Grafana Loki 配置解析
2023-12-28 15:34:37
Grafana Loki 配置文件是一个YML文件,在Grafana Loki 快速尝鲜的示例中是loki-config.yaml,该文件包含关于Loki 服务和各个组件的配置信息。由于配置数量实在太多,没法全部翻译,只能后期有需要了再补充。
如下是Grafana Loki 快速尝鲜一文中,安装完Loki后的默认配置:
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
common:
instance_addr: 127.0.0.1
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
schema_config:
configs:
- from: 2020-10-24
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
ruler:
alertmanager_url: http://localhost:9093
# By default, Loki will send anonymous, but uniquely-identifiable usage and configuration
# analytics to Grafana Labs. These statistics are sent to https://stats.grafana.org/
#
# Statistics help us better understand how Loki is used, and they show us performance
# levels for most users. This helps us prioritize features and documentation.
# For more information on what's sent, look at
# https://github.com/grafana/loki/blob/main/pkg/usagestats/stats.go
# Refer to the buildReport method to see what goes into a report.
#
# If you would like to disable reporting, uncomment the following lines:
#analytics:
# reporting_enabled: false
配置文件占位符说明
<boolean>布尔值,true或false<int>与[1-9]+[0-9]*匹配的整数<duration>与[0-9]+(ns|us|μs|ms|[smh])匹配的时间<labelname>与[a-zA-Z_][a-zA-Z0-9_]*匹配的字符串<labelvalue>unicode字符串<filename>相对路径或绝对路径<host>主机名或IP地址<string>string 字符串<secret>表示秘钥字符串
Loki支持的配置预览
# 要运行的组件列表,默认为all
# 允许的值有all, compactor, distributor, ingester, querier, query-scheduler,
# ingester-querier, query-frontend, index-gateway, ruler, table-manager, read, write
# CLI 参数: -target
[target: <string> | default = "all"]
# 开启通过X-Scope-OrgID头认证, 如果是true必须存在该头,false则OrgID被设置为fake
# CLI 参数: -auth.enabled
[auth_enabled: <boolean> | default = true]
# 为优化垃圾回收而预留的虚拟内存。以较大的内存为代价来减少垃圾回收次数
# CLI flag: -config.ballast-bytes
[ballast_bytes: <int> | default = 0]
# 配置已启动模块的服务
[server: <server>]
# 配置distributor(分发器)
[distributor: <distributor>]
# 配置查询器。仅用于以all启动或者只运行了querier的时候
[querier: <querier>]
# 配置后,将从query-frontend 分离查询队列
[query_scheduler: <query_scheduler>]
# query-frontend端配置
[frontend: <frontend>]
# 配置查询缓存和查询拆分
[query_range: <query_range>]
# 配置ruler
[ruler: <ruler>]
# 配置ingester(拉取器) 客户端,仅在all、distributor、querier下有效
[ingester_client: <ingester_client>]
# ingester 自身的配置
[ingester: <ingester>]
# 配置索引,使得查询不需要经常跟对象存储交互
[index_gateway: <index_gateway>]
# 配置各种存储,需要在schema_config中配置使用哪种存储
[storage_config: <storage_config>]
# 配置如何缓存块,以及在保存到存储之前等待多久时间
[chunk_store_config: <chunk_store_config>]
# 配置块索引结构和存储位置
[schema_config: <schema_config>]
# compactor压缩组件配置,有利于提高性能。
# -boltdb.shipper.compactor. 已经过期,请使用-compactor.
[compactor: <compactor>]
# 配置全局或者每个租户的限制,比如ingestion_rate_mb,用来限制拉取速率
[limits_config: <limits_config>]
# frontend_worker 主要配置frontend工作进程的最大并发数,frontend地址等
[frontend_worker: <frontend_worker>]
# 数据库相关的配置
[table_manager: <table_manager>]
# 仅当kvstore时,配置memberlist有效。
# 当至少定义了一个包含至少一个join_members的memberlist配置时,除非在组件配置部分中指定,
# 否则所有需要ring的所有组件都会自动选择类型为memberlist的kvstore
[memberlist: <memberlist>]
# 运行时配置,负责重新加载配置文件
[runtime_config: <runtime_config>]
# 跟踪配置
[tracing: <tracing>]
# 分析配置,包括使用报告等
[analytics: <analytics>]
# 多个模块之间共享的通用配置
# 如果在其他部分中给出了更具体的配置,则将忽略本部分中的相关配置
[common: <common>]
# SIGTERM 和 shutdown 之间等待多长时间。
# 收到SIGTERM后,Loki将通过/ready端点报告503服务不可用
# CLI flag: -shutdown-delay
[shutdown_delay: <duration> | default = 0s]
-config.file
-config.file 指定配置文件,逗号分割指定多个文件,但只会加载第一个文件。没有配置该参数,Loki会在当前工作目录和config/子目录中查找config.yaml。
-print-config-stderr
-print-config-stderr 打印配置文件
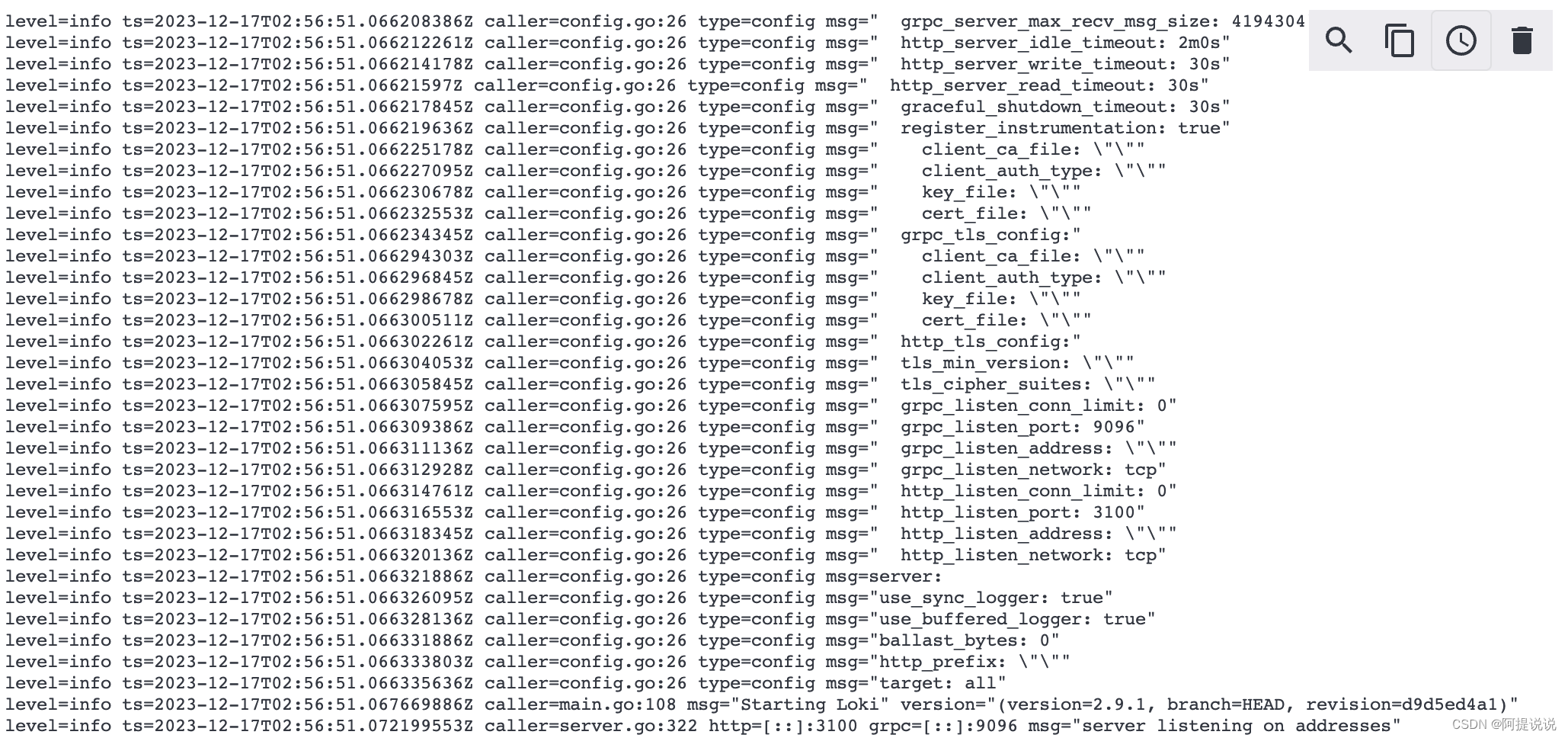
-log-config-reverse-order
-log-config-reverse-order反向打印配置文件,下图为打印的配置最后部分
-config.expand-env=true
-config.expand-env=true 开启环境变量引用,允许在Loki配置中引用环境变量的值
${VAR}
当环境变量不存在的时候,使用空字符串替代
${VAR:-default_value}
当环境变量不存在的时候,使用default_value替代
比如:${USER:-http://localhost:9093},USER变量不存在,显示的值是这样的
Loki 配置
server
配置已启动模块的服务
# HTTP 服务器网络监听类型,默认tcp
# CLI flag: -server.http-listen-network
[http_listen_network: <string> | default = "tcp"]
# HTTP服务器监听地址
# CLI flag: -server.http-listen-address
[http_listen_address: <string> | default = ""]
# HTTP服务器监听端口
# CLI flag: -server.http-listen-port
[http_listen_port: <int> | default = 3100]
# http最大连接数,<=0为禁用
# CLI flag: -server.http-conn-limit
[http_listen_conn_limit: <int> | default = 0]
# gRPC 监听类型
# CLI flag: -server.grpc-listen-network
[grpc_listen_network: <string> | default = "tcp"]
# gRPC监听地址
# CLI flag: -server.grpc-listen-address
[grpc_listen_address: <string> | default = ""]
# gRPC 监听端口
# CLI flag: -server.grpc-listen-port
[grpc_listen_port: <int> | default = 9095]
# gRPC同时最大连接数,<=0 为禁用
# CLI flag: -server.grpc-conn-limit
[grpc_listen_conn_limit: <int> | default = 0]
# 以逗号分隔的要使用的密码套件列表。如果为空,则使用默认的Go密码套件
# CLI flag: -server.tls-cipher-suites
[tls_cipher_suites: <string> | default = ""]
# 使用的最低TLS版本。允许值:VersionTLS10, VersionTLS11,VersionTLS12, VersionTLS13
# 如果为空,使用GO TLS 的最小版本
# CLI flag: -server.tls-min-version
[tls_min_version: <string> | default = ""]
http_tls_config:
# HTTP服务cert路径
# CLI flag: -server.http-tls-cert-path
[cert_file: <string> | default = ""]
# HTTP服务key路径
# CLI flag: -server.http-tls-key-path
[key_file: <string> | default = ""]
# HTTP TLS Client Auth type.
# CLI flag: -server.http-tls-client-auth
[client_auth_type: <string> | default = ""]
# HTTP TLS Client CA path.
# CLI flag: -server.http-tls-ca-path
[client_ca_file: <string> | default = ""]
grpc_tls_config:
# GRPC TLS server cert path.
# CLI flag: -server.grpc-tls-cert-path
[cert_file: <string> | default = ""]
# GRPC TLS server key path.
# CLI flag: -server.grpc-tls-key-path
[key_file: <string> | default = ""]
# GRPC TLS Client Auth type.
# CLI flag: -server.grpc-tls-client-auth
[client_auth_type: <string> | default = ""]
# GRPC TLS Client CA path.
# CLI flag: -server.grpc-tls-ca-path
[client_ca_file: <string> | default = ""]
# Register the intrumentation handlers (/metrics etc).
# CLI flag: -server.register-instrumentation
[register_instrumentation: <boolean> | default = true]
# 正常停机超时时间
# CLI flag: -server.graceful-shutdown-timeout
[graceful_shutdown_timeout: <duration> | default = 30s]
# Read timeout for HTTP server
# CLI flag: -server.http-read-timeout
[http_server_read_timeout: <duration> | default = 30s]
# Write timeout for HTTP server
# CLI flag: -server.http-write-timeout
[http_server_write_timeout: <duration> | default = 30s]
# Idle timeout for HTTP server
# CLI flag: -server.http-idle-timeout
[http_server_idle_timeout: <duration> | default = 2m]
# 能够接收的gRPC消息大小限制
# CLI flag: -server.grpc-max-recv-msg-size-bytes
[grpc_server_max_recv_msg_size: <int> | default = 4194304]
# 发送gRPC消息大小限制
# CLI flag: -server.grpc-max-send-msg-size-bytes
[grpc_server_max_send_msg_size: <int> | default = 4194304]
# gRPC调用并发数限制(0不限制)
# CLI flag: -server.grpc-max-concurrent-streams
[grpc_server_max_concurrent_streams: <int> | default = 100]
# 空闲gRPC连接关闭时间,默认无穷
# CLI flag: -server.grpc.keepalive.max-connection-idle
[grpc_server_max_connection_idle: <duration> | default = 2562047h47m16.854775807s]
# 连接在关闭之前可能存在的最长时间的持续时间,默认无穷
# CLI flag: -server.grpc.keepalive.max-connection-age
[grpc_server_max_connection_age: <duration> | default = 2562047h47m16.854775807s]
# 连接最长使用时间后的附加时间,在该时间后,连接将被强制关闭,默认无穷
# CLI flag: -server.grpc.keepalive.max-connection-age-grace
[grpc_server_max_connection_age_grace: <duration> | default = 2562047h47m16.854775807s]
# 连接保活时间,默认2h
# CLI flag: -server.grpc.keepalive.time
[grpc_server_keepalive_time: <duration> | default = 2h]
# 保活检查后,空闲连接关闭时间, 默认: 20s
# CLI flag: -server.grpc.keepalive.timeout
[grpc_server_keepalive_timeout: <duration> | default = 20s]
# 客户端发送保活请求之间等待的最小时间,如果请求频繁,服务端将发送GOAWAY并关闭连接
# CLI flag: -server.grpc.keepalive.min-time-between-pings
[grpc_server_min_time_between_pings: <duration> | default = 10s]
# 如果为true,服务端允许保活即使没有活动流(RPCs),如果fasle,服务端将发送GOAWAY并关闭连接
# CLI flag: -server.grpc.keepalive.ping-without-stream-allowed
[grpc_server_ping_without_stream_allowed: <boolean> | default = true]
# 以给定的格式,输出日志,有效格式:logfmt, json
# CLI flag: -log.format
[log_format: <string> | default = "logfmt"]
# 仅记录给定级别或以上的日志,可用级别:debug, info, warn, error
# CLI flag: -log.level
[log_level: <string> | default = "info"]
# 可选,记录源ip
# CLI flag: -server.log-source-ips-enabled
[log_source_ips_enabled: <boolean> | default = false]
# 存储源ip的header 字段,仅在 server.log-source-ips-enabled=true时有效
# 未配Forwarded, X-Real-IP 和 X-Forwarded-For,就使用header
# CLI flag: -server.log-source-ips-header
[log_source_ips_header: <string> | default = ""]
#用于匹配源ip,仅当server.log-source-ips-enabled=true时有效
# CLI flag: -server.log-source-ips-regex
[log_source_ips_regex: <string> | default = ""]
# 可选,记录请求头
# CLI flag: -server.log-request-headers
[log_request_headers: <boolean> | default = false]
# 在info 级别记录请求,如果开启了server.log-request-headers,也记录
# CLI flag: -server.log-request-at-info-level-enabled
[log_request_at_info_level_enabled: <boolean> | default = false]
# 逗号分割,要排除的header列表,仅当server.log-request-headers=true时有效
# CLI flag: -server.log-request-headers-exclude-list
[log_request_exclude_headers_list: <string> | default = ""]
# 所有路由的基本路径,比如/v1/
# CLI flag: -server.path-prefix
[http_path_prefix: <string> | default = ""]
distributor
配置分发器,distributor
ring:
kvstore:
# ring 后端存储,支持consul, etcd,inmemory, memberlist, multi
# CLI flag: -distributor.ring.store
[store: <string> | default = "consul"]
# 存储中的key前缀,应该以/结尾
# CLI flag: -distributor.ring.prefix
[prefix: <string> | default = "collectors/"]
# Consul配置,仅kvstore为consul时有效
# The CLI flags prefix for this block configuration is: distributor.ring
[consul: <consul>]
# ETCD v3 配置,仅在kvstore选择etcd时有效
# The CLI flags prefix for this block configuration is: distributor.ring
[etcd: <etcd>]
multi:
# multi-client 时,使用的主要后端存储
# CLI flag: -distributor.ring.multi.primary
[primary: <string> | default = ""]
# multi-client 时,辅助后端存储
# CLI flag: -distributor.ring.multi.secondary
[secondary: <string> | default = ""]
# 镜像写入辅助存储
# CLI flag: -distributor.ring.multi.mirror-enabled
[mirror_enabled: <boolean> | default = false]
# 辅助存储写入超时时间
# CLI flag: -distributor.ring.multi.mirror-timeout
[mirror_timeout: <duration> | default = 2s]
# ring的心跳周期,0为禁用
# CLI flag: -distributor.ring.heartbeat-period
[heartbeat_period: <duration> | default = 5s]
# 心跳检测超时后,分发器被认为在ring内是不健康的,0为永不(超时禁用)
# CLI flag: -distributor.ring.heartbeat-timeout
[heartbeat_timeout: <duration> | default = 1m]
# 要从中读取的网络接口名称
# CLI flag: -distributor.ring.instance-interface-names
[instance_interface_names: <list of strings> | default = [<private network interfaces>]]
rate_store:
# 向ingester请求的最大并发数
# CLI flag: -distributor.rate-store.max-request-parallelism
[max_request_parallelism: <int> | default = 200]
# 来自ingester的更新流速间隔
# CLI flag: -distributor.rate-store.stream-rate-update-interval
[stream_rate_update_interval: <duration> | default = 1s]
# 更新速率时,distributor 与 特定ingester之间的通信超时时间
# CLI flag: -distributor.rate-store.ingester-request-timeout
[ingester_request_timeout: <duration> | default = 500ms]
# 是否开启debug
# CLI flag: -distributor.rate-store.debug
[debug: <boolean> | default = false]
# 实验性,自定义写入失败的日志
write_failures_logging:
