李宏毅机器学习2023|图像生成模型
2023-12-26 15:42:13
文章目录
图像生成
机器需要大量的脑补
Autoregressive(各个击破)Non-Autoregressive(一次到位)
直接把图片的像素拉直,当成文字那样处理。
但是这样太耗时
一次到位法
因为每一个像素独立绘制,因此效果不好
额外的输入——从一个高维的Normal Distribution作simple得到一个向量

常用的图片生成模型
VAE
怎么样去找一些成对的训练集?使用Encoder产生。(图中省略了输入文字)

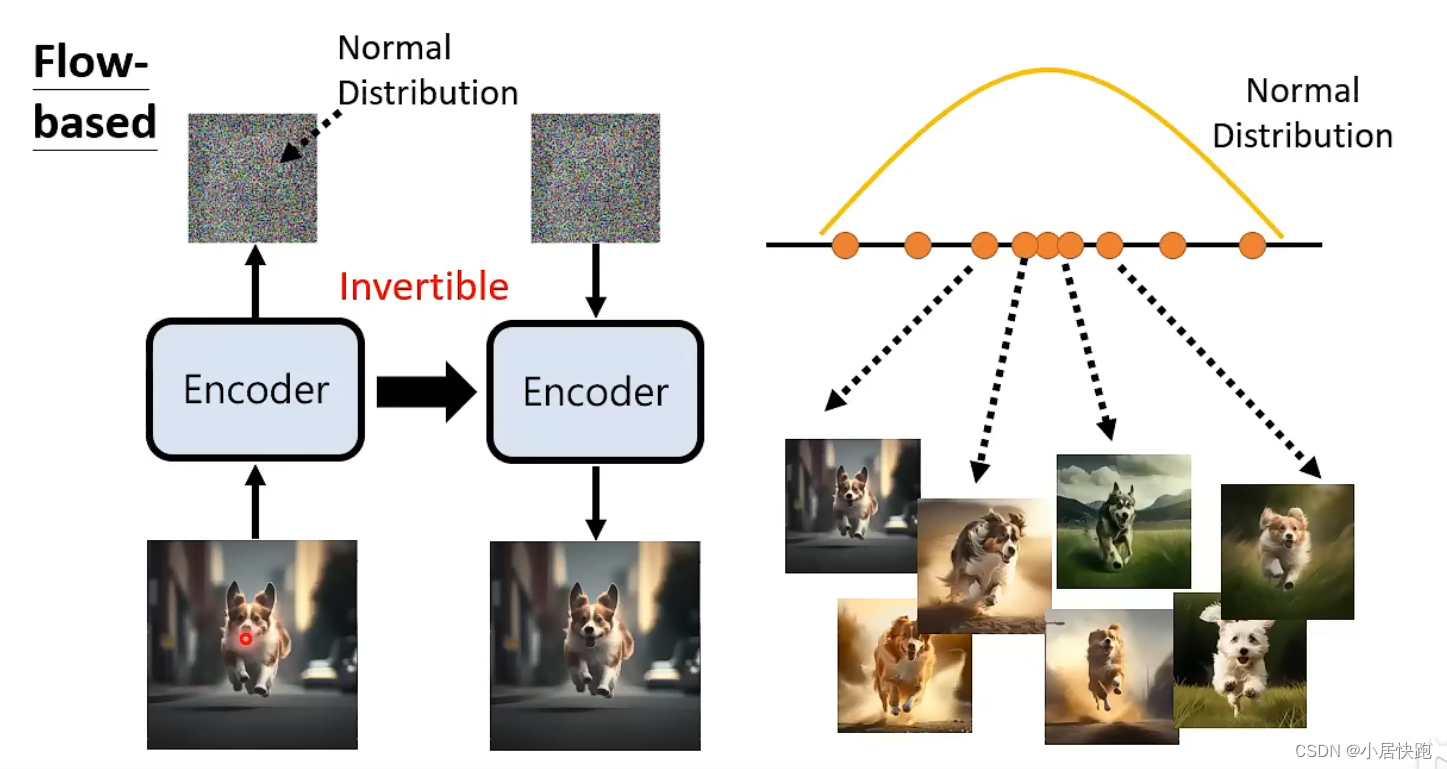
Flow-based Generative Model
因为Encoder必须是Invertible的,因此输出的vector的维度必须和输入的一样。(图上没画好)
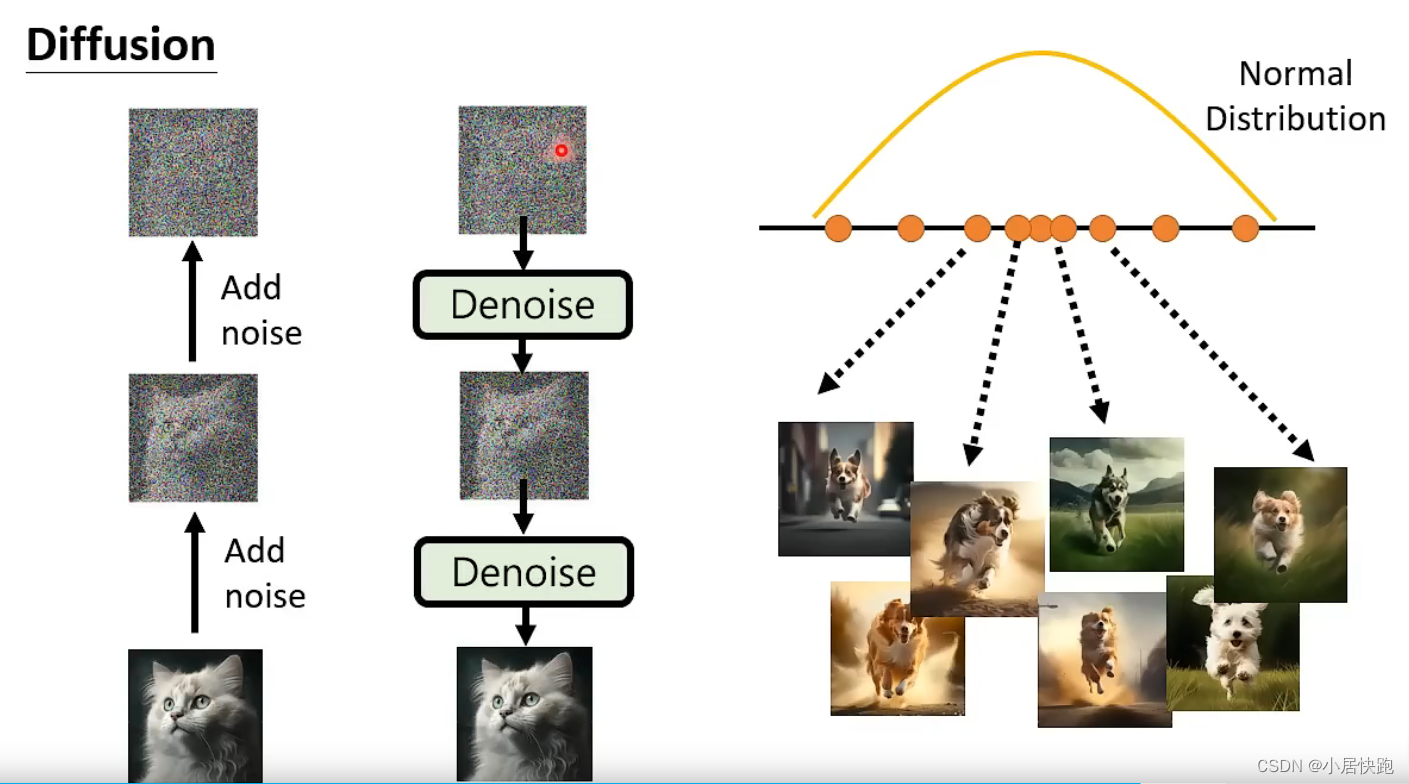
Diffusion Model
GAN
