爬虫-微信公众号
2023-12-18 09:49:25
一、声明
本文章仅供学习参考,不可用于商业用途。
如有侵权请联系本人删除。
二、程序简介
本程序属于学习过程中的一个小项目。该程序在很多地方还存在不足,如若在阅读过程中存在疑问,请私信本人,谢谢。
三、实现过程
- 建立个人微信公众号(此步略过)
- 构建请求链接
- 爬取正文链接
- 爬取正文
1. 建立个人公众号
略
2. 构建请求链接
在进行此步时已经默认创建好了个人公众号
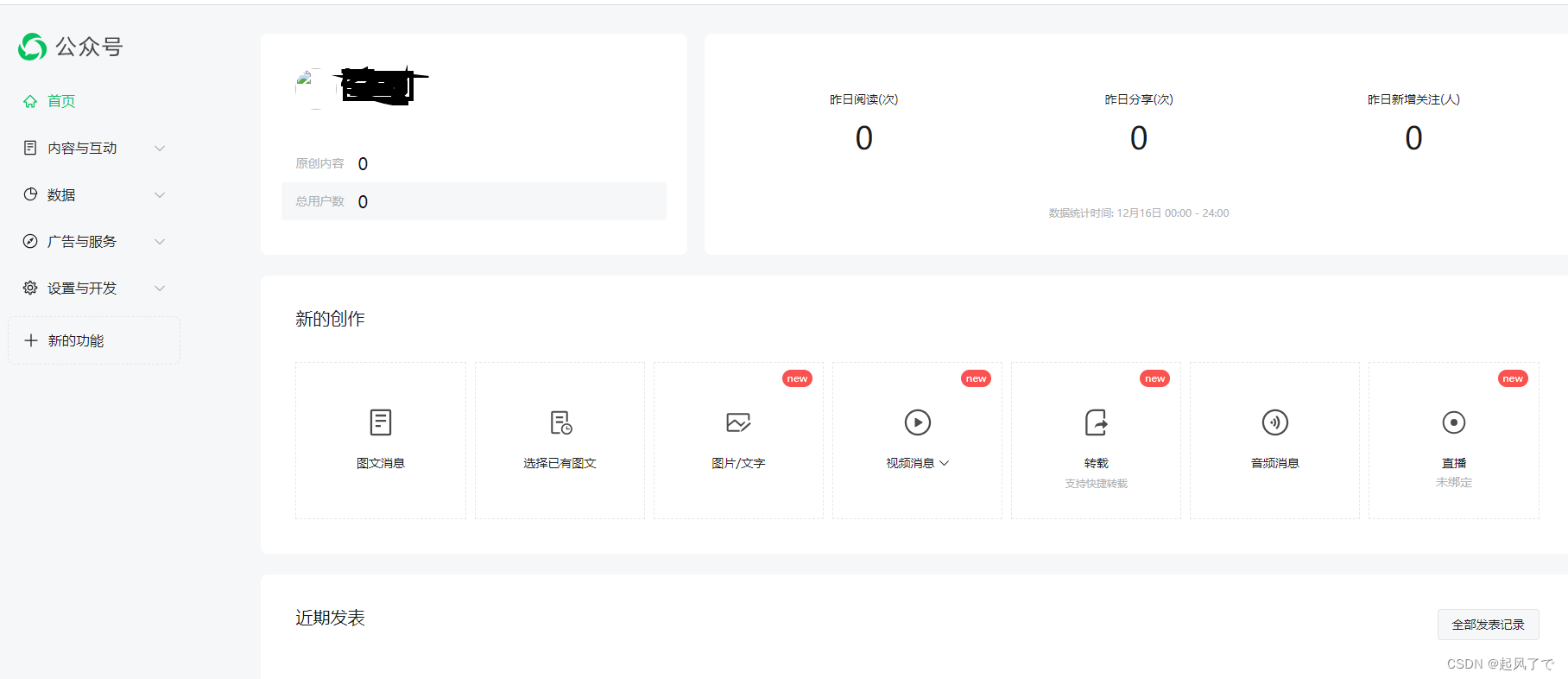
1、登录微信公众平台https://mp.weixin.qq.com/,登录后的界面如图所示:
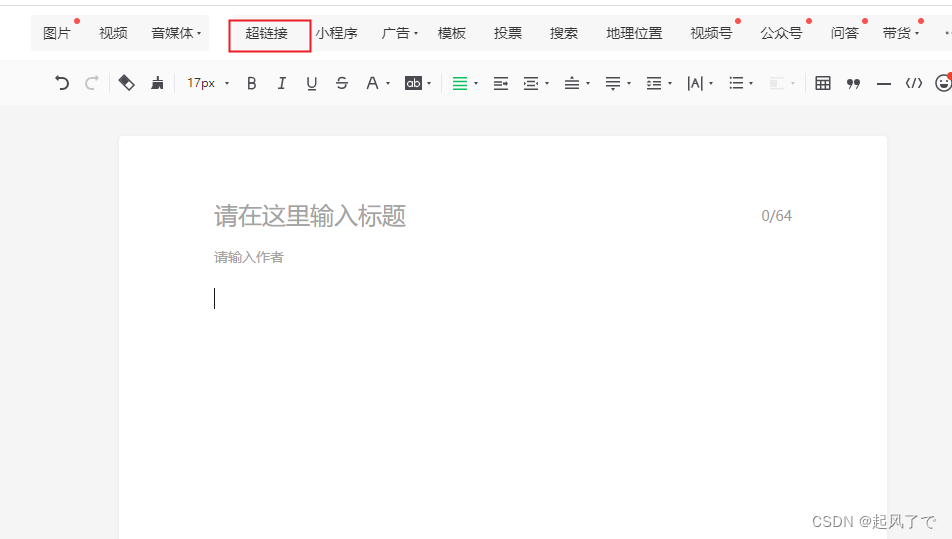
2、点击图文信息,光标放在正文处点击《超链接》、在浏览器按住F12将开发者工具调出来,
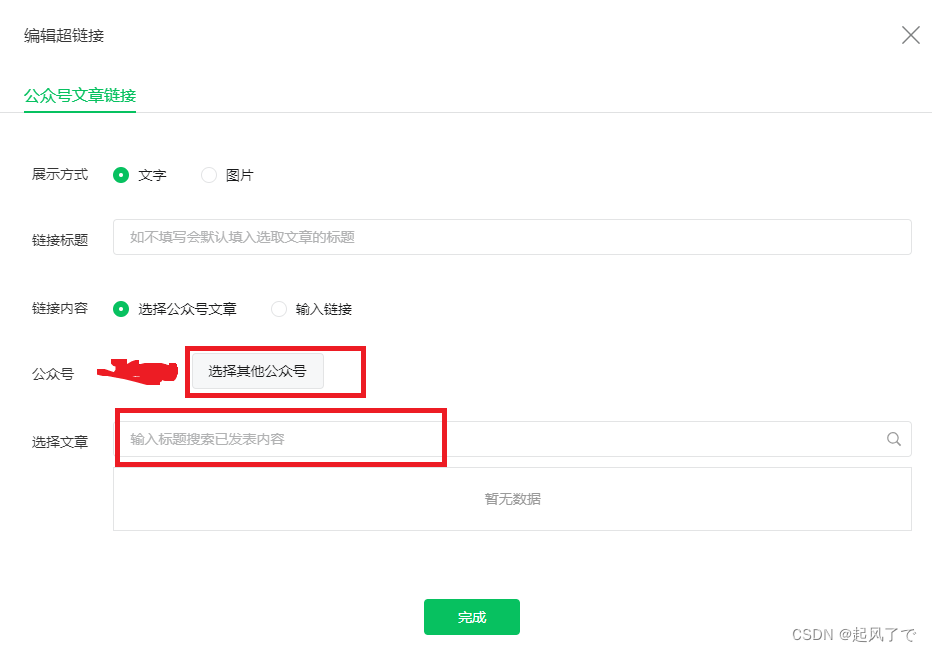
3、在弹出的点击《选择其它公众号》
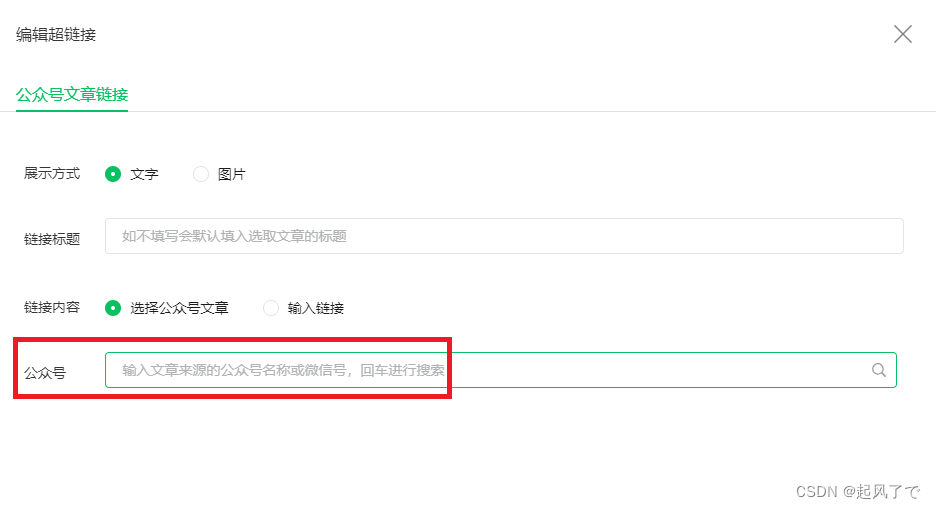
4、输入你需要爬取的微信公众号名称
5、点击搜索后会弹出如下界面:
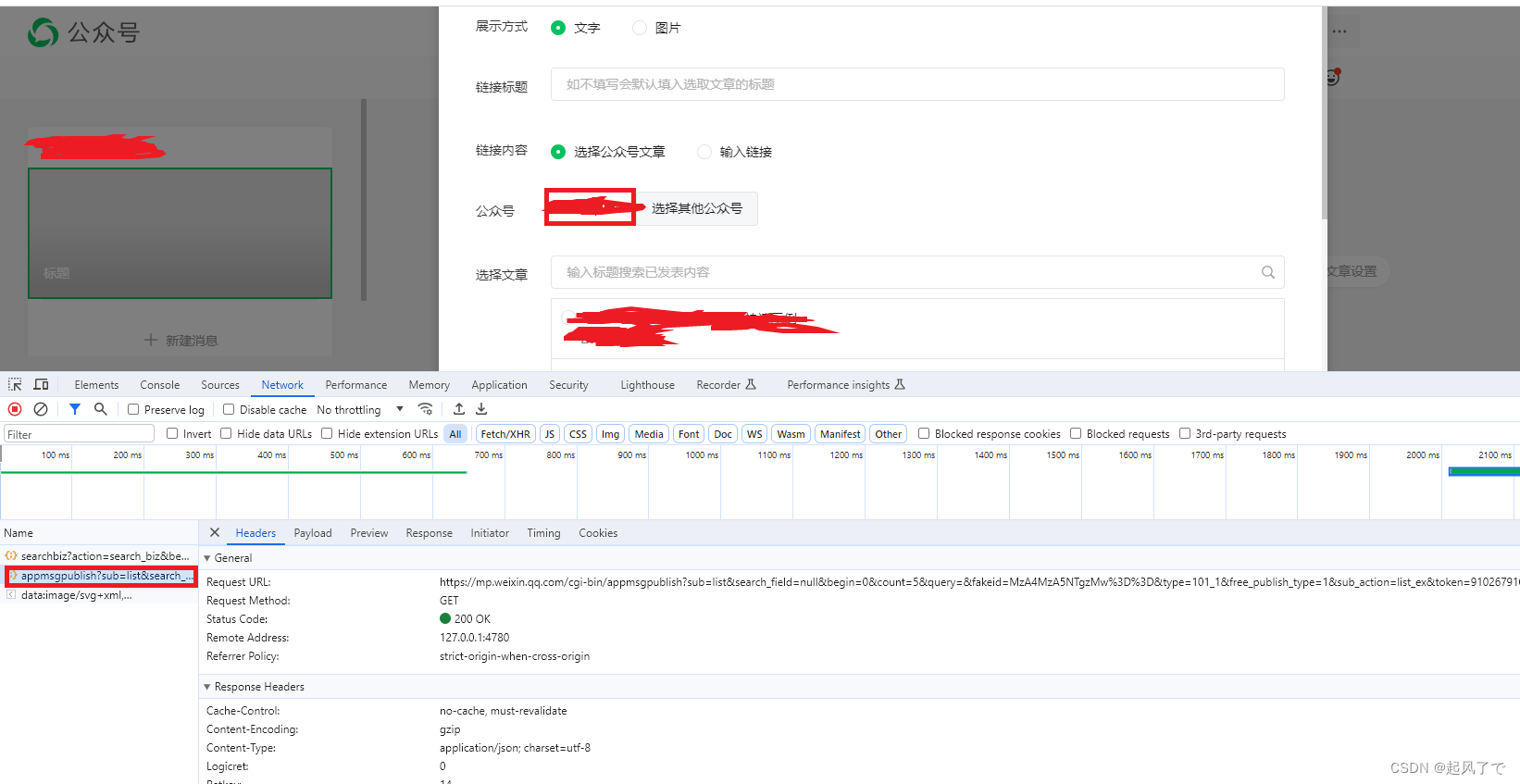
6、在该界面中开发者工具弹出了一个名为:appmsgpublish的数据包。下面分析一下该数据包。
双击后浏览器会跳转到一个新的界面,观察浏览器链接窗口该链接的规律。

7、整理该链接,发现其中的参数如下:
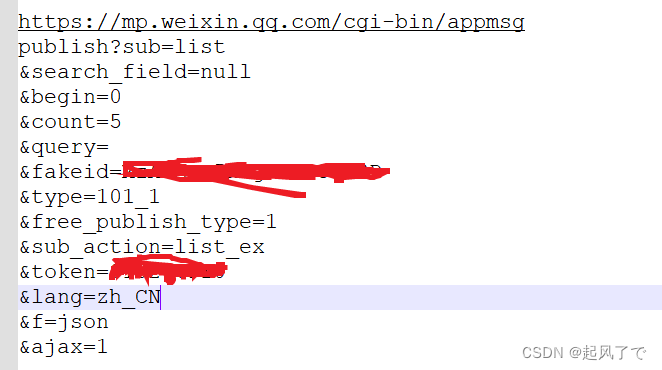
8、此参数可在开发者工具中也可看到
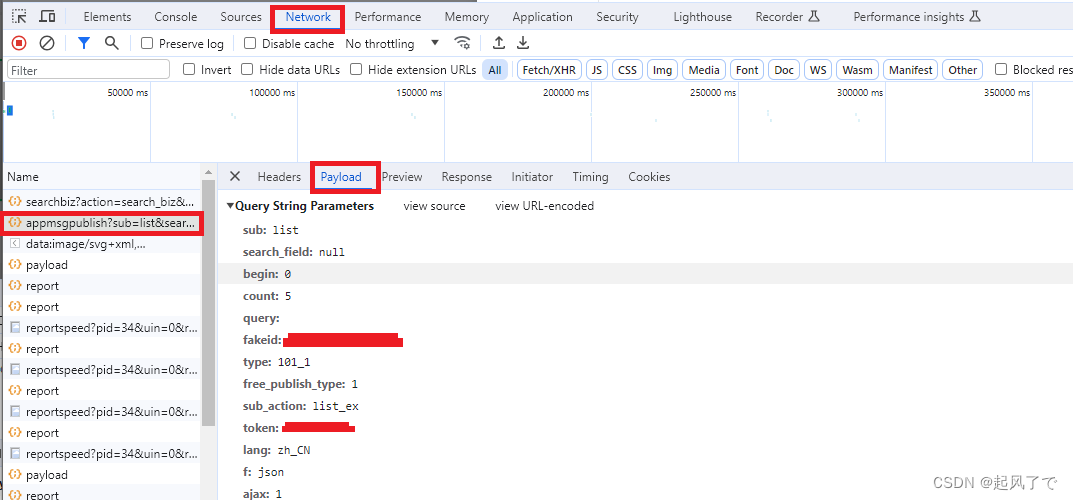
9、根据该参数构建请求链接
其中:
token参数为你自己公众号的标识
fakeid为你所搜索公众号的标识
