Flink CDC 1.0至3.0回忆录
Flink CDC 1.0至3.0回忆录
一、引言
回想起2020下半年,刚从Storm/JStorm转到Flink完成了一些中间件重构,Flink CDC就横空出世了,这对于实时采集侧简直是福音。当时便立即组织团队的小伙伴们,选择了几个下班前一小时的时间段,开始学习(云邪是多少学习Flink CDC小伙伴的启蒙老师?):

不知不觉Flink CDC 3.0已经Release了两周+,数据流处理技术也在各行各业得到了广泛应用。其中,Flink CDC 作为Apache Flink的关键组件,提供了一种高效可靠的方式,用于实时地获取DB中的数据变化并将其流式处理。
本文将一起回顾Flink CDC从1.0到3.0的发展历程,了解其背后的关键特性和发展趋势,共同探讨其在大数据领域的影响和价值。
二、CDC概述
在扬帆之前,先来简单概述一下CDC(Change Data Capture)。
CDC 是一种用以掌控数据变化的软件架构(通俗而言:技术思路),用于捕获和传递数据库中发生的数据变化。当数据库中发生增(INSERT)/ 删(DELETE)/ 改(UPDATE)时,
它可以将这种变化实时 / 非实时地将这些变更以事件流的形式推送给其它应用程序或数据存储系统。
例如通过数据库触发器 Trigger-based或数据库事务日志 Log-based 的方式实现CDC:
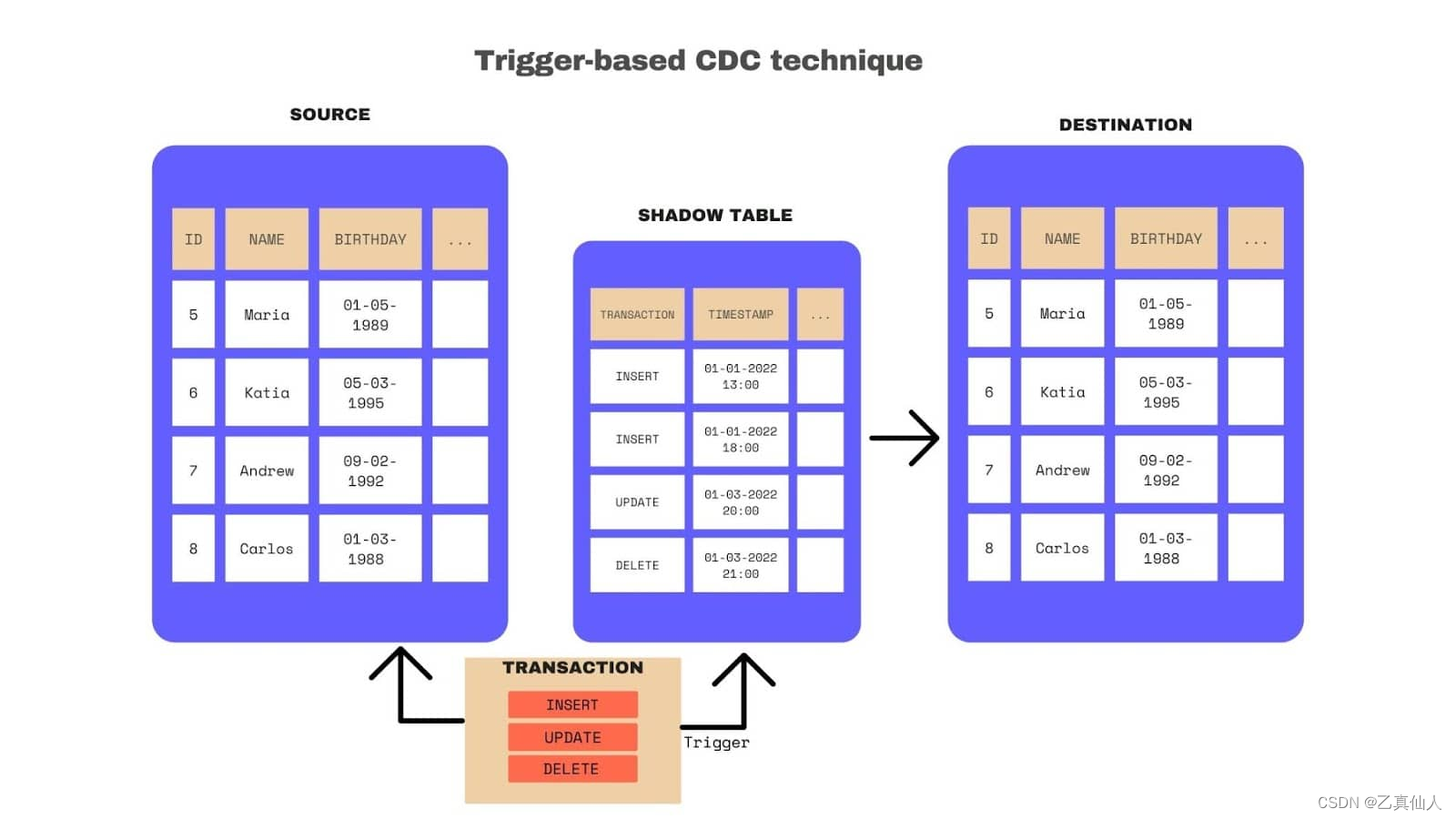
1)Trigger-based:在数据库进行 INSERT / UPDATE / DELETE 操作的时候,会触发执行另一段 SQL,就可以在另一张影子表中记录数据的变化。接下来做数据同步就很简单,只需要关注影子表里的记录,然后对应再执行一次即可:
