[PyTorch][chapter 8][李宏毅深度学习][DNN 训练技巧]
前言:
? ?
? ? ? ?DNN 是神经网络的里面基础核心模型之一.这里面结合DNN 介绍一下如何解决
深度学习里面过拟合,欠拟合问题
目录:
- ? ? ?DNN 训练常见问题
- ? ? ?过拟合处理
- ? ? 欠拟合处理
- ? ? keras 项目
一? DNN 训练常见问题
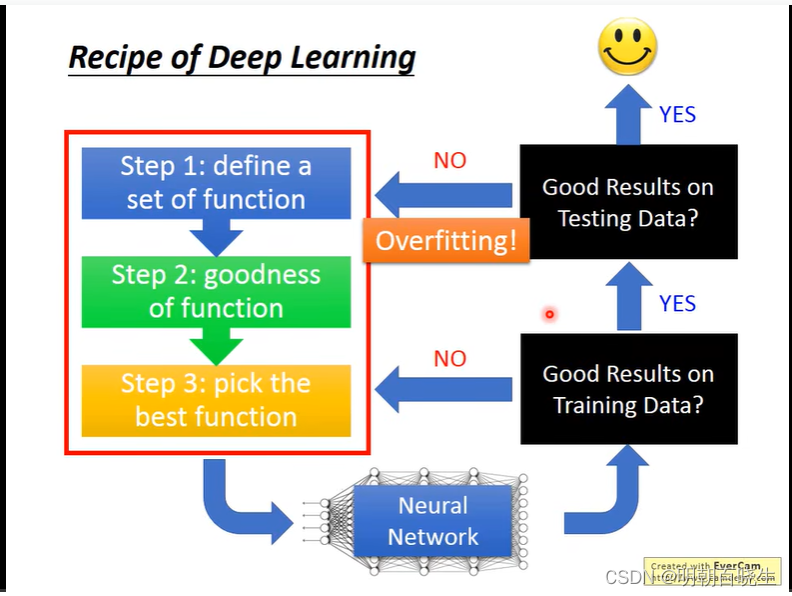
? 我们在深度学习网络训练的时候经常会遇到下面两类问题:
? ? ? ? ?1:? 训练集上面很差 : 欠拟合
? ? ? ? ?2: 训练集上面很好, 测试集上面很差: 过拟合
二? 过拟合解决
| 过拟合解决方案 |
| 主要有以下三个处理思路 |
| 1 Early Stopped |
| 2 L1 L2 正规化 |
| 3 Dropout 4: 增加训练集上面的数据量 |
?2.1? Early Stopping
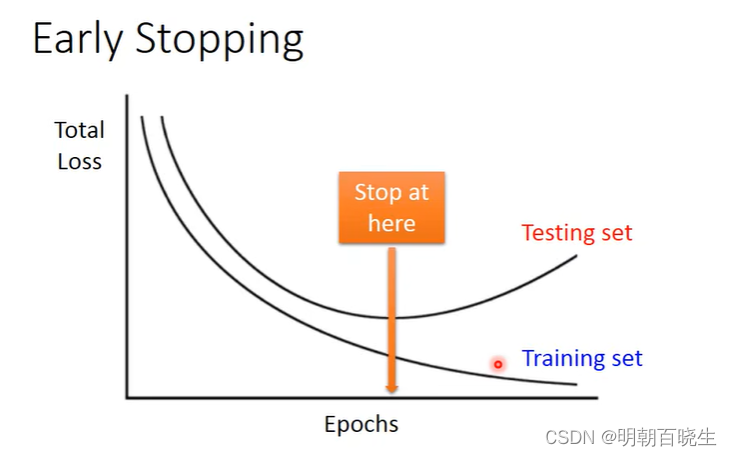
? ?方案
? ?这个数据集分为3部分: Training Data,validation data,Test Data
? ?1 ?将训练的数据分为Training Data 和validation data
? ?2 ?每个epoch结束后(或每N个epoch后):计算validation data 的 accuracy?
? ?3: 更新 最优 validation data accuracy 对应的网络参数
? ?3 ?随着epoch的增加,如果validation data 连续多次没有提升,则停止训练;
? ?4 ?将之前validation data 准确率最高时的权重作为网络的最终参数。
2.2? 正规化
? ? ? 分为L1,L2 正规化.