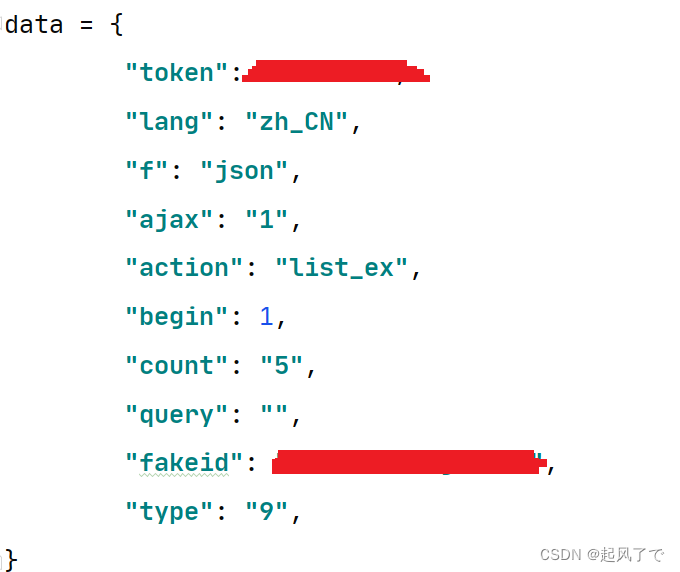
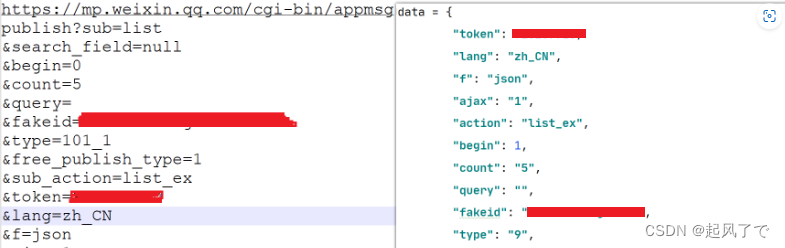
10、开始构建请求链接
# 基础url
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 使用Cookie,跳过登陆操作
headers = {
"Cookie": "你自己的cookie",
"User-Agent": "你自己的User-Agent"
}
# 请求参数
data = {
"token": “你自己的token”,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 1,
"count": "5",
"query": "",
"fakeid": "你需要爬取的公众号的fakeid",
"type": "9",
}
response = requests.get(url, headers=headers, params=data)
3. 爬取正文链接
1、对上一步构建的链接发起第一次请求并将返回的内容转换为json格式
# -*- coding: utf-8 -*-
# Author:
"""
博客
"""
import requests
# 目标url
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 使用Cookie,跳过登陆操作
headers = {
"Cookie": "你自己的cookie",
"User-Agent": "你自己的user-agent"
}
data = {
"token": 你自己的token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 1,
"count": "5",