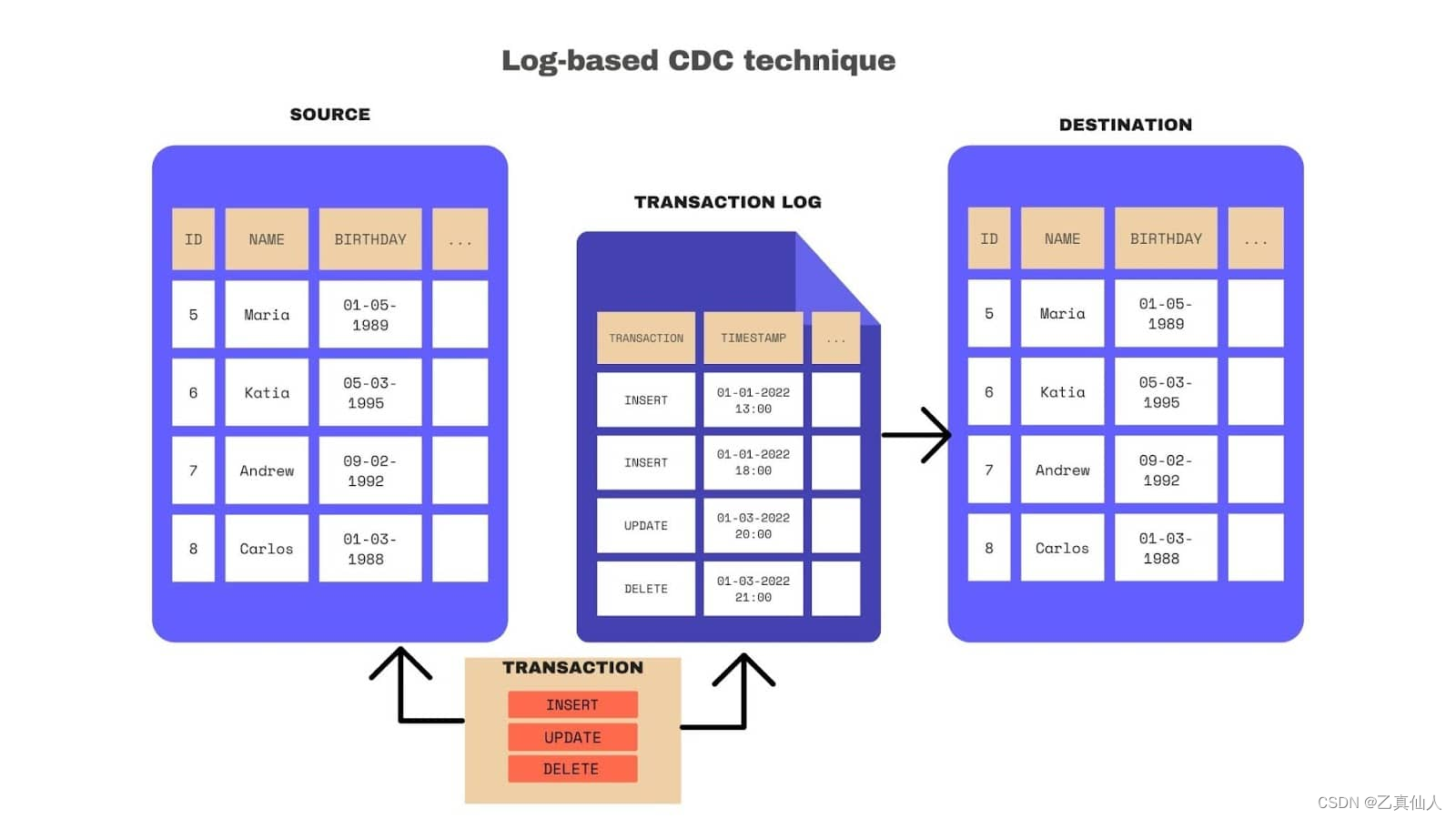
2)Log-based:和 Trigger-based 非常相似,所有数据的变动要么放在日志里,要么放在影子表里,内容上是一致的。但 Log-based 方法更好利用了数据库本身的核心能力,即大部分关系型数据,在数据发生变化的时候都会产生日志,如果直接用这样的日志来进行数据同步,不但可以在不同的系统间保证 ACID 可靠,对数据库的影响几乎可以忽略不计(不需要修改表结构,也不需要新增影子表),并且日志是实时产生的,可以有更好的时效性:
除了上述示例,还有其它比如表元信息 Table metadata 或 表求差 Table differences 的实现方式,皆聚焦于如何实现 Capture 这一动作。
总而言之,CDC 技术极大地提升了数据集成的效率和实时性,使得不同系统间的异构数据同步和共享变得更加可靠和高效,在现代数据架构中扮演着重要的角色。
下面,扬帆起航,一起看看基于Flink是如何实现CDC的吧。
三、Flink CDC 1.0:扬帆起航
2020 年 7 月由云邪提交了第一个 commit(基于个人兴趣孵化的项目),至此拉开了Flink CDC 的篇章。
3.1 架构设计
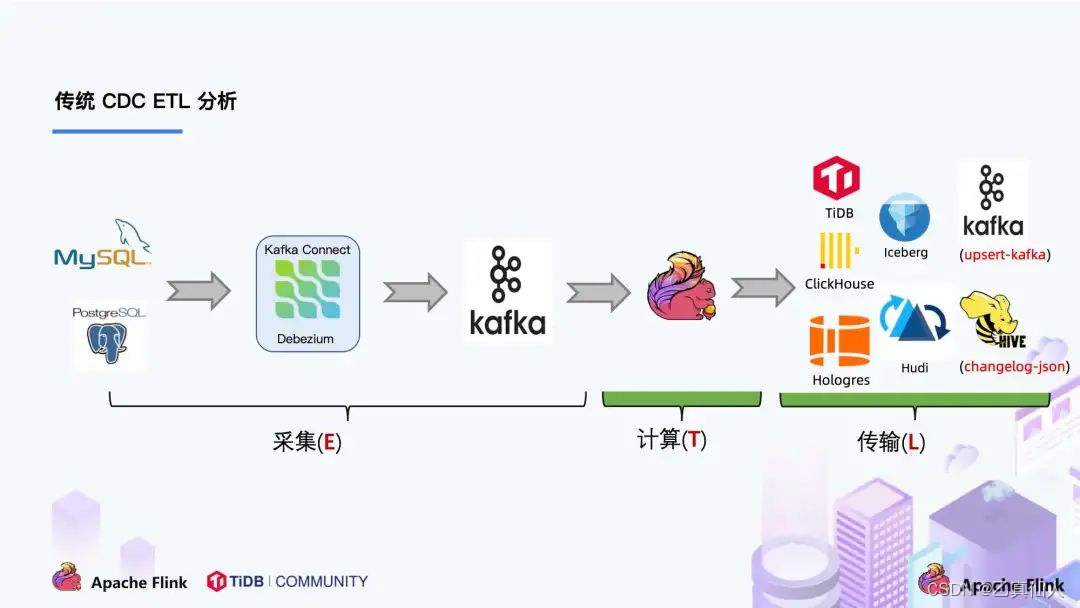
传统的CDC ETL链路中,采集到的数据一般输出到消息中间件如 Kafka,然后 Flink 计算引擎再去消费这一部分数据写入到目的端,目的端可以是各种 DB,数据湖,实时数仓和离线数仓等:
Flink CDC 1.0中,基于Flink的两个特性:Dynamic Table 和 Changelog Stream:

- Dynamic Table:Flink SQL 定义的动态表,动态表和流的概念是对等的;流可以转换成动态表,动态表也可以转换成流。
