从零开发短视频电商 Sagemaker端点模型部署方式
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/realtime-endpoints-options.html
简介
分为两种模型托管方式
-
单一模型端点
-
多模型端点
将多个模型托管在一个容器内,通过一个端点提供服务 多模型端点提供了一种可扩展且成本效益的解决方案,用于部署大量模型。它们使用相同的资源池和共享的服务容器来托管所有模型。与使用单一模型端点相比,这降低了托管成本,因为提高了端点利用率。同时,由于Amazon SageMaker管理内存中的模型加载和根据端点的流量模式进行扩展,这也减少了部署的开销。
以下图示说明了多模型端点与单一模型端点的工作方式的对比。
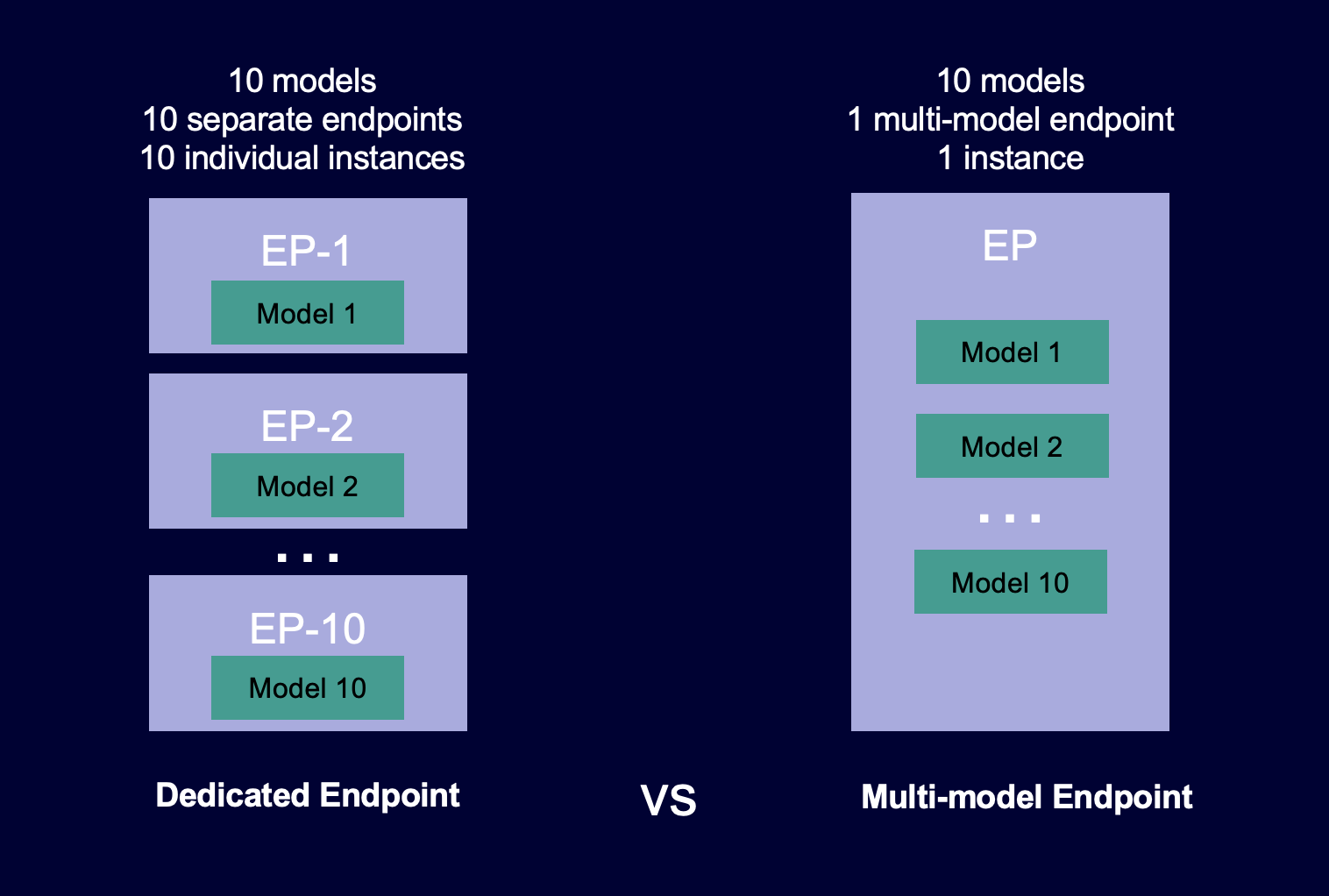
多模型端点非常适合托管大量使用相同ML框架的模型,它们共享一个服务容器。如果您有一组经常访问和不经常访问的模型,多模型端点可以使用更少的资源和更高的成本节省高效地为这些流量提供服务。您的应用程序应该能够容忍偶尔冷启动相关的延迟,这些延迟发生在调用不经常使用的模型时。
多模型端点支持托管既支持CPU又支持GPU的模型。通过使用支持GPU的模型,您可以通过增加端点及其基础加速计算实例的使用来降低模型部署成本。
多模型端点还支持在模型之间共享内存资源的时间共享。当模型在大小和调用延迟上相当相似时,这种方式效果最好。在这种情况下,多模型端点可以有效地跨所有模型使用实例。如果您有具有显著较高每秒事务数(TPS)或延迟要求的模型,我们建议将它们托管在专用端点上。
多模型端点的工作原理
SageMaker 管理托管在多模型端点容器内的模型的生命周期。与在创建端点时将所有模型从Amazon S3存储桶下载到容器的方法不同,SageMaker 在调用时动态加载和缓存它们。当SageMaker收到对特定模型的调用请求时,它执行以下操作:
- 将请求路由到端点后面的实例。
- 从S3存储桶下载模型到该实例的存储卷。
- 将模型加载到容器的内存中(取决于您是否使用CPU或GPU支持的实例)在加速计算实例上。如果模型已经加载到容器的内存中,调用速度会更快,因为SageMaker无需再次下载和加载它。
SageMaker 继续将对模型的请求路由到已经加载该模型的实例。然而,如果该模型接收到许多调用请求,并且多模型端点有其他实例,SageMaker 将一些请求路由到另一个实例以适应流量。如果第二个实例上没有加载该模型,该模型将被下载到该实例的存储卷并加载到容器的内存中。
当实例的内存利用率较高且SageMaker需要将另一个模型加载到内存中时,它会从该实例的容器中卸载未使用的模型,以确保有足够的内存来加载模型。已卸载的模型仍然保留在实例的存储卷上,稍后可以将其加载到容器的内存中,而无需再次从S3存储桶下载。如果实例的存储卷达到其容量,SageMaker 将从存储卷中删除任何未使用的模型。
要删除模型,请停止发送请求并从S3存储桶中删除它。SageMaker 在一个服务容器中提供了多模型端点的能力。向多模型端点添加模型以及从中删除模型不需要更新端点本身。要添加模型,您将其上传到S3存储桶并调用它。您无需更改代码即可使用它。
