RVC克隆自己的声音并令其唱歌
2024-01-08 16:19:09
克隆自己的声音并令其唱歌
准备工作
- 浏览器
- 声音文件,建议5分钟左右的清晰说话声音,wav格式
- autodl 网站(https://www.autodl.com/console/instance/list)上充个两块钱
- 阿里云盘
- replay软件
正式开始
-
在autodl上租用实例,这里以3080ti为例,镜像在社区镜像中搜索rvc,选择v3版本即可
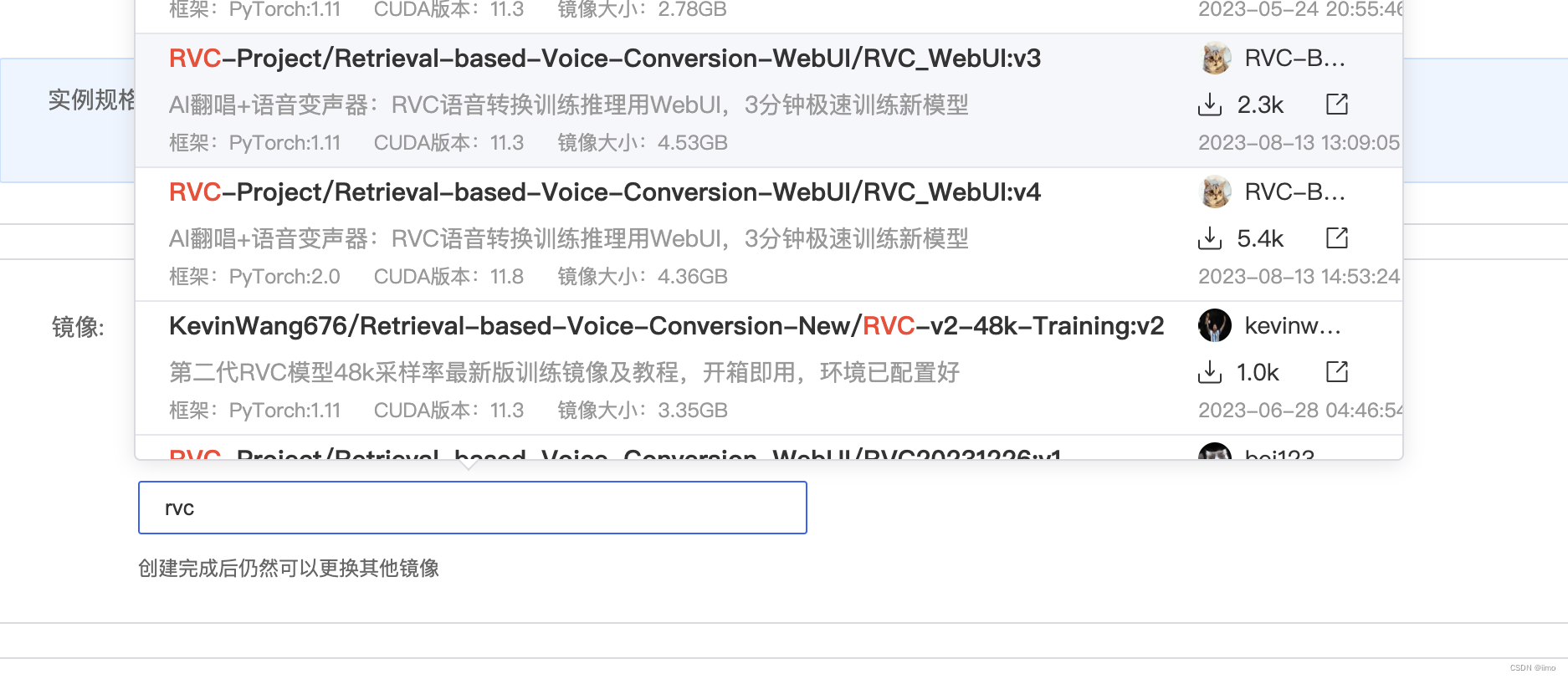
-
将镜像的详情页也打开,等会要用,也可以看看其介绍(https://www.codewithgpu.com/i/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/RVC_WebUI)
-
将你的声音文件上传至阿里云盘