- Changelog Stream:在 Flink SQL中,数据在从一个算子流向另外一个算子时都是以 Changelog Stream 的形式,任意时刻的 Changelog Stream 可以翻译为一个表,也可以翻译为一个流。
再联想MySQL 中的表和 binlog 日志,就会发现:MySQL 数据库的一张表所有的变更都记录在 binlog 日志中,如果一直对表进行更新,binlog 日志流也一直会追加,数据库中的表就相当于 binlog 日志流在某个时刻点物化的结果;日志流就是将表的变更数据持续捕获的结果。这说明 Flink SQL 的 Dynamic Table 是可以非常自然地表示一张不断变化的 MySQL 数据库表。
在此基础上,调研了一些 CDC 技术,最终选择了 Debezium 作为 Flink CDC 的底层采集工具。Debezium 支持全量同步,也支持增量同步,也支持全量 + 增量的同步,非常灵活,同时基于日志的 CDC 技术使得提供 Exactly-Once 成为可能:
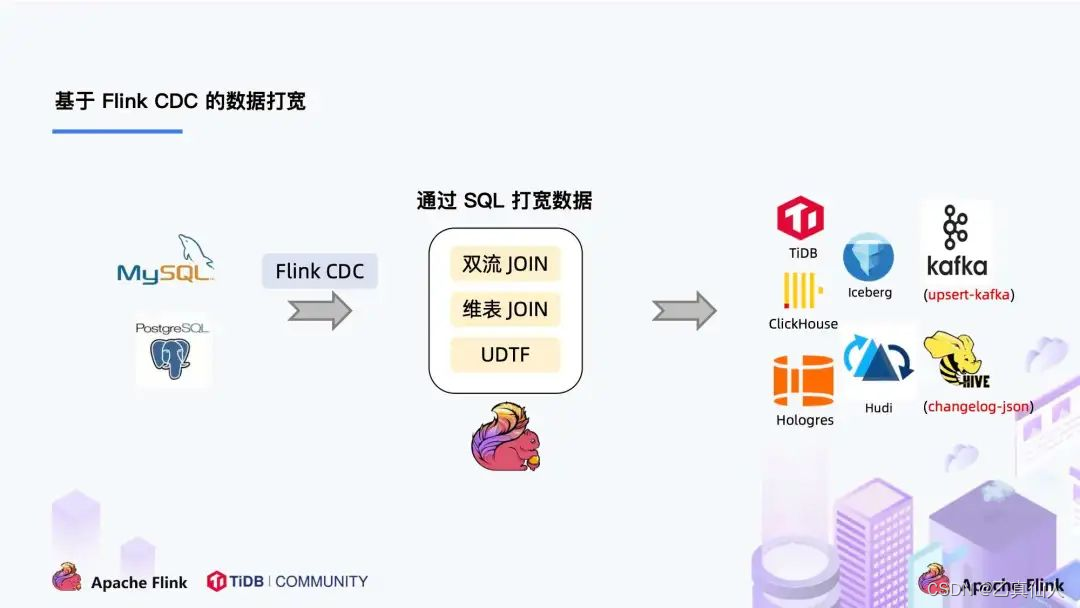
至此,用户只需在Flink SQL 创建对应的CDC 表,然后对数据流进行打宽以及各种业务逻辑加工,加工后直接写入到下游数据库。通过一个 Flink SQL 作业就完成了 CDC 的数据分析,加工和同步。
3.2 版本痛点
随着 Flink CDC 1.X 项目的发展,得到了很多用户在社区的反馈,主要归纳为三个:

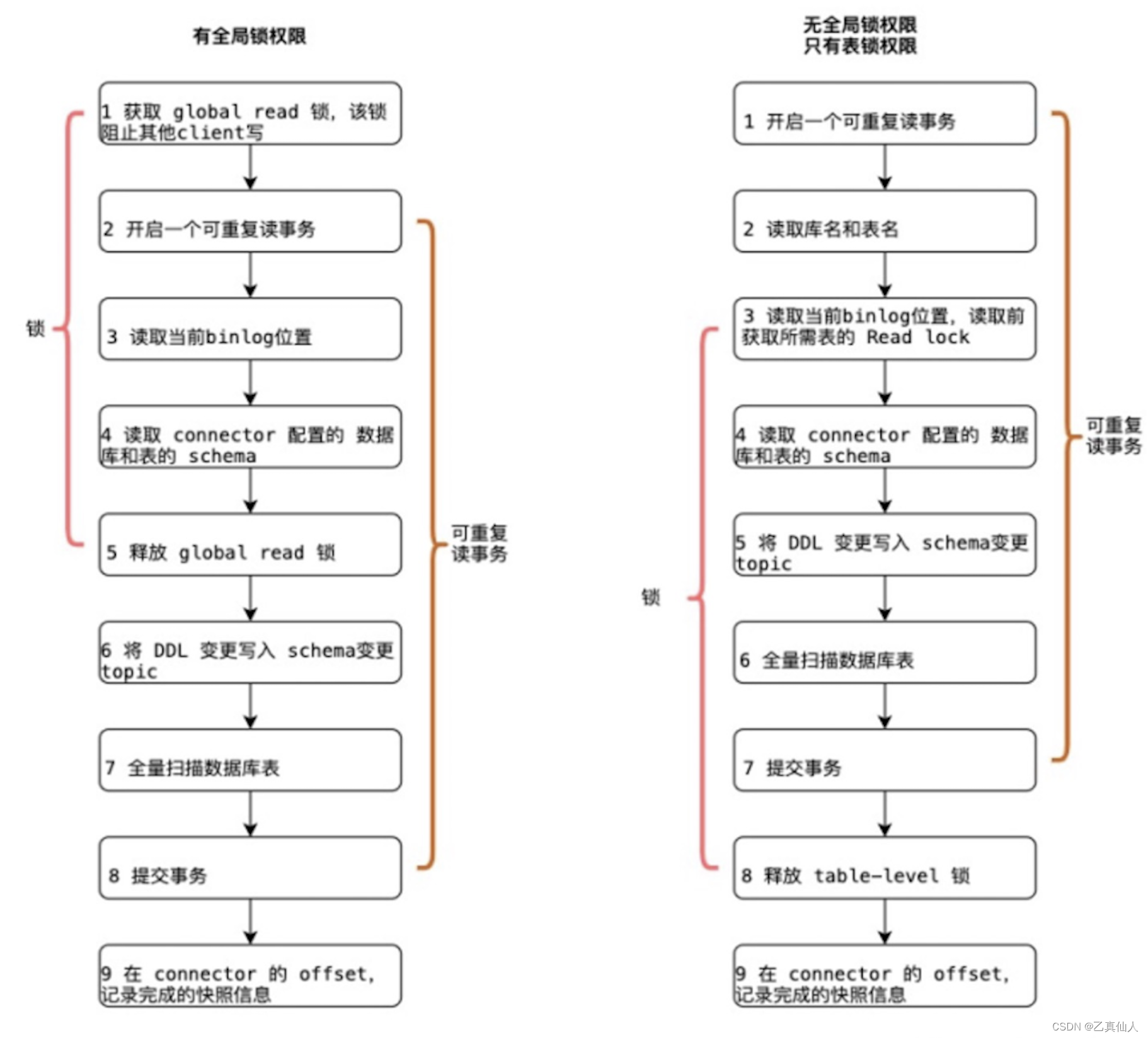