只learn decoder没有learn encoder。
Decoder要做的就是调整他自己,让判别器表现得越差越好。
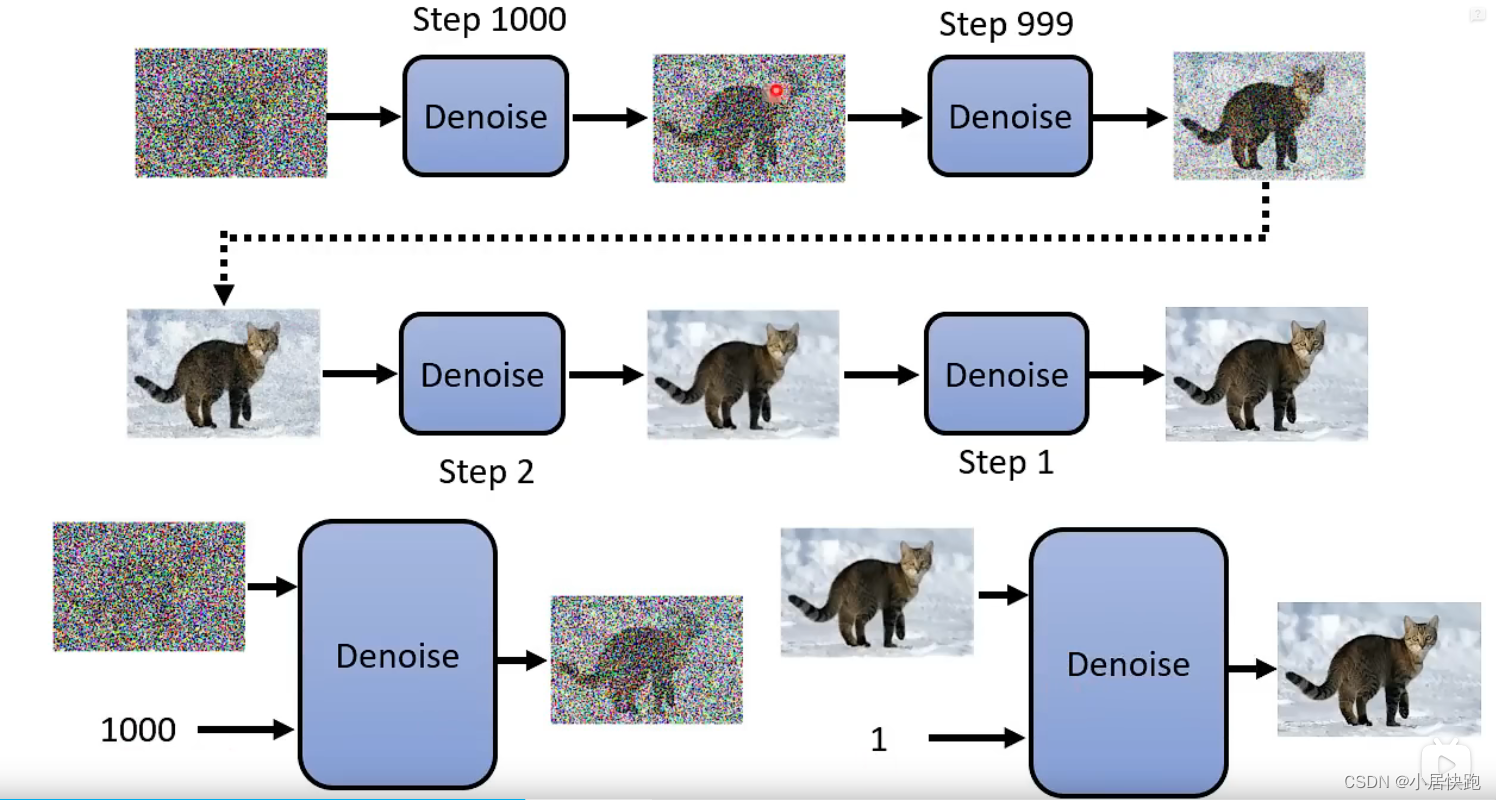
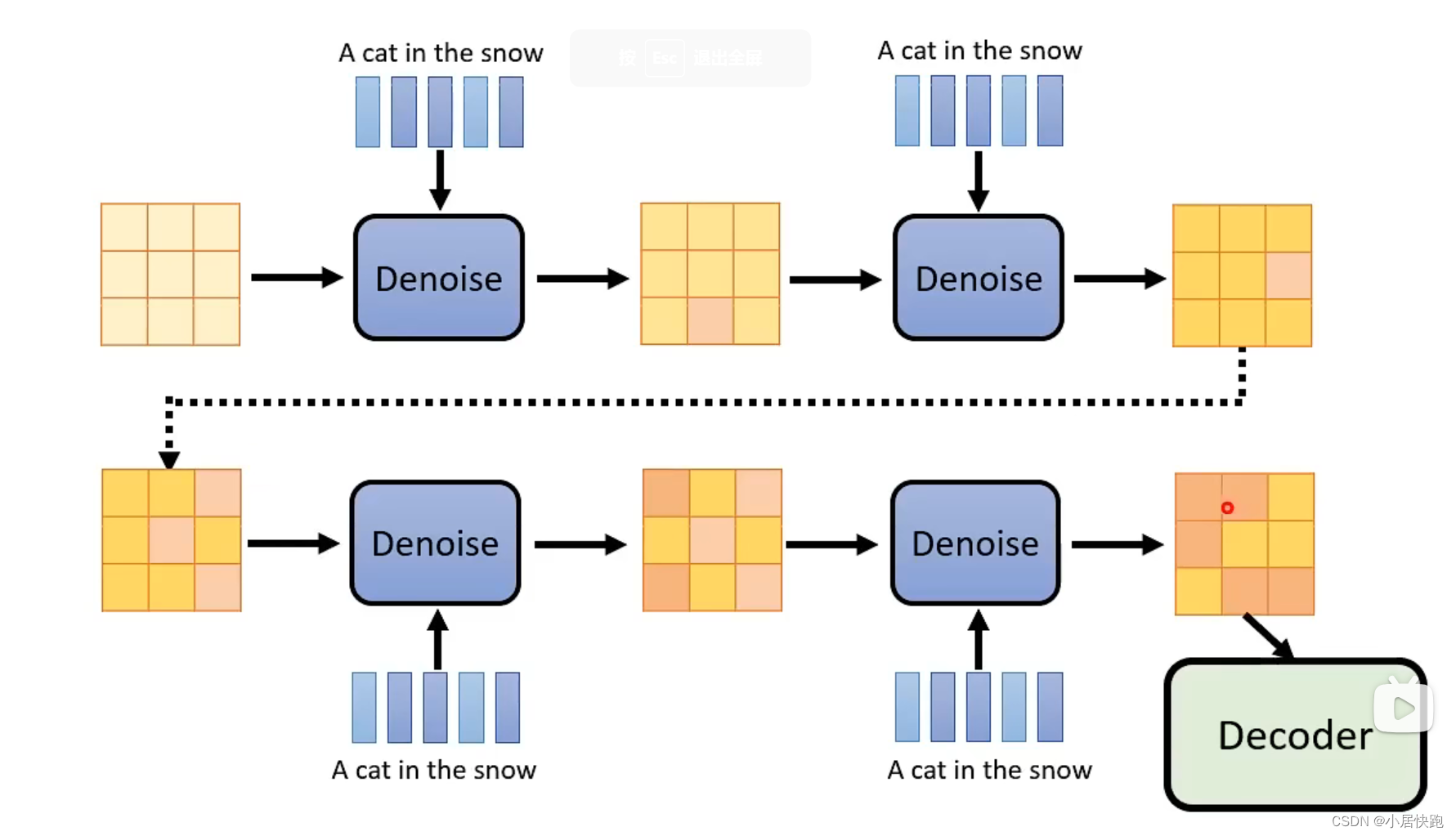
Diffusion Model
这里的Denoise都是同一个model
denoise model里实际内部做的事情
