NeurIPS’23 Paper Digest | 如何把 LLM 的推理能力应用于事件序列预测?
为期一周的人工智能和机器学习领域顶级会议?NeurlPS?正在美国路易斯安那州新奥尔良市举办中。蚂蚁集团有?20?篇论文被本届会议收录,其中《Language
Models?Can?Improve?Event?Prediction?by?Few-Shot?Abductive?Reasoning》是由蚂蚁基础智能技术部、消费金融技术部与芝加哥丰田工业大学、芝加哥大学合作完成。
论文作者简介:薛思乔是这篇论文的主要作者,也是蚂蚁集团高级算法专家,主要研究方向是生成式序列模型?(sequential?modeling),他的研究成果曾多次发表于主流机器学习相关会议?(NeurIPS/ICML/AAAI)。最近一年团队的主要工作聚焦于大语言模型与时间序列的交叉方向,在?NeurIPS'23?发表了事件序列预测模型的持续学习方法?"PromptTPP"?以及利用大语言模型支持事件序列预测的方法?"LAMP"?两篇论文。
论文通讯作者介绍:梅洪源,美国丰田工业大学芝加哥分校?(Toyota?Technological?Institute?at?Chicago)?研究助理教授,2021?年获得约翰霍普金斯大学计算机系博士学位。主要研究方向包括大规模概率空间序列模型、机器人智能、自然语言处理等。至今已在?ICML,NeuIPS,NAACL?和?AAAI?等顶级国际会议发表论学术论文近?20?篇,其中部分论文有极高的引用率,得到了美国财富杂志?(Fortune?Magazine)?和彭博科技?(TechAtBloomberg)?的报道。由于杰出的研究贡献,他获得了彭博数据科学博士奖学金、Jelinke?奖学金以及?Adobe?Faculty?Award?等项目的资助。
本文中,薛思乔会带大家了解论文《Language?Models?Can?Improve?Event?Prediction?by?Few-Shot?Abductive?Reasoning》的背景和主要研究成果,完整论文可点击阅读原文查看。
背景和动机
商业场景的事件序列(时间序列),通常带有一些文字信息,如图一所示,比如用户购买商品会伴随着文字点评记录,用户申赎基金后也可能会参与社区讨论。
以往我们通常的做法是对这些文字做编码到高纬度空间,然后通过某些方式并入主模型的架构中,然后再输出预测值。有了大语言模型(LLM)?后,我们希望可以直接利用其强大的文字理解和推理能力,来支持序列预测。这个方法更直接,随着LLM?理解能力的突飞猛进,这个方法很可能也更有效。我们在一篇被?NeurIPS'23?接收的文章?Language?Model?Can?Improve?Event?Prediction?by?Few-shot?Abductive?Reasoning?中提出了新的架构?LAMP,实现了这个目标。

图1:用户购买商品的点评序列示意图
方法
01 整体思路
LLM?的引入类似于推荐里面的检索和精排机制。在?Base?model?的预测值基础上,利用?LLM?推理并且从历史序列中检索出?cause?events,根据这些事件序列,重新再做一次精排,最终输出预测值。

图2:整体思路示意图
02 模型架构
LAMP?架构可以分成三个部分:
-
Event?Sequence?Model:经典的序列模型,比如点过程模型、时序图谱模型等,对所有预测集合中的预测值(下文中的effect?event)做一个打分。
-
LLM:?给一个?effect?event,?推导出他的?cause?event。因为LLM?生成的是虚拟的事件,所以要做一个模式匹配(text?matching),?然后从真实的数据上找到真实的事件,重新拼成一个序列。
-
对上一步拼成的序列重新再做一次打分。

03 Prompt?模版

04 训练与预测
Event?Sequence?Model?和?Ranking?Model?都是用经典方法单独训练的,?LLM?直接调用接口,不做微调。训练与预测的细节见论文。论文原文:https://arxiv.org/abs/2305.16646
05 实验
我们在三个开源数据集,两个是时序图谱数据集?GDELT?和?ICEWS,一个是?推荐系统常用的?Amazon?Review?序列数据。我们用Mean?Rank?作为指标来衡量模型的性能。从?Base?Model?的预测值中取出分数最高的M个,然后对这M个进行重排(第二步和第三步),我们看?ground?truth?event?的排名会不会更好?(Rank?数值会更低,比如从排名第8?到?排名第?2)。
LLM?我们测试了?GPT-3.0?和?GPT-3.5?两个选择。在消融实验的时候我们也测试了?Llama2,详见文章的实验部分。
从结果来看,不同的?Base?Model?和?Ranking?Model?组合下,GPT-3.5?都能提升最终的预测性能,GPT-3.0?效果相对一般。开源的?LLM?中?Llama2?也表现较好。

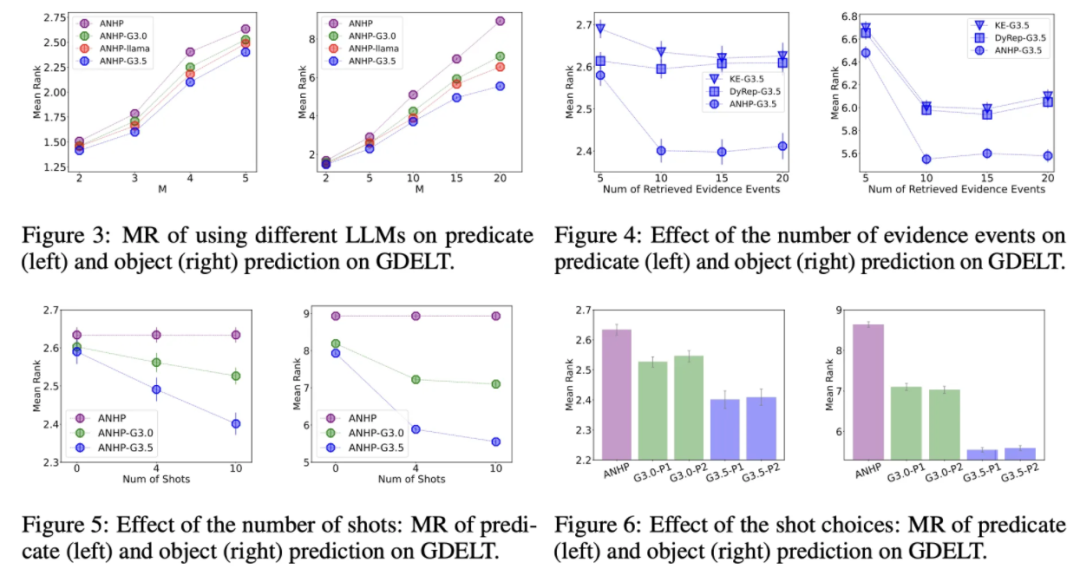
更多细节见论文的?section4?以及附录部分。论文原文:?https://arxiv.org/abs/2305.16646
结论
我们完成了首个把?LLM?推理能力引入事件序列领域的工作。代码、数据均已经开源,并将集成进开源库?EasyTPP。
EasyTPP?GitHub:?
https://github.com/ant-research/EasyTemporalPointProcess
关注我们,收货更多技术干货
微信公众号:金融机器智能

官网:https://openasce.openfinai.org/
GitHub:https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
官网:https://openagl.openfinai.org/
GitHub:https://github.com/TuGraph-family/TuGraph-AntGraphLearning
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!