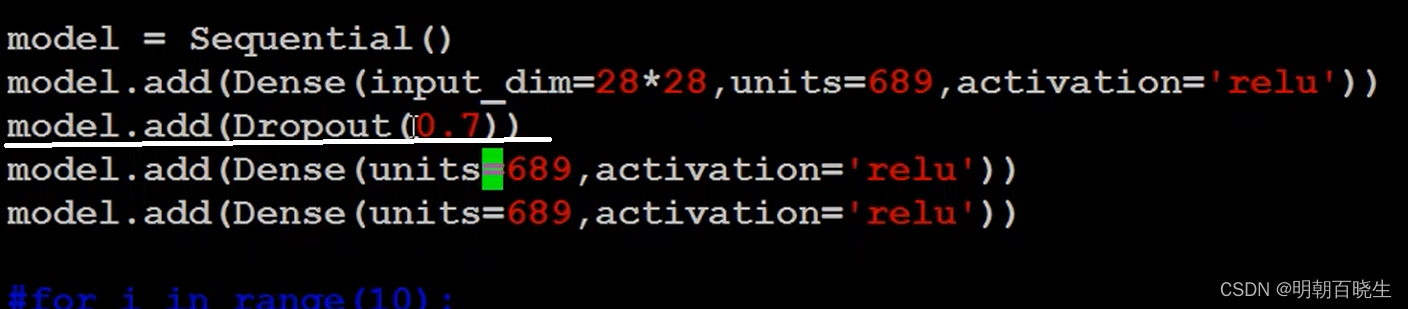
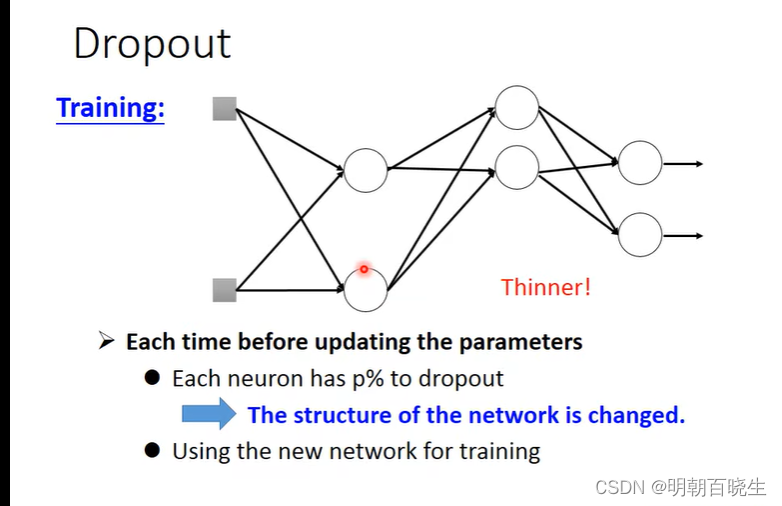
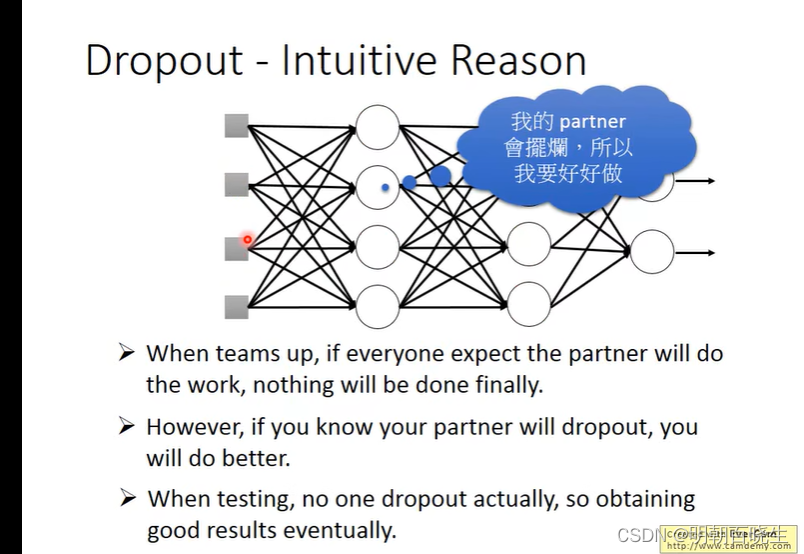
2.3 Dropout
原网络结构
? ? ? ? ? ??
? ? ? ? ? ??
训练:
? ? ? ? ? ? Dropout
? ? ? ? ? ??
: 上面每个输入值以p%的概率变为0? ? ?
? ? ? ? ? ?
? ? ? ? ? ??
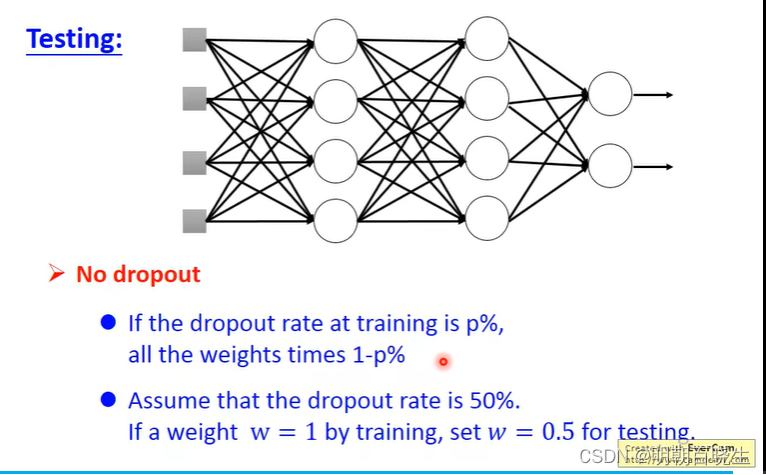
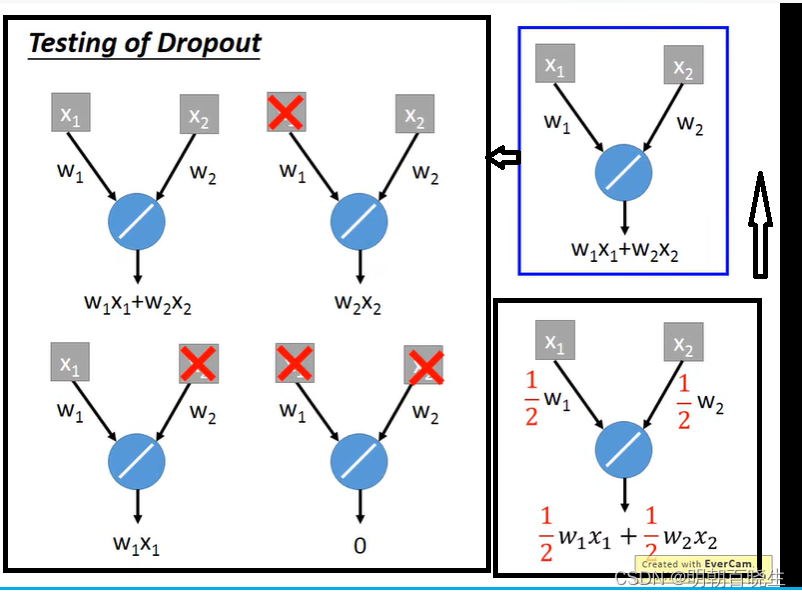
测试:?
? ? ? ? ? 权重系数
? ? ? ? ? ? ?
? ? ? ? ? ? 一般p 设置为0.5
? ? ? ? ? ?
、
4? 增加数据集上面数据量
? ? ? 作用? 降低方差
三? 欠拟合
| 欠拟合处理方案 |
| 主要有下面5个处理思路: |
| ? ? ?1 超参数调节: 学习率 训练轮次,batch_size ? ? ?2 更换激活函数 |
| ? ? ?3 梯度更新算法优化 ? ? ?4? 网络模型优化 ? ? ?5 损失函数 更换 |
3.1? 超参数调参
? ? ? ? ?主要更换学习率,增加迭代轮数等

