单日30PB量级!火山引擎ByteHouse云原生的数据导入这么做
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
近期,火山引擎ByteHouse技术专家受邀参加DataFunCon2023(深圳站)活动,并以“火山引擎ByteHouse基于云原生架构的实时导入探索与实践”为题进行了技术分享。在分享中,火山引擎ByteHouse技术专家以Kafka和物化MySQL两种实时导入技术为例,介绍了ByteHouse的整体架构演进以及基于不同架构的实时导入技术实现。
随着企业降本增效、智能化数据决策需求的增强,传统的商业数据库已经难以满足和响应快速增长的业务诉求。在此背景下,云原生数据库成为大势所趋。云原生数据库基于云平台构建、部署和分发,具有高可用性、高性能、高可靠等特点,可以帮助企业更好地实现数据智能化决策。
火山引擎ByteHouse是基于开源ClickHouse进行技术优化和升级的一款云原生数据仓库。ClickHouse原有的分布式架构具有无中心多主节点以及存储方便的优势。但它也存在节点故障处理成本高、读写冲突、扩容成本高以及一致性欠缺等架构痛点。基于此,ByteHouse在社区分布式架构基础上,演进并开源了ClickHouse新型云原生架构。并且ByteHouse在新架构下也做了实时导入技术的设计与实现。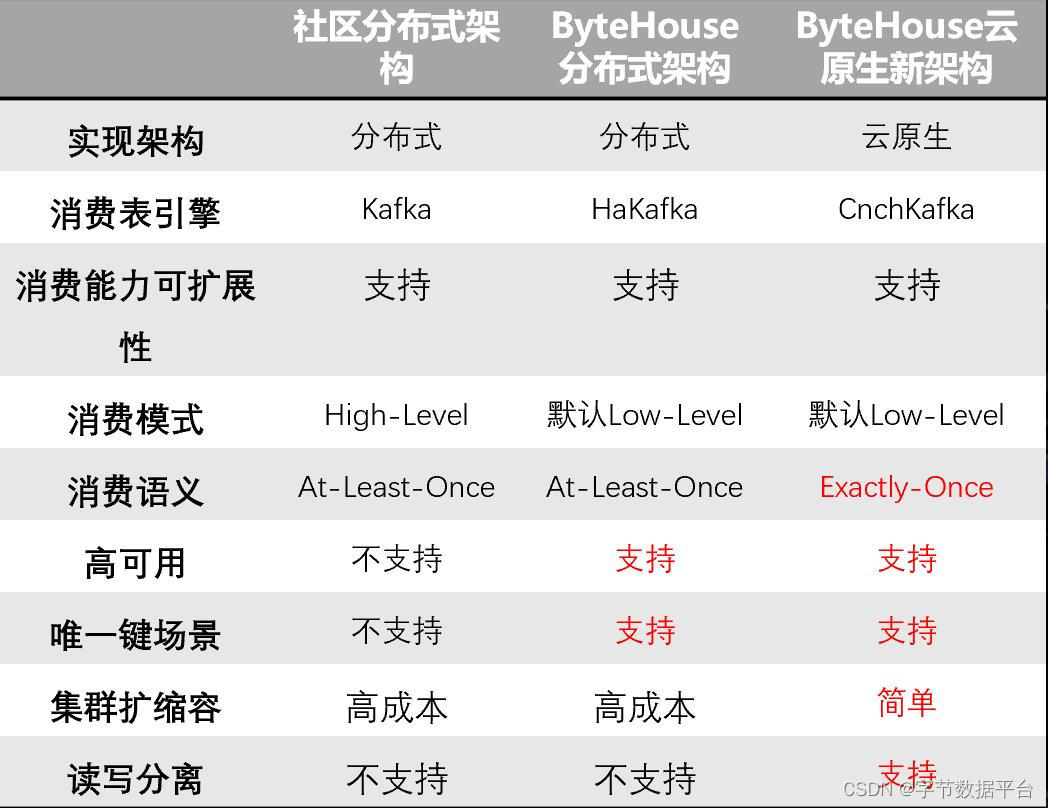
不同架构实时导入技术比较(Kafka)
据介绍,火山引擎ByteHouse云原生架构分为三层:第一层是云服务入口,负责承接所有的用户请求;第二层是执行层,主要负责查询和导入的功能,实现读写分离;第三层是数据存储层,支持多种云存储组件。在云原生架构下,ByteHouse不仅具有运维成本和门槛低的架构优势,还通过读写分离等手段解决了查询高峰导致导入停滞等问题,并且得益于架构优势引入了弹性扩缩容能力以及高可用性。
