【linux】Ubuntu 22.04.3 LTS截屏
一、快捷键
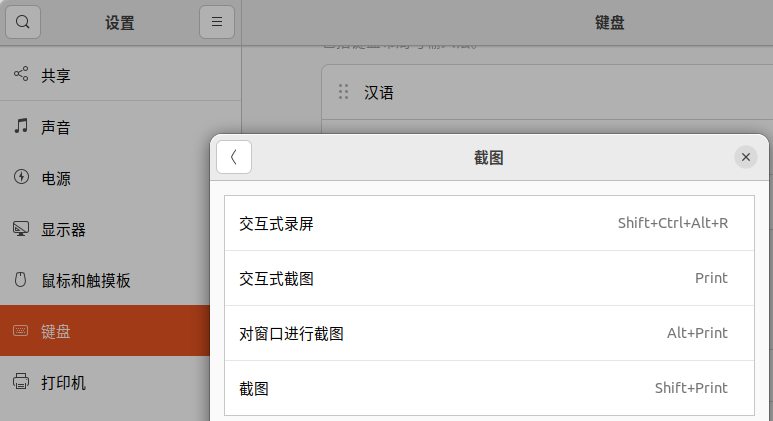
交互式录屏? Shift+CtrltAlt+R
交互式截图? Print
对窗口进行截图? Alt+Print
截图? Shift+Print
快捷键可能取决于使用的桌面环境和个人的键盘快捷键设置。如果上述快捷键不起作用,可能需要检查系统设置中的键盘快捷键部分,以了解系统中截图的快捷键是什么,或者进行自定义设置。在GNOME桌面,可以通过 "设置" -> "键盘" 中找到和设置快捷键。
二、使用第三方截图工具进行截屏
Shutter
1.安装Shutter:在终端中输入以下命令安装Shutter:
sudo apt-get install shutter2.打开Shutter:在应用程序菜单中找到并打开Shutter。
3.选择截图区域:在Shutter界面中,您可以选择全屏、窗口或自定义区域进行截图。
4.编辑截图:在截图完成后,您可以使用Shutter提供的编辑工具对截图进行编辑,如添加文字、绘制形状、应用滤镜等。
5.保存截图:编辑完成后,点击“保存”按钮将截图保存到计算机上。
6.在GNOME桌面,可以通过 "设置" -> "键盘" 中找到和设置自定义快捷键。
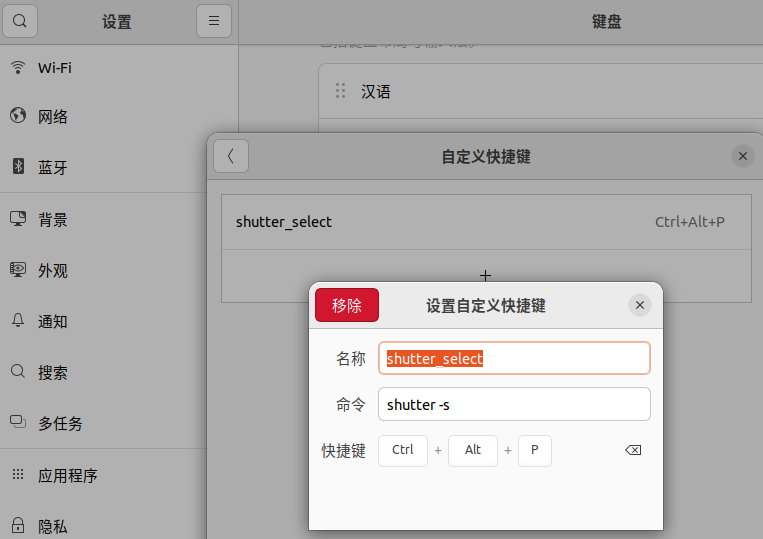
自定义快捷键可以设置以下命令:
shutter -s 或者shutter –select:自由选取。
shutter -a (a表示active):截取当前活动窗口。
三、从截图中提取文字
要在Debian中截图并从截图中提取文字,可以使用以下步骤:
1. 安装截图工具:在Debian中,可以使用默认的截图工具或第三方截图工具,如GNOME Screenshot、Shutter等。
2. 截图:使用截图工具,选择要截取的区域或全屏进行截图。
3. 打开截图:将截图保存到计算机上,然后使用图像查看器或编辑器打开它。
4. 提取文字:在Debian中,可以使用OCR(光学字符识别)工具从图像中提取文字。一些流行的OCR工具包括Tesseract和Google Cloud Vision API等。以下是在Debian中使用Tesseract进行文字提取的步骤:
a. 安装Tesseract OCR:在终端中使用以下命令安装Tesseract:
sudo apt-get install tesseract-ocr可能还需要安装特定的语言数据包,例如安装简体中文的数据包命令如下:
sudo apt-get install tesseract-ocr-chi-simb. 将图像转换为灰度图像:在终端中使用以下命令将图像转换为灰度图像,以方便Tesseract进行文字识别:
convert input.png -colorspace gray output.pngc. 使用Tesseract进行文字提取:在终端中使用以下命令进行文字提取:
tesseract output.png output -l chi_sim这将使用Tesseract从图像中提取文字,并将结果保存到名为“output.txt”的文件中。您可以根据需要调整语言参数(如“chi_sim”表示简体中文)。
5. 打开提取的文字:使用文本编辑器或记事本等应用程序打开提取的文字文件。您将看到从截图中识别的文字内容。
6. 除了命令行工具之外,还有一些图形界面的应用程序也提供了OCR功能,例如GImageReader,这是一个基于Tesseract的GUI前端。要安装它,可以使用APT:
sudo apt install gimagereader安装后,可以通过应用程序菜单启动GImageReader,然后按照应用内提供的说明使用OCR提取功能。
OCR技术并不完美,它的准确性可以受到图像质量、字体大小、布局复杂性以及OCR引擎本身的限制影响。因此,提取的文本可能需要手动校正。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!