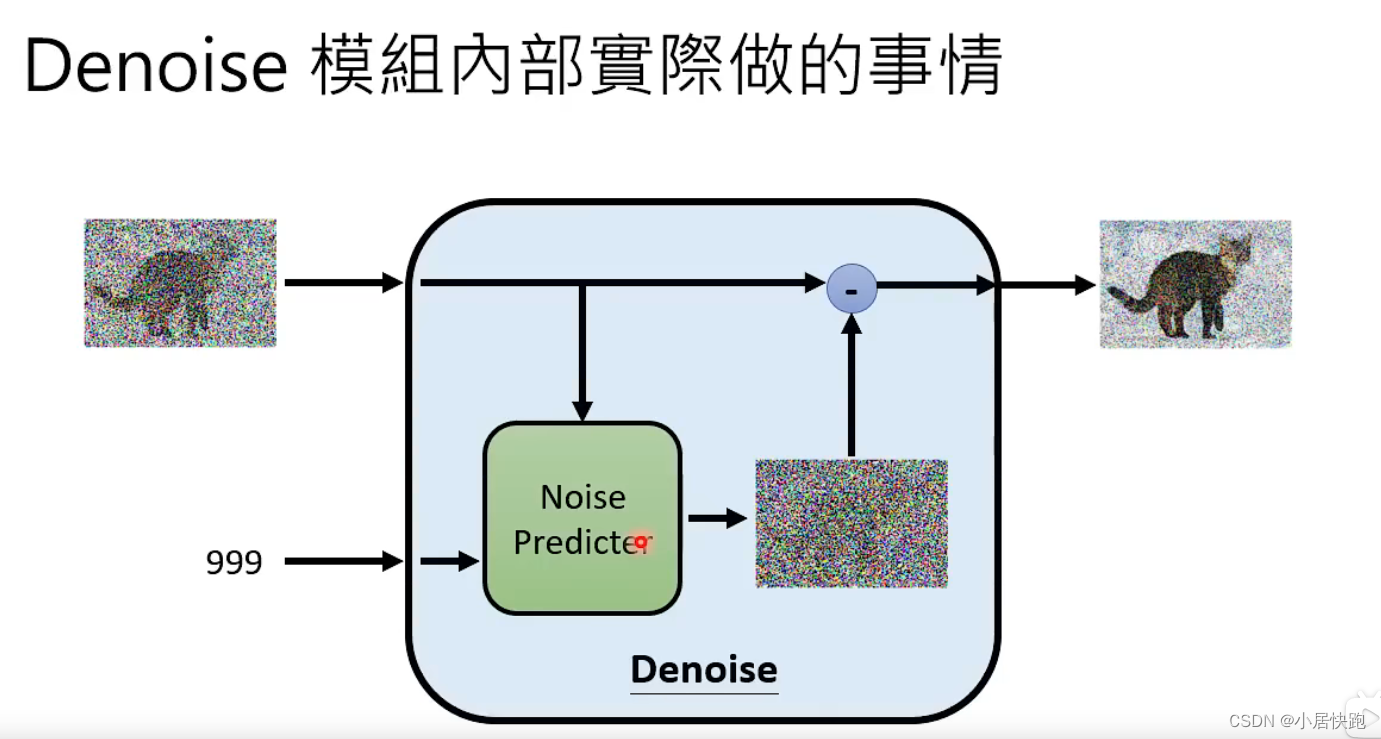
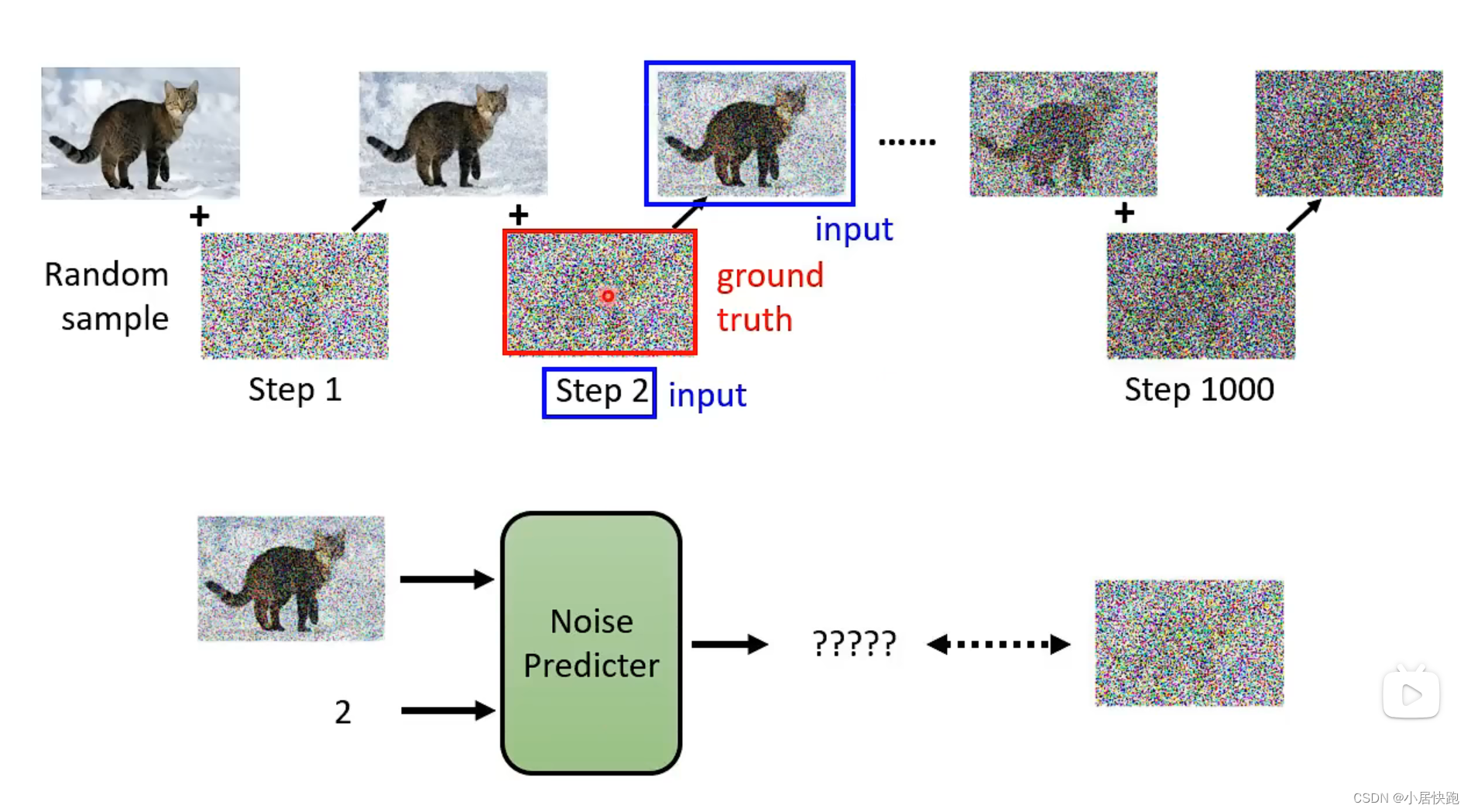
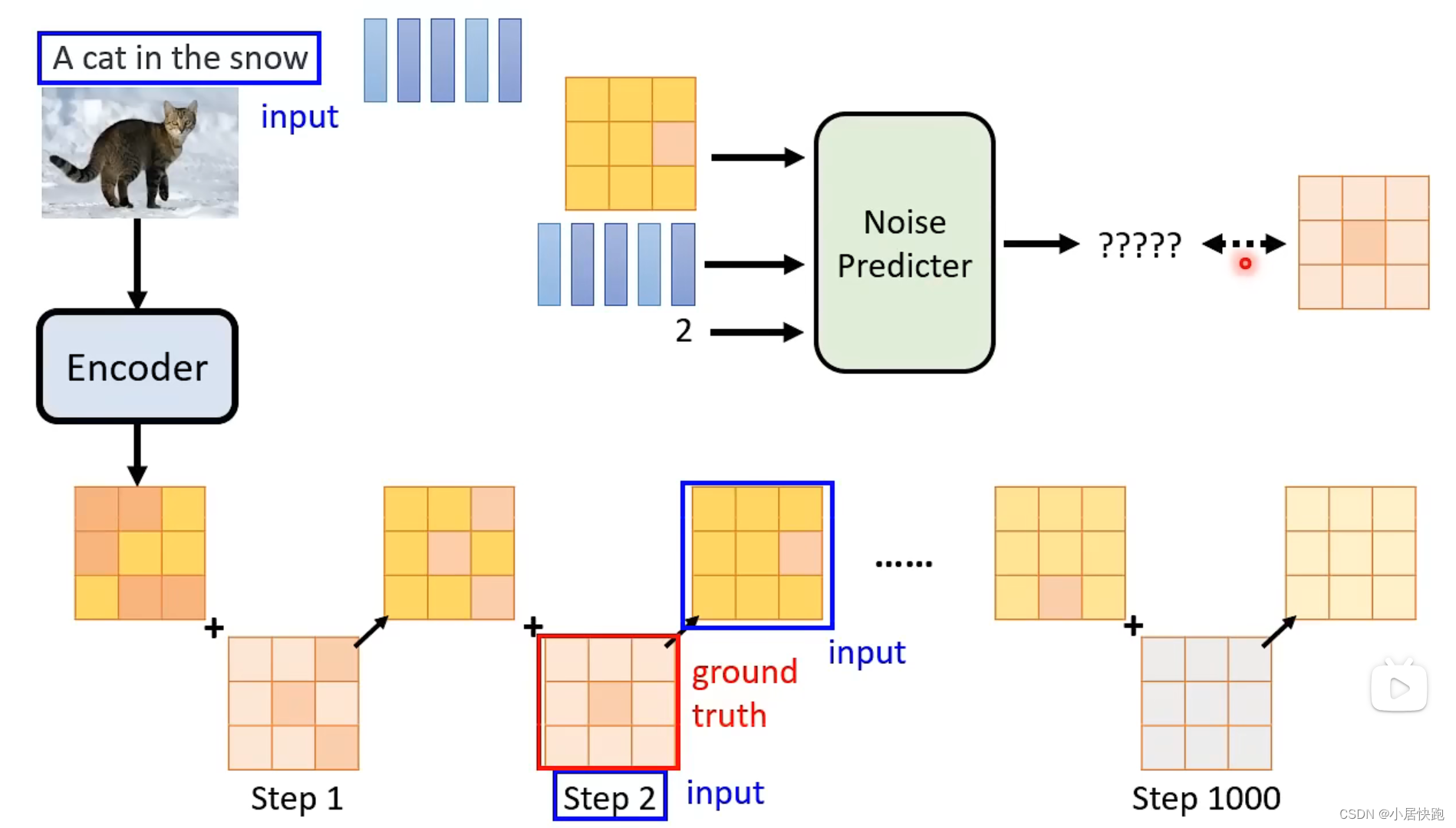
如何训练Noise Predictor
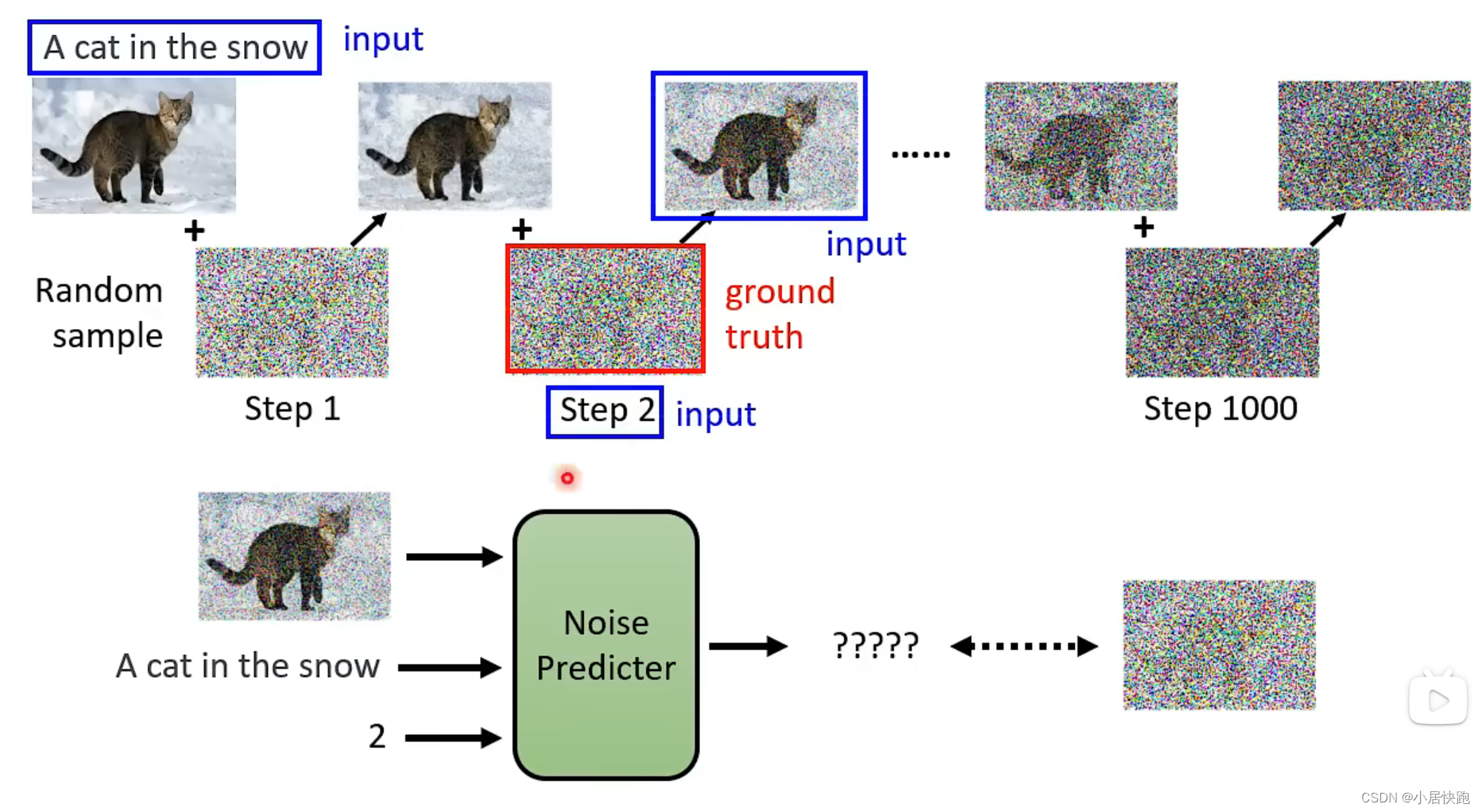
从哪获取训练资料——怎么找到杂屑的ground truth?这是人类自己创造的
