这应该是最全的大模型训练与微调关键技术梳理
作为算法工程师的你是否对如何应用大型语言模型构建医学问答系统充满好奇?是否希望深入探索LLaMA、ChatGLM等模型的微调技术,进一步优化参数和使用不同微调方式?现在我带大家领略大模型训练与微调进阶之路,拓展您的技术边界!
通过阅读文章,你可以详细学习LLaMA、ChatGLM等微调的相关知识和实践技巧。理解训练过程中的 Zero 等参数设置、数据准备(ChatGPT 训练数据生成流程)。
对于微调方式,本文将分别以 Lora 方式、Ptuning 方式为例,进行演示讲解,我们还会讲解合并LoRA 参数与原始参数的方法、Fsdp与Deepspeed 的全参数微调技巧等内容。最后,讲解模型效果的测评,还将对相关指标进行说明和分析,帮助大家掌握有效评估模型性能的方法。下面开始我们的分享:
一、大模型分布式训练并行技术
目前训练超大规模语言模型主要有两条技术路线:TPU + XLA + TensorFlow 和 GPU + PyTorch + Megatron-LM + DeepSpeed。前者由Google主导,由于TPU和自家云平台GCP深度绑定,对于非Google开发者来说, 只可远观而不可把玩,后者背后则有NVIDIA、Meta、微软等大厂加持,社区氛围活跃,也更受到群众欢迎。
数据并行(Data Parallel, DP)
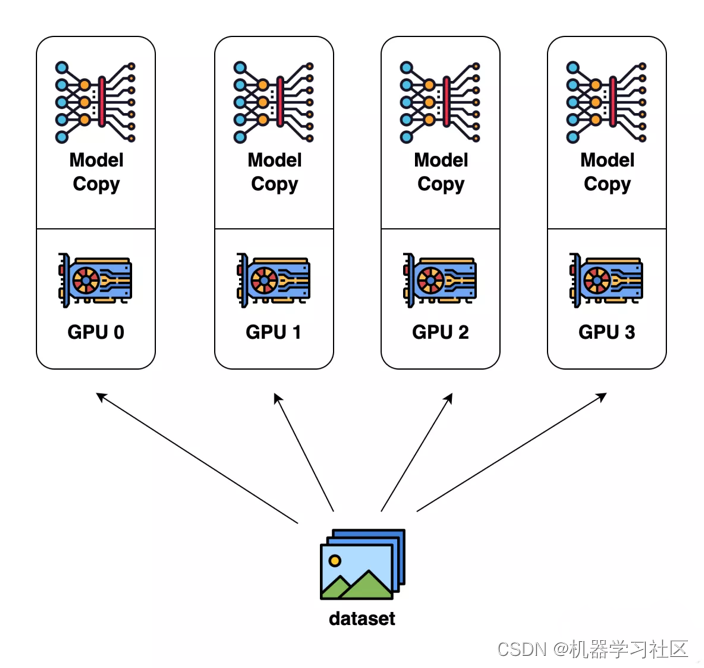
优点:可以不受单张GPU显存限制,训练更大的模型。
缺点:计算/通信效率低。
流水线并行(Pipeline Parallel, PP)
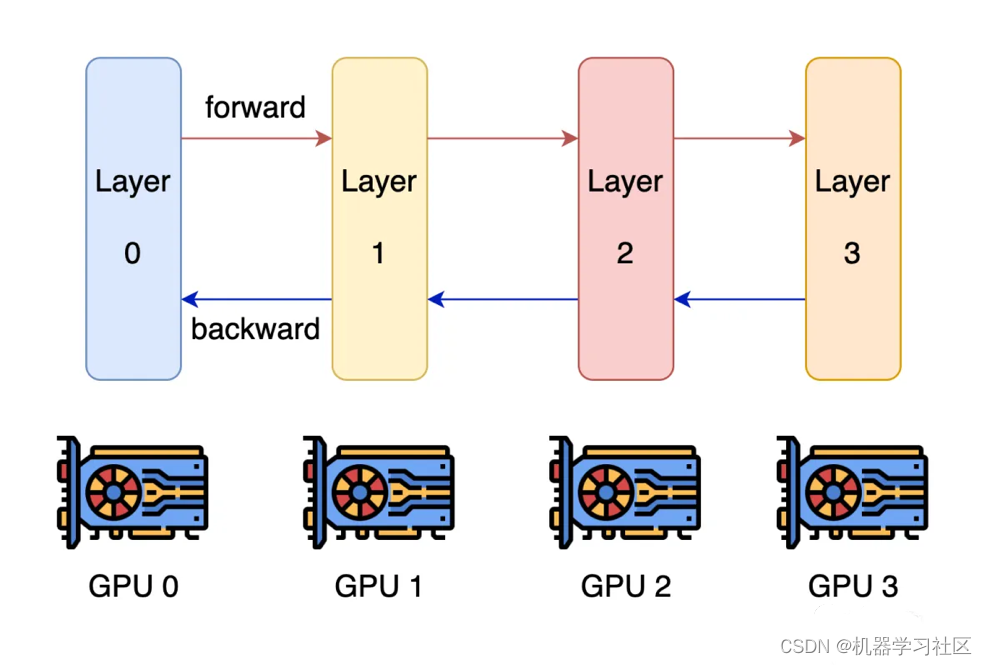
优点:层内计算/通信效率增加
缺点:存在空闲等待时间
流水线并行的核心思想是,模型按层分割成若干块,每块都交给一个设备。在前向传递过程中,每个设备将中间的激活传递给下一个阶段。在后向传递过程中,每个设备将输入张量的梯度传回给前一个流水线阶段。这允许设备同时进行计算,并增加了训练的吞吐量。流水线并行训练的一个缺点是,会有一些设备参与计算的冒泡时间,导致计算资源的浪费。
数据并行+流水线并行,如下图:

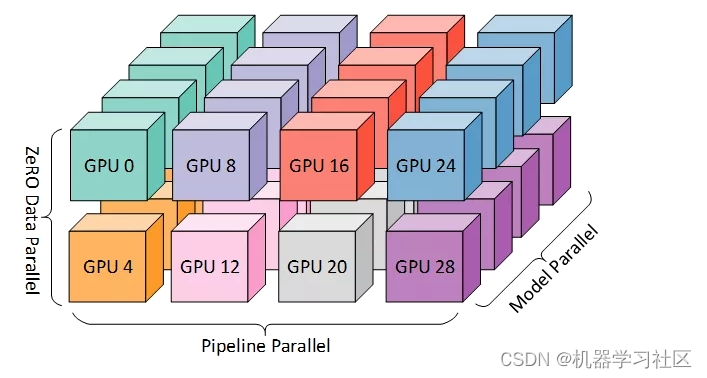