-
打开实例的autopanel
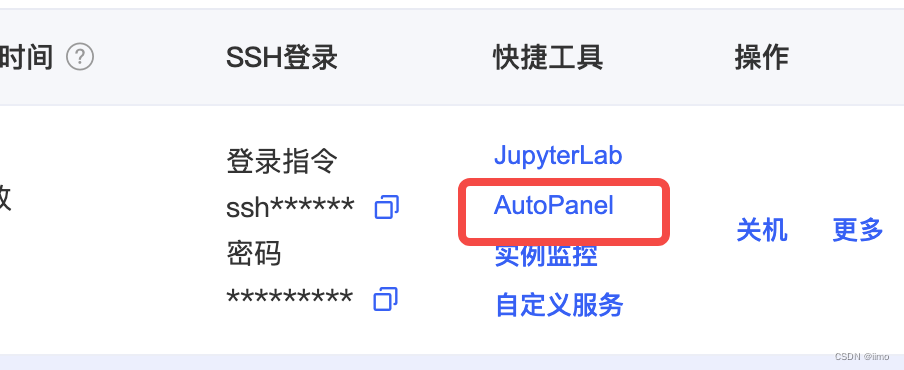
-
选择公网网盘-阿里云盘,下载你的声音文件到实例中,下载路径不用变
-
下载完成后,回到实例列表,点autopanel上方的jupyterlab
-
再打开刚才的镜像详情页拷贝启动代码,这里是
cd /root/Retrieval-based-Voice-Conversion-WebUI && python infer-web.py --port 6006
- 看到端口号就是启动成功了,回到实例列表,点击jupyterlab的自定义服务
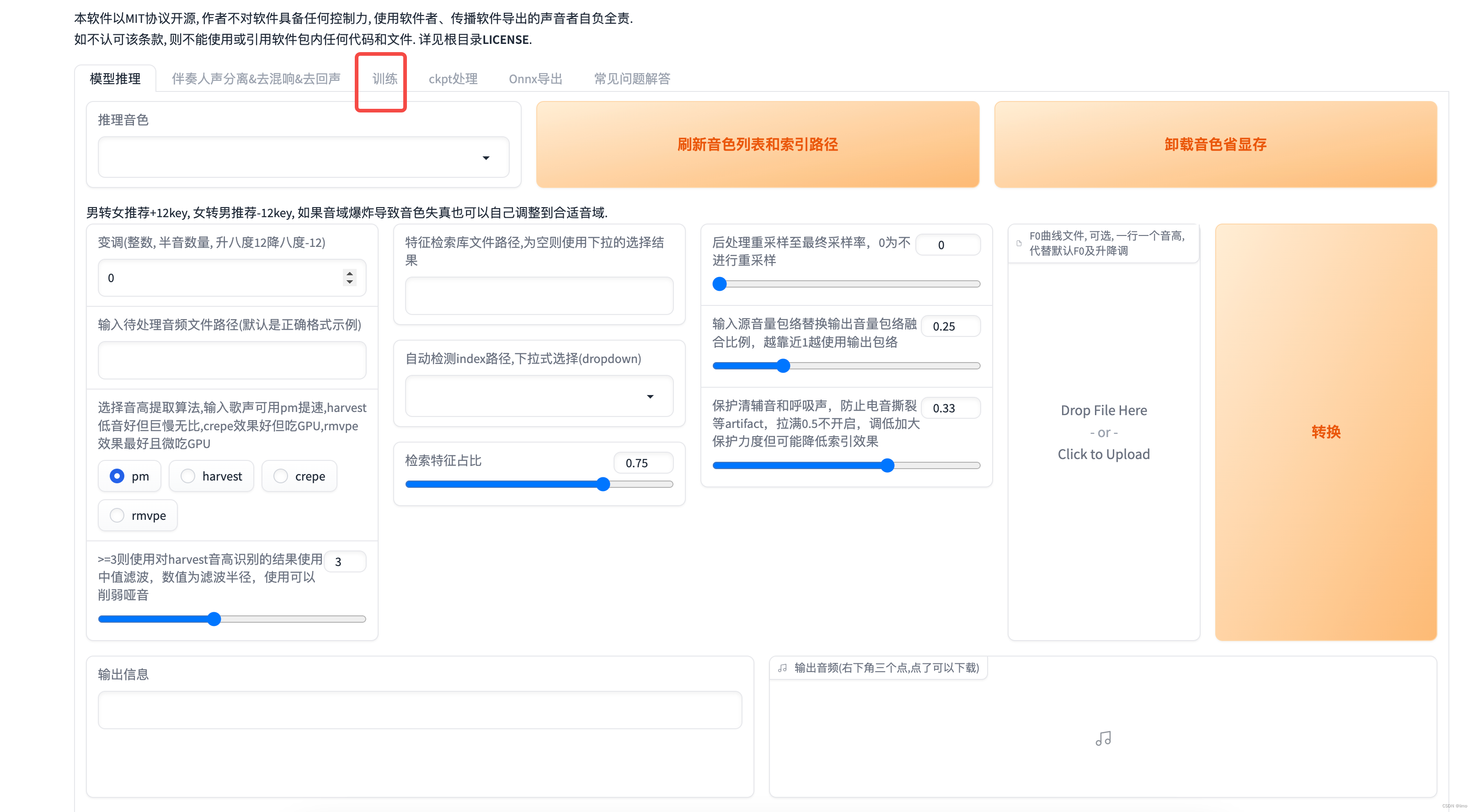
- 进入训练页面,填写必要信息
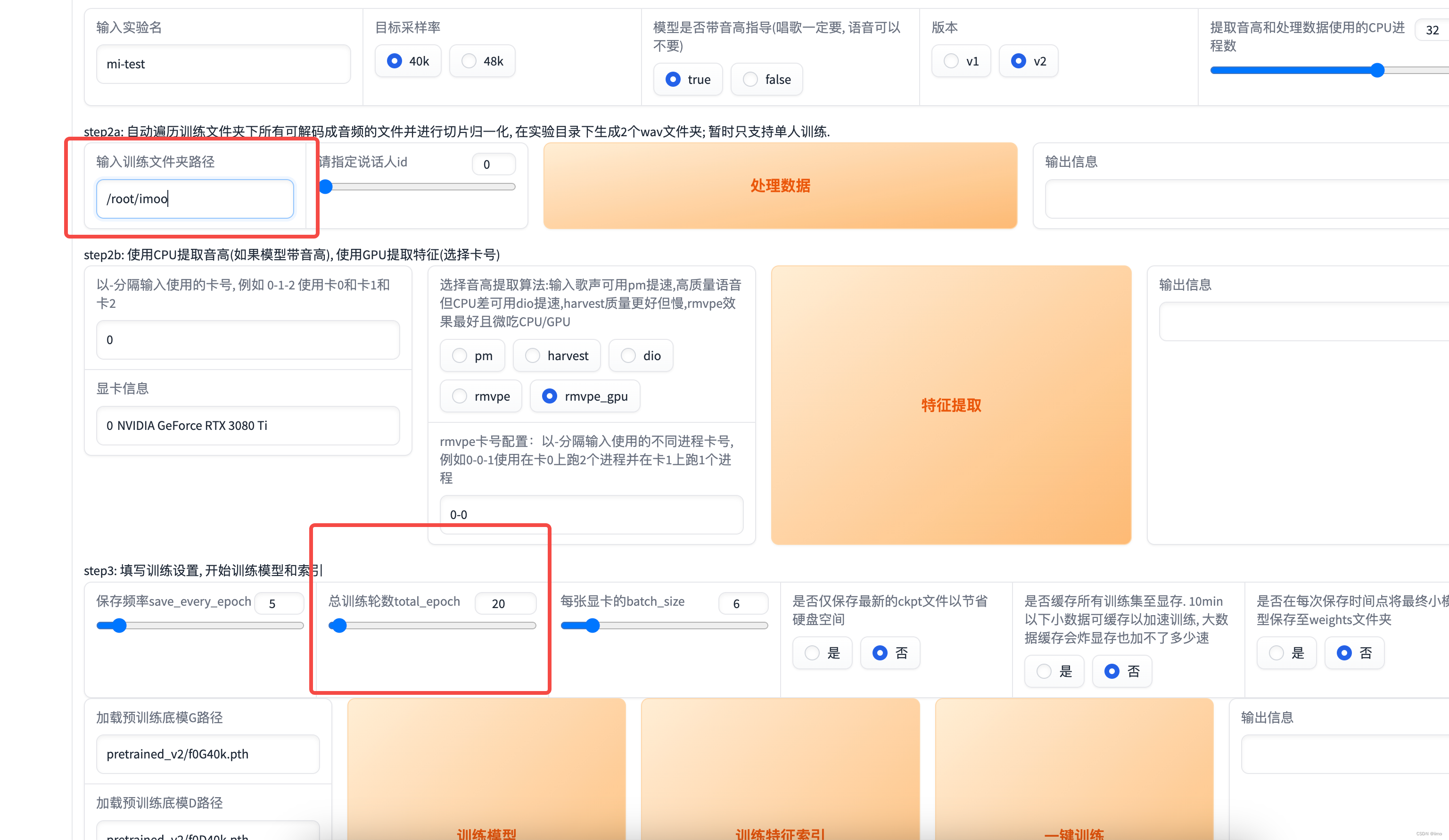
- 实验名:一会你生成的声音文件的名字