加噪音——Forward Process(Diffusion Process)
怎么把文字考虑进来
数据集:LAION-5b

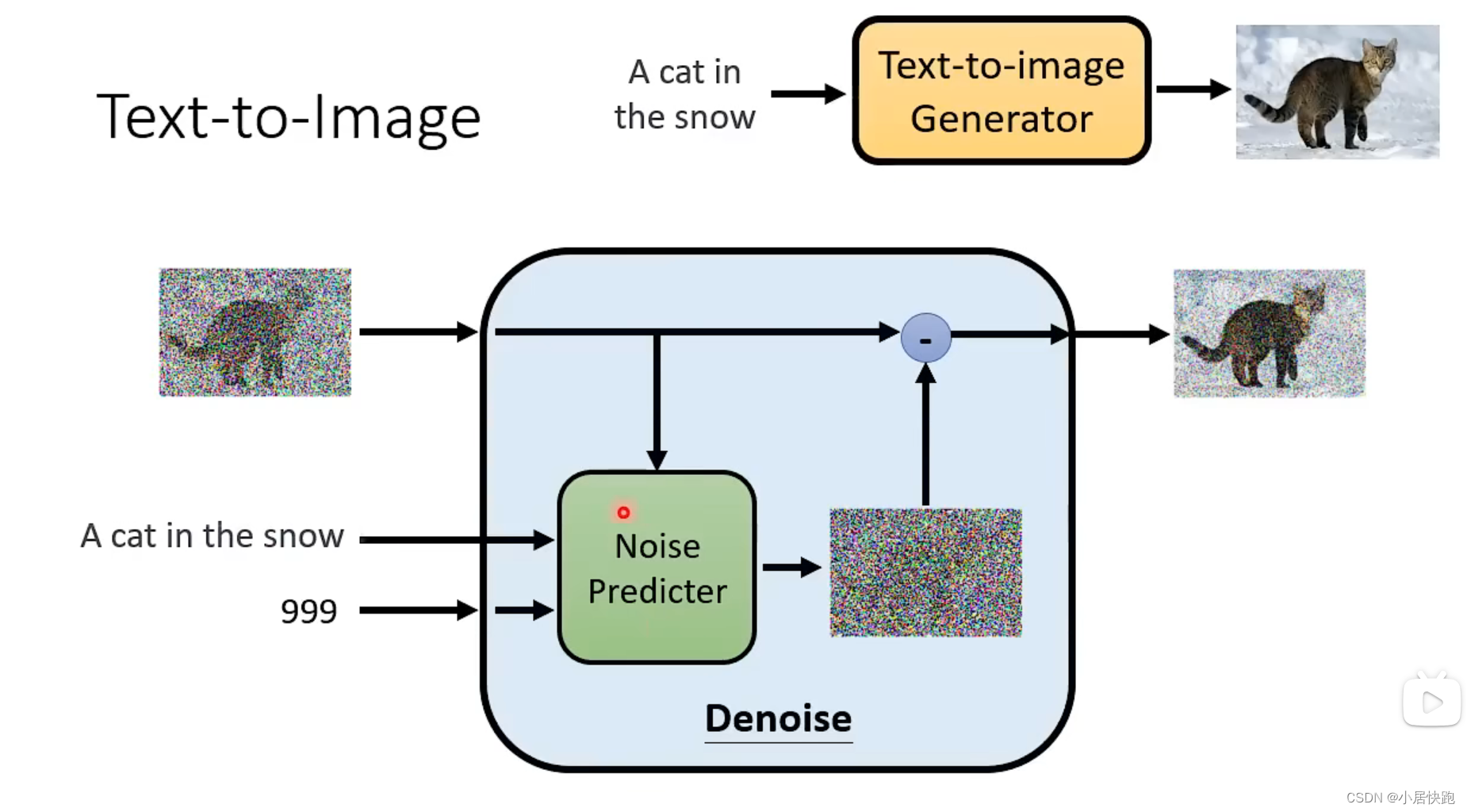
来源论文:Denoising Diffusion Probabilistic Models
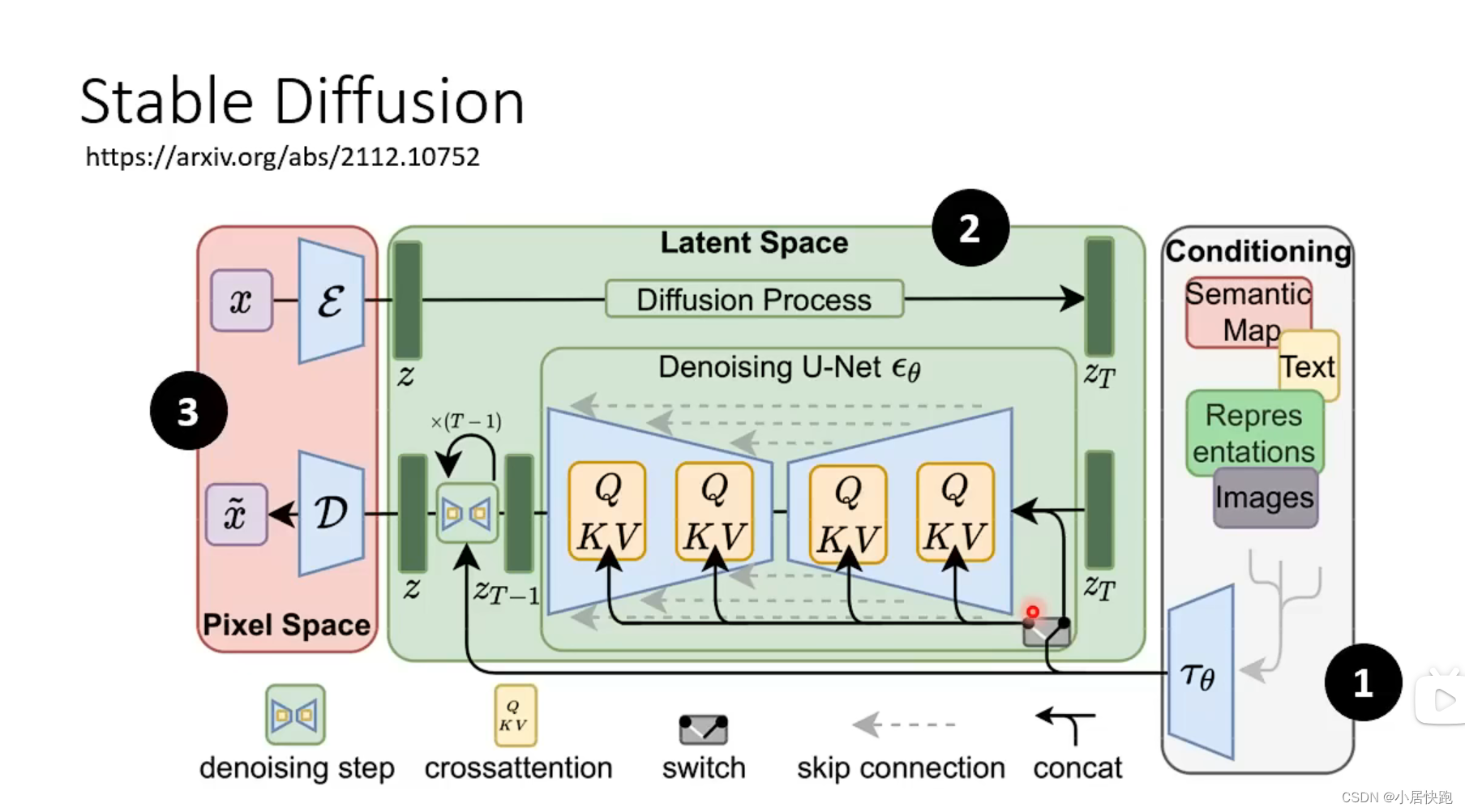
Stable Diffusion
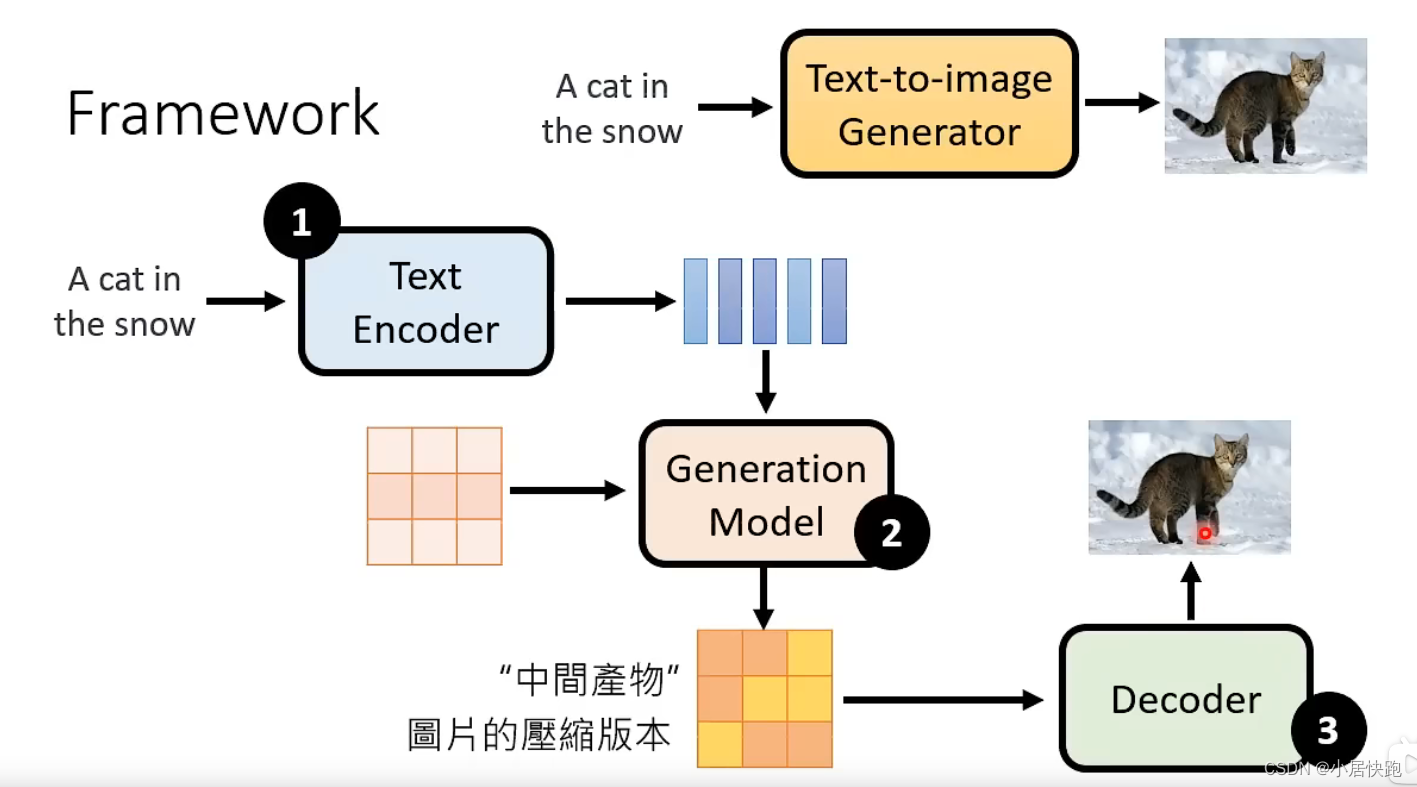
