Haproxy搭建Web群集
常见的Web集群调度器
目前常见的Web集群调度器分为软件和硬件
软件通常使用开源的LVS、Haproxy、Nginx。LVS 性能最好,但是搭建相对复杂; Nginx 的 upstream模块支持群集功能,但是对群集节点健康检查功能不强,高并发性能没有 Haproxy好
硬件一般使用比较多的是F5、Array,也有很多人使用国内的一些产品,如梭子鱼、绿盟等
Haproxy应用
Haproxy是可提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,是免费、快速并且可靠的一种解决方案。Haproxy非常适用于并发大(并发达1w以上)web站点,这些站点通常又需要会话保持或七层处理。Haproxy的运行模式使得它可以很简单安全的整合至当前的架构中,同时可以保护web服务器不被暴露到网络上。?LVS在企业应用中抗负载能力很强,但存在不足,LVS不支持正则处理,不能实现动静分离对于大型网站,LVS的实施配置复杂,维护成本相对较高。
HaProxy的主要特性
●可靠性和稳定性非常好,可以与硬件级的F5负载均衡设备相媲美;
●最高可以同时维护40000-50000个并发连接,单位时间内处理的最大请求数为20000个,最大处理能力可达10Git/s;
●支持多达8种负载均衡算法
●支持Session会话保持,Cookie的引导;
●支持通过获取指定的url来检测后端服务器的状态;
●支持虚机主机功能,从而实现web负载均衡更加灵活;
●支持连接拒绝、全透明代理等独特的功能;
●拥有强大的ACL支持,用于访问控制;
●支持TCP和HTTP协议的负载均衡转发;
●支持客户端的keepalive功能,减少客户端与haproxy的多次三次握手导致资源浪费,让多个请求在一个tcp连接中完成
Haproxy负载均衡策略,常见的有如下8种
(1)roundrobin,表示简单的轮询
(2)static-rr,表示根据权重
(3)leastconn,表示最少连接(最小连接)者先处理
(4)source,表示根据请求源IP
(5)uri,表示根据请求的URI,做cdn需使用;
(6)url_param,表示根据请求的URl参数'balance url_param' requires an URL parameter name
(7)hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求;
(8)rdp-cookie(name),表示根据cookie(name)来锁定并哈希每一次TCP请求。
LVS、Nginx、Haproxy的区别
●LVS基于Linux操作系统内核实现软负载均衡,而HAProxy和Nginx是基于第三方应用实现的软负载均衡;
●LVS是可实现4层的IP负载均衡技术,无法实现基于目录、URL的转发。而HAProxy和Nginx都可以实现4层和7层技术,HAProxy可提供TCP和HTTP应用的负载均衡综合解决方案;
●LVS因为工作在ISO模型的第四层,其状态监测功能单一,而HAProxy在状态监测方面功能更丰富、强大,可支持端口、URL、脚本等多种状态检测方式;
●HAProxy功能强大,单纯从效率上来讲HAProxy会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的。但整体性能低于4层模式的LVS负载均衡;
●Nginx主要用于Web服务器或缓存服务器。Nginx的upstream模块虽然也支持群集功能,但是性能没有LVS和Haproxy好,对群集节点健康检查功能不强,只支持通过端口来检测,不支持通过URL来检测。
Haproxy搭建 Web 群集
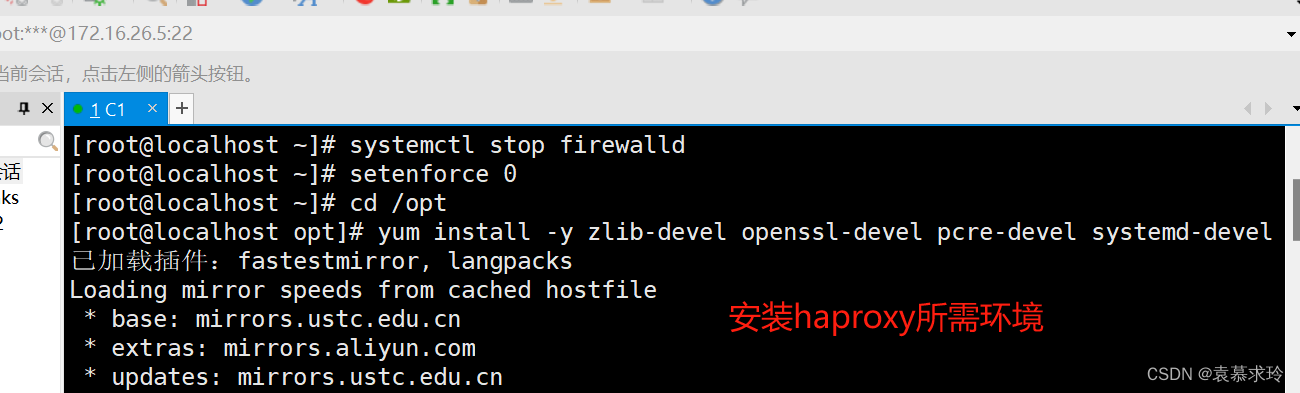
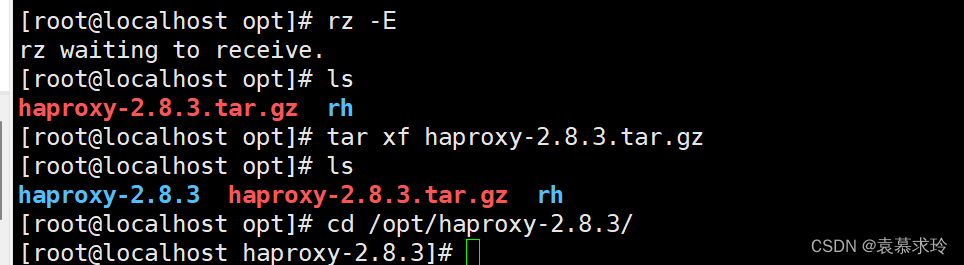
