3DV 2024 Oral | SlimmeRF:可动态压缩辐射场,实现模型大小和建模精度的灵活权衡
目前大多数NeRF模型要么通过使用大型模型来实现高精度,要么通过牺牲精度来节省内存资源。这使得任何单一模型的适用范围受到局限,因为高精度模型可能无法适应低内存设备,而内存高效模型可能无法满足高质量要求。为此,本文研究者提出了SlimmeRF,一种在测试阶段随时(即不需要对模型进行重新训练)通过动态压缩实现模型大小与精度之间权衡的模型,从而使模型同时适用于不同计算预算的场景。实验结果显示,SlimmeRF在不进行动态压缩时能够达到 SOTA 级别的精度,同时动态压缩时的效果明显好于基于 TensoRF 的基准模型。

论文题目: SlimmeRF: Slimmable Radiance Fields
论文链接:https://arxiv.org/abs/2312.10034?
代码链接:?GitHub - Shiran-Yuan/SlimmeRF: Official implementation for SlimmeRF: Slimmable Radiance Fields
01. 简介
辐射场(Radiance Fields)是一种通过神经网络等方法对3D场景进行建模的方法。我们观察到,在实际应用中,往往存在一个问题:效果较好的辐射场模型会对内存等资源要求较高,因此难以应用于资源较为稀缺的应用场景;相反,比较节省内存资源、算力资源等的模型则可能效果不佳。
因此,当需要训练能够兼容高负载能力与低负载能力环境的模型时,就只能采用后者,因为前者无法在低负载能力环境中运行。然而实际情况是,往往高负载能力的环境也有较高对模型效果的需求,而低负载能力的环境则对模型效果需求不高,因此前述的方法不符合高负载能力环境下的需求。因此,如果能够训练出能够在高负载能力环境下取得极佳效果,同时在低负载能力环境下也能牺牲效果成功运行的模型,就可以同时满足这两种需求。