?
3.2 更换激活函数
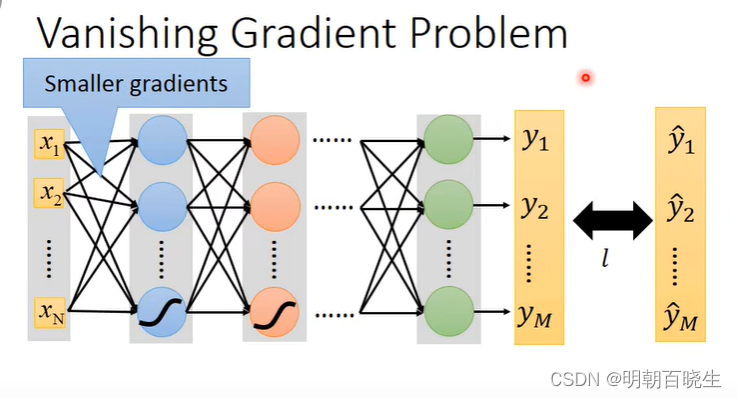
? ? ? DNN 随着网络层数的增加会出现梯度弥散现象,可以通过把激活函数sigmod 更换为
ReLu 一定程度上面优化该方案。? ??
? ? 更换激活函数 ReLu(导数为1,链式求导的时候连乘不会减少)


? ? ? ? 增加,减少 网络层数(梯度弥散,梯度爆炸)
? ? ? ??
3.3 梯度更新优化算法

? ? ? 方案1? SGD 随机梯度下降
? ? ? ? ?
? ? ? ? 当梯度为0,参数无法更新容易陷入到局部极小值点
? ? ? ? 学习率太大: 不容易进入到极小值点,容易发生网络震荡
? ? ? ? ?学习率太小: 收敛速度慢