# 实验性会改变的配置,允许的每秒日志记录大小
# Default: 1KB.
# CLI flag: -distributor.write-failures-logging.rate
[rate: <int> | default = 1KB]
# 实验性会改变的配置,insight=true key是否记录,默认false
# CLI flag: -distributor.write-failures-logging.add-insights-label
[add_insights_label: <boolean> | default = false]
querier
配置查询器。仅用于以all启动或者只运行了querier的时候
# 提供实时跟踪请求的最长持续时间
# CLI flag: -querier.tail-max-duration
[tail_max_duration: <duration> | default = 1h]
# 发送超过最小成功查询请求数之前等待的时间
# CLI flag: -querier.extra-query-delay
[extra_query_delay: <duration> | default = 0s]
# 查询的最大回顾时间,超过该时间的查询不会发送到ingester,0表示所有请求发送到ingester
# CLI flag: -querier.query-ingesters-within
[query_ingesters_within: <duration> | default = 3h]
engine:
# 过时,使用querier.query-timeout代替。查询超时时间
# CLI flag: -querier.engine.timeout
[timeout: <duration> | default = 5m]
# 查看日志的最大时间,仅用于实时日志查询
# CLI flag: -querier.engine.max-lookback-period
[max_look_back_period: <duration> | default = 30s]
# 查询的最大并发数
# CLI flag: -querier.max-concurrent
[max_concurrent: <int> | default = 10]
# 为true,仅查询存储,不对接ingester。这在只针对存储数据运行独立的查询池时非常有用
# CLI flag: -querier.query-store-only
[query_store_only: <boolean> | default = false]
# 为true,仅查询ingester,而不查询存储。这在对象存储不可用时,非常有用
# CLI flag: -querier.query-ingester-only
[query_ingester_only: <boolean> | default = false]
# 如果为true,则允许查询跨越多个租户
# CLI flag: -querier.multi-tenant-queries-enabled
[multi_tenant_queries_enabled: <boolean> | default = false]
# 当为true时,将强制执行通过header发送的查询限制
# CLI flag: -querier.per-request-limits-enabled
[per_request_limits_enabled: <boolean> | default = false]
query_scheduler
配置后,将从query-frontend 分离查询队列
# 每个租户中每个query_scheduler的最大未处理请求数
# 如果超过了该限制,正在进行的请求将失败,报429错误
# CLI flag: -query-scheduler.max-outstanding-requests-per-tenant
[max_outstanding_requests_per_tenant: <int> | default = 100]
# 队列最大嵌套数,0意味着禁止
# CLI flag: -query-scheduler.max-queue-hierarchy-levels
[max_queue_hierarchy_levels: <int> | default = 3]
# 如果查询者在没有发送有关优雅关闭通知的情况下断开连接,查询调度程序将查询者保留在租户的shard中,直到过了延时时间。
# 当 shuffle-sharding开启的时候,这个功能有助于减小影响范围
# CLI flag: -query-scheduler.querier-forget-delay
[querier_forget_delay: <duration> | default = 0s]
# 该配置用于将错误返回到query-frontend的gRPC客户端
# The CLI flags prefix for this block configuration is:
# query-scheduler.grpc-client-config
[grpc_client_config: <grpc_client>]
# 为true 表示创建query schedulers,并将本身也置于ring中。
# 如果没有frontend_address 或者 scheduler_address,该值被设置为true
# CLI flag: -query-scheduler.use-scheduler-ring
[use_scheduler_ring: <boolean> | default = false]
# hash ring 配置,只有在use_scheduler_ring为true时有效
scheduler_ring:
kvstore:
# 使用ring时的存储,支持consul, etcd,inmemory, memberlist, multi
# CLI flag: -query-scheduler.ring.store
[store: <string> | default = "consul"]
# 存储中key的前缀,应该以/结尾
# CLI flag: -query-scheduler.ring.prefix
[prefix: <string> | default = "collectors/"]
# Consul 客户端的配置。kvstore选择consul的时候有效
# The CLI flags prefix for this block configuration is: query-scheduler.ring
[consul: <consul>]
# ETCD v3 客户端配置,kvstore选择etcd时有效
# The CLI flags prefix for this block configuration is: query-scheduler.ring
[etcd: <etcd>]
multi:
# multi-client 时主存储
# CLI flag: -query-scheduler.ring.multi.primary
[primary: <string> | default = ""]
# multi-client时的辅助存储
# CLI flag: -query-scheduler.ring.multi.secondary
[secondary: <string> | default = ""]
# 镜像写入辅助存储
# CLI flag: -query-scheduler.ring.multi.mirror-enabled
[mirror_enabled: <boolean> | default = false]
# 镜像写入辅助存储的超时时间
# CLI flag: -query-scheduler.ring.multi.mirror-timeout
[mirror_timeout: <duration> | default = 2s]
# ring的心跳周期,0为禁用
# CLI flag: -query-scheduler.ring.heartbeat-period
[heartbeat_period: <duration> | default = 15s]
# 心跳检测超时后,压缩器被认为在ring内是不健康的,0为永不(超时禁用)
# CLI flag: -query-scheduler.ring.heartbeat-timeout
[heartbeat_timeout: <duration> | default = 1m]
# token 存储路径,如果为空,则在关闭时不存储令牌,在启动时恢复令牌
# CLI flag: -query-scheduler.ring.tokens-file-path
[tokens_file_path: <string> | default = ""]
# 为true表示可实现区域感知并跨不同可用性区域复制数据块
# CLI flag: -query-scheduler.ring.zone-awareness-enabled
[zone_awareness_enabled: <boolean> | default = false]
# 要在ring 中注册的实例id
# CLI flag: -query-scheduler.ring.instance-id
[instance_id: <string> | default = "<hostname>"]
# 要从中读取地址的网络接口的名称
# CLI flag: -query-scheduler.ring.instance-interface-names
[instance_interface_names: <list of strings> | default = [<private network interfaces>]]
# 在ring 中的端口,默认使用server.grpc-listen-port
# CLI flag: -query-scheduler.ring.instance-port
[instance_port: <int> | default = 0]
# 在ring 中的 IP 地址
# IP address to advertise in the ring.
# CLI flag: -query-scheduler.ring.instance-addr
[instance_addr: <string> | default = ""]
# 运行该实例的可用性区域,如果zone-awareness 是开启的,则必选
# CLI flag: -query-scheduler.ring.instance-availability-zone
[instance_availability_zone: <string> | default = ""]
# 开启实例 IPv6 地址
# CLI flag: -query-scheduler.ring.instance-enable-ipv6
[instance_enable_ipv6: <boolean> | default = false]
frontend
query-frontend端配置
# 记录比指定时间慢的查询,0表示禁用, <0 开启所有查询
# Log queries that are slower than the specified duration. Set to 0 to disable.
# Set to < 0 to enable on all queries.
# CLI flag: -frontend.log-queries-longer-than
[log_queries_longer_than: <duration> | default = 0s]
# 下游prometheus的最大请求体
# Max body size for downstream prometheus.
# CLI flag: -frontend.max-body-size
[max_body_size: <int> | default = 10485760]
# true表示开启查询统计信息跟踪,每个查询都会记录一条带有一些统计信息的消息
# True to enable query statistics tracking. When enabled, a message with some
# statistics is logged for every query.
# CLI flag: -frontend.query-stats-enabled
[query_stats_enabled: <boolean> | default = false]
# 每个租户每个frontend的最大请求数。超出这个数返回HTTP 429
# Maximum number of outstanding requests per tenant per frontend; requests
# beyond this error with HTTP 429.
# CLI flag: -querier.max-outstanding-requests-per-tenant
[max_outstanding_per_tenant: <int> | default = 2048]
#如果租户重复发送查询,导致查询器崩溃或因内存不足错误而终止,
#则崩溃的查询器将与查询前端断开连接,并立即将新的查询器分配给租户的碎片
#这就使得哈希分片可以减少对租户的影响的假设失效。
#该选项通过在查询器因崩溃而断开连接和实际将崩溃的查询器从租户的分片中移除之间配置延迟来缓解影响
# In the event a tenant is repeatedly sending queries that lead the querier to
# crash or be killed due to an out-of-memory error, the crashed querier will be
# disconnected from the query frontend and a new querier will be immediately
# assigned to the tenant’s shard. This invalidates the assumption that shuffle
# sharding can be used to reduce the impact on tenants. This option mitigates
# the impact by configuring a delay between when a querier disconnects because
# of a crash and when the crashed querier is actually removed from the tenant's
# shard.
# CLI flag: -query-frontend.querier-forget-delay
[querier_forget_delay: <duration> | default = 0s]
# DNS 主机名用于查找query-schedulers
# CLI flag: -frontend.scheduler-address
[scheduler_address: <string> | default = ""]
# query-schedulers解析评率,用于查找新的query-scheduler实例
# 如果配置了scheduler-ring,也用于确定获取scheduler-ring地址的频率
# How often to resolve the scheduler-address, in order to look for new
# query-scheduler instances. Also used to determine how often to poll the
# scheduler-ring for addresses if the scheduler-ring is configured.
# CLI flag: -frontend.scheduler-dns-lookup-period
[scheduler_dns_lookup_period: <duration> | default = 10s]
#将查询转发到单个query-scheduler时的并发数
# Number of concurrent workers forwarding queries to single query-scheduler.
# CLI flag: -frontend.scheduler-worker-concurrency
[scheduler_worker_concurrency: <int> | default = 5]
# grpc_client配置用于在两个Loki组件之间通信的grpc客户端,见后面的grpc_client配置
# The grpc_client block configures the gRPC client used to communicate between
# two Loki components.
# The CLI flags prefix for this block configuration is:
# frontend.grpc-client-config
[grpc_client_config: <grpc_client>]
# 在关机之前等待请求完成的时间,需要跟查询器超时时间和优雅关机保持一致
# Time to wait for inflight requests to finish before forcefully shutting down.
# This needs to be aligned with the query timeout and the graceful termination
# period of the process orchestrator.
# CLI flag: -frontend.graceful-shutdown-timeout
[graceful_shutdown_timeout: <duration> | default = 5m]
# 要从中读取地址的网络接口名称。这个地址被发送到query-scheduler和querier,
# querier使用它将查询响应发送回query-frontend
# Name of network interface to read address from. This address is sent to
# query-scheduler and querier, which uses it to send the query response back to
# query-frontend.
# CLI flag: -frontend.instance-interface-names
[instance_interface_names: <list of strings> | default = [<private network interfaces>]]
# 是否压缩http响应
# Compress HTTP responses.
# CLI flag: -querier.compress-http-responses
[compress_responses: <boolean> | default = false]
# 下游Loki的URL
# URL of downstream Loki.
# CLI flag: -frontend.downstream-url
[downstream_url: <string> | default = ""]
# 尾部代理的查询器 URL
# URL of querier for tail proxy.
# CLI flag: -frontend.tail-proxy-url
[tail_proxy_url: <string> | default = ""]
# TLS配置
# The TLS configuration.
[tail_tls_config: <tls_config>]
query_range
配置查询缓存和查询拆分
# 过期配置,使用-querier.split-queries-by-interval 替代
# Deprecated: Use -querier.split-queries-by-interval instead. CLI flag:
# -querier.split-queries-by-day. Split queries by day and execute in parallel.
[split_queries_by_interval: <duration>]
# 将输入的查询进行变换,使其起始位置和结束位置与其步长对齐
# Mutate incoming queries to align their start and end with their step.
# CLI flag: -querier.align-querier-with-step
[align_queries_with_step: <boolean> | default = false]
results_cache:
# 缓存配置
# The cache block configures the cache backend.
# The CLI flags prefix for this block configuration is: frontend
[cache: <cache_config>]
# 是否压缩,默认为空,禁用压缩。支持值有 'snappy' 和''
# Use compression in cache. The default is an empty value '', which disables
# compression. Supported values are: 'snappy' and ''.
# CLI flag: -frontend.compression
[compression: <string> | default = ""]
# 是否缓存查询结果
# Cache query results.
# CLI flag: -querier.cache-results
[cache_results: <boolean> | default = false]
# 单个请求的最大重试次数。除外,还会返回下游错误
# Maximum number of retries for a single request; beyond this, the downstream
# error is returned.
# CLI flag: -querier.max-retries-per-request
[max_retries: <int> | default = 5]
# 基于存储分片配置和查询AST执行查询并行化,此功能仅由分块存储引擎支持
# Perform query parallelisations based on storage sharding configuration and
# query ASTs. This feature is supported only by the chunks storage engine.
# CLI flag: -querier.parallelise-shardable-queries
[parallelise_shardable_queries: <boolean> | default = true]
# 过期,查询前端转发到下游查询器的标头列表
# Deprecated. List of headers forwarded by the query Frontend to downstream
# querier.
# CLI flag: -frontend.forward-headers-list
[forward_headers_list: <list of strings> | default = []]
# 下游查询器指定的响应格式,可以是json或protobuf,两者还是通过GRPC路由
# The downstream querier is required to answer in the accepted format. Can be
# 'json' or 'protobuf'. Note: Both will still be routed over GRPC.
# CLI flag: -frontend.required-query-response-format
[required_query_response_format: <string> | default = "json"]
# 是否缓存索引统计信息查询结果
# Cache index stats query results.
# CLI flag: -querier.cache-index-stats-results
[cache_index_stats_results: <boolean> | default = false]
# 如果未指定缓存配置,并且cache_index_stats_results是true,那么使用这个配置
# If a cache config is not specified and cache_index_stats_results is true, the
# config for the results cache is used.
index_stats_results_cache:
# 缓存块配置
# The cache block configures the cache backend.
# The CLI flags prefix for this block configuration is:
# frontend.index-stats-results-cache
[cache: <cache_config>]
# 缓存压缩
# Use compression in cache. The default is an empty value '', which disables
# compression. Supported values are: 'snappy' and ''.
# CLI flag: -frontend.index-stats-results-cache.compression
[compression: <string> | default = ""]
ruler
配置ruler规则
# Grafana 实例的基础URL
# Base URL of the Grafana instance.
# CLI flag: -ruler.external.url
[external_url: <url>]
# 仪表板数据源UID
# Datasource UID for the dashboard.
# CLI flag: -ruler.datasource-uid
[datasource_uid: <string> | default = ""]