安装 Haproxy,关闭防火墙,将安装Haproxy所需软件包传到/opt目录下






![]()
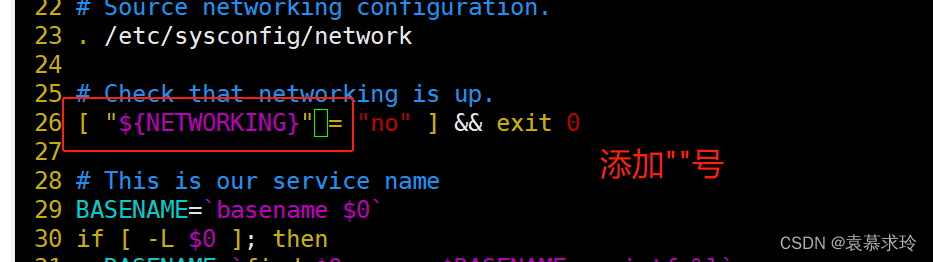
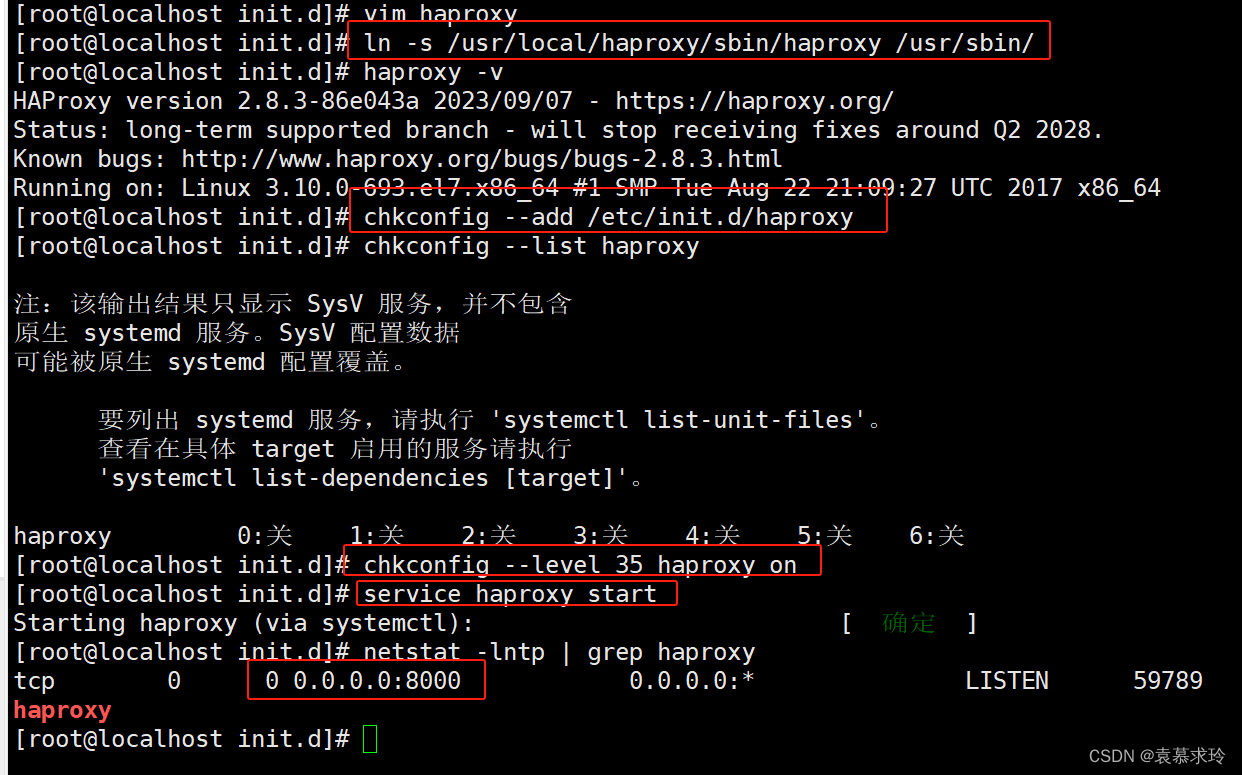
Haproxy服务器配置
HAProxy 的配置文件共有 5 个域:
●global:用于配置全局参数
●default:用于配置所有frontend和backend的默认属性
●frontend:用于配置前端服务(即HAProxy自身提供的服务)实例
●backend:用于配置后端服务(即HAProxy后面接的服务)实例组
●listen:frontend + backend的组合配置,可以理解成更简洁的配置方法,frontend域和backend域中所有的配置都可以配置在listen域下
vim haproxy.cfg
global #全局配置,主要用于定义全局参数,属于进程级的配置,通常和操作系统配置有关
#将info(及以上)的日志发送到rsyslog的local0接口,将warning(及以上)的日志发送到rsyslog的local1接口
log 127.0.0.1 local0 info
log 127.0.0.1 local1 warning
maxconn 30000 #最大连接数,HAProxy 要求系统的 ulimit -n 参数大于 maxconn*2+18
#chroot /var/lib/haproxy #修改haproxy工作目录至指定目录,一般需将此行注释掉
pidfile /var/run/haproxy.pid #指定保存HAProxy进程号的文件
user haproxy #以指定的用户名身份运行haproxy进程
group haproxy #以指定的组名运行haproxy,以免因权限问题带来风险
daemon #让haproxy以守护进程的方式工作于后台
#nbproc 1 #指定启动的haproxy进程个数,只能用于守护进程模式的haproxy,默认只启动一个进程。haproxy是单进程、事件驱动模型的软件,单进程下工作效率已经非常好,不建议开启多进程
spread-checks 2 #在haproxy后端有着众多服务器的场景中,在精确的时间间隔后统一对众服务器进行健康状况检查可能会带来意外问题;此选项用于将其检查的时间间隔长度上增加或减小一定的随机时长;默认为0,官方建议设置为2到5之间。
defaults #配置默认参数,这些参数可以被用到listen,frontend,backend组件
log global #所有前端都默认使用global中的日志配置
mode http #模式为http(7层代理http,4层代理tcp)
option http-keep-alive #使用keepAlive连接,后端为静态建议使用http-keep-alive,后端为动态应用程序建议使用http-server-close
option forwardfor #记录客户端IP在X-Forwarded-For头域中,haproxy将在发往后端的请求中加上"X-Forwarded-For"首部字段
option httplog #开启httplog,在日志中记录http请求、session信息等。http模式时开启httplog,tcp模式时开启tcplog
option dontlognull #不在日志中记录空连接
option redispatch #当某后端down掉使得haproxy无法转发携带cookie的请求到该后端时,将其转发到别的后端上
option abortonclose #当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
maxconn 20000 #最大连接数,“defaults”中的值不能超过“global”段中的定义