1)全量 + 增量读取的过程需要保证所有数据的一致性,因此需要通过加锁保证,但是加锁在数据库层面上是一个十分高危的操作。底层 Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库锁住,表级锁会锁住表的读,DBA 一般不给锁权限:
2) 不支持水平扩展,因为 Flink CDC 底层是基于 Debezium,起架构是单节点,所以Flink CDC 只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天级别,用户不能通过增加资源去提升作业速度。
3)全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,全量读取和增量读取,目前全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当同步全量数据时,假设需要 5 个小时,当同步了 4 小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
四、Flink CDC 2.0:成长突破
通过上面的分析,可以知道 2.0 的设计方案,核心要解决上述的三个问题,即支持无锁、水平扩展和checkpoint(MySQL为例):

4.1 DBlog 无锁算法
DBlog 这篇论文里描述的无锁算法如下图所示:
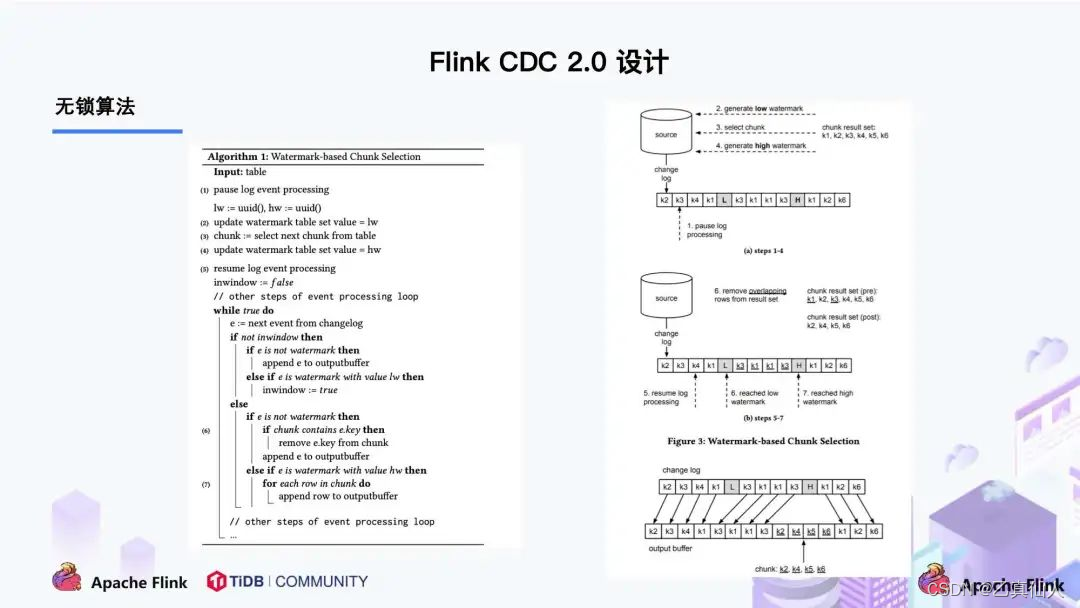
左边是 Chunk 的切分算法描述,Chunk 的切分算法其实和很多数据库的分库分表原理类似,通过表的主键对表中的数据进行分片。假设每个 Chunk 的步长为 10,按照这个规则进行切分,只需要把这些 Chunk 的区间做成左开右闭或者左闭右开的区间,保证衔接后的区间能够等于表的主键区间即可。