现在最好的图像生成模型由三个元件组成:
1、Text Encoder
2、Generation Model(Stable Diffusion或者其他)
3、Decoder
三个元件分开训练再合起来
常见的图生文模型
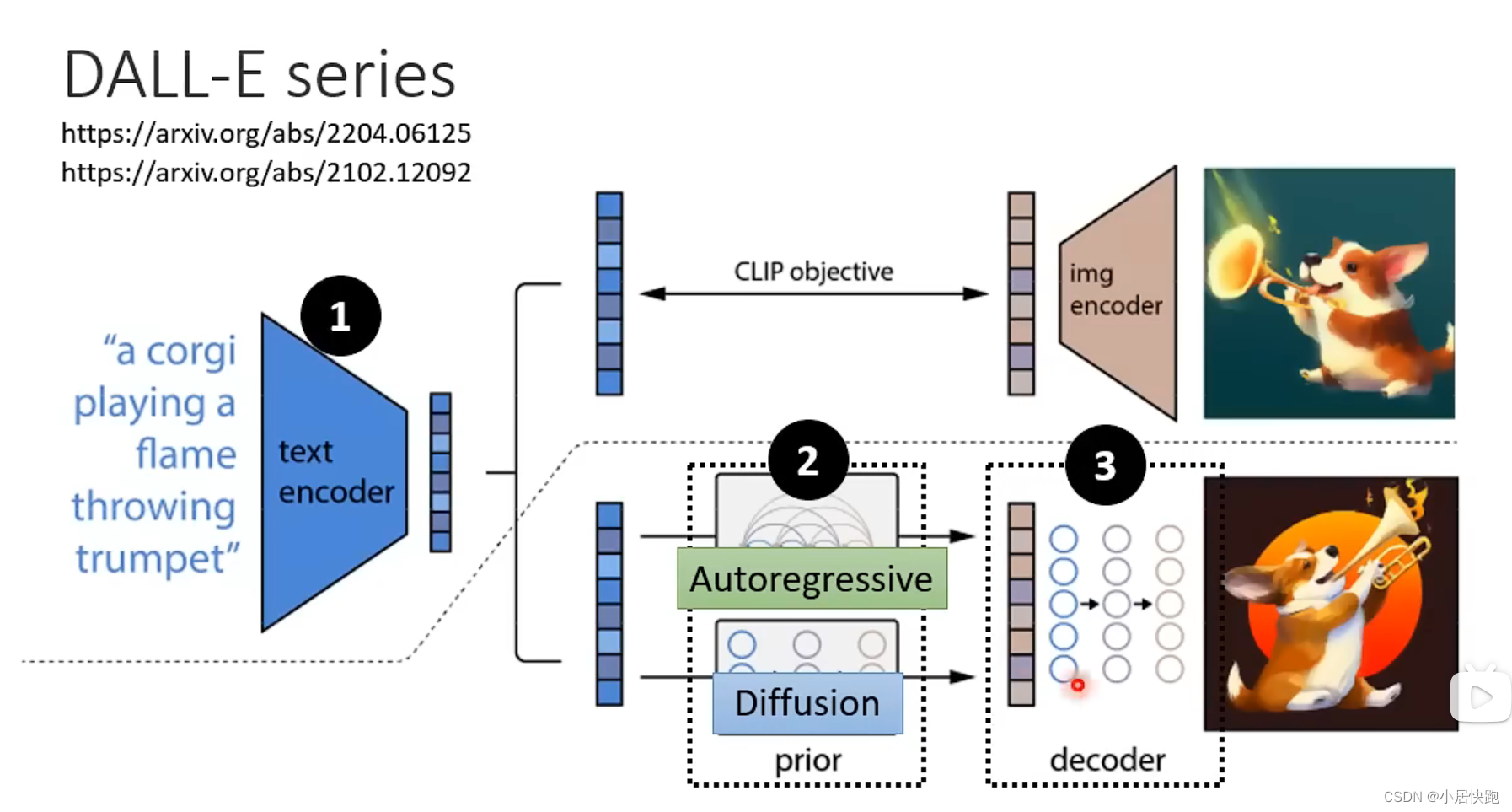
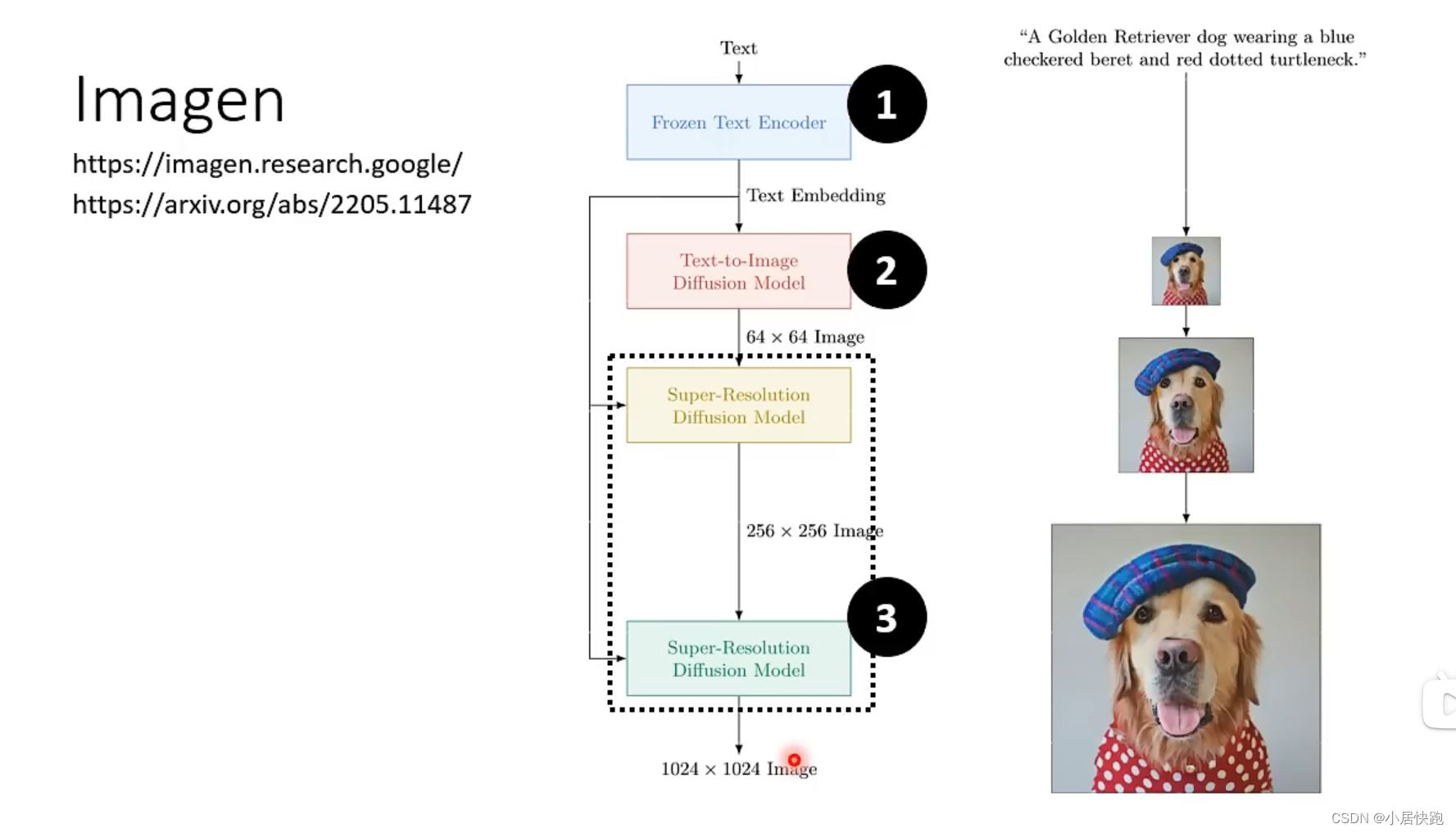
组成部分
text encoder