# 添加到所有警报的额外标签
# Labels to add to all alerts.
[external_labels: <list of Labels>]
#grpc_client配置用于在两个Loki组件之间通信的grpc客户端
# The grpc_client block configures the gRPC client used to communicate between
# two Loki components.
# The CLI flags prefix for this block configuration is: ruler.client
[ruler_client: <grpc_client>]
# 评估规则的频率
# How frequently to evaluate rules.
# CLI flag: -ruler.evaluation-interval
[evaluation_interval: <duration> | default = 1m]
# 轮询规则更改的频率
# How frequently to poll for rule changes.
# CLI flag: -ruler.poll-interval
[poll_interval: <duration> | default = 1m]
# 过期,使用-ruler-storage
# Deprecated: Use -ruler-storage. CLI flags and their respective YAML config
# options instead.
storage:
# 后端存储类型
# Method to use for backend rule storage (configdb, azure, gcs, s3, swift,
# local, bos, cos)
# CLI flag: -ruler.storage.type
[type: <string> | default = ""]
# Configures backend rule storage for Azure.
# The CLI flags prefix for this block configuration is: ruler.storage
[azure: <azure_storage_config>]
# Configures backend rule storage for AlibabaCloud Object Storage (OSS).
# The CLI flags prefix for this block configuration is: ruler
[alibabacloud: <alibabacloud_storage_config>]
# Configures backend rule storage for GCS.
# The CLI flags prefix for this block configuration is: ruler.storage
[gcs: <gcs_storage_config>]
# Configures backend rule storage for S3.
# The CLI flags prefix for this block configuration is: ruler
[s3: <s3_storage_config>]
# Configures backend rule storage for Baidu Object Storage (BOS).
# The CLI flags prefix for this block configuration is: ruler.storage
[bos: <bos_storage_config>]
# Configures backend rule storage for Swift.
# The CLI flags prefix for this block configuration is: ruler.storage
[swift: <swift_storage_config>]
# Configures backend rule storage for IBM Cloud Object Storage (COS).
# The CLI flags prefix for this block configuration is: ruler.storage
[cos: <cos_storage_config>]
# Configures backend rule storage for a local file system directory.
local:
# Directory to scan for rules
# CLI flag: -ruler.storage.local.directory
[directory: <string> | default = ""]
#用于存储临时规则文件的文件路径
# File path to store temporary rule files.
# CLI flag: -ruler.rule-path
[rule_path: <string> | default = "/rules"]
# 要向其发送通知的Alertmanager URL的逗号分隔列表
# 每个Alertmanager URL在配置中被视为一个单独的组
# 通过“-duler.alertmanager discovery”使用DNS解析,可以支持每个组HA中的多个alertmanager
# Comma-separated list of Alertmanager URLs to send notifications to. Each
# Alertmanager URL is treated as a separate group in the configuration. Multiple
# Alertmanagers in HA per group can be supported by using DNS resolution via
# '-ruler.alertmanager-discovery'.
# CLI flag: -ruler.alertmanager-url
[alertmanager_url: <string> | default = ""]
# 使用DNS SRV记录来发现Alertmanager主机
# Use DNS SRV records to discover Alertmanager hosts.
# CLI flag: -ruler.alertmanager-discovery
[enable_alertmanager_discovery: <boolean> | default = false]
# 刷新Alertmanager主机的DNS解析之间需要等待多长时间
# How long to wait between refreshing DNS resolutions of Alertmanager hosts.
# CLI flag: -ruler.alertmanager-refresh-interval
[alertmanager_refresh_interval: <duration> | default = 1m]
# 如果启用了对警报管理器的请求,则将使用V2 API
# If enabled requests to Alertmanager will utilize the V2 API.
# CLI flag: -ruler.alertmanager-use-v2
[enable_alertmanager_v2: <boolean> | default = false]
# 警报重新配置列表
# List of alert relabel configs.
[alert_relabel_configs: <relabel_config...>]
# 要发送到Alertmanager的通知的队列容量
# Capacity of the queue for notifications to be sent to the Alertmanager.
# CLI flag: -ruler.notification-queue-capacity
[notification_queue_capacity: <int> | default = 10000]
# 向Alertmanager发送通知时的HTTP超时持续时间
# HTTP timeout duration when sending notifications to the Alertmanager.
# CLI flag: -ruler.notification-timeout
[notification_timeout: <duration> | default = 10s]
alertmanager_client:
# 客户端证书路径,用于服务器身份验证,还要配置key路径
# Path to the client certificate, which will be used for authenticating with
# the server. Also requires the key path to be configured.
# CLI flag: -ruler.alertmanager-client.tls-cert-path
[tls_cert_path: <string> | default = ""]
# 客户端证书key路径,要求客户端证书配置
# Path to the key for the client certificate. Also requires the client
# certificate to be configured.
# CLI flag: -ruler.alertmanager-client.tls-key-path
[tls_key_path: <string> | default = ""]
# Path to the CA certificates to validate server certificate against. If not
# set, the host's root CA certificates are used.
# CLI flag: -ruler.alertmanager-client.tls-ca-path
[tls_ca_path: <string> | default = ""]
# Override the expected name on the server certificate.
# CLI flag: -ruler.alertmanager-client.tls-server-name
[tls_server_name: <string> | default = ""]
# Skip validating server certificate.
# CLI flag: -ruler.alertmanager-client.tls-insecure-skip-verify
[tls_insecure_skip_verify: <boolean> | default = false]
# Override the default cipher suite list (separated by commas). Allowed
# values:
#
# Secure Ciphers:
# - TLS_RSA_WITH_AES_128_CBC_SHA
# - TLS_RSA_WITH_AES_256_CBC_SHA
# - TLS_RSA_WITH_AES_128_GCM_SHA256
# - TLS_RSA_WITH_AES_256_GCM_SHA384
# - TLS_AES_128_GCM_SHA256
# - TLS_AES_256_GCM_SHA384
# - TLS_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256
#
# Insecure Ciphers:
# - TLS_RSA_WITH_RC4_128_SHA
# - TLS_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_RSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_ECDSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
# CLI flag: -ruler.alertmanager-client.tls-cipher-suites
[tls_cipher_suites: <string> | default = ""]
# Override the default minimum TLS version. Allowed values: VersionTLS10,
# VersionTLS11, VersionTLS12, VersionTLS13
# CLI flag: -ruler.alertmanager-client.tls-min-version
[tls_min_version: <string> | default = ""]
# HTTP Basic 认证的username,会覆盖URL中设置的username
# HTTP Basic authentication username. It overrides the username set in the URL
# (if any).
# CLI flag: -ruler.alertmanager-client.basic-auth-username
[basic_auth_username: <string> | default = ""]
# HTTP Basic 认证的password,会覆盖URL中设置的password
# HTTP Basic authentication password. It overrides the password set in the URL
# (if any).
# CLI flag: -ruler.alertmanager-client.basic-auth-password
[basic_auth_password: <string> | default = ""]
# HTTP头认证类型
# HTTP Header authorization type (default: Bearer).
# CLI flag: -ruler.alertmanager-client.type
[type: <string> | default = "Bearer"]
# HTTP 头授权凭证
# HTTP Header authorization credentials.
# CLI flag: -ruler.alertmanager-client.credentials
[credentials: <string> | default = ""]
# HTTP头授权凭证文件
# HTTP Header authorization credentials file.
# CLI flag: -ruler.alertmanager-client.credentials-file
[credentials_file: <string> | default = ""]
# for状态评估的最大时间
# Max time to tolerate outage for restoring "for" state of alert.
# CLI flag: -ruler.for-outage-tolerance
[for_outage_tolerance: <duration> | default = 1h]
# 警报和恢复 for 状态之间的最短持续时间。仅当配置的 for 时间大于这个宽限期时,才维护
# Minimum duration between alert and restored "for" state. This is maintained
# only for alerts with configured "for" time greater than the grace period.
# CLI flag: -ruler.for-grace-period
[for_grace_period: <duration> | default = 10m]
# 向 Alertmanager重新发送警报之前等待的最短时间
# Minimum amount of time to wait before resending an alert to Alertmanager.
# CLI flag: -ruler.resend-delay
[resend_delay: <duration> | default = 1m]
# 使用环形后端分发规则评估
# Distribute rule evaluation using ring backend.
# CLI flag: -ruler.enable-sharding
[enable_sharding: <boolean> | default = false]
# 使用的分片策略。支持:default, shuffle-sharding
# The sharding strategy to use. Supported values are: default, shuffle-sharding.
# CLI flag: -ruler.sharding-strategy
[sharding_strategy: <string> | default = "default"]
# 决定如何对规则和组进行分片的分片算法
# The sharding algorithm to use for deciding how rules & groups are sharded.
# Supported values are: by-group, by-rule.
# CLI flag: -ruler.sharding-algo
[sharding_algo: <string> | default = "by-group"]
# 关闭时花在搜索待处理规则上的时间
# Time to spend searching for a pending ruler when shutting down.
# CLI flag: -ruler.search-pending-for
[search_pending_for: <duration> | default = 5m]
# Loki 规则使用的Ring
# Ring used by Loki ruler. The CLI flags prefix for this block configuration is
# 'ruler.ring'.
ring:
kvstore:
# ring 使用的后端存储
# Backend storage to use for the ring. Supported values are: consul, etcd,
# inmemory, memberlist, multi.
# CLI flag: -ruler.ring.store
[store: <string> | default = "consul"]
# The prefix for the keys in the store. Should end with a /.
# CLI flag: -ruler.ring.prefix
[prefix: <string> | default = "rulers/"]
# Configuration for a Consul client. Only applies if the selected kvstore is
# consul.
# The CLI flags prefix for this block configuration is: ruler.ring
[consul: <consul>]
# Configuration for an ETCD v3 client. Only applies if the selected kvstore
# is etcd.
# The CLI flags prefix for this block configuration is: ruler.ring
[etcd: <etcd>]
multi:
# multi-client 时主存储
# Primary backend storage used by multi-client.
# CLI flag: -ruler.ring.multi.primary
[primary: <string> | default = ""]
# multi-client 时辅助存储
# Secondary backend storage used by multi-client.
# CLI flag: -ruler.ring.multi.secondary
[secondary: <string> | default = ""]
# 镜像写入辅助存储
# Mirror writes to secondary store.
# CLI flag: -ruler.ring.multi.mirror-enabled
[mirror_enabled: <boolean> | default = false]
# 镜像写入辅助存储的超时时间
# Timeout for storing value to secondary store.
# CLI flag: -ruler.ring.multi.mirror-timeout
[mirror_timeout: <duration> | default = 2s]
# ring的心跳周期,0为禁用
# Interval between heartbeats sent to the ring. 0 = disabled.
# CLI flag: -ruler.ring.heartbeat-period
[heartbeat_period: <duration> | default = 5s]
# 心跳检测超时后,这个ruler再环内被认为是不健康的
# The heartbeat timeout after which ruler ring members are considered
# unhealthy within the ring. 0 = never (timeout disabled).
# CLI flag: -ruler.ring.heartbeat-timeout
[heartbeat_timeout: <duration> | default = 1m]
# 要从中读取地址的网络接口名称
# Name of network interface to read addresses from.
# CLI flag: -ruler.ring.instance-interface-names
[instance_interface_names: <list of strings> | default = [<private network interfaces>]]
# 如果在没有从另一个lifecycler转移令牌的情况下加入,则lifecycler将生成并放入环中的令牌数
# The number of tokens the lifecycler will generate and put into the ring if
# it joined without transferring tokens from another lifecycler.
# CLI flag: -ruler.ring.num-tokens
[num_tokens: <int> | default = 128]
# 刷新规则组的时间段
# Period with which to attempt to flush rule groups.
# CLI flag: -ruler.flush-period
[flush_period: <duration> | default = 1m]
# 开启规则api
# Enable the ruler API.
# CLI flag: -ruler.enable-api
[enable_api: <boolean> | default = true]
# 该规则可以评估的租户列表,逗号分割。如果指定,只有这些租户会被规则处理,否则该规则处理所有的租户
# Comma separated list of tenants whose rules this ruler can evaluate. If
# specified, only these tenants will be handled by ruler, otherwise this ruler
# can process rules from all tenants. Subject to sharding.
# CLI flag: -ruler.enabled-tenants
[enabled_tenants: <string> | default = ""]
# 该规则不评估的租户列表
# Comma separated list of tenants whose rules this ruler cannot evaluate. If
# specified, a ruler that would normally pick the specified tenant(s) for
# processing will ignore them instead. Subject to sharding.
# CLI flag: -ruler.disabled-tenants
[disabled_tenants: <string> | default = ""]
# 将 ruler 查询完成的总耗时作为每个用户的指标报告,并做为info 级别的日志信息
# Report the wall time for ruler queries to complete as a per user metric and as
# an info level log message.
# CLI flag: -ruler.query-stats-enabled
[query_stats_enabled: <boolean> | default = false]
# 再导出的指标中禁用rule_group
# Disable the rule_group label on exported metrics.
# CLI flag: -ruler.disable-rule-group-label
[disable_rule_group_label: <boolean> | default = false]
wal:
# 预写日志(WAL)文件目录,每个租户都有一个自己的目录
# The directory in which to write tenant WAL files. Each tenant will have its
# own directory one level below this directory.
# CLI flag: -ruler.wal.dir
[dir: <string> | default = "ruler-wal"]
# WAL 压缩进程的频率
# Frequency with which to run the WAL truncation process.
# CLI flag: -ruler.wal.truncate-frequency
[truncate_frequency: <duration> | default = 1h]
# Minimum age that samples must exist in the WAL before being truncated.
# CLI flag: -ruler.wal.min-age
[min_age: <duration> | default = 5m]
# 开始压缩之前在WAL中存在的最大年龄
# Maximum age that samples must exist in the WAL before being truncated.
# CLI flag: -ruler.wal.max-age
[max_age: <duration> | default = 4h]
wal_cleaner:
# 用于清理的WAL的最小文件年龄
# The minimum age of a WAL to consider for cleaning.
# CLI flag: -ruler.wal-cleaner.min-age
[min_age: <duration> | default = 12h]
# Deprecated: CLI flag -ruler.wal-cleaer.period.
# Use -ruler.wal-cleaner.period instead.
#
# How often to run the WAL cleaner. 0 = disabled.
# CLI flag: -ruler.wal-cleaner.period
[period: <duration> | default = 0s]
# 远程写入配置,用来发送规则样本到Prometheus远程端点
# Remote-write configuration to send rule samples to a Prometheus remote-write
# endpoint.
remote_write:
# Deprecated: Use 'clients' instead. Configure remote write client.
[client: <RemoteWriteConfig>]
# 配置远程写入客户端。以远程客户端id做为map的key
# Configure remote write clients. A map with remote client id as key.
[clients: <map of string to RemoteWriteConfig>]
# 是否启用远程写入功能
# Enable remote-write functionality.
# CLI flag: -ruler.remote-write.enabled
[enabled: <boolean> | default = false]
# 刷新远程配置之间等待的最短时间
# Minimum period to wait between refreshing remote-write reconfigurations.
# This should be greater than or equivalent to
# -limits.per-user-override-period.
# CLI flag: -ruler.remote-write.config-refresh-period
[config_refresh_period: <duration> | default = 10s]
# 规则评估配置
# Configuration for rule evaluation.
evaluation:
# 评估模式。可以是'local'或者'remote'。
# The evaluation mode for the ruler. Can be either 'local' or 'remote'. If set
# to 'local', the ruler will evaluate rules locally. If set to 'remote', the
# ruler will evaluate rules remotely. If unset, the ruler will evaluate rules
# locally.
# CLI flag: -ruler.evaluation.mode
[mode: <string> | default = "local"]
# 在规则评估之前等待的随机持续时间的上限,以避免在规则的并发执行过程中发生争用。
# 对于给定的规则,抖动会一致的计算。设为0表示禁用
# Upper bound of random duration to wait before rule evaluation to avoid
# contention during concurrent execution of rules. Jitter is calculated
# consistently for a given rule. Set 0 to disable (default).
# CLI flag: -ruler.evaluation.max-jitter
[max_jitter: <duration> | default = 0s]
query_frontend:
# GRPC listen address of the query-frontend(s). Must be a DNS address
# (prefixed with dns:///) to enable client side load balancing.
# CLI flag: -ruler.evaluation.query-frontend.address
[address: <string> | default = ""]
