Linux安装Hadoop
2023-12-21 18:14:05
(1)下载Hadoop安装包并上传
下载Hadoop安装包到本地,并导入到Linux服务器的/opt/software路径下
(2)解压安装包
解压安装文件并放到/opt/module下面
[root@hadoop100 ?~]$ cd /opt/software
[root@hadoop100 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
(3)将Hadoop添加到环境变量
?[root@hadoop100 ?~]$ vim /etc/profile.d/hadoop_env.sh在hadoop_env.sh文件末尾添加如下内容:
?#HADOOP_HOME
?export HADOOP_HOME=/opt/module/hadoop-3.1.3
?export PATH=$PATH:$HADOOP_HOME/bin
?export PATH=$PATH:$HADOOP_HOME/sbin
保存并退出: ?:wq
(4)让修改文件生效
? [root@hadoop100 ~]$ source /etc/profile如果命令还不能让hadoop生效,则重启虚拟机
[root@hadoop100 ~]$ sudo reboot(5)测试是否安装成功
? [root@hadoop100 ~]$ ?hadoop version
(6)查看Hadoop目录结构
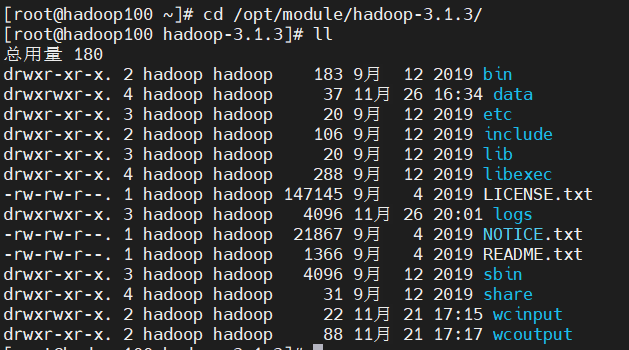
以下是Hadoop文件中重要的目录:
- bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
- etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
- lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
- sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
- share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
(7)扩展:本地测试官方案例WordCount
WordCount是一个统计文件内单词数量的程序。可以理解为MapReduce的helloword。
1)创建测试文件
?[hadoop@hadoop100 ~]$ cd /opt/module/hadoop-3.1.3
?[hadoop@hadoop100 hadoop-3.1.3]$ ?mkdir wcinput
?[hadoop@hadoop100 hadoop-3.1.3]$ ?cd wcinput
?[hadoop@hadoop100 wcinput]$ ? vim word.txt在文件中输入以下内容:
hadoop yarn
hadoop mapreduce
test
test
保存并退出: ?:wq
?2)执行程序
回到Hadoop目录/opt/module/hadoop-3.1.3,执行程序
? [hadoop@hadoop100 wcinput]$ ? cd ../
? [hadoop@hadoop100 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput命令结构:
hadoop jar ?Jar包的路径 ?Jar包的主类 传递给主类的参数地址 ?由主类执行后输出的结果地址
3)查看结果
[hadoop@hadoop100 hadoop-3.1.3]$ cat wcoutput/part-r-00000
文章来源:https://blog.csdn.net/qq_39512532/article/details/135134503
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!