数据并行+流水线并行+模型并行,如下图:
二、训练-Deepspeed ZeRO模式
ZeRO(Zero Redundancy Optimizer)类似于张量并行进行切分,支持多种offload技术。目标:优化存储效率的同时还能保持较高的计算和通信效率。
为了能够在比较普通的机器上也能微调大模型,我们首先需要分析一下模型训练过程中都有哪些部分需要消耗存储空间。在进行深度学习训练的时候,有4大部分的显存开销,分别是模型参数(Parameters),模型参数的梯度(Gradients),优化器状态(Optimizer States)以及中间激活值(Intermediate Activations)。
ZeRO-DP
基于上述问题,提出了ZeRO-DP技术,即ZeRO驱动的数据并行,兼顾数据并行的计算/通信效率和模型并行的空间效率。首先ZeRO-DP会对模型状态进行分区,避免了复制模型导致的冗余,然后在训练期间使用动态通信调度保留数据并行的计算粒度和通信量,也能维持一个类似的计算/通信效率。
ZeRO-DP有三个优化阶段:① 优化器状态分区、② 梯度分区、③ 参数分区。
1.优化器状态分区(Optimizer State Partitioning, Pos):在与数据并行保持相同通信的情况下可以降低4倍空间占用;
2.① + 梯度分区(Gradient Partitioning, Pos+g):在与数据并行保持相同通信量的情况下可以降低8倍空间占用;
3.① + ② + 参数分区(Parameter Partitioning, Pos+g+p):空间占用减少量与GPU的个数呈线性关系 ,通信量增加50%。
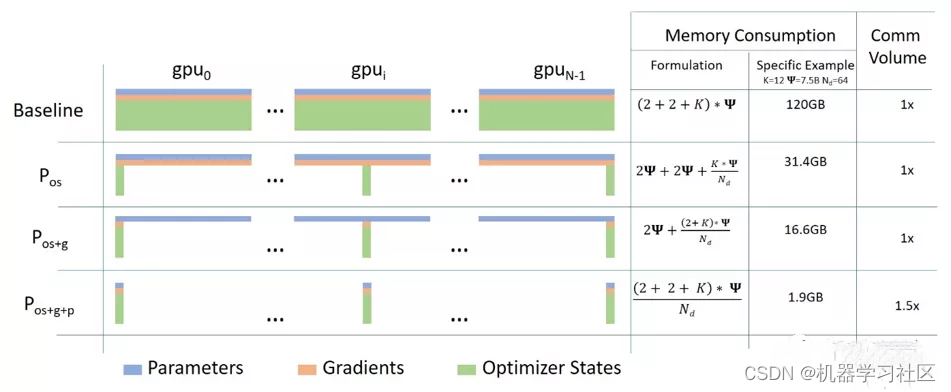
优化模型占用空间:在训练过程中当然模型占用的空间是最大的,但是现有的方法中,不管是数据并行DP还是模型并行MP都不能很好的解决。数据并行有很好的计算/通信效率,但是由于模型复制了多份,导致空间利用率很差,而模型并行虽然内存利用率高,但是由于对模型的进行了很精细的拆分,导致计算/通信效率很低。除此之外,所有这些方法都静态保存了整个训练过程中所需的所有模型参数,但实际上并不是整个训练期间都需要这些内容。