# Set to true if query-frontend connection requires TLS.
# CLI flag: -ruler.evaluation.query-frontend.tls-enabled
[tls_enabled: <boolean> | default = false]
# Path to the client certificate, which will be used for authenticating with
# the server. Also requires the key path to be configured.
# CLI flag: -ruler.evaluation.query-frontend.tls-cert-path
[tls_cert_path: <string> | default = ""]
# Path to the key for the client certificate. Also requires the client
# certificate to be configured.
# CLI flag: -ruler.evaluation.query-frontend.tls-key-path
[tls_key_path: <string> | default = ""]
# Path to the CA certificates to validate server certificate against. If not
# set, the host's root CA certificates are used.
# CLI flag: -ruler.evaluation.query-frontend.tls-ca-path
[tls_ca_path: <string> | default = ""]
# Override the expected name on the server certificate.
# CLI flag: -ruler.evaluation.query-frontend.tls-server-name
[tls_server_name: <string> | default = ""]
# Skip validating server certificate.
# CLI flag: -ruler.evaluation.query-frontend.tls-insecure-skip-verify
[tls_insecure_skip_verify: <boolean> | default = false]
# Override the default cipher suite list (separated by commas). Allowed
# values:
#
# Secure Ciphers:
# - TLS_RSA_WITH_AES_128_CBC_SHA
# - TLS_RSA_WITH_AES_256_CBC_SHA
# - TLS_RSA_WITH_AES_128_GCM_SHA256
# - TLS_RSA_WITH_AES_256_GCM_SHA384
# - TLS_AES_128_GCM_SHA256
# - TLS_AES_256_GCM_SHA384
# - TLS_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256
#
# Insecure Ciphers:
# - TLS_RSA_WITH_RC4_128_SHA
# - TLS_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_RSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_ECDSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
# CLI flag: -ruler.evaluation.query-frontend.tls-cipher-suites
[tls_cipher_suites: <string> | default = ""]
# Override the default minimum TLS version. Allowed values: VersionTLS10,
# VersionTLS11, VersionTLS12, VersionTLS13
# CLI flag: -ruler.evaluation.query-frontend.tls-min-version
[tls_min_version: <string> | default = ""]
ingester_client
配置ingester(拉取器) 客户端,仅在all、distributor、querier下有效
# 连接池的配置
# Configures how connections are pooled.
pool_config:
# 多久清理一次,已删除的拉取器客户端
# How frequently to clean up clients for ingesters that have gone away.
# CLI flag: -distributor.client-cleanup-period
[client_cleanup_period: <duration> | default = 15s]
# 在定期清理期间,对每个拉取器客户端进行健康检查
# Run a health check on each ingester client during periodic cleanup.
# CLI flag: -distributor.health-check-ingesters
[health_check_ingesters: <boolean> | default = true]
# 检测到一个无效的客户端后,删除该客户端的时间。设置该值表示允许二次健康检查来恢复丢失的客户端。
# How quickly a dead client will be removed after it has been detected to
# disappear. Set this to a value to allow time for a secondary health check to
# recover the missing client.
# CLI flag: -ingester.client.healthcheck-timeout
[remote_timeout: <duration> | default = 1s]
# 客户端的远程请求超时时间
# The remote request timeout on the client side.
# CLI flag: -ingester.client.timeout
[remote_timeout: <duration> | default = 5s]
# 跟拉取器连接的gRPC客户端配置
# Configures how the gRPC connection to ingesters work as a client.
# The CLI flags prefix for this block configuration is: ingester.client
[grpc_client_config: <grpc_client>]
ingester
ingester 自身的配置
# 配置拉取器的生命周期如何运行以及在哪里注册发现
# Configures how the lifecycle of the ingester will operate and where it will
# register for discovery.
lifecycler:
ring:
kvstore:
# Backend storage to use for the ring. Supported values are: consul, etcd,
# inmemory, memberlist, multi.
# CLI flag: -ring.store
[store: <string> | default = "consul"]
# The prefix for the keys in the store. Should end with a /.
# CLI flag: -ring.prefix
[prefix: <string> | default = "collectors/"]
# Configuration for a Consul client. Only applies if the selected kvstore
# is consul.
[consul: <consul>]
# Configuration for an ETCD v3 client. Only applies if the selected
# kvstore is etcd.
[etcd: <etcd>]
multi:
# Primary backend storage used by multi-client.
# CLI flag: -multi.primary
[primary: <string> | default = ""]
# Secondary backend storage used by multi-client.
# CLI flag: -multi.secondary
[secondary: <string> | default = ""]
# Mirror writes to secondary store.
# CLI flag: -multi.mirror-enabled
[mirror_enabled: <boolean> | default = false]
# Timeout for storing value to secondary store.
# CLI flag: -multi.mirror-timeout
[mirror_timeout: <duration> | default = 2s]
# The heartbeat timeout after which ingesters are skipped for reads/writes.
# 0 = never (timeout disabled).
# CLI flag: -ring.heartbeat-timeout
[heartbeat_timeout: <duration> | default = 1m]
# 要写入和读取的拉取器数量
# The number of ingesters to write to and read from.
# CLI flag: -distributor.replication-factor
[replication_factor: <int> | default = 3]
# true 开启区域感知,并在不同的可用区域中复制拉取器样本
# True to enable the zone-awareness and replicate ingested samples across
# different availability zones.
# CLI flag: -distributor.zone-awareness-enabled
[zone_awareness_enabled: <boolean> | default = false]
# 要排除的区别列表,逗号分隔
# Comma-separated list of zones to exclude from the ring. Instances in
# excluded zones will be filtered out from the ring.
# CLI flag: -distributor.excluded-zones
[excluded_zones: <string> | default = ""]
每个拉取器的token数量
# Number of tokens for each ingester.
# CLI flag: -ingester.num-tokens
[num_tokens: <int> | default = 128]
# Period at which to heartbeat to consul. 0 = disabled.
# CLI flag: -ingester.heartbeat-period
[heartbeat_period: <duration> | default = 5s]
# Heartbeat timeout after which instance is assumed to be unhealthy. 0 =
# disabled.
# CLI flag: -ingester.heartbeat-timeout
[heartbeat_timeout: <duration> | default = 1m]
# 在生成后观察令牌以解决冲突。在使用 gossiping ring 时很有用
# Observe tokens after generating to resolve collisions. Useful when using
# gossiping ring.
# CLI flag: -ingester.observe-period
[observe_period: <duration> | default = 0s]
# Period to wait for a claim from another member; will join automatically
# after this.
# CLI flag: -ingester.join-after
[join_after: <duration> | default = 0s]
# 内部就绪检查通过但尚未成功通过就绪端点后的最小等待时间
# 在实例就绪后和进行滚动更新之前,用于减慢部署控制器(例如 Kubernetes)
# 以便给其余集群实例足够的时间来接收环更新
# Minimum duration to wait after the internal readiness checks have passed but
# before succeeding the readiness endpoint. This is used to slowdown
# deployment controllers (eg. Kubernetes) after an instance is ready and
# before they proceed with a rolling update, to give the rest of the cluster
# instances enough time to receive ring updates.
# CLI flag: -ingester.min-ready-duration
[min_ready_duration: <duration> | default = 15s]
# Name of network interface to read address from.
# CLI flag: -ingester.lifecycler.interface
[interface_names: <list of strings> | default = [<private network interfaces>]]
# Enable IPv6 support. Required to make use of IP addresses from IPv6
# interfaces.
# CLI flag: -ingester.enable-inet6
[enable_inet6: <boolean> | default = false]
# 退出前的休眠持续时间,确保指标删除
# Duration to sleep for before exiting, to ensure metrics are scraped.
# CLI flag: -ingester.final-sleep
[final_sleep: <duration> | default = 0s]
# File path where tokens are stored. If empty, tokens are not stored at
# shutdown and restored at startup.
# CLI flag: -ingester.tokens-file-path
[tokens_file_path: <string> | default = ""]
# The availability zone where this instance is running.
# CLI flag: -ingester.availability-zone
[availability_zone: <string> | default = ""]
# 完全关闭后从环中注销。
# 在与 -distributor.extend-writes=false 一起使用时,禁用它可以实现一致性命名的滚动重启
# Unregister from the ring upon clean shutdown. It can be useful to disable
# for rolling restarts with consistent naming in conjunction with
# -distributor.extend-writes=false.
# CLI flag: -ingester.unregister-on-shutdown
[unregister_on_shutdown: <boolean> | default = true]
# When enabled the readiness probe succeeds only after all instances are
# ACTIVE and healthy in the ring, otherwise only the instance itself is
# checked. This option should be disabled if in your cluster multiple
# instances can be rolled out simultaneously, otherwise rolling updates may be
# slowed down.
# CLI flag: -ingester.readiness-check-ring-health
[readiness_check_ring_health: <boolean> | default = true]
# 在环中广播的IP地址
# IP address to advertise in the ring.
# CLI flag: -ingester.lifecycler.addr
[address: <string> | default = ""]
# port to advertise in consul (defaults to server.grpc-listen-port).
# CLI flag: -ingester.lifecycler.port
[port: <int> | default = 0]
# ID to register in the ring.
# CLI flag: -ingester.lifecycler.ID
[id: <string> | default = "<hostname>"]
# 在回退到刷新之前尝试传输块的次数,设置0或者小于0,表示禁用
# Number of times to try and transfer chunks before falling back to flushing. If
# set to 0 or negative value, transfers are disabled.
# CLI flag: -ingester.max-transfer-retries
[max_transfer_retries: <int> | default = 0]
# 每个流可以同时进行多少次刷新
# How many flushes can happen concurrently from each stream.
# CLI flag: -ingester.concurrent-flushes
[concurrent_flushes: <int> | default = 32]
# 拉取器多久检查一次是否有块要刷新。
# 第一次刷新检查被延迟检查周期的0.8倍,上下浮动1%
# How often should the ingester see if there are any blocks to flush. The first
# flush check is delayed by a random time up to 0.8x the flush check period.
# Additionally, there is +/- 1% jitter added to the interval.
# CLI flag: -ingester.flush-check-period
[flush_check_period: <duration> | default = 30s]
# 取消刷新的超时时间
# The timeout before a flush is cancelled.
# CLI flag: -ingester.flush-op-timeout
[flush_op_timeout: <duration> | default = 10m]
# 块刷新后再内存中保留的时间
# How long chunks should be retained in-memory after they've been flushed.
# CLI flag: -ingester.chunks-retain-period
[chunk_retain_period: <duration> | default = 0s]
#如果块没有达到最大块大小,在刷新之前,块应该在内存中保留多长时间而没有更新
#这意味着,只要没有收到进一步的活动,半空的块在一定时间后仍将被刷新
# How long chunks should sit in-memory with no updates before being flushed if
# they don't hit the max block size. This means that half-empty chunks will
# still be flushed after a certain period as long as they receive no further
# activity.
# CLI flag: -ingester.chunks-idle-period
[chunk_idle_period: <duration> | default = 30m]
# 当超过该阈值时,头部的块将被切割和压缩
# The targeted _uncompressed_ size in bytes of a chunk block When this threshold
# is exceeded the head block will be cut and compressed inside the chunk.
# CLI flag: -ingester.chunks-block-size
[chunk_block_size: <int> | default = 262144]
#这是一个期望的大小,而不是确切的大小,如果由于其他原因(例如 chunk_idle_period)而刷新块,
# 则块可能稍微大一些或小一些。
# 值为 0 会创建具有固定 10 个块的块,非零值会创建具有可变数量块以满足目标大小的块
# A target _compressed_ size in bytes for chunks. This is a desired size not an
# exact size, chunks may be slightly bigger or significantly smaller if they get
# flushed for other reasons (e.g. chunk_idle_period). A value of 0 creates
# chunks with a fixed 10 blocks, a non zero value will create chunks with a
# variable number of blocks to meet the target size.
# CLI flag: -ingester.chunk-target-size
[chunk_target_size: <int> | default = 1572864]
# 压缩块算法(none, gzip, lz4-64k, snappy,lz4-256k, lz4-1M, lz4, flate, zstd)
# The algorithm to use for compressing chunk. (none, gzip, lz4-64k, snappy,
# lz4-256k, lz4-1M, lz4, flate, zstd)
# CLI flag: -ingester.chunk-encoding
[chunk_encoding: <string> | default = "gzip"]
# The maximum duration of a timeseries chunk in memory. If a timeseries runs for
# longer than this, the current chunk will be flushed to the store and a new
# chunk created.
# CLI flag: -ingester.max-chunk-age
[max_chunk_age: <duration> | default = 2h]
# Forget about ingesters having heartbeat timestamps older than
# `ring.kvstore.heartbeat_timeout`. This is equivalent to clicking on the
# `/ring` `forget` button in the UI: the ingester is removed from the ring. This
# is a useful setting when you are sure that an unhealthy node won't return. An
# example is when not using stateful sets or the equivalent. Use
# `memberlist.rejoin_interval` > 0 to handle network partition cases when using
# a memberlist.
# CLI flag: -ingester.autoforget-unhealthy
[autoforget_unhealthy: <boolean> | default = false]
# Parameters used to synchronize ingesters to cut chunks at the same moment.
# Sync period is used to roll over incoming entry to a new chunk. If chunk's
# utilization isn't high enough (eg. less than 50% when sync_min_utilization is
# set to 0.5), then this chunk rollover doesn't happen.
# CLI flag: -ingester.sync-period
[sync_period: <duration> | default = 0s]
# Minimum utilization of chunk when doing synchronization.
# CLI flag: -ingester.sync-min-utilization
[sync_min_utilization: <float> | default = 0]
# The maximum number of errors a stream will report to the user when a push
# fails. 0 to make unlimited.
# CLI flag: -ingester.max-ignored-stream-errors
[max_returned_stream_errors: <int> | default = 10]
# How far back should an ingester be allowed to query the store for data, for
# use only with boltdb-shipper/tsdb index and filesystem object store. -1 for
# infinite.
# CLI flag: -ingester.query-store-max-look-back-period
[query_store_max_look_back_period: <duration> | default = 0s]
# The ingester WAL (Write Ahead Log) records incoming logs and stores them on
# the local file systems in order to guarantee persistence of acknowledged data
# in the event of a process crash.
wal:
# Enable writing of ingested data into WAL.
# CLI flag: -ingester.wal-enabled
[enabled: <boolean> | default = true]
# Directory where the WAL data is stored and/or recovered from.
# CLI flag: -ingester.wal-dir
[dir: <string> | default = "wal"]
# Interval at which checkpoints should be created.
# CLI flag: -ingester.checkpoint-duration
[checkpoint_duration: <duration> | default = 5m]
# When WAL is enabled, should chunks be flushed to long-term storage on
# shutdown.
# CLI flag: -ingester.flush-on-shutdown
[flush_on_shutdown: <boolean> | default = false]
# Maximum memory size the WAL may use during replay. After hitting this, it
# will flush data to storage before continuing. A unit suffix (KB, MB, GB) may
# be applied.
# CLI flag: -ingester.wal-replay-memory-ceiling
[replay_memory_ceiling: <int> | default = 4GB]
# Shard factor used in the ingesters for the in process reverse index. This MUST
# be evenly divisible by ALL schema shard factors or Loki will not start.
# CLI flag: -ingester.index-shards
[index_shards: <int> | default = 32]
# Maximum number of dropped streams to keep in memory during tailing.
# CLI flag: -ingester.tailer.max-dropped-streams
[max_dropped_streams: <int> | default = 10]
# Path where the shutdown marker file is stored. If not set and
# common.path_prefix is set then common.path_prefix will be used.
# CLI flag: -ingester.shutdown-marker-path
[shutdown_marker_path: <string> | default = ""]
index_gateway
# Defines in which mode the index gateway server will operate (default to
# 'simple'). It supports two modes:
# - 'simple': an index gateway server instance is responsible for handling,
# storing and returning requests for all indices for all tenants.
# - 'ring': an index gateway server instance is responsible for a subset of
# tenants instead of all tenants.
# CLI flag: -index-gateway.mode
[mode: <string> | default = "simple"]
# Defines the ring to be used by the index gateway servers and clients in case
# the servers are configured to run in 'ring' mode. In case this isn't
# configured, this block supports inheriting configuration from the common ring
# section.
ring:
kvstore:
# Backend storage to use for the ring. Supported values are: consul, etcd,
# inmemory, memberlist, multi.
# CLI flag: -index-gateway.ring.store
[store: <string> | default = "consul"]
# The prefix for the keys in the store. Should end with a /.
# CLI flag: -index-gateway.ring.prefix
[prefix: <string> | default = "collectors/"]
# Configuration for a Consul client. Only applies if the selected kvstore is
# consul.
# The CLI flags prefix for this block configuration is: index-gateway.ring
[consul: <consul>]
# Configuration for an ETCD v3 client. Only applies if the selected kvstore
# is etcd.
# The CLI flags prefix for this block configuration is: index-gateway.ring
[etcd: <etcd>]
multi:
# Primary backend storage used by multi-client.
# CLI flag: -index-gateway.ring.multi.primary
[primary: <string> | default = ""]
# Secondary backend storage used by multi-client.
# CLI flag: -index-gateway.ring.multi.secondary
[secondary: <string> | default = ""]
# Mirror writes to secondary store.
# CLI flag: -index-gateway.ring.multi.mirror-enabled
[mirror_enabled: <boolean> | default = false]
# Timeout for storing value to secondary store.
# CLI flag: -index-gateway.ring.multi.mirror-timeout
[mirror_timeout: <duration> | default = 2s]
# Period at which to heartbeat to the ring. 0 = disabled.
# CLI flag: -index-gateway.ring.heartbeat-period
[heartbeat_period: <duration> | default = 15s]
# The heartbeat timeout after which compactors are considered unhealthy within
# the ring. 0 = never (timeout disabled).
# CLI flag: -index-gateway.ring.heartbeat-timeout
[heartbeat_timeout: <duration> | default = 1m]
# File path where tokens are stored. If empty, tokens are not stored at
# shutdown and restored at startup.
# CLI flag: -index-gateway.ring.tokens-file-path
[tokens_file_path: <string> | default = ""]
# True to enable zone-awareness and replicate blocks across different
# availability zones.
# CLI flag: -index-gateway.ring.zone-awareness-enabled
[zone_awareness_enabled: <boolean> | default = false]
# Instance ID to register in the ring.
# CLI flag: -index-gateway.ring.instance-id
[instance_id: <string> | default = "<hostname>"]
# Name of network interface to read address from.
# CLI flag: -index-gateway.ring.instance-interface-names
[instance_interface_names: <list of strings> | default = [<private network interfaces>]]
# Port to advertise in the ring (defaults to server.grpc-listen-port).
# CLI flag: -index-gateway.ring.instance-port
[instance_port: <int> | default = 0]
# IP address to advertise in the ring.
# CLI flag: -index-gateway.ring.instance-addr
[instance_addr: <string> | default = ""]
# The availability zone where this instance is running. Required if
# zone-awareness is enabled.
# CLI flag: -index-gateway.ring.instance-availability-zone
[instance_availability_zone: <string> | default = ""]
# Enable using a IPv6 instance address.
# CLI flag: -index-gateway.ring.instance-enable-ipv6
[instance_enable_ipv6: <boolean> | default = false]
# Deprecated: How many index gateway instances are assigned to each tenant.
# Use -index-gateway.shard-size instead. The shard size is also a per-tenant
# setting.
# CLI flag: -replication-factor
[replication_factor: <int> | default = 3]
storage_config
# The alibabacloud_storage_config block configures the connection to Alibaba
# Cloud Storage object storage backend.
# The CLI flags prefix for this block configuration is: common
[alibabacloud: <alibabacloud_storage_config>]
# The aws_storage_config block configures the connection to dynamoDB and S3
# object storage. Either one of them or both can be configured.
[aws: <aws_storage_config>]
# The azure_storage_config block configures the connection to Azure object
# storage backend.
[azure: <azure_storage_config>]
# The bos_storage_config block configures the connection to Baidu Object Storage
# (BOS) object storage backend.
[bos: <bos_storage_config>]
# Deprecated: Configures storing indexes in Bigtable. Required fields only
# required when bigtable is defined in config.
bigtable:
# Bigtable project ID.
# CLI flag: -bigtable.project
[project: <string> | default = ""]
# Bigtable instance ID. Please refer to
# https://cloud.google.com/docs/authentication/production for more information
# about how to configure authentication.
# CLI flag: -bigtable.instance
[instance: <string> | default = ""]
# The grpc_client block configures the gRPC client used to communicate between
# two Loki components.
# The CLI flags prefix for this block configuration is: bigtable
[grpc_client_config: <grpc_client>]
# If enabled, once a tables info is fetched, it is cached.
# CLI flag: -bigtable.table-cache.enabled
[table_cache_enabled: <boolean> | default = true]
# Duration to cache tables before checking again.
# CLI flag: -bigtable.table-cache.expiration
[table_cache_expiration: <duration> | default = 30m]
# Configures storing chunks in GCS. Required fields only required when gcs is
# defined in config.
[gcs: <gcs_storage_config>]
# Deprecated: Configures storing chunks and/or the index in Cassandra.
cassandra:
# Comma-separated hostnames or IPs of Cassandra instances.
# CLI flag: -cassandra.addresses
[addresses: <string> | default = ""]
# Port that Cassandra is running on
# CLI flag: -cassandra.port
[port: <int> | default = 9042]
# Keyspace to use in Cassandra.
# CLI flag: -cassandra.keyspace
[keyspace: <string> | default = ""]
# Consistency level for Cassandra.
# CLI flag: -cassandra.consistency
[consistency: <string> | default = "QUORUM"]
# Replication factor to use in Cassandra.
# CLI flag: -cassandra.replication-factor
[replication_factor: <int> | default = 3]
# Instruct the cassandra driver to not attempt to get host info from the
# system.peers table.
# CLI flag: -cassandra.disable-initial-host-lookup
[disable_initial_host_lookup: <boolean> | default = false]
# Use SSL when connecting to cassandra instances.
# CLI flag: -cassandra.ssl
[SSL: <boolean> | default = false]
# Require SSL certificate validation.
# CLI flag: -cassandra.host-verification
[host_verification: <boolean> | default = true]
# Policy for selecting Cassandra host. Supported values are: round-robin,
# token-aware.
# CLI flag: -cassandra.host-selection-policy
[host_selection_policy: <string> | default = "round-robin"]
# Path to certificate file to verify the peer.
# CLI flag: -cassandra.ca-path
[CA_path: <string> | default = ""]
# Path to certificate file used by TLS.
# CLI flag: -cassandra.tls-cert-path
[tls_cert_path: <string> | default = ""]
# Path to private key file used by TLS.
# CLI flag: -cassandra.tls-key-path
[tls_key_path: <string> | default = ""]
# Enable password authentication when connecting to cassandra.
# CLI flag: -cassandra.auth
[auth: <boolean> | default = false]
# Username to use when connecting to cassandra.
# CLI flag: -cassandra.username
[username: <string> | default = ""]
# Password to use when connecting to cassandra.
# CLI flag: -cassandra.password
[password: <string> | default = ""]
# File containing password to use when connecting to cassandra.
# CLI flag: -cassandra.password-file
[password_file: <string> | default = ""]
# If set, when authenticating with cassandra a custom authenticator will be
# expected during the handshake. This flag can be set multiple times.
# CLI flag: -cassandra.custom-authenticator
[custom_authenticators: <list of strings> | default = []]
# Timeout when connecting to cassandra.
# CLI flag: -cassandra.timeout
[timeout: <duration> | default = 2s]
# Initial connection timeout, used during initial dial to server.
# CLI flag: -cassandra.connect-timeout
[connect_timeout: <duration> | default = 5s]
# Interval to retry connecting to cassandra nodes marked as DOWN.
# CLI flag: -cassandra.reconnent-interval
[reconnect_interval: <duration> | default = 1s]
# Number of retries to perform on a request. Set to 0 to disable retries.
# CLI flag: -cassandra.max-retries
[max_retries: <int> | default = 0]
# Maximum time to wait before retrying a failed request.
# CLI flag: -cassandra.retry-max-backoff
[retry_max_backoff: <duration> | default = 10s]
# Minimum time to wait before retrying a failed request.
# CLI flag: -cassandra.retry-min-backoff
[retry_min_backoff: <duration> | default = 100ms]
# Limit number of concurrent queries to Cassandra. Set to 0 to disable the
# limit.
# CLI flag: -cassandra.query-concurrency
[query_concurrency: <int> | default = 0]
# Number of TCP connections per host.
# CLI flag: -cassandra.num-connections
[num_connections: <int> | default = 2]
# Convict hosts of being down on failure.
# CLI flag: -cassandra.convict-hosts-on-failure
[convict_hosts_on_failure: <boolean> | default = true]
# Table options used to create index or chunk tables. This value is used as
# plain text in the table `WITH` like this, "CREATE TABLE
# <generated_by_cortex> (...) WITH <cassandra.table-options>". For details,
# see https://cortexmetrics.io/docs/production/cassandra. By default it will
# use the default table options of your Cassandra cluster.
# CLI flag: -cassandra.table-options
[table_options: <string> | default = ""]
# Deprecated: Configures storing index in BoltDB. Required fields only required
# when boltdb is present in the configuration.
boltdb:
# Location of BoltDB index files.
# CLI flag: -boltdb.dir
[directory: <string> | default = ""]
# Configures storing the chunks on the local file system. Required fields only
# required when filesystem is present in the configuration.
[filesystem: <local_storage_config>]
# The swift_storage_config block configures the connection to OpenStack Object
# Storage (Swift) object storage backend.
[swift: <swift_storage_config>]
# Deprecated:
grpc_store:
# Hostname or IP of the gRPC store instance.
# CLI flag: -grpc-store.server-address
[server_address: <string> | default = ""]
hedging:
# If set to a non-zero value a second request will be issued at the provided
# duration. Default is 0 (disabled)
# CLI flag: -store.hedge-requests-at
[at: <duration> | default = 0s]
# The maximum of hedge requests allowed.
# CLI flag: -store.hedge-requests-up-to
[up_to: <int> | default = 2]
# The maximum of hedge requests allowed per seconds.
# CLI flag: -store.hedge-max-per-second
[max_per_second: <int> | default = 5]
# Configures additional object stores for a given storage provider.
# Supported stores: aws, azure, bos, filesystem, gcs, swift.
# Example:
# storage_config:
# named_stores:
# aws:
# store-1:
# endpoint: s3://foo-bucket
# region: us-west1
# Named store from this example can be used by setting object_store to store-1
# in period_config.
[named_stores: <named_stores_config>]
# The cos_storage_config block configures the connection to IBM Cloud Object
# Storage (COS) backend.
[cos: <cos_storage_config>]
# Cache validity for active index entries. Should be no higher than
# -ingester.max-chunk-idle.
# CLI flag: -store.index-cache-validity
[index_cache_validity: <duration> | default = 5m]
# The cache block configures the cache backend.
# The CLI flags prefix for this block configuration is: store.index-cache-read
[index_queries_cache_config: <cache_config>]
# Disable broad index queries which results in reduced cache usage and faster
# query performance at the expense of somewhat higher QPS on the index store.
# CLI flag: -store.disable-broad-index-queries
[disable_broad_index_queries: <boolean> | default = false]
# Maximum number of parallel chunk reads.
# CLI flag: -store.max-parallel-get-chunk
[max_parallel_get_chunk: <int> | default = 150]
# The maximum number of chunks to fetch per batch.
# CLI flag: -store.max-chunk-batch-size
[max_chunk_batch_size: <int> | default = 50]
# Configures storing index in an Object Store
# (GCS/S3/Azure/Swift/COS/Filesystem) in the form of boltdb files. Required
# fields only required when boltdb-shipper is defined in config.
boltdb_shipper:
# Directory where ingesters would write index files which would then be
# uploaded by shipper to configured storage
# CLI flag: -boltdb.shipper.active-index-directory
[active_index_directory: <string> | default = ""]
# Shared store for keeping index files. Supported types: gcs, s3, azure, cos,
# filesystem
# CLI flag: -boltdb.shipper.shared-store
[shared_store: <string> | default = ""]
# Prefix to add to Object Keys in Shared store. Path separator(if any) should
# always be a '/'. Prefix should never start with a separator but should
# always end with it
# CLI flag: -boltdb.shipper.shared-store.key-prefix
[shared_store_key_prefix: <string> | default = "index/"]
# Cache location for restoring index files from storage for queries
# CLI flag: -boltdb.shipper.cache-location
[cache_location: <string> | default = ""]
# TTL for index files restored in cache for queries
# CLI flag: -boltdb.shipper.cache-ttl
[cache_ttl: <duration> | default = 24h]
# Resync downloaded files with the storage
# CLI flag: -boltdb.shipper.resync-interval
[resync_interval: <duration> | default = 5m]
# Number of days of common index to be kept downloaded for queries. For per
# tenant index query readiness, use limits overrides config.
# CLI flag: -boltdb.shipper.query-ready-num-days
[query_ready_num_days: <int> | default = 0]
index_gateway_client:
# The grpc_client block configures the gRPC client used to communicate
# between two Loki components.
# The CLI flags prefix for this block configuration is:
# boltdb.shipper.index-gateway-client.grpc
[grpc_client_config: <grpc_client>]
# Hostname or IP of the Index Gateway gRPC server running in simple mode.
# CLI flag: -boltdb.shipper.index-gateway-client.server-address
[server_address: <string> | default = ""]
# Whether requests sent to the gateway should be logged or not.
# CLI flag: -boltdb.shipper.index-gateway-client.log-gateway-requests
[log_gateway_requests: <boolean> | default = false]
# Use boltdb-shipper index store as backup for indexing chunks. When enabled,
# boltdb-shipper needs to be configured under storage_config
# CLI flag: -boltdb.shipper.use-boltdb-shipper-as-backup
[use_boltdb_shipper_as_backup: <boolean> | default = false]
[ingestername: <string> | default = ""]
[mode: <string> | default = ""]
[ingesterdbretainperiod: <duration>]
# Build per tenant index files
# CLI flag: -boltdb.shipper.build-per-tenant-index
[build_per_tenant_index: <boolean> | default = false]
# Configures storing index in an Object Store
# (GCS/S3/Azure/Swift/COS/Filesystem) in a prometheus TSDB-like format. Required
# fields only required when TSDB is defined in config.
tsdb_shipper:
# Directory where ingesters would write index files which would then be
# uploaded by shipper to configured storage
# CLI flag: -tsdb.shipper.active-index-directory
[active_index_directory: <string> | default = ""]
# Shared store for keeping index files. Supported types: gcs, s3, azure, cos,
# filesystem
# CLI flag: -tsdb.shipper.shared-store
[shared_store: <string> | default = ""]
# Prefix to add to Object Keys in Shared store. Path separator(if any) should
# always be a '/'. Prefix should never start with a separator but should
# always end with it
# CLI flag: -tsdb.shipper.shared-store.key-prefix
[shared_store_key_prefix: <string> | default = "index/"]
# Cache location for restoring index files from storage for queries
# CLI flag: -tsdb.shipper.cache-location
[cache_location: <string> | default = ""]
# TTL for index files restored in cache for queries
# CLI flag: -tsdb.shipper.cache-ttl
[cache_ttl: <duration> | default = 24h]
# Resync downloaded files with the storage
# CLI flag: -tsdb.shipper.resync-interval
[resync_interval: <duration> | default = 5m]
# Number of days of common index to be kept downloaded for queries. For per
# tenant index query readiness, use limits overrides config.
# CLI flag: -tsdb.shipper.query-ready-num-days
[query_ready_num_days: <int> | default = 0]
index_gateway_client:
# The grpc_client block configures the gRPC client used to communicate
# between two Loki components.
# The CLI flags prefix for this block configuration is:
# tsdb.shipper.index-gateway-client.grpc
[grpc_client_config: <grpc_client>]
# Hostname or IP of the Index Gateway gRPC server running in simple mode.
# CLI flag: -tsdb.shipper.index-gateway-client.server-address
[server_address: <string> | default = ""]
# Whether requests sent to the gateway should be logged or not.
# CLI flag: -tsdb.shipper.index-gateway-client.log-gateway-requests
[log_gateway_requests: <boolean> | default = false]
# Use boltdb-shipper index store as backup for indexing chunks. When enabled,
# boltdb-shipper needs to be configured under storage_config
# CLI flag: -tsdb.shipper.use-boltdb-shipper-as-backup
[use_boltdb_shipper_as_backup: <boolean> | default = false]
[ingestername: <string> | default = ""]
[mode: <string> | default = ""]
[ingesterdbretainperiod: <duration>]