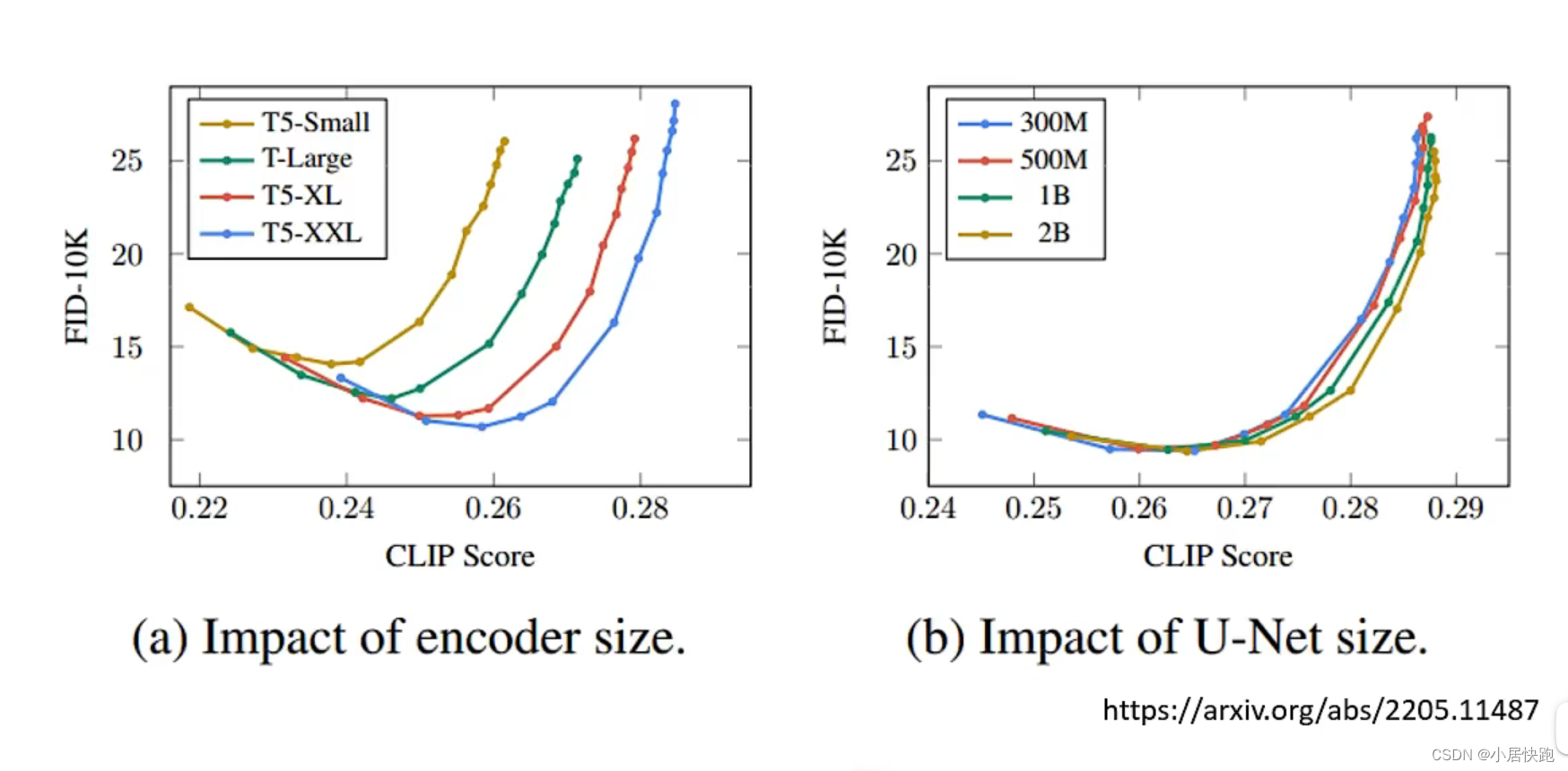
encoder对结果影响很大,相对而言diffusion model(这里指那个noise predicter的大小)对结果影响就不大。
Generation Model
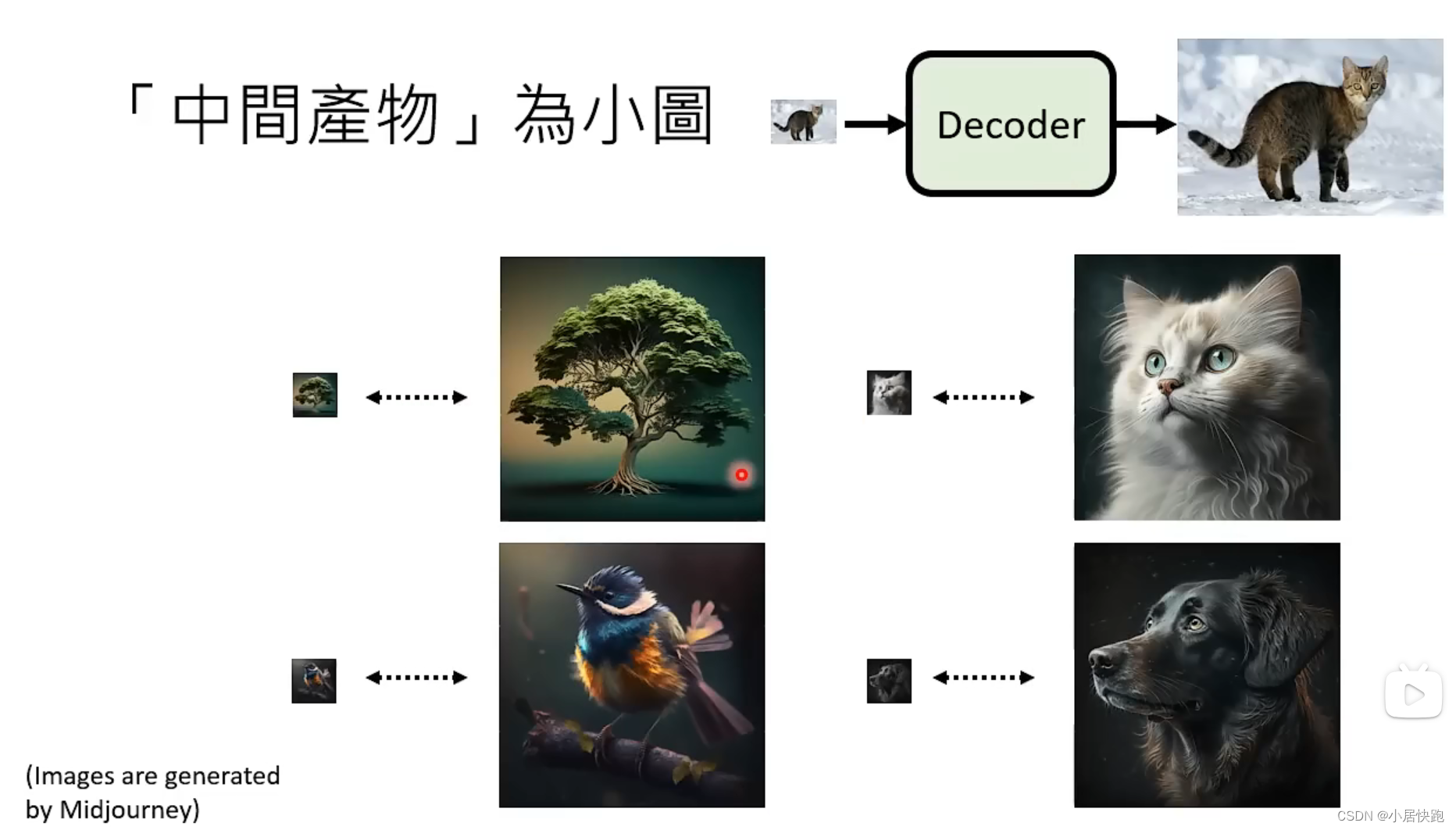
杂屑不是加在图片上,而是加在中间产物上
Decoder
训练时不需要labelled data