这里假设模型参数(fp16)、模型梯度(fp16)和Adam状态(fp32的模型参数备份,fp32的momentum和fp32的variance)。假设模型参数量 Φ ,则共需要 2Φ+2Φ+(4Φ+4Φ+4Φ)=4Φ+12Φ=16Φ 字节存储。
ZeRO-Offload
ZeRO说到底是一种数据并行方案,可是很多人只有几张甚至一张卡,显存加起来都不够,那怎么办呢?在操作系统中,当内存不足时,可以选择一些页面进行换入换出,为新的数据腾出空间。类比一下,既然是因为显存不足导致一张卡训练不了大模型,那么ZeRO-Offload的想法就是:显存不足,内存来补。在一个典型的服务器上,CPU 可以轻松拥有几百GB的内存,而每个 GPU 通常只有16或32GB的内存。相比于昂贵的显存,内存比较廉价,之前的很多工作都是聚焦在内存显存的换入换出,并没有用到CPU的计算能力,也没有考虑到多卡的场景。ZeRO-Offload则是将训练阶段的某些模型状态从GPU和显存卸载到CPU和内存。当然ZeRO-Offload并不希望为了最小化显存占用而牺牲计算效率, 否则的话还不如直接使用CPU和内存,因为即使将部分GPU的计算和显存卸载到CPU和内存,肯定要涉及到GPU和CPU、显存和内存的通信,而通信成本一般是非常高的,此外GPU的计算效率比CPU的计算效率高了好几个数量积,因此也不能让CPU参与过多的计算。
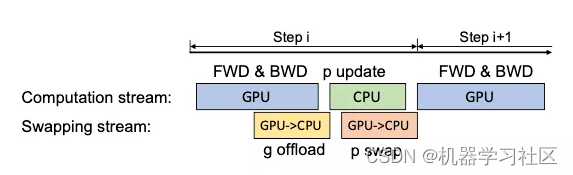
单卡场景-上图
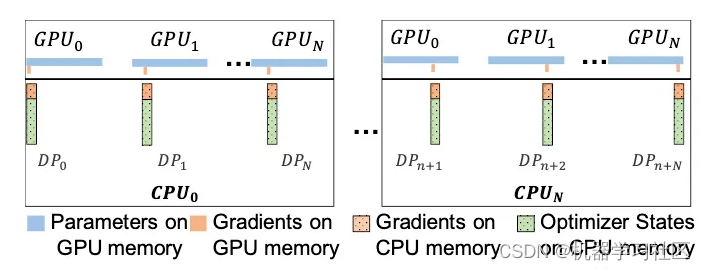
多卡场景-上图
现在的计算流程是,在GPU上面进行前向和后向计算,将梯度传给CPU,进行参数更新,再将更新后的参数传给GPU。为了提高效率,可以将计算和通信并行起来,GPU在反向传播阶段,可以待梯度值填满bucket后,一边计算新的梯度一边将bucket传输给CPU,当反向传播结束,CPU基本上已经有最新的梯度值了,同样的,CPU在参数更新时也同步将已经计算好的参数传给GPU,如下图所示。
到目前为止还都是单卡的场景,在多卡场景中,ZeRO-Offload可以利用ZeRO-2,将优化器状态和梯度进行切分,每张卡只保留,结合上ZeRO-Offload同样是将这的优化器状态和梯度卸载到内存,在CPU上进行参数更新。在多卡场景,利用CPU多核并行计算,每张卡至少对应一个CPU进程,由这个进程负责进行局部参数更新。