注意 当您更新多模型端点时,端点上的初始调用请求可能会因多模型端点中的智能路由适应您的流量模式而经历较高的延迟。但是,一旦它学习了您的流量模式,您可以在使用最频繁的模型时体验低延迟。不经常使用的模型可能会因为模型被动态加载到实例上而产生一些冷启动延迟。
设置SageMaker多模型端点模型缓存行为
默认情况下,多模型端点将常用模型缓存在内存中(取决于您是否使用CPU或GPU支持的实例)和磁盘上,以提供低延迟的推理。缓存的模型仅在容器因内存或磁盘空间不足以容纳新的目标模型而卸载和/或删除时才会被卸载和/或删除。
您可以通过在调用create_model时设置参数ModelCacheSetting来更改多模型端点的缓存行为,并明确启用或禁用模型缓存。
我们建议将ModelCacheSetting参数的值设置为Disabled,用于不从模型缓存中获益的用例。例如,当需要从端点中服务大量模型,但每个模型只被调用一次(或非常不经常调用)时。对于这种用例,将ModelCacheSetting参数的值设置为Disabled可以使invoke_endpoint请求的事务每秒(TPS)比默认缓存模式更高。在这些用例中,高TPS是因为SageMaker在invoke_endpoint请求之后执行以下操作:
- 在调用后异步从内存中卸载模型并立即从磁盘中删除。
- 为推理容器中的模型下载和加载提供更高的并发性。对于CPU和GPU支持的端点,并发性是容器实例的vCPUs数量的一个因素。
总结
多模型端点和专用端点都是Amazon SageMaker中用于托管机器学习模型的方式,它们适用于不同的使用场景和需求。以下是它们的优缺点和适用场景的总结:
多模型端点(Multi-Model Endpoints)
优点:
- 资源共享: 多模型端点允许在同一容器内托管多个模型,通过共享资源以提高端点的利用率。
- 成本效益: 由于多个模型共享相同的计算资源,相比于专用端点,使用多模型端点可以减少托管成本。
- 灵活性: 适用于部署大量模型,尤其是当这些模型使用相同的机器学习框架时。
缺点:
- 性能: 在某些情况下,多模型端点可能因为动态加载模型而引入一些冷启动延迟,尤其是对于不经常使用的模型。
- 资源分配: 如果有明显不同的模型访问模式或延迟要求,多模型端点可能不如专用端点。
专用端点(Dedicated Endpoints)
优点:
- 性能: 专用端点通常提供更稳定和可控的性能,适用于对延迟要求较高的场景。
- 定制化: 可以为每个端点定制独立的资源配置,以满足特定模型的要求。
- 预测性: 适用于对端点性能和行为有明确预期的应用场景。
缺点:
- 成本: 由于资源独立分配,专用端点可能在资源利用率方面较多模型端点更昂贵。
- 管理复杂性: 需要单独管理每个端点,可能会增加系统的复杂性和维护成本。
总结:
-
多模型端点: 适用于大规模部署相似或相对较小的模型,具有成本效益和资源共享的优势。
-
专用端点: 适用于对性能和资源分配有严格要求的场景,以及当模型异构性较大时。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!