为了解决该问题,本文提出,应当让辐射场模型能够拥有可动态压缩性(Slimmability)。我们提出的 SlimmeRF 模型基于低秩张量近似(Low-Rank Tensor Approximation)对场景进行建模,在不被动态压缩(Slim)的情况下建模精度能够达到 SOTA 等级,同时还能在测试阶段随时(即不需要对模型进行重新训练)通过动态压缩减小模型大小,牺牲精度来满足更严格的环境负载能力要求。
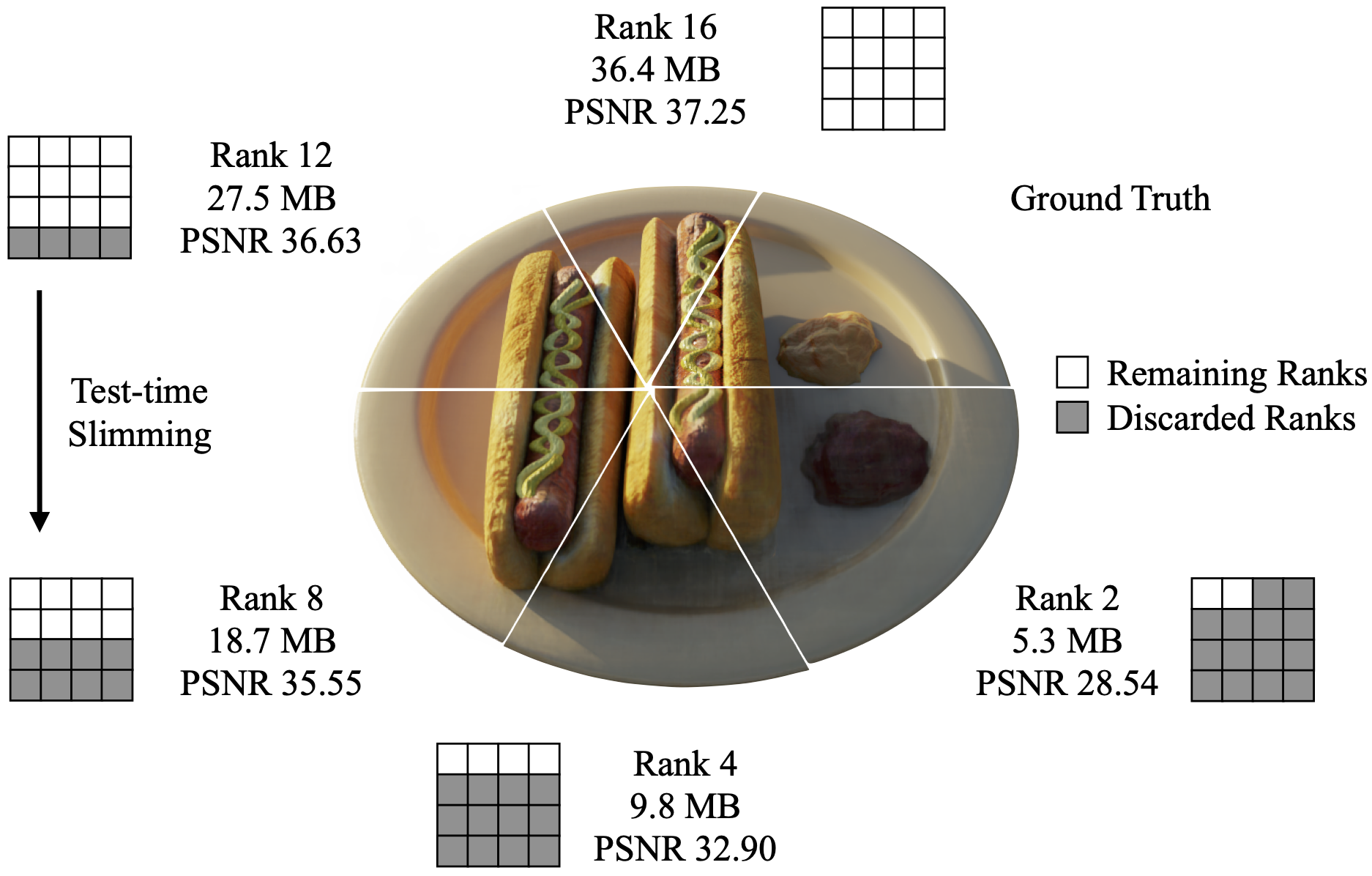
技术方面,我们受张量辐射场(TensoRF)启发,利用矩阵-向量张量分解(VM 分解,Vector-Matrix Tensor Decomposition)建模3D场景的密度(Density)与外观(Appearance)。同时,为了使模型中的张量具备可进行低秩张量近似的性质,我们提出了张量增秩算法(TRaIn, Tensorial Rank Incrementation),用于进行训练。实现中,我们在训练时通过对张量进行遮罩(Masking)来模拟张量秩的变化,而测试时直接对分解后的成分(Factors)进行截断(Truncation)。
实验结果显示,SlimmeRF 中张量分解成的不同成分间出现了“分工”,由对应秩较低的成分对于大致轮廓、颜色等进行建模,而对应秩较高的成分则对于细节进行建模。我们的模型在不进行动态压缩时能够达到?SOTA 级别的精度(这一点许多其他可压缩与低内存消耗模型都无法做到),同时动态压缩时的效果明显好于基于 TensoRF 的基准模型(Baseline)。我们还在稀疏输入(Sparse Input)的场景下进行了实验,发现 SlimmeRF 的可动态压缩性提升了很多,并且在特定视角下效果好于专门用于稀疏输入的模型。
02. 方法