并且CPU和GPU的通信量和 N 无关,因为传输的是fp16 gradient和fp16 parameter,总的传输量是固定的,由于利用多核并行计算,每个CPU进程只负责 1N 的计算,反而随着卡数增加节省了CPU计算时间。
三、利用ChatGPT生成训练数据
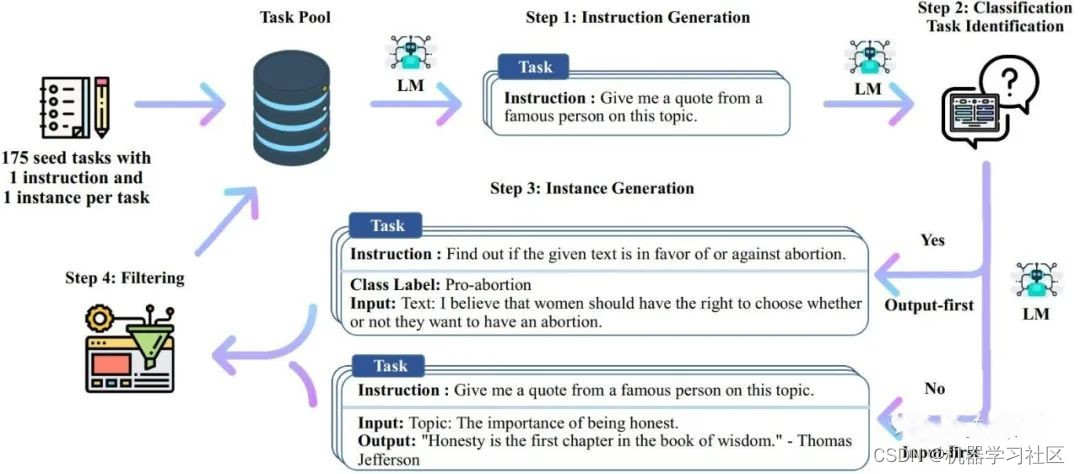
如何通过chatgpt生成新的指令:
generate_instruction_zh.py
Seed:
{“id”: “seed_task_174”, “name”: “事实核查”, “instruction”: “事实核查 - 根据您的知识和常识告诉我这个陈述是真、假还是未知。”, “instances”: [{“input”: “费城是美国前十大最安全城市之一。”, “output”: “假”}], “is_classification”: true}
指令生成所用到的提示:
请你给出20条不同的任务指令列表。这些任务指令将用于GPT模型的训练。
以下是要求:
1. 尽量不要重复每个指令的动词,以最大限度地提高多样性。
2. 指令的语言可以包含英语与简体中文。
3. 指令的类型应该是多样化的,列表中应包括不同类型的任务,如生成、分类、编辑等。
4. 以下指令不要输出:要求助手创建任何视觉或音频输出;要求助手在下午5点叫醒你或设置一个提醒。
5. 指令描述应该是简体中文。
6. 指令应该是1到2句话的长度。既可以是命令句,也可以是疑问句。
7. 你应该为指令生成一个适当的输入,输入栏应包含为指令提供的具体例子。它应涉及真实的数据,不包含简单的占位符。输入应提供实质性的内容,使指令具有挑战性,不要超过40字。
8. 不是所有的指令都需要输入。例如,当一个指令询问事实信息,“世界上最高的山峰是什么”,就没有必要提供具体的背景。在这种情况下,你只需在输入框中写上""。
9. 输出应该是对指令和输入的适当回应。确保输出的内容少于50字。
四、LoRA微调
LoRA的实现原理:冻结预训练模型权重,并将可训练的秩分解矩阵注入到Transformer层的每个权重中,大大减少了下游任务的可训练参数数量。直白的来说,实际上是增加了右侧的“旁支”,也就是先用一个Linear层A,将数据从 d维降到r,再用第二个Linear层B,将数据从r变回d维。最后再将左右两部分的结果相加融合,得到输出的hidden_state。