"query": "",
"fakeid": "MzA4MzA5NTgzMw==",
"type": "9",
}
response = requests.get(url, headers=headers, params=data)
content_json = response.json()
print(content_json)
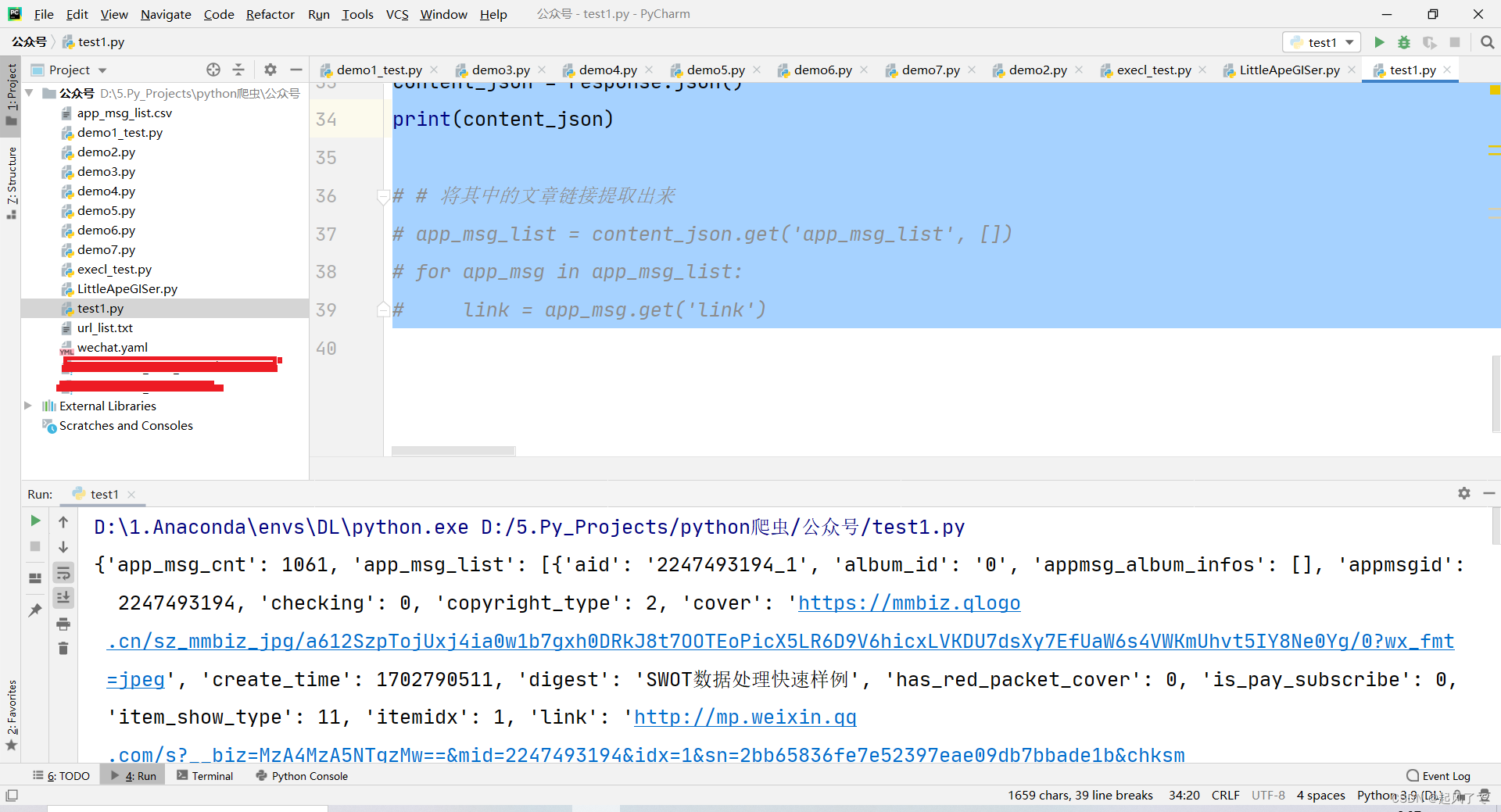
2、通过观察可以看到正文链接都存在【app_msg_list】中
3、将其中的【app_msg_list】依此取出来
app_msg_list = content_json.get('app_msg_list', [])
for app_msg in app_msg_list:
link = app_msg.get('link')
print('-------------------------------')
print(link)

4. 爬取正文
此时我们已经取得正文的链接,使用selenium进行爬取
# 使用selenium进行爬取
def scrape_article_info(link):
try:
browser.get(link)
# 停留
time.sleep(random.randint(30, 80))
# 使用selenium模拟下滑到底部
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(random.randint(20, 70))
# 提取文章内容
content = browser.find_element(By.CSS_SELECTOR, "#img-content").text
# 获取文章标题
title_element = browser.find_element(By.CSS_SELECTOR, "#activity-name")