# Experimental. Whether TSDB should cache postings or not. The
# index-read-cache will be used as the backend.
# CLI flag: -tsdb.enable-postings-cache
[enable_postings_cache: <boolean> | default = false]
chunk_store_config
# The cache block configures the cache backend.
# The CLI flags prefix for this block configuration is: store.chunks-cache
[chunk_cache_config: <cache_config>]
# The cache block configures the cache backend.
# The CLI flags prefix for this block configuration is: store.index-cache-write
[write_dedupe_cache_config: <cache_config>]
# Cache index entries older than this period. 0 to disable.
# CLI flag: -store.cache-lookups-older-than
[cache_lookups_older_than: <duration> | default = 0s]
# This flag is deprecated. Use -querier.max-query-lookback instead.
# CLI flag: -store.max-look-back-period
[max_look_back_period: <duration> | default = 0s]
schema_config
[configs: <list of period_configs>]
compactor
# Directory where files can be downloaded for compaction.
# CLI flag: -compactor.working-directory
[working_directory: <string> | default = ""]
# The shared store used for storing boltdb files. Supported types: gcs, s3,
# azure, swift, filesystem, bos, cos. If not set, compactor will be initialized
# to operate on all the object stores that contain either boltdb-shipper or tsdb
# index.
# CLI flag: -compactor.shared-store
[shared_store: <string> | default = ""]
# Prefix to add to object keys in shared store. Path separator(if any) should
# always be a '/'. Prefix should never start with a separator but should always
# end with it.
# CLI flag: -compactor.shared-store.key-prefix
[shared_store_key_prefix: <string> | default = "index/"]
# Interval at which to re-run the compaction operation.
# CLI flag: -compactor.compaction-interval
[compaction_interval: <duration> | default = 10m]
# Interval at which to apply/enforce retention. 0 means run at same interval as
# compaction. If non-zero, it should always be a multiple of compaction
# interval.
# CLI flag: -compactor.apply-retention-interval
[apply_retention_interval: <duration> | default = 0s]
# (Experimental) Activate custom (per-stream,per-tenant) retention.
# CLI flag: -compactor.retention-enabled
[retention_enabled: <boolean> | default = false]
# Delay after which chunks will be fully deleted during retention.
# CLI flag: -compactor.retention-delete-delay
[retention_delete_delay: <duration> | default = 2h]
# The total amount of worker to use to delete chunks.
# CLI flag: -compactor.retention-delete-worker-count
[retention_delete_worker_count: <int> | default = 150]
# The maximum amount of time to spend running retention and deletion on any
# given table in the index.
# CLI flag: -compactor.retention-table-timeout
[retention_table_timeout: <duration> | default = 0s]
# Store used for managing delete requests. Defaults to -compactor.shared-store.
# CLI flag: -compactor.delete-request-store
[delete_request_store: <string> | default = ""]
# The max number of delete requests to run per compaction cycle.
# CLI flag: -compactor.delete-batch-size
[delete_batch_size: <int> | default = 70]
# Allow cancellation of delete request until duration after they are created.
# Data would be deleted only after delete requests have been older than this
# duration. Ideally this should be set to at least 24h.
# CLI flag: -compactor.delete-request-cancel-period
[delete_request_cancel_period: <duration> | default = 24h]
# Constrain the size of any single delete request. When a delete request >
# delete_max_interval is input, the request is sharded into smaller requests of
# no more than delete_max_interval
# CLI flag: -compactor.delete-max-interval
[delete_max_interval: <duration> | default = 0s]
# Maximum number of tables to compact in parallel. While increasing this value,
# please make sure compactor has enough disk space allocated to be able to store
# and compact as many tables.
# CLI flag: -compactor.max-compaction-parallelism
[max_compaction_parallelism: <int> | default = 1]
# Number of upload/remove operations to execute in parallel when finalizing a
# compaction. NOTE: This setting is per compaction operation, which can be
# executed in parallel. The upper bound on the number of concurrent uploads is
# upload_parallelism * max_compaction_parallelism.
# CLI flag: -compactor.upload-parallelism
[upload_parallelism: <int> | default = 10]
# The hash ring configuration used by compactors to elect a single instance for
# running compactions. The CLI flags prefix for this block config is:
# compactor.ring
compactor_ring:
kvstore:
# Backend storage to use for the ring. Supported values are: consul, etcd,
# inmemory, memberlist, multi.
# CLI flag: -compactor.ring.store
[store: <string> | default = "consul"]
# The prefix for the keys in the store. Should end with a /.
# CLI flag: -compactor.ring.prefix
[prefix: <string> | default = "collectors/"]
# Configuration for a Consul client. Only applies if the selected kvstore is
# consul.
# The CLI flags prefix for this block configuration is: compactor.ring
[consul: <consul>]
# Configuration for an ETCD v3 client. Only applies if the selected kvstore
# is etcd.
# The CLI flags prefix for this block configuration is: compactor.ring
[etcd: <etcd>]
multi:
# Primary backend storage used by multi-client.
# CLI flag: -compactor.ring.multi.primary
[primary: <string> | default = ""]
# Secondary backend storage used by multi-client.
# CLI flag: -compactor.ring.multi.secondary
[secondary: <string> | default = ""]
# Mirror writes to secondary store.
# CLI flag: -compactor.ring.multi.mirror-enabled
[mirror_enabled: <boolean> | default = false]
# Timeout for storing value to secondary store.
# CLI flag: -compactor.ring.multi.mirror-timeout
[mirror_timeout: <duration> | default = 2s]
# Period at which to heartbeat to the ring. 0 = disabled.
# CLI flag: -compactor.ring.heartbeat-period
[heartbeat_period: <duration> | default = 15s]
# The heartbeat timeout after which compactors are considered unhealthy within
# the ring. 0 = never (timeout disabled).
# CLI flag: -compactor.ring.heartbeat-timeout
[heartbeat_timeout: <duration> | default = 1m]
# File path where tokens are stored. If empty, tokens are not stored at
# shutdown and restored at startup.
# CLI flag: -compactor.ring.tokens-file-path
[tokens_file_path: <string> | default = ""]
# True to enable zone-awareness and replicate blocks across different
# availability zones.
# CLI flag: -compactor.ring.zone-awareness-enabled
[zone_awareness_enabled: <boolean> | default = false]
# Instance ID to register in the ring.
# CLI flag: -compactor.ring.instance-id
[instance_id: <string> | default = "<hostname>"]
# Name of network interface to read address from.
# CLI flag: -compactor.ring.instance-interface-names
[instance_interface_names: <list of strings> | default = [<private network interfaces>]]
# Port to advertise in the ring (defaults to server.grpc-listen-port).
# CLI flag: -compactor.ring.instance-port
[instance_port: <int> | default = 0]
# IP address to advertise in the ring.
# CLI flag: -compactor.ring.instance-addr
[instance_addr: <string> | default = ""]
# The availability zone where this instance is running. Required if
# zone-awareness is enabled.
# CLI flag: -compactor.ring.instance-availability-zone
[instance_availability_zone: <string> | default = ""]
# Enable using a IPv6 instance address.
# CLI flag: -compactor.ring.instance-enable-ipv6
[instance_enable_ipv6: <boolean> | default = false]
# Number of tables that compactor will try to compact. Newer tables are chosen
# when this is less than the number of tables available.
# CLI flag: -compactor.tables-to-compact
[tables_to_compact: <int> | default = 0]
# Do not compact N latest tables. Together with -compactor.run-once and
# -compactor.tables-to-compact, this is useful when clearing compactor backlogs.
# CLI flag: -compactor.skip-latest-n-tables
[skip_latest_n_tables: <int> | default = 0]
# Deprecated: Use deletion_mode per tenant configuration instead.
[deletion_mode: <string> | default = ""]
limits_config
# Whether the ingestion rate limit should be applied individually to each
# distributor instance (local), or evenly shared across the cluster (global).
# The ingestion rate strategy cannot be overridden on a per-tenant basis.
# - local: enforces the limit on a per distributor basis. The actual effective
# rate limit will be N times higher, where N is the number of distributor
# replicas.
# - global: enforces the limit globally, configuring a per-distributor local
# rate limiter as 'ingestion_rate / N', where N is the number of distributor
# replicas (it's automatically adjusted if the number of replicas change). The
# global strategy requires the distributors to form their own ring, which is
# used to keep track of the current number of healthy distributor replicas.
# CLI flag: -distributor.ingestion-rate-limit-strategy
[ingestion_rate_strategy: <string> | default = "global"]
# Per-user ingestion rate limit in sample size per second. Units in MB.
# CLI flag: -distributor.ingestion-rate-limit-mb
[ingestion_rate_mb: <float> | default = 4]
# Per-user allowed ingestion burst size (in sample size). Units in MB. The burst
# size refers to the per-distributor local rate limiter even in the case of the
# 'global' strategy, and should be set at least to the maximum logs size
# expected in a single push request.
# CLI flag: -distributor.ingestion-burst-size-mb
[ingestion_burst_size_mb: <float> | default = 6]
# Maximum length accepted for label names.
# CLI flag: -validation.max-length-label-name
[max_label_name_length: <int> | default = 1024]
# Maximum length accepted for label value. This setting also applies to the
# metric name.
# CLI flag: -validation.max-length-label-value
[max_label_value_length: <int> | default = 2048]
# Maximum number of label names per series.
# CLI flag: -validation.max-label-names-per-series
[max_label_names_per_series: <int> | default = 30]
# Whether or not old samples will be rejected.
# CLI flag: -validation.reject-old-samples
[reject_old_samples: <boolean> | default = true]
# Maximum accepted sample age before rejecting.
# CLI flag: -validation.reject-old-samples.max-age
[reject_old_samples_max_age: <duration> | default = 1w]
# Duration which table will be created/deleted before/after it's needed; we
# won't accept sample from before this time.
# CLI flag: -validation.create-grace-period
[creation_grace_period: <duration> | default = 10m]
# Enforce every sample has a metric name.
# CLI flag: -validation.enforce-metric-name
[enforce_metric_name: <boolean> | default = true]
# Maximum line size on ingestion path. Example: 256kb. Any log line exceeding
# this limit will be discarded unless `distributor.max-line-size-truncate` is
# set which in case it is truncated instead of discarding it completely. There
# is no limit when unset or set to 0.
# CLI flag: -distributor.max-line-size
[max_line_size: <int> | default = 0B]
# Whether to truncate lines that exceed max_line_size.
# CLI flag: -distributor.max-line-size-truncate
[max_line_size_truncate: <boolean> | default = false]
# Alter the log line timestamp during ingestion when the timestamp is the same
# as the previous entry for the same stream. When enabled, if a log line in a
# push request has the same timestamp as the previous line for the same stream,
# one nanosecond is added to the log line. This will preserve the received order
# of log lines with the exact same timestamp when they are queried, by slightly
# altering their stored timestamp. NOTE: This is imperfect, because Loki accepts
# out of order writes, and another push request for the same stream could
# contain duplicate timestamps to existing entries and they will not be
# incremented.
# CLI flag: -validation.increment-duplicate-timestamps
[increment_duplicate_timestamp: <boolean> | default = false]
# Maximum number of active streams per user, per ingester. 0 to disable.
# CLI flag: -ingester.max-streams-per-user
[max_streams_per_user: <int> | default = 0]
# Maximum number of active streams per user, across the cluster. 0 to disable.
# When the global limit is enabled, each ingester is configured with a dynamic
# local limit based on the replication factor and the current number of healthy
# ingesters, and is kept updated whenever the number of ingesters change.
# CLI flag: -ingester.max-global-streams-per-user
[max_global_streams_per_user: <int> | default = 5000]
# Deprecated. When true, out-of-order writes are accepted.
# CLI flag: -ingester.unordered-writes
[unordered_writes: <boolean> | default = true]
# Maximum byte rate per second per stream, also expressible in human readable
# forms (1MB, 256KB, etc).
# CLI flag: -ingester.per-stream-rate-limit
[per_stream_rate_limit: <int> | default = 3MB]
# Maximum burst bytes per stream, also expressible in human readable forms (1MB,
# 256KB, etc). This is how far above the rate limit a stream can 'burst' before
# the stream is limited.
# CLI flag: -ingester.per-stream-rate-limit-burst
[per_stream_rate_limit_burst: <int> | default = 15MB]
# Maximum number of chunks that can be fetched in a single query.
# CLI flag: -store.query-chunk-limit
[max_chunks_per_query: <int> | default = 2000000]
# Limit the maximum of unique series that is returned by a metric query. When
# the limit is reached an error is returned.
# CLI flag: -querier.max-query-series
[max_query_series: <int> | default = 500]
# Limit how far back in time series data and metadata can be queried, up until
# lookback duration ago. This limit is enforced in the query frontend, the
# querier and the ruler. If the requested time range is outside the allowed
# range, the request will not fail, but will be modified to only query data
# within the allowed time range. The default value of 0 does not set a limit.
# CLI flag: -querier.max-query-lookback
[max_query_lookback: <duration> | default = 0s]
# The limit to length of chunk store queries. 0 to disable.
# CLI flag: -store.max-query-length
[max_query_length: <duration> | default = 30d1h]
# Limit the length of the [range] inside a range query. Default is 0 or
# unlimited
# CLI flag: -querier.max-query-range
[max_query_range: <duration> | default = 0s]
# Maximum number of queries that will be scheduled in parallel by the frontend.
# CLI flag: -querier.max-query-parallelism
[max_query_parallelism: <int> | default = 32]
# Maximum number of queries will be scheduled in parallel by the frontend for
# TSDB schemas.
# CLI flag: -querier.tsdb-max-query-parallelism
[tsdb_max_query_parallelism: <int> | default = 512]
# Maximum number of bytes assigned to a single sharded query. Also expressible
# in human readable forms (1GB, etc).
# CLI flag: -querier.tsdb-max-bytes-per-shard
[tsdb_max_bytes_per_shard: <int> | default = 600MB]
# Cardinality limit for index queries.
# CLI flag: -store.cardinality-limit
[cardinality_limit: <int> | default = 100000]
# Maximum number of stream matchers per query.
# CLI flag: -querier.max-streams-matcher-per-query
[max_streams_matchers_per_query: <int> | default = 1000]
# Maximum number of concurrent tail requests.
# CLI flag: -querier.max-concurrent-tail-requests
[max_concurrent_tail_requests: <int> | default = 10]
# Maximum number of log entries that will be returned for a query.
# CLI flag: -validation.max-entries-limit
[max_entries_limit_per_query: <int> | default = 5000]
# Most recent allowed cacheable result per-tenant, to prevent caching very
# recent results that might still be in flux.
# CLI flag: -frontend.max-cache-freshness
[max_cache_freshness_per_query: <duration> | default = 1m]
# Do not cache requests with an end time that falls within Now minus this
# duration. 0 disables this feature (default).
# CLI flag: -frontend.max-stats-cache-freshness
[max_stats_cache_freshness: <duration> | default = 0s]
# Maximum number of queriers that can handle requests for a single tenant. If
# set to 0 or value higher than number of available queriers, *all* queriers
# will handle requests for the tenant. Each frontend (or query-scheduler, if
# used) will select the same set of queriers for the same tenant (given that all
# queriers are connected to all frontends / query-schedulers). This option only
# works with queriers connecting to the query-frontend / query-scheduler, not
# when using downstream URL.
# CLI flag: -frontend.max-queriers-per-tenant
[max_queriers_per_tenant: <int> | default = 0]
# Number of days of index to be kept always downloaded for queries. Applies only
# to per user index in boltdb-shipper index store. 0 to disable.
# CLI flag: -store.query-ready-index-num-days
[query_ready_index_num_days: <int> | default = 0]
# Timeout when querying backends (ingesters or storage) during the execution of
# a query request. When a specific per-tenant timeout is used, the global
# timeout is ignored.
# CLI flag: -querier.query-timeout
[query_timeout: <duration> | default = 1m]
# Split queries by a time interval and execute in parallel. The value 0 disables
# splitting by time. This also determines how cache keys are chosen when result
# caching is enabled.
# CLI flag: -querier.split-queries-by-interval
[split_queries_by_interval: <duration> | default = 30m]