2.1 问题表述

2.2 张量增秩算法
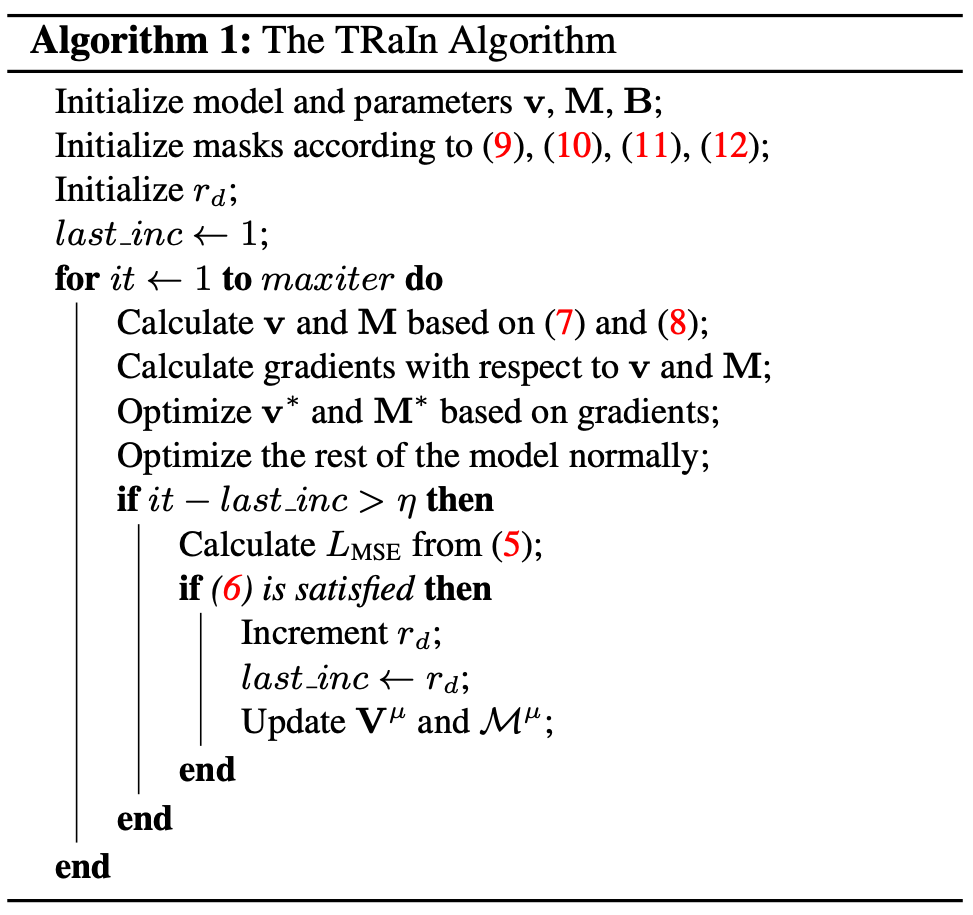



2.3 遮罩训练与截断测试


03. 实验
3.1 与 TensoRF 基准对比
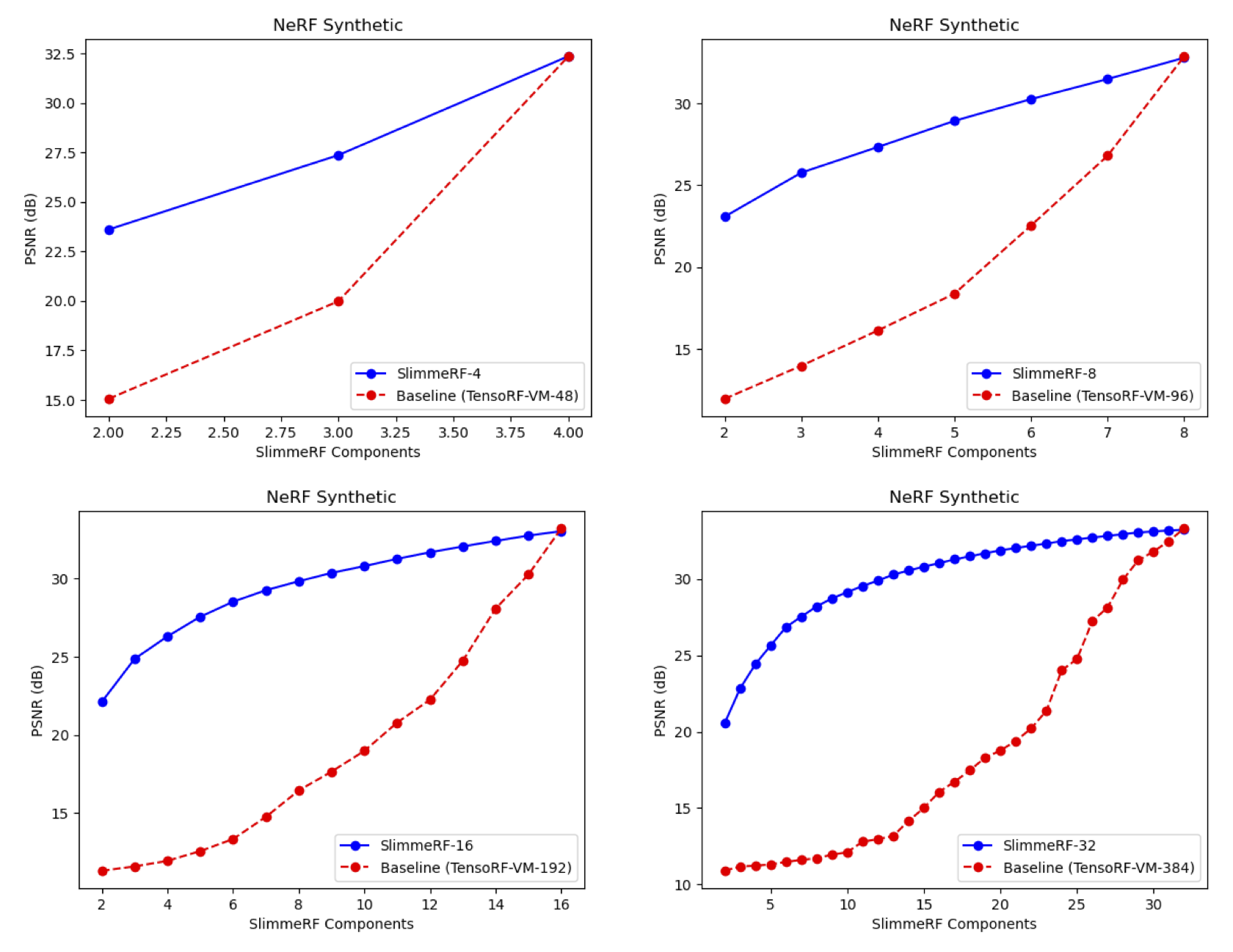
我们直接对于使用类似表示结构的 TensoRF 进行截断来作为基准,将其结果与参数量相同的 SlimmeRF 进行对比,定量、定性结果分别如下图所示。可以看到,我们的模型效果明显远好于基准,说明了 TRaIn 算法的作用。

3.2 与 SOTA 模型对比
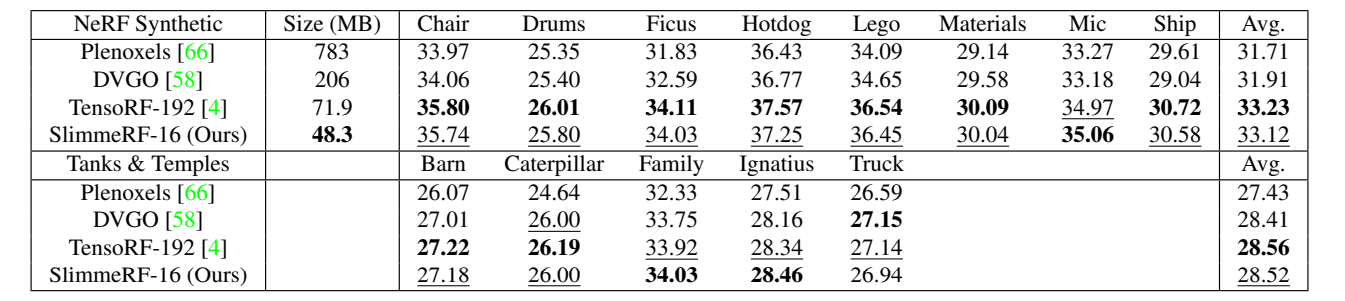
我们与 SOTA 模型 Plenoxels、DVGO、TensoRF 进行了对比,定量结果如下表所示。与 TensoRF 的定性对比如下图所示。结果说明,我们的模型在不进行动态压缩时能够达到 SOTA 级的效果,不会以牺牲效果为代价,只有在进行动态压缩后才会牺牲效果。

3.3 与可压缩模型/低内存消耗模型对比
我们将 SlimmeRF 与 TensoRF、CCNeRF、MWR (Masked Wavelet Representation)、TinyNeRF、PlenVDB 等以可压缩或低内存消耗为主要优势的模型进行了对比,结果如下图所示。其中,除了 CCNeRF 以外均没有可动态压缩性,仅仅作为参考。