title = title_element.text.strip()
article_data = [title, content, link]
return article_data
except Exception as e:
print(f"An error occurred: {e}")
return None, None
四、完整代码
# -*- coding: utf-8 -*-
# Author:
"""
单个测试
"""
import requests
import time
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
import openpyxl
# 创建一个execl文件并添加标题
def create_execl_file(file_name):
# 创建一个新的 Excel 工作簿
workbook = openpyxl.Workbook()
# 获取默认的工作表
sheet = workbook.active
# 添加标题
titles = ["Title", "Content", "URL"]
sheet.append(titles)
# 保存 Excel 文件
workbook.save(file_name)
def append_to_excel(file_name, data):
# 打开现有的 Excel 文件
workbook = openpyxl.load_workbook(file_name)
# 获取默认的工作表
sheet = workbook.active
# 添加新数据(假设 data 是一个包含三个值的列表)
sheet.append(data)
# 保存 Excel 文件
workbook.save(file_name)
# 目标url
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 使用Cookie,跳过登陆操作
headers = {
"Cookie": "你自己的Cookie",
"User-Agent": "你自己的User-Agent"
}
# Data to be submitted
data = {
"token": 你自己的token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 1,
"count": "5",
"query": "",
"fakeid": "你需要爬取的公众号的fakeid",
"type": "9",
}
# 抓取文章url
def scrape_articles_link(url):
link_list = []
try:
# 使用get方法进行提交
response = requests.get(url, headers=headers, params=data)
if response.status_code == 200:
content_json = response.json()
# 将其中的文章链接提取出来
app_msg_list = content_json.get('app_msg_list', [])
for app_msg in app_msg_list:
link = app_msg.get('link')
if link:
link_list.append(link)
else:
print(f"Request failed with status code {response.status_code}")
print(response.text) # 打印响应内容以查看错误信息
except requests.exceptions.RequestException as e:
