Spark二、Spark技术栈之Spark Core
Spark Core
spark核心:包括RDD、RDD算子、RDD的持久化/缓存、累加器和广播变量
学习链接:https://mp.weixin.qq.com/s/caCk3mM5iXy0FaXCLkDwYQ
一、 RDD
1.1 为什么要有RDD
在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,之前的 MapReduce 框架采用非循环式的数据流模型,把中间结果写入到 HDFS 中,带来了大量的数据复制、磁盘 IO 和序列化开销。且这些框架只能支持一些特定的计算模式(map/reduce),并没有提供一种通用的数据抽象。
RDD 提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同 RDD 之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销,并且还提供了更多的 API(map/reduec/filter/groupBy…)。
参考论文:Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
1.2 RDD是什么
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
Resilient:弹性的,RDD 里面的中的数据可以保存在内存中或者磁盘里面;
Distributed:元素是分布式存储的,可以用于分布式计算;
Dataset:一个集合,可以存放很多元素
1.3 RDD属性

分区列表:一个分区/分片,即数据集的基本组成单位。对于 RDD 来说,每个分片都会被一个计算任务处理,分片数决定并行度。用户可以在创建 RDD 时指定 RDD 的分片个数,如果没有指定,那么就会采用默认值。
计算函数:一个函数会被作用在每一个分区。 RDD 的计算是以分片为单位的,compute 函数会被作用到每个分区上。
依赖关系:一个 RDD 会依赖于其他多个 RDD。RDD 的每次转换都会生成一个新的 RDD,所以 RDD 之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark 可以通过这个依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算。(Spark 的容错机制)
分区函数(默认是hash):对于 KV 类型的 RDD 会有一个 Partitioner,即 RDD 的分区函数,默认为 HashPartitioner。
最佳位置: 一个列表,存储存取每个 Partition 的优先位置(preferred location)。对于一个 HDFS 文件来说,这个列表保存的就是每个 Partition 所在的块的位置。按照"移动数据不如移动计算"的理念,Spark 在进行任务调度的时候,会尽可能选择那些存有数据的 worker 节点来进行任务计算。
分区列表、分区函数、最佳位置,这三个属性其实说的就是数据集在哪,在哪计算更合适,如何分区;
计算函数、依赖关系,这两个属性其实说的是数据集怎么来的。
二、 RDD-API
2.1 RDD的创建方式
- 由外部存储系统的数据集创建,包括本地的文件系统,还有所有 Hadoop 支持的数据集,比如 HDFS、Cassandra、HBase 等
val inputUserInfoTxt = "filePath"
val userInfoRDD: RDD[String] = session.sparkContext.textFile(inputUserInfoTxt)
- 通过已有的 RDD 经过算子转换生成新的 RDD:
val rdd2=rdd1.flatMap(_.split(" "))
- 由一个已经存在的 Scala 集合创建:
val rdd3 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
val rdd4 = sc.makeRDD(List(1,2,3,4,5,6,7,8))
makeRDD 方法底层调用了 parallelize 方法
2.2 RDD算子
RDD算子分为两类:
Transformation:转换操作,返回一个新的RDD
Action:动作操作,返回值不是RDD(无返回值或者其他)
- RDD不实际存储真正计算的数据,而是记录了数据的位置,数据的转化关系
- RDD中所有的操作都是惰性求值/延迟执行的,即不会直接计算。只有当发生一个要求返回结果给Driver的Action动作时,这些转换才会真正运行
- 之所以使用惰性求值/延迟执行,是因为这样可以在Action时对RDD操作形成DAG有向无环图进行Stage的划分和并行优化,整体运行更有效率。
2.3 RDD转换算子
| 转换算子 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由func函数计算后返回值为true的输入元素组成 |
| flagMap(func) | 类似map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是一个单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func函数类型必须是Iterator[T]=>Iterator[U] |