右边是每个 Chunk 的无锁读算法描述,该算法的核心思想是在划分了 Chunk 后,对于每个 Chunk 的全量读取和增量读取,在不用锁的条件下完成一致性的合并。Chunk 的切分如下图所示:
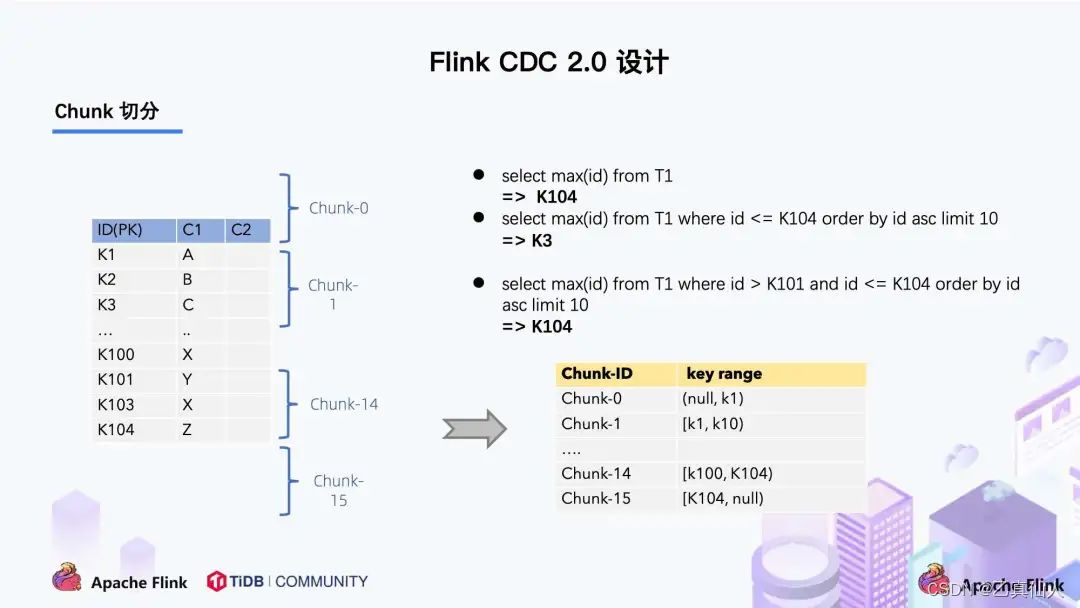
因为每个 chunk 只负责自己主键范围内的数据,不难推导,只要能够保证每个 Chunk 读取的一致性,就能保证整张表读取的一致性,这便是无锁算法的基本原理。
4.2 FLIP-27 架构实现
Flink CDC 2.0 基于 FLIP-27 优雅地实现了多表场景分发Chunk并保证全局一致性。
通过下图可以看到有 SourceEnumerator 的组件,这个组件主要用于 Chunk 的划分,划分好的 Chunk 会提供给下游的 SourceReader 去读取,通过把 chunk 分发给不同的 SourceReader 便实现了并发读取 Snapshot Chunk 的过程,同时基于 FLIP-27 能较为方便地做到 chunk 粒度的 checkpoint。

当 Snapshot Chunk 读取完成之后,需要有一个汇报的流程,如下图中橘色的汇报信息,将 Snapshot Chunk 完成信息汇报给 SourceEnumerator。
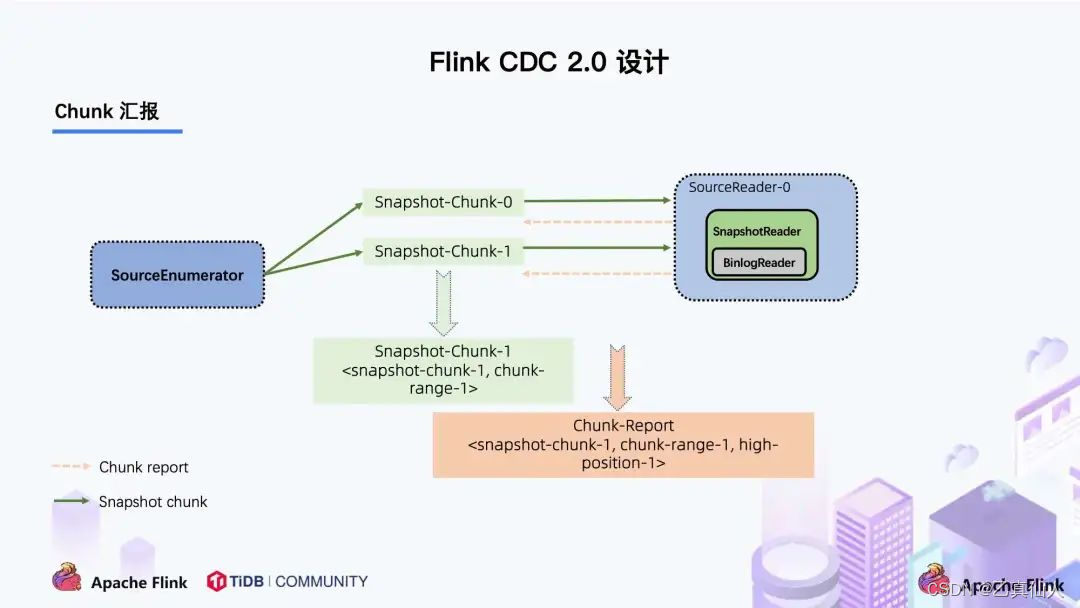
汇报的主要目的是为了后续分发 binlog chunk (如下图)。因为 Flink CDC 支持全量 + 增量同步,所以当所有 Snapshot Chunk 读取完成之后,还需要消费增量的 binlog,这是通过下发一个 binlog chunk 给任意一个 Source Reader 进行单并发读取实现的。
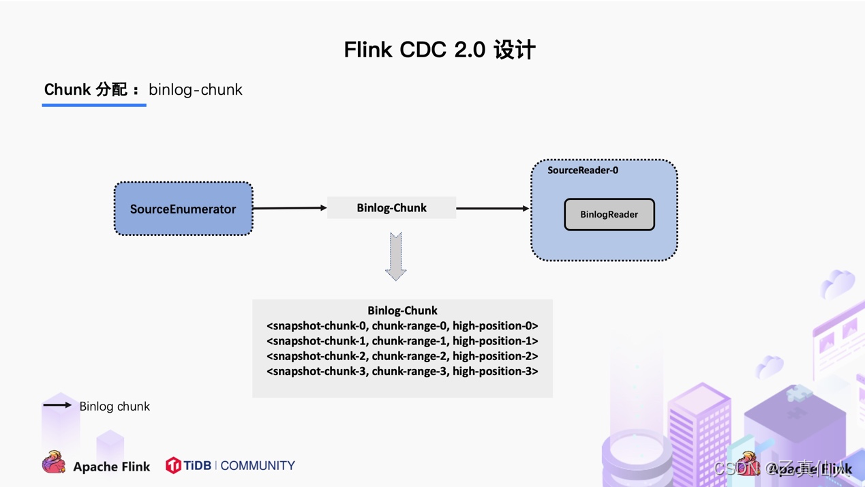
4.3 整体流程