print(f"An error occurred while making the request: {e}")
except ValueError as ve:
print(f"An error occurred while parsing JSON: {ve}")
return link_list
# 创建谷歌浏览器对象,并设置反爬
def create_chrome_driver(*, headless=False):
options = webdriver.ChromeOptions()
if headless:
options.add_argument('--headless')
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=options)
browser.execute_cdp_cmd(
'Page.addScriptToEvaluateOnNewDocument',
{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'}
)
return browser
# 使用selenium进行爬取
def scrape_article_info(link):
try:
browser.get(link)
# 停留
time.sleep(random.randint(30, 80))
# 使用selenium模拟下滑到底部
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(random.randint(20, 70))
# 提取文章内容
content = browser.find_element(By.CSS_SELECTOR, "#img-content").text
# 获取文章标题
title_element = browser.find_element(By.CSS_SELECTOR, "#activity-name")
title = title_element.text.strip()
article_data = [title, content, link]
return article_data
except Exception as e:
print(f"An error occurred: {e}")
return None, None
if __name__ == "__main__":
excel_file = "xxxx.xlsx"
# 创建 Excel 文件并添加标题
create_execl_file(excel_file)
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 初始化浏览器对象
browser = create_chrome_driver()
# 爬取文章链接
link_list = scrape_articles_link(url)
# 迭代处理每个链接
for link in link_list:
link = link.strip()
new_data = scrape_article_info(link)
# 将新抓取到的内容追加到文件中
append_to_excel(excel_file, new_data )
time.sleep(random.randint(30, 60))
# # 关闭浏览器
browser.quit()
五、补充
本次代码只设置了爬取单页内容,如果想要爬取多页,可以观察每次请求中的begin参数,用begin参数进行构建。
文章来源:https://blog.csdn.net/weixin_44064040/article/details/135020869
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!