# Limit queries that can be sharded. Queries within the time range of now and
# now minus this sharding lookback are not sharded. The default value of 0s
# disables the lookback, causing sharding of all queries at all times.
# CLI flag: -frontend.min-sharding-lookback
[min_sharding_lookback: <duration> | default = 0s]
# Max number of bytes a query can fetch. Enforced in log and metric queries only
# when TSDB is used. The default value of 0 disables this limit.
# CLI flag: -frontend.max-query-bytes-read
[max_query_bytes_read: <int> | default = 0B]
# Max number of bytes a query can fetch after splitting and sharding. Enforced
# in log and metric queries only when TSDB is used. The default value of 0
# disables this limit.
# CLI flag: -frontend.max-querier-bytes-read
[max_querier_bytes_read: <int> | default = 0B]
# Enable log-volume endpoints.
[volume_enabled: <boolean>]
# The maximum number of aggregated series in a log-volume response
# CLI flag: -limits.volume-max-series
[volume_max_series: <int> | default = 1000]
# Deprecated. Duration to delay the evaluation of rules to ensure the underlying
# metrics have been pushed to Cortex.
# CLI flag: -ruler.evaluation-delay-duration
[ruler_evaluation_delay_duration: <duration> | default = 0s]
# Maximum number of rules per rule group per-tenant. 0 to disable.
# CLI flag: -ruler.max-rules-per-rule-group
[ruler_max_rules_per_rule_group: <int> | default = 0]
# Maximum number of rule groups per-tenant. 0 to disable.
# CLI flag: -ruler.max-rule-groups-per-tenant
[ruler_max_rule_groups_per_tenant: <int> | default = 0]
# The default tenant's shard size when shuffle-sharding is enabled in the ruler.
# When this setting is specified in the per-tenant overrides, a value of 0
# disables shuffle sharding for the tenant.
# CLI flag: -ruler.tenant-shard-size
[ruler_tenant_shard_size: <int> | default = 0]
# Disable recording rules remote-write.
[ruler_remote_write_disabled: <boolean>]
# Deprecated: Use 'ruler_remote_write_config' instead. The URL of the endpoint
# to send samples to.
[ruler_remote_write_url: <string> | default = ""]
# Deprecated: Use 'ruler_remote_write_config' instead. Timeout for requests to
# the remote write endpoint.
[ruler_remote_write_timeout: <duration>]
# Deprecated: Use 'ruler_remote_write_config' instead. Custom HTTP headers to be
# sent along with each remote write request. Be aware that headers that are set
# by Loki itself can't be overwritten.
[ruler_remote_write_headers: <headers>]
# Deprecated: Use 'ruler_remote_write_config' instead. List of remote write
# relabel configurations.
[ruler_remote_write_relabel_configs: <relabel_config...>]
# Deprecated: Use 'ruler_remote_write_config' instead. Number of samples to
# buffer per shard before we block reading of more samples from the WAL. It is
# recommended to have enough capacity in each shard to buffer several requests
# to keep throughput up while processing occasional slow remote requests.
[ruler_remote_write_queue_capacity: <int>]
# Deprecated: Use 'ruler_remote_write_config' instead. Minimum number of shards,
# i.e. amount of concurrency.
[ruler_remote_write_queue_min_shards: <int>]
# Deprecated: Use 'ruler_remote_write_config' instead. Maximum number of shards,
# i.e. amount of concurrency.
[ruler_remote_write_queue_max_shards: <int>]
# Deprecated: Use 'ruler_remote_write_config' instead. Maximum number of samples
# per send.
[ruler_remote_write_queue_max_samples_per_send: <int>]
# Deprecated: Use 'ruler_remote_write_config' instead. Maximum time a sample
# will wait in buffer.
[ruler_remote_write_queue_batch_send_deadline: <duration>]
# Deprecated: Use 'ruler_remote_write_config' instead. Initial retry delay. Gets
# doubled for every retry.
[ruler_remote_write_queue_min_backoff: <duration>]
# Deprecated: Use 'ruler_remote_write_config' instead. Maximum retry delay.
[ruler_remote_write_queue_max_backoff: <duration>]
# Deprecated: Use 'ruler_remote_write_config' instead. Retry upon receiving a
# 429 status code from the remote-write storage. This is experimental and might
# change in the future.
[ruler_remote_write_queue_retry_on_ratelimit: <boolean>]
# Deprecated: Use 'ruler_remote_write_config' instead. Configures AWS's
# Signature Verification 4 signing process to sign every remote write request.
ruler_remote_write_sigv4_config:
[region: <string> | default = ""]
[access_key: <string> | default = ""]
[secret_key: <string> | default = ""]
[profile: <string> | default = ""]
[role_arn: <string> | default = ""]
# Configures global and per-tenant limits for remote write clients. A map with
# remote client id as key.
[ruler_remote_write_config: <map of string to RemoteWriteConfig>]
# Timeout for a remote rule evaluation. Defaults to the value of
# 'querier.query-timeout'.
[ruler_remote_evaluation_timeout: <duration>]
# Maximum size (in bytes) of the allowable response size from a remote rule
# evaluation. Set to 0 to allow any response size (default).
[ruler_remote_evaluation_max_response_size: <int>]
# Deletion mode. Can be one of 'disabled', 'filter-only', or
# 'filter-and-delete'. When set to 'filter-only' or 'filter-and-delete', and if
# retention_enabled is true, then the log entry deletion API endpoints are
# available.
# CLI flag: -compactor.deletion-mode
[deletion_mode: <string> | default = "filter-and-delete"]
# Retention period to apply to stored data, only applies if retention_enabled is
# true in the compactor config. As of version 2.8.0, a zero value of 0 or 0s
# disables retention. In previous releases, Loki did not properly honor a zero
# value to disable retention and a really large value should be used instead.
# CLI flag: -store.retention
[retention_period: <duration> | default = 0s]
# Per-stream retention to apply, if the retention is enable on the compactor
# side.
# Example:
# retention_stream:
# - selector: '{namespace="dev"}'
# priority: 1
# period: 24h
# - selector: '{container="nginx"}'
# priority: 1
# period: 744h
# Selector is a Prometheus labels matchers that will apply the 'period'
# retention only if the stream is matching. In case multiple stream are
# matching, the highest priority will be picked. If no rule is matched the
# 'retention_period' is used.
[retention_stream: <list of StreamRetentions>]
# Feature renamed to 'runtime configuration', flag deprecated in favor of
# -runtime-config.file (runtime_config.file in YAML).
# CLI flag: -limits.per-user-override-config
[per_tenant_override_config: <string> | default = ""]
# Feature renamed to 'runtime configuration'; flag deprecated in favor of
# -runtime-config.reload-period (runtime_config.period in YAML).
# CLI flag: -limits.per-user-override-period
[per_tenant_override_period: <duration> | default = 10s]
# Deprecated: Use deletion_mode per tenant configuration instead.
[allow_deletes: <boolean>]
shard_streams:
[enabled: <boolean>]
[logging_enabled: <boolean>]
[desired_rate: <int>]
[blocked_queries: <blocked_query...>]
# Define a list of required selector labels.
[required_labels: <list of strings>]
# Minimum number of label matchers a query should contain.
[minimum_labels_number: <int>]
# The shard size defines how many index gateways should be used by a tenant for
# querying. If the global shard factor is 0, the global shard factor is set to
# the deprecated -replication-factor for backwards compatibility reasons.
# CLI flag: -index-gateway.shard-size
[index_gateway_shard_size: <int> | default = 0]
# Allow user to send structured metadata (non-indexed labels) in push payload.
# CLI flag: -validation.allow-structured-metadata
[allow_structured_metadata: <boolean> | default = false]
frontend_worker
# Address of query frontend service, in host:port format. If
# -querier.scheduler-address is set as well, querier will use scheduler instead.
# Only one of -querier.frontend-address or -querier.scheduler-address can be
# set. If neither is set, queries are only received via HTTP endpoint.
# CLI flag: -querier.frontend-address
[frontend_address: <string> | default = ""]
# Hostname (and port) of scheduler that querier will periodically resolve,
# connect to and receive queries from. Only one of -querier.frontend-address or
# -querier.scheduler-address can be set. If neither is set, queries are only
# received via HTTP endpoint.
# CLI flag: -querier.scheduler-address
[scheduler_address: <string> | default = ""]
# How often to query DNS for query-frontend or query-scheduler address. Also
# used to determine how often to poll the scheduler-ring for addresses if the
# scheduler-ring is configured.
# CLI flag: -querier.dns-lookup-period
[dns_lookup_duration: <duration> | default = 3s]
# Number of simultaneous queries to process per query-frontend or
# query-scheduler.
# CLI flag: -querier.worker-parallelism
[parallelism: <int> | default = 10]
# Force worker concurrency to match the -querier.max-concurrent option.
# Overrides querier.worker-parallelism.
# CLI flag: -querier.worker-match-max-concurrent
[match_max_concurrent: <boolean> | default = true]
# Querier ID, sent to frontend service to identify requests from the same
# querier. Defaults to hostname.
# CLI flag: -querier.id
[id: <string> | default = ""]
# The grpc_client block configures the gRPC client used to communicate between
# two Loki components.
# The CLI flags prefix for this block configuration is: querier.frontend-client
[grpc_client_config: <grpc_client>]
table_manager
# If true, disable all changes to DB capacity
# CLI flag: -table-manager.throughput-updates-disabled
[throughput_updates_disabled: <boolean> | default = false]
# If true, enables retention deletes of DB tables
# CLI flag: -table-manager.retention-deletes-enabled
[retention_deletes_enabled: <boolean> | default = false]
# Tables older than this retention period are deleted. Must be either 0
# (disabled) or a multiple of 24h. When enabled, be aware this setting is
# destructive to data!
# CLI flag: -table-manager.retention-period
[retention_period: <duration> | default = 0s]
# How frequently to poll backend to learn our capacity.
# CLI flag: -table-manager.poll-interval
[poll_interval: <duration> | default = 2m]
# Periodic tables grace period (duration which table will be created/deleted
# before/after it's needed).
# CLI flag: -table-manager.periodic-table.grace-period
[creation_grace_period: <duration> | default = 10m]
index_tables_provisioning:
# Enables on demand throughput provisioning for the storage provider (if
# supported). Applies only to tables which are not autoscaled. Supported by
# DynamoDB
# CLI flag: -table-manager.index-table.enable-ondemand-throughput-mode
[enable_ondemand_throughput_mode: <boolean> | default = false]
# Table default write throughput. Supported by DynamoDB
# CLI flag: -table-manager.index-table.write-throughput
[provisioned_write_throughput: <int> | default = 1000]
# Table default read throughput. Supported by DynamoDB
# CLI flag: -table-manager.index-table.read-throughput
[provisioned_read_throughput: <int> | default = 300]
write_scale:
# Should we enable autoscale for the table.
# CLI flag: -table-manager.index-table.write-throughput.scale.enabled
[enabled: <boolean> | default = false]
# AWS AutoScaling role ARN
# CLI flag: -table-manager.index-table.write-throughput.scale.role-arn
[role_arn: <string> | default = ""]
# DynamoDB minimum provision capacity.
# CLI flag: -table-manager.index-table.write-throughput.scale.min-capacity
[min_capacity: <int> | default = 3000]
# DynamoDB maximum provision capacity.
# CLI flag: -table-manager.index-table.write-throughput.scale.max-capacity
[max_capacity: <int> | default = 6000]
# DynamoDB minimum seconds between each autoscale up.
# CLI flag: -table-manager.index-table.write-throughput.scale.out-cooldown
[out_cooldown: <int> | default = 1800]
# DynamoDB minimum seconds between each autoscale down.
# CLI flag: -table-manager.index-table.write-throughput.scale.in-cooldown
[in_cooldown: <int> | default = 1800]
# DynamoDB target ratio of consumed capacity to provisioned capacity.
# CLI flag: -table-manager.index-table.write-throughput.scale.target-value
[target: <float> | default = 80]
read_scale:
# Should we enable autoscale for the table.
# CLI flag: -table-manager.index-table.read-throughput.scale.enabled
[enabled: <boolean> | default = false]
# AWS AutoScaling role ARN
# CLI flag: -table-manager.index-table.read-throughput.scale.role-arn
[role_arn: <string> | default = ""]
# DynamoDB minimum provision capacity.
# CLI flag: -table-manager.index-table.read-throughput.scale.min-capacity
[min_capacity: <int> | default = 3000]
# DynamoDB maximum provision capacity.
# CLI flag: -table-manager.index-table.read-throughput.scale.max-capacity
[max_capacity: <int> | default = 6000]
# DynamoDB minimum seconds between each autoscale up.
# CLI flag: -table-manager.index-table.read-throughput.scale.out-cooldown
[out_cooldown: <int> | default = 1800]
# DynamoDB minimum seconds between each autoscale down.
# CLI flag: -table-manager.index-table.read-throughput.scale.in-cooldown
[in_cooldown: <int> | default = 1800]
# DynamoDB target ratio of consumed capacity to provisioned capacity.
# CLI flag: -table-manager.index-table.read-throughput.scale.target-value
[target: <float> | default = 80]
# Enables on demand throughput provisioning for the storage provider (if
# supported). Applies only to tables which are not autoscaled. Supported by
# DynamoDB
# CLI flag: -table-manager.index-table.inactive-enable-ondemand-throughput-mode
[enable_inactive_throughput_on_demand_mode: <boolean> | default = false]
# Table write throughput for inactive tables. Supported by DynamoDB
# CLI flag: -table-manager.index-table.inactive-write-throughput
[inactive_write_throughput: <int> | default = 1]
# Table read throughput for inactive tables. Supported by DynamoDB
# CLI flag: -table-manager.index-table.inactive-read-throughput
[inactive_read_throughput: <int> | default = 300]
inactive_write_scale:
# Should we enable autoscale for the table.
# CLI flag: -table-manager.index-table.inactive-write-throughput.scale.enabled
[enabled: <boolean> | default = false]
# AWS AutoScaling role ARN
# CLI flag: -table-manager.index-table.inactive-write-throughput.scale.role-arn
[role_arn: <string> | default = ""]
# DynamoDB minimum provision capacity.
# CLI flag: -table-manager.index-table.inactive-write-throughput.scale.min-capacity
[min_capacity: <int> | default = 3000]
# DynamoDB maximum provision capacity.
# CLI flag: -table-manager.index-table.inactive-write-throughput.scale.max-capacity
[max_capacity: <int> | default = 6000]
# DynamoDB minimum seconds between each autoscale up.
# CLI flag: -table-manager.index-table.inactive-write-throughput.scale.out-cooldown
[out_cooldown: <int> | default = 1800]
# DynamoDB minimum seconds between each autoscale down.
# CLI flag: -table-manager.index-table.inactive-write-throughput.scale.in-cooldown
[in_cooldown: <int> | default = 1800]
# DynamoDB target ratio of consumed capacity to provisioned capacity.
# CLI flag: -table-manager.index-table.inactive-write-throughput.scale.target-value
[target: <float> | default = 80]
inactive_read_scale:
# Should we enable autoscale for the table.
# CLI flag: -table-manager.index-table.inactive-read-throughput.scale.enabled
[enabled: <boolean> | default = false]
# AWS AutoScaling role ARN
# CLI flag: -table-manager.index-table.inactive-read-throughput.scale.role-arn
[role_arn: <string> | default = ""]
# DynamoDB minimum provision capacity.
# CLI flag: -table-manager.index-table.inactive-read-throughput.scale.min-capacity
[min_capacity: <int> | default = 3000]
# DynamoDB maximum provision capacity.
# CLI flag: -table-manager.index-table.inactive-read-throughput.scale.max-capacity
[max_capacity: <int> | default = 6000]
# DynamoDB minimum seconds between each autoscale up.
# CLI flag: -table-manager.index-table.inactive-read-throughput.scale.out-cooldown
[out_cooldown: <int> | default = 1800]
# DynamoDB minimum seconds between each autoscale down.
# CLI flag: -table-manager.index-table.inactive-read-throughput.scale.in-cooldown
[in_cooldown: <int> | default = 1800]
# DynamoDB target ratio of consumed capacity to provisioned capacity.
# CLI flag: -table-manager.index-table.inactive-read-throughput.scale.target-value
[target: <float> | default = 80]
# Number of last inactive tables to enable write autoscale.
# CLI flag: -table-manager.index-table.inactive-write-throughput.scale-last-n
[inactive_write_scale_lastn: <int> | default = 4]