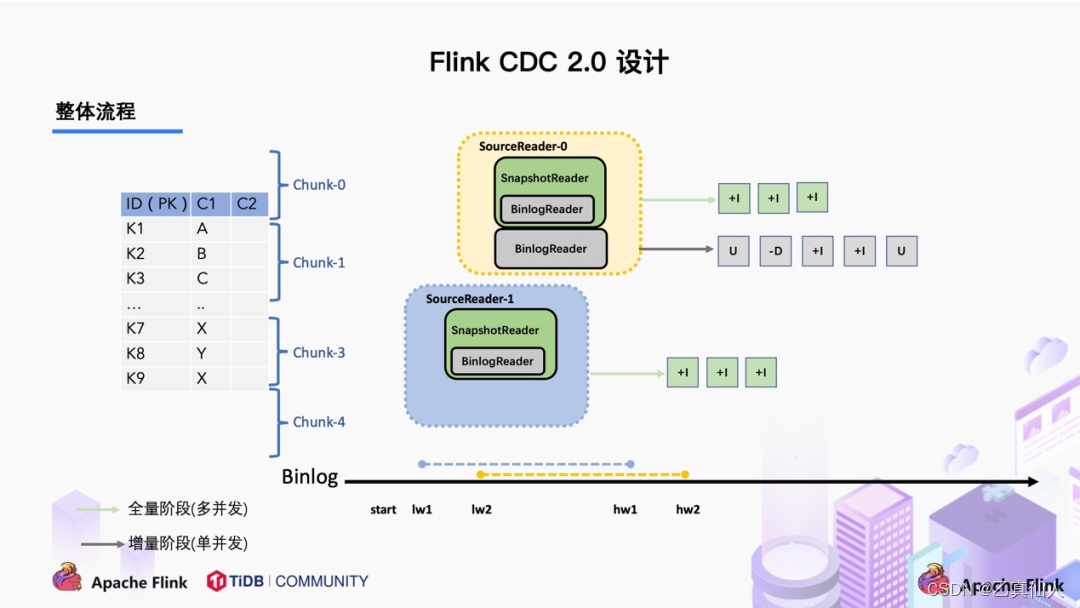
整体流程可以概括为,首先通过主键对表进行 Snapshot Chunk 划分,再将 Snapshot Chunk 分发给多个 SourceReader,每个 Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读,SourceReader 读取时支持 chunk 粒度的 checkpoint,在所有 Snapshot Chunk 读取完成后,下发一个 binlog chunk 进行增量部分的 binlog 读取,这便是 Flink CDC 2.0 的整体流程,如下图所示:
五、Flink CDC 3.0:应运而生
Flink CDC 2.X 支持了全增量一体化、无锁读取、并行读取、表结构变更自动同步、分布式架构等高级特性。配合 Flink 优秀的管道能力和丰富的上下游生态,Flink CDC 可以高效实现海量数据的实时集成。
虽然 Flink CDC 有很多技术优势,社区用户增长很快,但随着 Flink CDC 项目用户基数的日益增长,以及应用场景的不断扩大,社区收到了很多用户反馈:
- 用户体验:只提供 Flink source,不支持端到端数据集成, SQL 和 DS API 构建作业流程复杂
- 维护频繁:上游数据库表结构变更非常常见 ,增加、删除表的业务需求普遍存在
- 扩展性:全量和增量阶段资源难以灵活扩缩容 ,千表同步、万表入湖入仓资源消耗大
- 中立性:项目使用 Apache License V2 协议,不属于 Apache Flink ,版权归属于 Alibaba (Ververica)