| mapParritionWithIndex(func) | 类似于 mapPartitions,但 func 带有一个整数参数表示分片的索引值,因此在类型为 T 的 RDD 上运行时,func 的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | 根据 fraction 指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed 用于指定随机数生成器种子 |
| union(otherDataset) | 对源RDD和参数RDD求并集并返回一个新的RDD |
| intersection(otherDataset) | 对源 RDD 和参数 RDD 求交集后返回一个新的 RDD |
| distinct([numTask]) | 对源 RDD 进行去重后返回一个新的 RDD |
| groupByKey([numTask)) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的 RDD 上调用,返回一个(K,V)的 RDD,使用指定的 reduce 函数,将相同 key 的值聚合到一起,与 groupByKey 类似,reduce 任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(SeqOp, combOp,[numTasks]) | 对 PairRDD 中相同的 Key 值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。和 aggregate 函数类似,aggregateByKey 返回值的类型不需要和 RDD 中 value 的类型一致 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口,返回一个按照 key 进行排序的(K,V)的 RDD |
| sortBy(func,[ascending],[numTasks]) | 与 sortByKey 类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素对在一起的(K,(V,W))的 RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable,Iterable))类型的 RDD |
| cartesian(otherDataset) | 笛卡尔积 |
| pipe(command, [envVars]) | 对 rdd 进行管道操作 |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。在过滤大量数据之后,可以执行此操作 |
| repartition(numPartitions) | 重新给RDD分区 |
2.4 Action算子
Action算子
| 动作算子 | 含义 |
|---|---|
| reduce(func) | 通过func函数聚集RDD中所有元素,这个功能必须是可交换且可并联的 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前 n 个元素组成的数组 |
| takeSample(withReplacement,num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的 num 个元素组成,可以选择是否用随机数替换不足的部分,seed 用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) | 返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) | 将数据集的元素以 textfile 的形式保存到 HDFS 文件系统或者其他支持的文件系统,对于每个元素,Spark 将会调用 toString 方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以 Hadoop sequencefile 的格式保存到指定的目录下,可以使 HDFS 或者其他 Hadoop 支持的文件系统 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的 map,表示每一个 key 对应的元素个数 |
| foreach(func) | 在数据集的每一个元素上,运行函数 func 进行更新 |
| foreachPartition(func) | 在数据集的每一个分区上,运行函数 func |
统计操作:
| 算子 | count | mean | sum | max | min | variance | sampleVariance | stdev | sampleStdev | stats |
|---|---|---|---|---|---|---|---|---|---|---|
| 含义 | 个数 | 均值 | 求和 | 最大值 | 最小值 | 方差 | 采样的方差 | 标准差 | 采样的标准差 | 查看统计结果 |
三、RDD的持久化/缓存
在实际开发中某些 RDD 的计算或转换可能会比较耗费时间,如果这些 RDD 后续还会频繁的被使用到,那么可以将这些 RDD 进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
3.1 持久化/缓存API
persist方法和cache方法
RDD通过persist或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立刻缓存,而是触发后面的action时,该RDD将被缓存在计算节点的内存中,并供后面重用。
RDD的cache()方法也是调用了persist方法实现。
3.1 存储级别