retries 3 #定义连接后端服务器的失败重连次数,连接失败次数超过此值后会将对应后端服务器标记为不可用
#contimeout 5000 #设置连接超时时间,默认单位是毫秒
#clitimeout 50000 #设置客户端超时时间,默认单位是毫秒
#srvtimeout 50000 #设置服务器超时时间,默认单位是毫秒
timeout http-request 2s #默认http请求超时时间,此为等待客户端发送完整请求的最大时长,用于避免类DoS攻击。haproxy总是要求一次请求或响应全部发送完成后才会处理、转发
timeout queue 3s #默认客户端请求在队列中的最大时长
timeout connect 1s #默认haproxy和服务端建立连接的最大时长,新版本中替代contimeout,该参数向后兼容
timeout client 10s #默认和客户端保持空闲连接的超时时长,在高并发下可稍微短一点,可设置为10秒以尽快释放连接,新版本中替代clitimeout
timeout server 2s #默认和服务端保持空闲连接的超时时长,局域网内建立连接很快,所以尽量设置短一些,特别是高并发时,新版本中替代srvtimeout
timeout http-keep-alive 10s #默认和客户端保持长连接的最大时长。优先级高于timeout http-request 也高于timeout client
timeout check 2s #和后端服务器成功建立连接后到最终完成检查的最大时长(不包括建立连接的时间,只是读取到检查结果的时长)
frontend http-in #定义前端域
bind *:80 #设置监听地址和端口,指定为*或0.0.0.0时,将监听当前系统的所有IPv4地址
maxconn 18000 #定义此端口上的maxconn
acl url_static1 path_beg -i /static /images #定义ACL,当uri以定义的路径开头时,ACL[url_static1]为true
acl url_static2 path_end -i .jpg .jpeg .gif .png .html .htm .txt #定义ACL,当uri以定义的路径结尾时,ACL[url_static2]为true
use_backend ms1 if url_static1 #当[url_static1]为true时,定向到后端域ms1中
use_backend ms2 if url_static2 #当[url_static2]为true时,定向到后端域ms2中
default_backend dynamic_group #其他情况时,定向到后端域dynamic_group中
backend ms1 #定义后端域ms1
balance roundrobin #使用轮询算法
option httpchk GET /test.html #表示基于http协议来做健康状况检查,只有返回状态码为2xx或3xx的才认为是健康的,其余所有状态码都认为不健康。不设置该选项时,默认采用tcp做健康检查,只要能建立tcp就表示健康。
server ms1.inst1 192.168.80.100:80 maxconn 5000 check inter 2000 rise 2 fall 3
server ms1.inst2 192.168.80.100:81 maxconn 5000 check #同上,inter 2000 rise 2 fall 3是默认值,可以省略
backend ms2 #定义后端域ms2
balance roundrobin
option httpchk GET /test.html
server ms2.inst1 192.168.80.101:80 maxconn 5000 check