?方案2 Momentum: 当前的梯度 = 当前的梯度+历史梯度
? ? ? ? ? ?SGD 会发生震荡而迟迟不能接近极小值,所以对更新梯度引入Momentum概念,加速SGD,并抑制震荡(也就是在SGD基础上引入了一阶动量)
? ? ? ? ? ? 初始化动量:
? ? ? ? ? ? ? ? ? ? ? ? ? ?
: 动量
? ? ?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
: 动量
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ?整个思想: 有点跟马尔科夫链时序链相似,当前输出值不仅仅跟当前的
输入相关,也跟历史值相关。
? ? ? ? ? ??
方案3:Adagrad (Adaptive Gradient,自适应梯度)
? ? ? ? ? ? ?不同参数进行不同程度的更新 - 逐参数适应学习率方法
? ? ? ? ? ?方案:
? ? ? ? ? 在Adagrad算法中,每个参数的学习率各不相同。计算某参数的学习率时需将该参数前面所有时间步的梯度平方求和,随着时间步的增加,学习率将减小.
? ? ??
? ? ? ?
? ? ??
?二阶动量,权重系数里面的每个系数单独计算
: 当前权重系数的梯度
Adgrad方法中,学习率一直在衰减,所以可以起到抑制震荡的作用,
对于频繁更新的参数,它们的二阶动量比较大,学习率小;
对于不怎么更新的参数,它们的二阶动量比较小,学习率就大。
但因为那个分母是单调递增的,会使得学习率单调递减至0,可能会使得训练过程提前结束,即便后续还有数据也无法学到必要的知识
? ??
方案4 RMSProp:
Root Mean Square Propagation,自适应学习率方法,由Geoff Hinton提出,是梯度下降优化算法的扩展。在AdaGrad的基础上,对二阶动量的计算进行了改进:即有历史梯度的信息,但是我又不想让信息一直膨胀,那么只要让历史信息一直衰减就好了。因此得到RMSProp的二阶动量计算公式:
如下图所示,截图来自:https://arxiv.org/pdf/1609.04747.pdf

方案4 Adam算法即自适应时刻估计方法(Adaptive Moment Estimation)
算法思想? moment+Adagrad
同时考虑了动量 和二阶动量

3.4? 更换损失函数
? ? ? 比如mse 更换成CRE

3.5 更换模型
? ? ? ? ?增加网络层次,参数例如

? ? ? 或者
? ? ? ? ? ?RNN 用LSTM??
? ? ? ? ? ?CNN 里面的ResNet
? ? ? ? ? ? ?解决梯度弥散问题
四? ??keras?
? ? ? ? ? Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化 [1]。
Keras在代码结构上由面向对象方法编写,完全模块化并具有可扩展性,其运行机制和说明文档有将用户体验和使用难度纳入考虑,并试图简化复杂算法的实现难度 [1]。Keras支持现代人工智能领域的主流算法,包括前馈结构和递归结构的神经网络,也可以通过封装参与构建统计学习模型 [2]。在硬件和开发环境方面,Keras支持多操作系统下的多GPU并行计算,可以根据后台设置转化为Tensorflow、Microsoft-CNTK等系统下的组件 [3]。
Keras的主要开发者是谷歌工程师Fran?ois Chollet,此外其GitHub项目页面包含6名主要维护者和超过800名直接贡献者 [4]。Keras在其正式版本公开后,除部分预编译模型外,按MIT许可证开放源代码 [1]
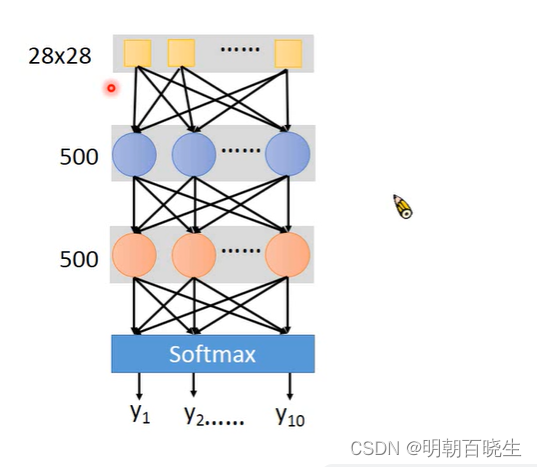
? ?keras 创建一个神经网络,训练,测试主要流程如下
| model | 模型搭建 |
| compile | 损失函数,loss, batch_size |
| fit | 训练 |
| evaluate | 验证测试集 |
| predict | 预测 |
model = Sequential()
#输入层
model.add(Dense(input_dim=28*28,
units = 500,
activation='relu'))
#1 隐藏层
model.add(Dense(units=500,
activation='relu'))
#2 输出层
model.add(Dense(units=10,
activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam'
metrics =['accuracy'])
#3 pick the best function ,完成训练工作
model.fit(x_train, y_train, batch_size=100, epochs=20)
#4 使用该模型
score = model.evaluate(x_test,y_test)
result = model.predict(x_test)参考:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!