默认的存储级别都是仅在内存存储一份,Spark 的存储级别还有好多种,存储级别在 object StorageLevel 中定义的。
- RDD持久化/缓存的目的是为了提高后续操作的速度
- 缓存的级别有很多,默认只存在内存中,开发中使用memory_and_disk
- 只有还行action操作后才会真正将RDD数据进行持久化/缓存
- 持久化/缓存的应用场景为该RDD后续被频繁使用
| 持久化级别 | 说明 |
|---|---|
| MORY_ONLY(默认) | 将 RDD 以非序列化的 Java 对象存储在 JVM 中。如果没有足够的内存存储 RDD,则某些分区将不会被缓存,每次需要时都会重新计算。这是默认级别 |
| MORY_AND_DISK(开发中可以使用这个) | 将 RDD 以非序列化的 Java 对象存储在 JVM 中。如果数据在内存中放不下,则溢写到磁盘上.需要时则会从磁盘上读取 |
| MEMORY_ONLY_SER (Java and Scala) | 将 RDD 以序列化的 Java 对象(每个分区一个字节数组)的方式存储.这通常比非序列化对象(deserialized objects)更具空间效率,特别是在使用快速序列化的情况下,但是这种方式读取数据会消耗更多的 CPU |
| MEMORY_AND_DISK_SER (Java and Scala) | 与 MEMORY_ONLY_SER 类似,但如果数据在内存中放不下,则溢写到磁盘上,而不是每次需要重新计算它们 |
| DISK_ONLY | 将 RDD 分区存储在磁盘上 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2 等 | 与上面的储存级别相同,只不过将持久化数据存为两份,备份每个分区存储在两个集群节点上 |
| OFF_HEAP(实验中) | 与 MEMORY_ONLY_SER 类似,但将数据存储在堆外内存中。(即不是直接存储在 JVM 内存中) |
四、RDD容错机制Checkpoint
4.1 持久化的局限
持久化/缓存可以把数据放在内存中,虽然快速,但是不可靠;也可以放在磁盘的,但是也不完全可靠,例如磁盘会损坏
4.2 解决方法
Checkpoint的时候一般把数据放在HDFS上,借助了 HDFS 天生的高容错、高可靠来实现数据最大程度上的安全,实现了 RDD 的容错和高可用。
SparkContext.setCheckpointDir("目录") //HDFS的目录
RDD.checkpoint
4.3 持久化和Checkpoint的区别
- Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存–实验中) Checkpoint 可以保存数据到 HDFS 这类可靠的存储上。
- 生命周期:Cache 和 Persist 的 RDD 会在程序结束后会被清除或者手动调用 unpersist 方法。 Checkpoint 的 RDD 在程序结束后依然存在,不会被删除。
五、RDD依赖关系
5.1 宽窄依赖
RDD 和它依赖的父 RDD 的关系有两种不同的类型,即
宽依赖(wide dependency/shuffle dependency):父RDD的一个分区只会被子RDD的一个分区依赖
窄依赖(narrow dependency):父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
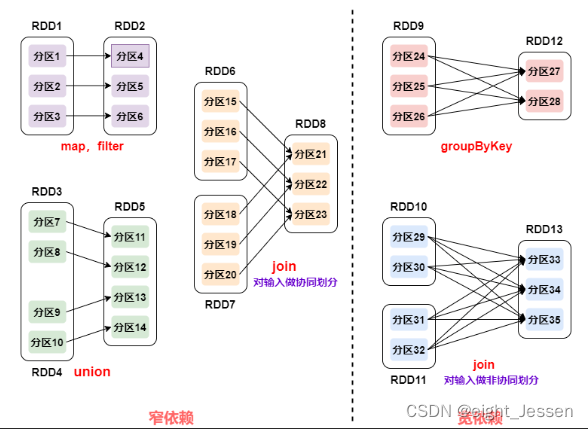
5.2 为什么涉及宽窄依赖
- 窄依赖
窄依赖的多个分区可以并行计算;
窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。 - 宽依赖
划分 Stage(阶段)的依据:对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
六、DAG的生成和划分Stage
6.1 DAG
6.1 DAG(Directed Acyclic Graph有向无环图)是什么
DAG指的是数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程);
原始的 RDD 通过一系列的转换操作就形成了 DAG 有向无环图,任务执行时,可以按照 DAG 的描述,执行真正的计算(数据被操作的一个过程)。
6.1.2 DAG的边界
开始:通过 SparkContext 创建的 RDD;
结束:触发 Action,一旦触发 Action 就形成了一个完整的 DAG。
6.2 DAG划分Stage
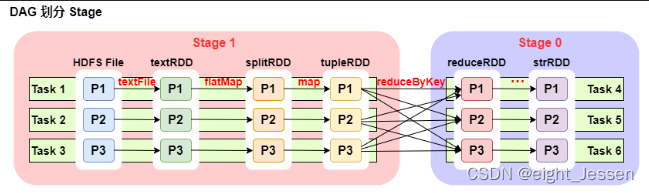
一个Spark程序可以有多个DAG(有几个Action,就有几个DAG)
一个DAG可以有多个Stage(根据宽依赖/shuffle进行划分)
同一个Stage可以有多个Task并行执行(task数=分区数,如上图,stage1有三个分区,对应也有三个Task)
DAG 中只 reduceByKey 操作是一个宽依赖,Spark 内核会以此为边界将其前后划分成不同的 Stage。
在图中 Stage1 中,从 textFile 到 flatMap 到 map 都是窄依赖,这几步操作可以形成一个流水线操作,通过 flatMap 操作生成的 partition 可以不用等待整个 RDD 计算结束,而是继续进行 map 操作,这样大大提高了计算的效率。
6.2.1 划分Stage的好处
并行计算
一个复杂的业务逻辑如果有 shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。