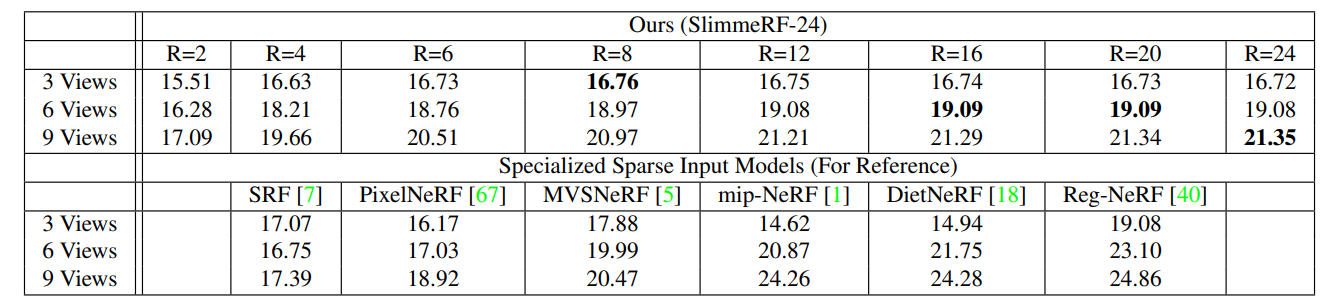
3.4 稀疏输入实验
我们将 SlimmeRF 与用于稀疏输入场景的 SRF、PixelNeRF、MVSNeRF、mip-NeRF、DietNeRF、Reg-NeRF 等模型进行了对比,定量结果如下表所示。与 Reg-NeRF 在一些视角下的定性对比如下图所示。SlimmeRF 并不是稀疏输入模型,没有对场景的几何构造进行重建,因此效果并没有稳定超越其它方法;但定性实验表明,SlimmeRF 在稀疏输入场景下效果很好,在特定视角下甚至可以超越专用于稀疏输入场景的模型;同时,定量结果表明,SlimmeRF 在稀疏输入场景下可动态压缩性极佳,在模型大小缩小时效果不会变差很多,甚至在输入视角较少的时候会出现模型大小越小,模型效果越好的情况。

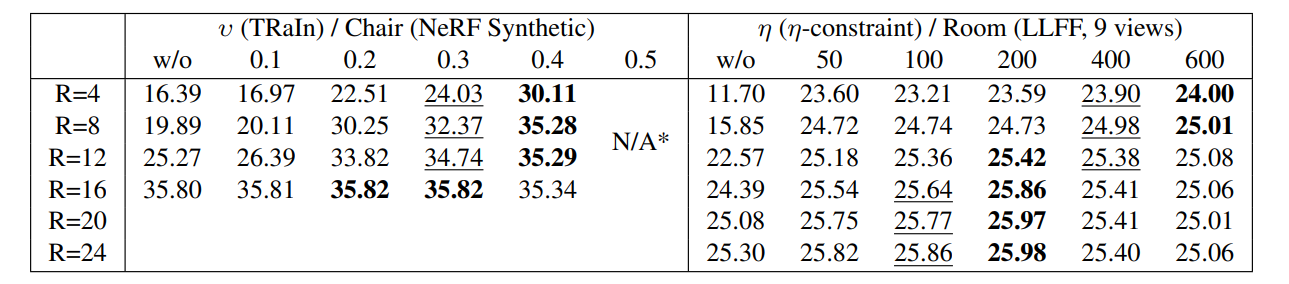
3.5 消融实验与参数敏感性分析

3.6 与BCD基准对比
我们尝试实现了基于前述 BCD 算法的模型,但训练过程中模型损失与精度浮动极大,因此我们没有获得可展示的结果。这体现出了我们采用原创算法进行训练的必要性。
04. 结语
我们工作的主要贡献在于提出并实现了神经辐射场的可动态压缩性(Slimmability),同时为神经辐射场研究提供了低秩张量近似与秩增训练的新思路。在未来,我们会进一步将这一工作拓展到4D等其它场景,并将其应用化。
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!