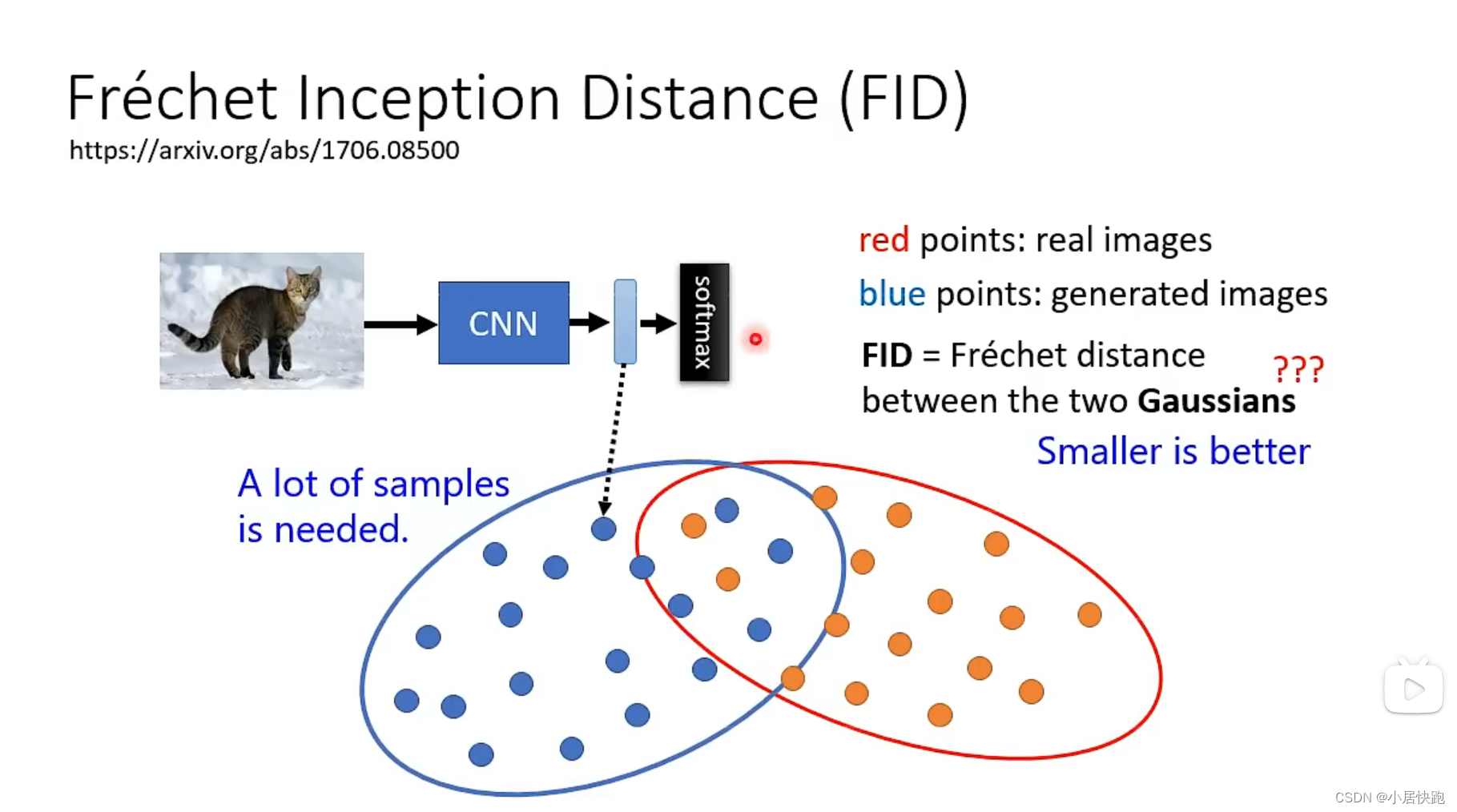
评估指标
FID
越小越好
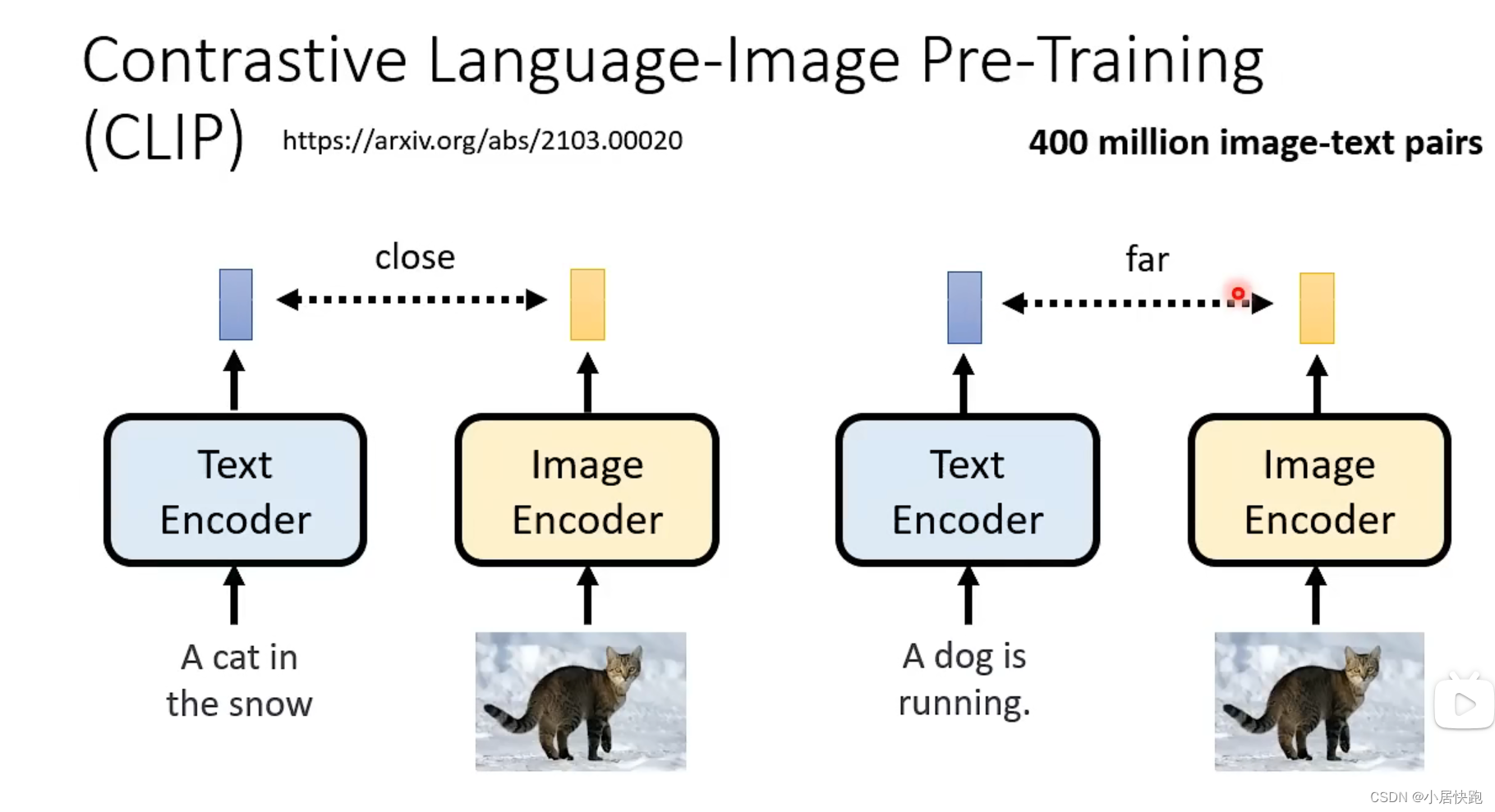
CLIP Score
越大越好
文章来源:https://blog.csdn.net/m0_57290240/article/details/135209490
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!