按照 shuffle 进行划分(也就是按照宽依赖就行划分),就可以将一个 DAG 划分成多个 Stage/阶段,在同一个 Stage 中,会有多个算子操作,可以形成一个 pipeline 流水线,流水线内的多个平行的分区可以并行执行。
6.2.2 如何划分DAG的stage
对于窄依赖,partition 的转换处理在 stage 中完成计算,不划分(将窄依赖尽量放在在同一个 stage 中,可以实现流水线计算)。
对于宽依赖,由于有 shuffle 的存在,只能在父 RDD 处理完成后,才能开始接下来的计算,也就是说需要要划分 stage。
Spark 会根据 shuffle/宽依赖使用回溯算法来对 DAG 进行 Stage 划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的 stage/阶段中
参考论文:Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
七、RDD累加器和广播变量
当 Spark 在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark 提供了两种类型的变量:
- 累加器accumulators:累加器支持在所有不同节点之间进行累加计算(比如计数或者求和)。
- 广播变量broadcast variables:
把变量在所有节点的内存之间进行共享,在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。
7.1 Accumulators
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。这时使用累加器就可以实现我们想要的效果:
import org.apache.spark.sql.SparkSession
object MyAccumulater {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("MY ACCUMULATOR").getOrCreate()
// 使用scala集合完成累加
var counter = 0
val data = Seq(1, 2, 3)
data.foreach(x => counter += x)
println(s"add $counter") // 6
// 使用RDD进行累加
var newCounter = 0
val newData = Seq(1, 2, 3)
val dataRdd = session.sparkContext.parallelize(newData)
dataRdd.foreach(x => newCounter += x)
println(s"session add $newCounter") //0
// foreach中的函数是传递给Worker中的Executor执行,用到了newCounter 变量
//而newCounter 变量在Driver端定义的,在传递给Executor的时候,各个Executor都有了一份counter2
//最后各个Executor将各自个x加到自己的newCounter 上面了,和Driver端的newCounter 没有关系
val AddCounter = session.sparkContext.longAccumulator("accumulator")
dataRdd.foreach(x => AddCounter.add(x))
println(s"accumulator add $AddCounter") //6
}
}
7.2 广播变量
package com.example
import org.apache.spark.sql.SparkSession
object MyBroadcast {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("MyBroadcast").getOrCreate()
val sc = session.sparkContext
sc.setLogLevel("WARN")
// 不使用广播变量
val kvFruit = sc.parallelize(List((1,"apple"),(2,"orange"),(3,"banana"),(4,"grape")))
val fruitMap = kvFruit.collectAsMap()
val fruitIds = sc.parallelize(List(2,4,1,3))
// 获取水果名
// 当数据量少的时候,这样运行没有问题
// 但是如果数据量大,Task数多,那么每个Task用到的fruitMap会被多次传输
// 应该要减少fruitMap的传输,一台机器上一个,被该台机器中的Task共用
val fruitNames = fruitIds.map(x => fruitMap(x))
fruitNames.foreach(println)
// 使用广播变量,将fruitMap放到各个机器上
// 注意: 广播变量的值不能被修改, 如需修改可以将数据存到外部数据源, 如MySQL、Redis
println("=====================")
val broadcastFruitMap = sc.broadcast(fruitMap)
val fruitNames2 = fruitIds.map(x => broadcastFruitMap.value(x))
fruitNames2.foreach(println)
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!