针对这些反馈,Flink CDC 社区里面与 Maintainer 一起展开了多轮讨论和设计。最终,面向数据集成用户、面向端到端实时数据集成的框架 Flink CDC 3.0 应运而生。在产品设计上社区追求简洁,秉持以下原则和目标进行设计实现:
- 端到端体验:Flink CDC 3.0 定位为端到端的数据集成框架,API 设计直接面向数据集成场景,帮助用户轻松构建同步作业
- 自动化:上游 schema 变更自动同步到下游,已有作业支持动态加表
- 极致扩展:空闲资源自动回收,一个 sink 实例支持写入多表
- 推动捐赠:推动 Flink CDC 成为 Apache Flink 的子项目,版权属于中立的 Apache 基金会,吸引更多的公司和开发者参与。
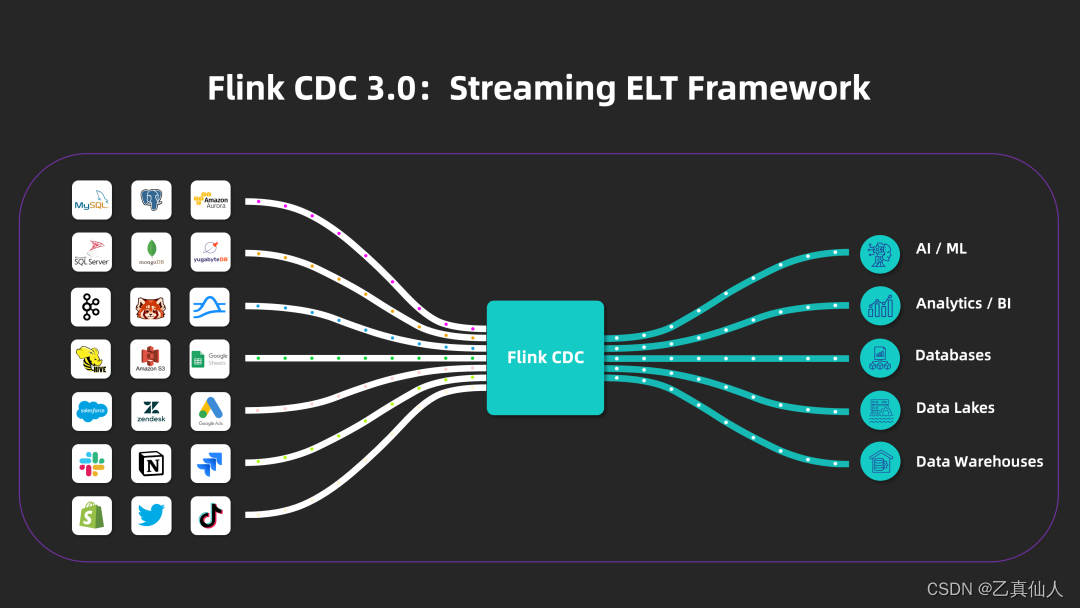
总体来说,Flink CDC 3.0 不仅提供基础的数据同步能力,schema 变更自动同步、整库同步、分库分表等增强功能使 Flink CDC 3.0 在更复杂的数据集成与用户业务场景中发挥作用:用户无需在数据源发生 schema 变更时手动介入,大大降低用户的运维成本;只需对同步任务进行简单配置即可将多表、多库同步至下游,并进行合并等逻辑,显著降低用户的开发难度与入门门槛。
六、Flink CDC 的影响和价值
Flink CDC的价值和影响主要体现在以下几个方面:
1. 实时数据同步:Flink CDC能够实时捕获和处理关系型数据库中的数据变化,使得多个系统之间的数据能够实时同步,保持数据的一致性。
2. 数据湖建设:通过使用Flink CDC,可以将关系型数据库中的数据变化流式导入到数据湖中,为数据分析和机器学习等应用提供实时的、可靠的数据源。
3. 实时监控和报警:Flink CDC可以对关系型数据库进行实时监控,并在数据变化满足特定条件时触发报警,帮助企业及时发现和解决数据异常或问题。