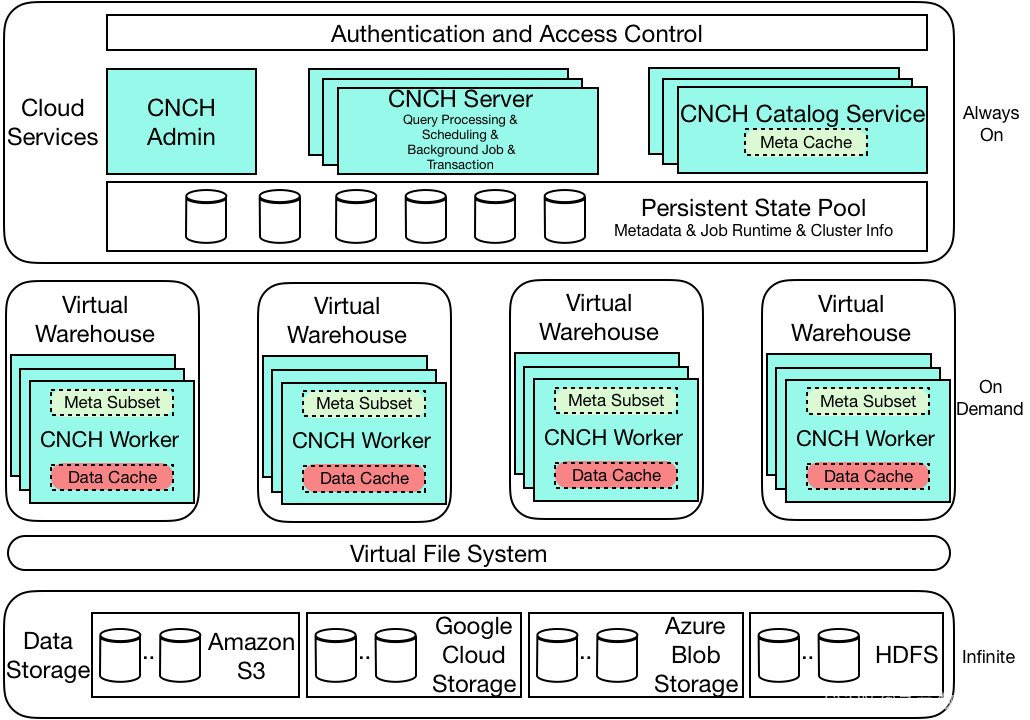
火山引擎ByteHouse云原生架构图
由于云原生架构的应用,面对字节跳动内部激增的业务量以及处理庞大数据量的需求,ByteHouse在实时导入技术方面进行了相应的优化升级。目前,ByteHouse以Kafka和物化MySQL作为实时导入的主要数据源。
在Kafka导入实现中,ByteHouse可以实现秒级数据延时和单表GiB级吞吐,支持绝大部分在线实时分析业务场景。相比社区版本,其优势在于高可用性和容错机制,并支持Exactly-Once消费语义,保证数据的可靠性和完整性。
物化MySQL是一种将MySQL数据库中的数据按库级别同步到ByteHouse中的能力,主要工作流程为基于MySQL数据库创建一个物化库引擎,该引擎初始化时从MySQL拉取指定库的所有存量数据,后续通过binlog同步回放的方式持续同步增量数据。其优势在于,不仅保证数据的一致性和完整性,还可以对数据实时分析和处理,提高处理的速度和效率。
目前,火山引擎ByteHouse云原生架构已经全面服务内、外部多种业务场景,实时导入已支持超过2500个服务节点,每天实时导入数据规模超过30PB。未来,火山引擎ByteHouse团队还将持续探索更通用的实时导入技术解决方案,进一步提升数据导入的性能和通用性。
点击跳转火山引擎ByteHouse了解更多
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!