- 文件夹路径:/root/你刚才下载文件的地方,默认是 /root/auto-tmp
- 训练轮数:20够用,追求更好效果就开大点
-
点击开始训练,就会开始跑了,可以回到刚才的jupyterlab查看具体日志
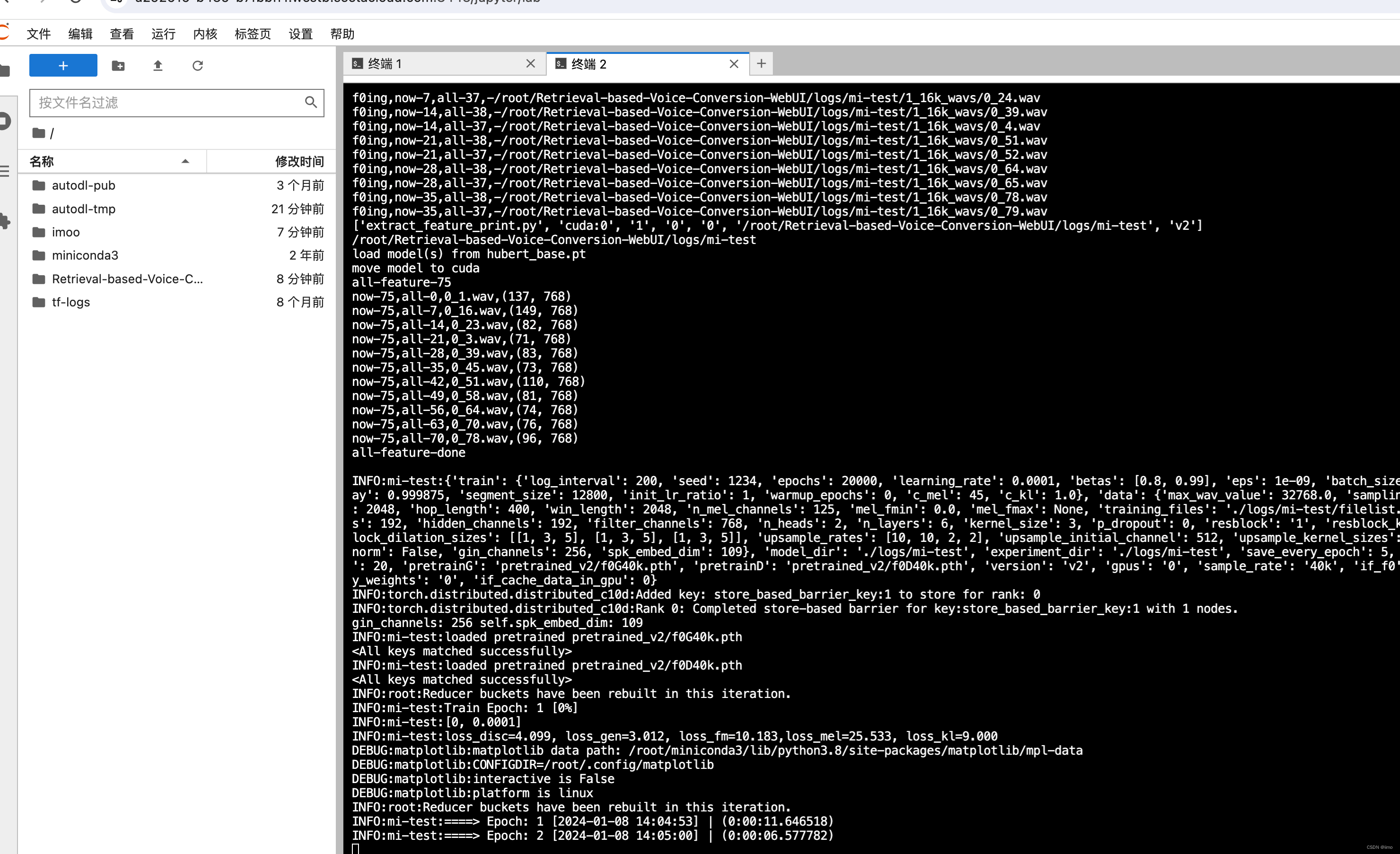
-
训练完成后,你可以在jupyterlab的/Retrieval-based-Voice-Conversion-WebUI/weights/找到训练结果,尾缀为.pth,这就是你的声音文件,将其下载到本地
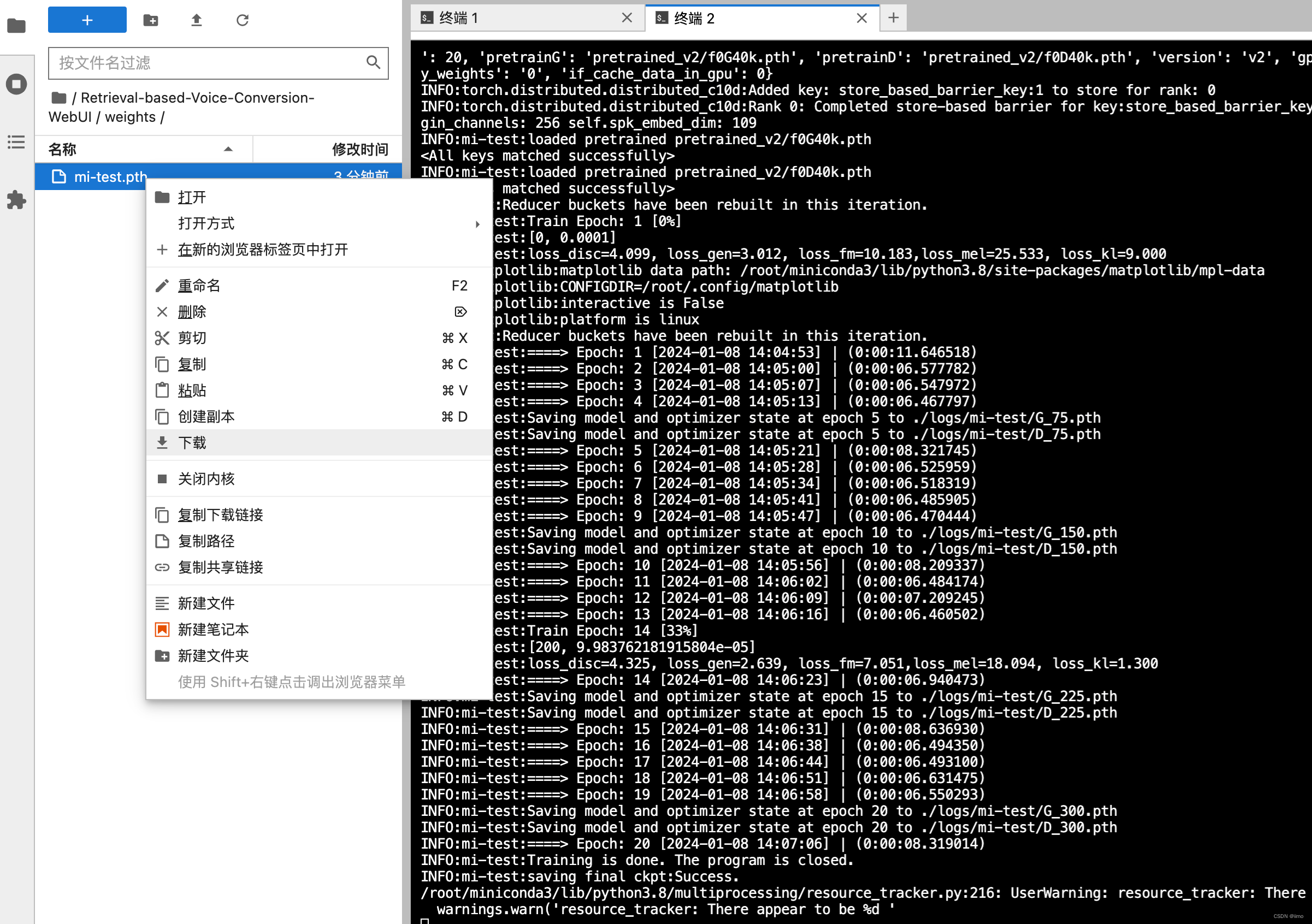
-
打开replay,将你的声音文件拖动进model
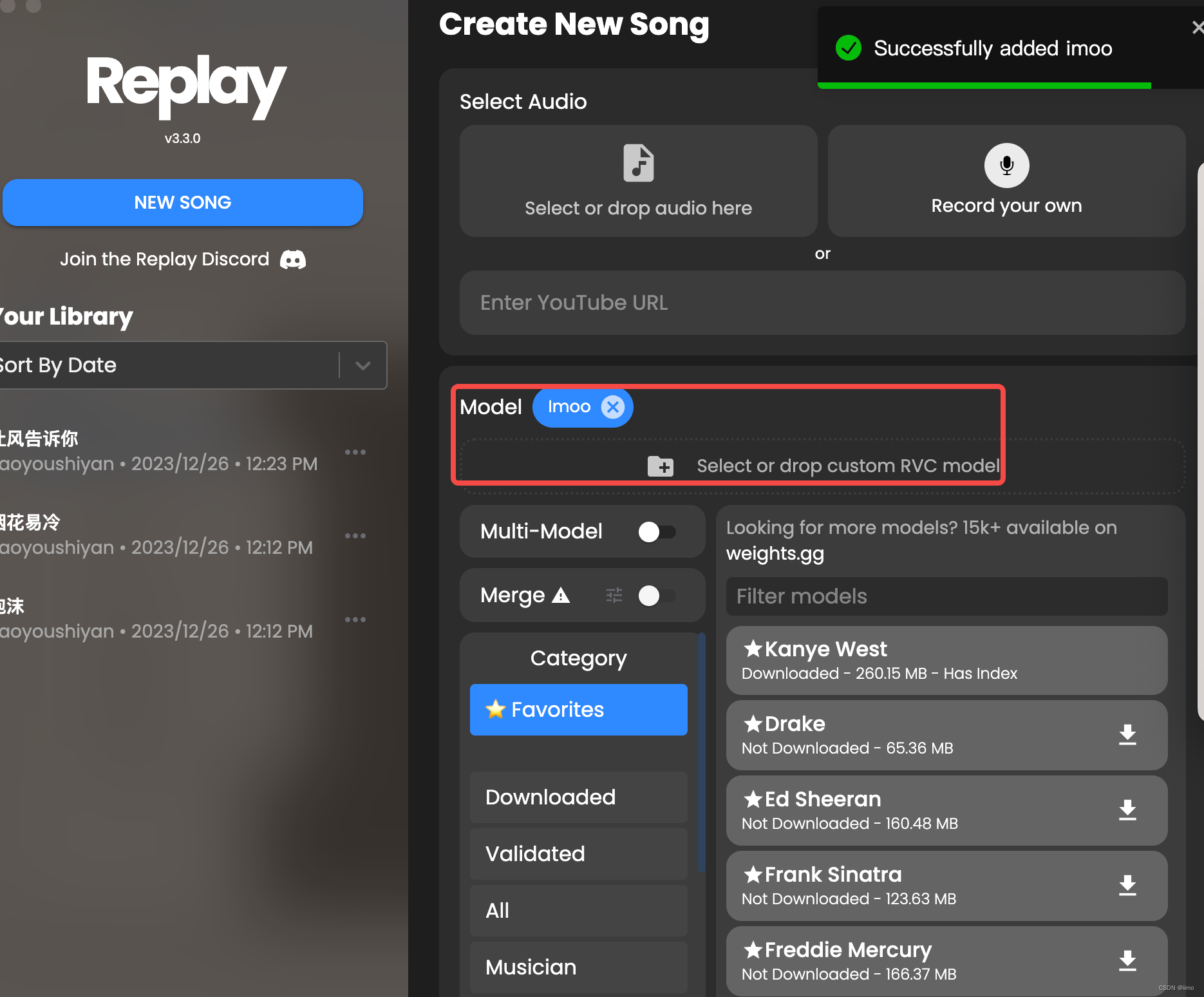
-
导入你的音乐,我找了一个烟花易冷.mp3,可以进行trim裁剪,因为歌太长会跑很久,可以先跑一下小段试试