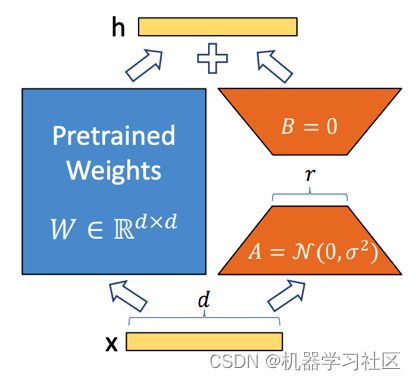

使用LoRA:
1、LoRA模型无法单独使用,需要搭配原版LLaMA模型,发布的是LoRA权重,可以理解为原LLaMA模型上的一个“补丁”,两者进行合并即可获得完整版权重。
2、LoRA 与 Transformer 的结合也很简单,仅在 QKV attention 中 QKV 的映射增加一个旁路(可看下文中具体的 LORA 网络结构),而不动MLP模块。基于大模型的内在低秩特性,增加旁路矩阵来模拟全模型参数微调,LoRA通过简单有效的方案来达成轻量微调的目的,可以将现在的各种大模型通过轻量微调变成各个不同领域的专业模型。
五、Ptuning微调
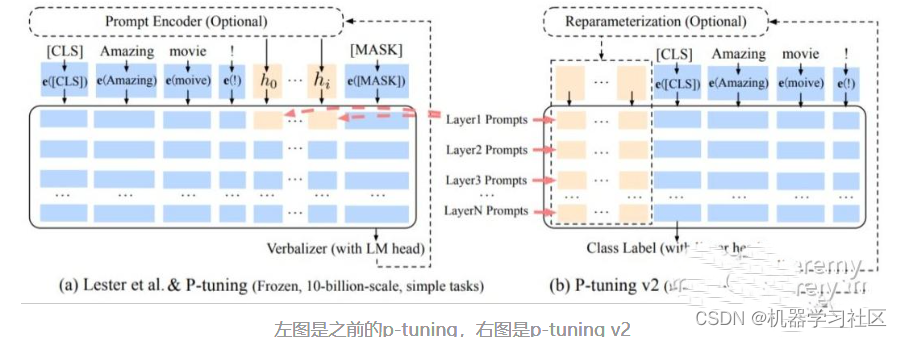
Github:chatglm-ptuning
prompt tuning, prefix tuning 和p-tuning v1 有一定的联系,这几种方法都是基于优化continuous prompt,之前的工作都是手动设计模板或者自动生成模板,统称discrete prompt。discrete prompt有一定的局限性,找出的结果可能不是最优,而且对token的变动十分敏感,所以之后的研究方向也都是连续空间内的prompt。
结语
文章中介绍了微调的部分核心知识,限于文章的篇幅关于训练(微调)-LLaMA代码结构、工具配置-Accelerate、工具配置-Deepspeed、工具配置-FSDP、训练(微调)-全参数微调、训练(微调)-LoRA微调、训练(微调)-Ptuning微调、结果评估的详细的讲解和代码实操,会在我们的课程中进行详细的阐述。希望文章能够对您的工作有所帮助和启发。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
建了技术答疑、交流群!想要进交流群、需要资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流
资料1

资料2

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!