恢复,其中包含详细的验证步骤与验证结果。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为以下几篇文章:
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(1) - checkpoint配置及实现
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(2) -重启策略与手动恢复
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!