4. 实时ETL和数据处理:Flink CDC可以将关系型数据库中的数据变化与其他数据源进行实时集成和处理,支持实时ETL(Extract-Transform-Load)和数据流处理,提供更加灵活和高效的数据处理能力。
…
总的来说,Flink CDC以其强大的功能和广泛的应用场景,为企业数据处理和分析带来了极大的便利和价值。
七、结语

Flink CDC 1.0 于2020年8月4日发布1.0 Release,让用户只需通过一个 Flink SQL 作业就完成了 CDC 的数据分析,加工和同步。
Flink CDC 2.0 于2021年8月11日发布2.0 Release,支持了无锁、水平扩展和checkpoint,让用户可放心地高效实现海量数据的实时集成。
Flink CDC 3.0于2023年12月7日重磅推出,让用户只需对同步任务进行简单配置即可完成多表、多库同步至下游,且无需在数据源发生 schema 变更时手动介入,极其贴心易用。
未来,Flink CDC 项目的版权将会属于中立的 Apache 基金会, Flink CDC 也能与 Apache Flink 进行更深度的集成,为用户提供更好的实时数据集成体验的同时扩展 Apache Flink 的社区生态。
最后,愿中国开源社区越来越好,早日从 “开源大国” 发展为 “开源强国”。
参考
[1] Flink CDC 2.0:
https://mp.weixin.qq.com/s/iwY5975XXp7QOBeV0q4TfQ
[2] Flink CDC 3.0:
https://mp.weixin.qq.com/s/rkjIK2UH_IeC5QIwHw_4fw
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!