server ms2.inst2 192.168.80.101:81 maxconn 5000 check
backend dynamic_group #定义后端域dynamic_group
balance roundrobin
option http-server-close
cookie HA_STICKY_dy insert indirect nocache
server appsrv1 192.168.80.100:8080 cookie appsrv1 maxconn 5000 check
server appsrv2 192.168.80.101:8080 cookie appsrv2 maxconn 5000 check
listen stats #定义监控页面
bind *:1080 #绑定端口1080
stats enable #启用统计报告监控
stats refresh 30s #每30秒更新监控数据
stats uri /stats #访问监控页面的uri
stats realm HAProxy\ Stats #监控页面的认证提示
stats auth admin:admin #监控页面的用户名和密码
●balance roundrobin?? ??? ?#负载均衡调度算法
roundrobin:轮询算法;leastconn:最小连接数算法;source:来源访问调度算法,类似于nginx的ip_hash●check 指定此参数时,HAProxy 将会对此 server 执行健康检查,检查方法在 option httpchk 中配置。同时还可以在 check 后指定 inter, rise, fall 三个参数, 分别代表健康检查的周期、连续几次成功认为 server UP、连续几次失败认为 server DOWN,默认值是 inter 2000 rise 2 fall 3
inter 2000?? ??? ?#表示启用对此后端服务器执行健康检查,设置健康状态检查的时间间隔,单位为毫秒
rise 2?? ??? ??? ?#设定server从离线状态重新上线需要成功检查的次数;不指定默认为2
fall 3?? ??? ??? ?#表示连续三次检测不到心跳频率则认为该节点失效●cookie:在 backend server 间启用基于 cookie 的会话保持策略,最常用的是 insert 方式。
cookie HA_STICKY_dy insert indirect nocache,指 HAProxy 将在响应中插入名为 HA_STICKY_dy 的 cookie,其值为对应的 server 定义中指定的值,并根据请求中此 cookie 的值决定转发至哪个 server。indirect ? ?#代表如果请求中已经带有合法的 HA_STICK_dy cookie,则 HAProxy 不会在响应中再次插入此 cookie
nocache ? ? #代表禁止链路上的所有网关和缓存服务器缓存带有 Set-Cookie 头的响应●若节点配置后带有“backup”表示该节点只是个备份节点,仅在所有在线节点都失效该节点才启用。不携带“backup”,表示为在线节点,和其它在线节点共同提供服务。
#frontend域和backend域中所有的配置都可以配置在listen域下
listen webcluster
bind *:80
option httpchk GET /test.html
balance roundrobin
server inst1 192.168.80.100:80 check inter 2000 rise 2 fall 3
server inst2 192.168.80.101:80 check inter 2000 rise 2 fall 3
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!