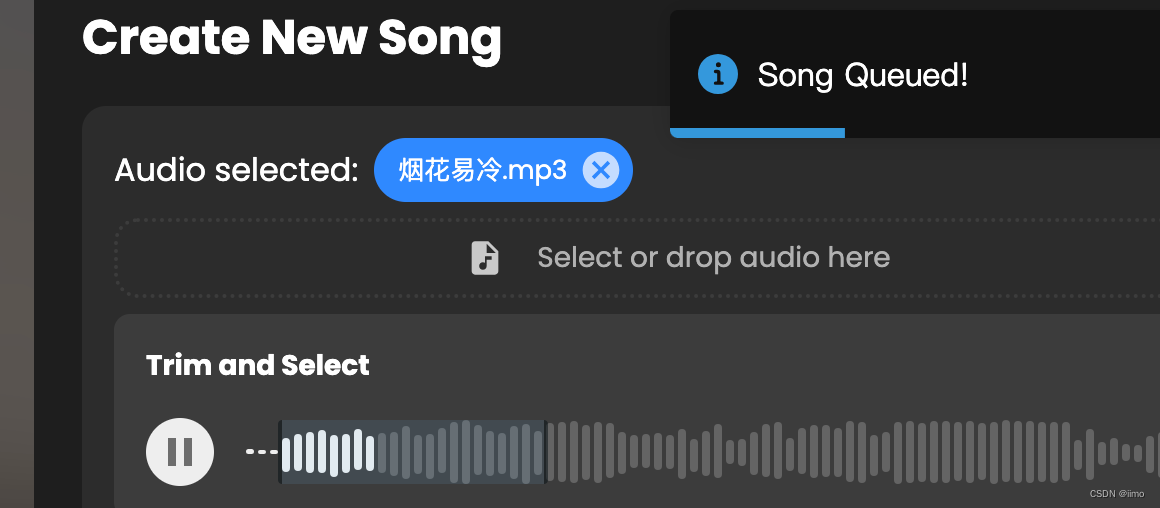
-
点击create生成,等待即可。
文章来源:https://blog.csdn.net/qq_41569151/article/details/135455328
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!