# Number of last inactive tables to enable read autoscale.
# CLI flag: -table-manager.index-table.inactive-read-throughput.scale-last-n
[inactive_read_scale_lastn: <int> | default = 4]
chunk_tables_provisioning:
# Enables on demand throughput provisioning for the storage provider (if
# supported). Applies only to tables which are not autoscaled. Supported by
# DynamoDB
# CLI flag: -table-manager.chunk-table.enable-ondemand-throughput-mode
[enable_ondemand_throughput_mode: <boolean> | default = false]
# Table default write throughput. Supported by DynamoDB
# CLI flag: -table-manager.chunk-table.write-throughput
[provisioned_write_throughput: <int> | default = 1000]
# Table default read throughput. Supported by DynamoDB
# CLI flag: -table-manager.chunk-table.read-throughput
[provisioned_read_throughput: <int> | default = 300]
write_scale:
# Should we enable autoscale for the table.
# CLI flag: -table-manager.chunk-table.write-throughput.scale.enabled
[enabled: <boolean> | default = false]
# AWS AutoScaling role ARN
# CLI flag: -table-manager.chunk-table.write-throughput.scale.role-arn
[role_arn: <string> | default = ""]
# DynamoDB minimum provision capacity.
# CLI flag: -table-manager.chunk-table.write-throughput.scale.min-capacity
[min_capacity: <int> | default = 3000]
# DynamoDB maximum provision capacity.
# CLI flag: -table-manager.chunk-table.write-throughput.scale.max-capacity
[max_capacity: <int> | default = 6000]
# DynamoDB minimum seconds between each autoscale up.
# CLI flag: -table-manager.chunk-table.write-throughput.scale.out-cooldown
[out_cooldown: <int> | default = 1800]
# DynamoDB minimum seconds between each autoscale down.
# CLI flag: -table-manager.chunk-table.write-throughput.scale.in-cooldown
[in_cooldown: <int> | default = 1800]
# DynamoDB target ratio of consumed capacity to provisioned capacity.
# CLI flag: -table-manager.chunk-table.write-throughput.scale.target-value
[target: <float> | default = 80]
read_scale:
# Should we enable autoscale for the table.
# CLI flag: -table-manager.chunk-table.read-throughput.scale.enabled
[enabled: <boolean> | default = false]
# AWS AutoScaling role ARN
# CLI flag: -table-manager.chunk-table.read-throughput.scale.role-arn
[role_arn: <string> | default = ""]
# DynamoDB minimum provision capacity.
# CLI flag: -table-manager.chunk-table.read-throughput.scale.min-capacity
[min_capacity: <int> | default = 3000]
# DynamoDB maximum provision capacity.
# CLI flag: -table-manager.chunk-table.read-throughput.scale.max-capacity
[max_capacity: <int> | default = 6000]
# DynamoDB minimum seconds between each autoscale up.
# CLI flag: -table-manager.chunk-table.read-throughput.scale.out-cooldown
[out_cooldown: <int> | default = 1800]
# DynamoDB minimum seconds between each autoscale down.
# CLI flag: -table-manager.chunk-table.read-throughput.scale.in-cooldown
[in_cooldown: <int> | default = 1800]
# DynamoDB target ratio of consumed capacity to provisioned capacity.
# CLI flag: -table-manager.chunk-table.read-throughput.scale.target-value
[target: <float> | default = 80]
# Enables on demand throughput provisioning for the storage provider (if
# supported). Applies only to tables which are not autoscaled. Supported by
# DynamoDB
# CLI flag: -table-manager.chunk-table.inactive-enable-ondemand-throughput-mode
[enable_inactive_throughput_on_demand_mode: <boolean> | default = false]
# Table write throughput for inactive tables. Supported by DynamoDB
# CLI flag: -table-manager.chunk-table.inactive-write-throughput
[inactive_write_throughput: <int> | default = 1]
# Table read throughput for inactive tables. Supported by DynamoDB
# CLI flag: -table-manager.chunk-table.inactive-read-throughput
[inactive_read_throughput: <int> | default = 300]
inactive_write_scale:
# Should we enable autoscale for the table.
# CLI flag: -table-manager.chunk-table.inactive-write-throughput.scale.enabled
[enabled: <boolean> | default = false]
# AWS AutoScaling role ARN
# CLI flag: -table-manager.chunk-table.inactive-write-throughput.scale.role-arn
[role_arn: <string> | default = ""]
# DynamoDB minimum provision capacity.
# CLI flag: -table-manager.chunk-table.inactive-write-throughput.scale.min-capacity
[min_capacity: <int> | default = 3000]
# DynamoDB maximum provision capacity.
# CLI flag: -table-manager.chunk-table.inactive-write-throughput.scale.max-capacity
[max_capacity: <int> | default = 6000]
# DynamoDB minimum seconds between each autoscale up.
# CLI flag: -table-manager.chunk-table.inactive-write-throughput.scale.out-cooldown
[out_cooldown: <int> | default = 1800]
# DynamoDB minimum seconds between each autoscale down.
# CLI flag: -table-manager.chunk-table.inactive-write-throughput.scale.in-cooldown
[in_cooldown: <int> | default = 1800]
# DynamoDB target ratio of consumed capacity to provisioned capacity.
# CLI flag: -table-manager.chunk-table.inactive-write-throughput.scale.target-value
[target: <float> | default = 80]
inactive_read_scale:
# Should we enable autoscale for the table.
# CLI flag: -table-manager.chunk-table.inactive-read-throughput.scale.enabled
[enabled: <boolean> | default = false]
# AWS AutoScaling role ARN
# CLI flag: -table-manager.chunk-table.inactive-read-throughput.scale.role-arn
[role_arn: <string> | default = ""]
# DynamoDB minimum provision capacity.
# CLI flag: -table-manager.chunk-table.inactive-read-throughput.scale.min-capacity
[min_capacity: <int> | default = 3000]
# DynamoDB maximum provision capacity.
# CLI flag: -table-manager.chunk-table.inactive-read-throughput.scale.max-capacity
[max_capacity: <int> | default = 6000]
# DynamoDB minimum seconds between each autoscale up.
# CLI flag: -table-manager.chunk-table.inactive-read-throughput.scale.out-cooldown
[out_cooldown: <int> | default = 1800]
# DynamoDB minimum seconds between each autoscale down.
# CLI flag: -table-manager.chunk-table.inactive-read-throughput.scale.in-cooldown
[in_cooldown: <int> | default = 1800]
# DynamoDB target ratio of consumed capacity to provisioned capacity.
# CLI flag: -table-manager.chunk-table.inactive-read-throughput.scale.target-value
[target: <float> | default = 80]
# Number of last inactive tables to enable write autoscale.
# CLI flag: -table-manager.chunk-table.inactive-write-throughput.scale-last-n
[inactive_write_scale_lastn: <int> | default = 4]
# Number of last inactive tables to enable read autoscale.
# CLI flag: -table-manager.chunk-table.inactive-read-throughput.scale-last-n
[inactive_read_scale_lastn: <int> | default = 4]
runtime_config
# How often to check runtime config files.
# CLI flag: -runtime-config.reload-period
[period: <duration> | default = 10s]
# Comma separated list of yaml files with the configuration that can be updated
# at runtime. Runtime config files will be merged from left to right.
# CLI flag: -runtime-config.file
[file: <string> | default = ""]
tracing
# Set to false to disable tracing.
# CLI flag: -tracing.enabled
[enabled: <boolean> | default = true]
analytics
# Enable anonymous usage reporting.
# CLI flag: -reporting.enabled
[reporting_enabled: <boolean> | default = true]
# URL to which reports are sent
# CLI flag: -reporting.usage-stats-url
[usage_stats_url: <string> | default = "https://stats.grafana.org/loki-usage-report"]
common
[path_prefix: <string> | default = ""]
storage:
# The s3_storage_config block configures the connection to Amazon S3 object
# storage backend.
# The CLI flags prefix for this block configuration is: common
[s3: <s3_storage_config>]
# The gcs_storage_config block configures the connection to Google Cloud
# Storage object storage backend.
# The CLI flags prefix for this block configuration is: common.storage
[gcs: <gcs_storage_config>]
# The azure_storage_config block configures the connection to Azure object
# storage backend.
# The CLI flags prefix for this block configuration is: common.storage
[azure: <azure_storage_config>]
# The alibabacloud_storage_config block configures the connection to Alibaba
# Cloud Storage object storage backend.
[alibabacloud: <alibabacloud_storage_config>]
# The bos_storage_config block configures the connection to Baidu Object
# Storage (BOS) object storage backend.
# The CLI flags prefix for this block configuration is: common.storage
[bos: <bos_storage_config>]
# The swift_storage_config block configures the connection to OpenStack Object
# Storage (Swift) object storage backend.
# The CLI flags prefix for this block configuration is: common.storage
[swift: <swift_storage_config>]
filesystem:
# Directory to store chunks in.
# CLI flag: -common.storage.filesystem.chunk-directory
[chunks_directory: <string> | default = ""]
# Directory to store rules in.
# CLI flag: -common.storage.filesystem.rules-directory
[rules_directory: <string> | default = ""]
hedging:
# If set to a non-zero value a second request will be issued at the provided
# duration. Default is 0 (disabled)
# CLI flag: -common.storage.hedge-requests-at
[at: <duration> | default = 0s]
# The maximum of hedge requests allowed.
# CLI flag: -common.storage.hedge-requests-up-to
[up_to: <int> | default = 2]
# The maximum of hedge requests allowed per seconds.
# CLI flag: -common.storage.hedge-max-per-second
[max_per_second: <int> | default = 5]
# The cos_storage_config block configures the connection to IBM Cloud Object
# Storage (COS) backend.
# The CLI flags prefix for this block configuration is: common.storage
[cos: <cos_storage_config>]
[persist_tokens: <boolean>]
[replication_factor: <int>]
ring:
kvstore:
# Backend storage to use for the ring. Supported values are: consul, etcd,
# inmemory, memberlist, multi.
# CLI flag: -common.storage.ring.store
[store: <string> | default = "consul"]
# The prefix for the keys in the store. Should end with a /.
# CLI flag: -common.storage.ring.prefix
[prefix: <string> | default = "collectors/"]
# Configuration for a Consul client. Only applies if the selected kvstore is
# consul.
# The CLI flags prefix for this block configuration is: common.storage.ring
[consul: <consul>]
# Configuration for an ETCD v3 client. Only applies if the selected kvstore
# is etcd.
# The CLI flags prefix for this block configuration is: common.storage.ring
[etcd: <etcd>]
multi:
# Primary backend storage used by multi-client.
# CLI flag: -common.storage.ring.multi.primary
[primary: <string> | default = ""]
# Secondary backend storage used by multi-client.
# CLI flag: -common.storage.ring.multi.secondary
[secondary: <string> | default = ""]
# Mirror writes to secondary store.
# CLI flag: -common.storage.ring.multi.mirror-enabled
[mirror_enabled: <boolean> | default = false]
# Timeout for storing value to secondary store.
# CLI flag: -common.storage.ring.multi.mirror-timeout
[mirror_timeout: <duration> | default = 2s]
# Period at which to heartbeat to the ring. 0 = disabled.
# CLI flag: -common.storage.ring.heartbeat-period
[heartbeat_period: <duration> | default = 15s]
# The heartbeat timeout after which compactors are considered unhealthy within
# the ring. 0 = never (timeout disabled).
# CLI flag: -common.storage.ring.heartbeat-timeout
[heartbeat_timeout: <duration> | default = 1m]
# File path where tokens are stored. If empty, tokens are not stored at
# shutdown and restored at startup.
# CLI flag: -common.storage.ring.tokens-file-path
[tokens_file_path: <string> | default = ""]
# True to enable zone-awareness and replicate blocks across different
# availability zones.
# CLI flag: -common.storage.ring.zone-awareness-enabled
[zone_awareness_enabled: <boolean> | default = false]
# Instance ID to register in the ring.
# CLI flag: -common.storage.ring.instance-id
[instance_id: <string> | default = "<hostname>"]
# Name of network interface to read address from.
# CLI flag: -common.storage.ring.instance-interface-names
[instance_interface_names: <list of strings> | default = [<private network interfaces>]]
# Port to advertise in the ring (defaults to server.grpc-listen-port).
# CLI flag: -common.storage.ring.instance-port
[instance_port: <int> | default = 0]
# IP address to advertise in the ring.
# CLI flag: -common.storage.ring.instance-addr
[instance_addr: <string> | default = ""]
# The availability zone where this instance is running. Required if
# zone-awareness is enabled.
# CLI flag: -common.storage.ring.instance-availability-zone
[instance_availability_zone: <string> | default = ""]
# Enable using a IPv6 instance address.
# CLI flag: -common.storage.ring.instance-enable-ipv6
[instance_enable_ipv6: <boolean> | default = false]
[instance_interface_names: <list of strings>]
[instance_addr: <string> | default = ""]
# the http address of the compactor in the form http://host:port
# CLI flag: -common.compactor-address
[compactor_address: <string> | default = ""]
# the grpc address of the compactor in the form host:port
# CLI flag: -common.compactor-grpc-address
[compactor_grpc_address: <string> | default = ""]
consul
# Hostname and port of Consul.
# CLI flag: -<prefix>.consul.hostname
[host: <string> | default = "localhost:8500"]
# ACL Token used to interact with Consul.
# CLI flag: -<prefix>.consul.acl-token
[acl_token: <string> | default = ""]
# HTTP timeout when talking to Consul
# CLI flag: -<prefix>.consul.client-timeout
[http_client_timeout: <duration> | default = 20s]
# Enable consistent reads to Consul.
# CLI flag: -<prefix>.consul.consistent-reads
[consistent_reads: <boolean> | default = false]
# Rate limit when watching key or prefix in Consul, in requests per second. 0
# disables the rate limit.
# CLI flag: -<prefix>.consul.watch-rate-limit
[watch_rate_limit: <float> | default = 1]
# Burst size used in rate limit. Values less than 1 are treated as 1.
# CLI flag: -<prefix>.consul.watch-burst-size
[watch_burst_size: <int> | default = 1]
# Maximum duration to wait before retrying a Compare And Swap (CAS) operation.
# CLI flag: -<prefix>.consul.cas-retry-delay
[cas_retry_delay: <duration> | default = 1s]
etcd
# The etcd endpoints to connect to.
# CLI flag: -<prefix>.etcd.endpoints
[endpoints: <list of strings> | default = []]
# The dial timeout for the etcd connection.
# CLI flag: -<prefix>.etcd.dial-timeout
[dial_timeout: <duration> | default = 10s]
# The maximum number of retries to do for failed ops.
# CLI flag: -<prefix>.etcd.max-retries
[max_retries: <int> | default = 10]
# Enable TLS.
# CLI flag: -<prefix>.etcd.tls-enabled
[tls_enabled: <boolean> | default = false]
# Path to the client certificate, which will be used for authenticating with the
# server. Also requires the key path to be configured.
# CLI flag: -<prefix>.etcd.tls-cert-path
[tls_cert_path: <string> | default = ""]
# Path to the key for the client certificate. Also requires the client
# certificate to be configured.
# CLI flag: -<prefix>.etcd.tls-key-path
[tls_key_path: <string> | default = ""]
# Path to the CA certificates to validate server certificate against. If not
# set, the host's root CA certificates are used.
# CLI flag: -<prefix>.etcd.tls-ca-path
[tls_ca_path: <string> | default = ""]
# Override the expected name on the server certificate.
# CLI flag: -<prefix>.etcd.tls-server-name
[tls_server_name: <string> | default = ""]
# Skip validating server certificate.
# CLI flag: -<prefix>.etcd.tls-insecure-skip-verify
[tls_insecure_skip_verify: <boolean> | default = false]
# Override the default cipher suite list (separated by commas). Allowed values:
#
# Secure Ciphers:
# - TLS_RSA_WITH_AES_128_CBC_SHA
# - TLS_RSA_WITH_AES_256_CBC_SHA
# - TLS_RSA_WITH_AES_128_GCM_SHA256
# - TLS_RSA_WITH_AES_256_GCM_SHA384
# - TLS_AES_128_GCM_SHA256
# - TLS_AES_256_GCM_SHA384
# - TLS_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256
#
# Insecure Ciphers:
# - TLS_RSA_WITH_RC4_128_SHA
# - TLS_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_RSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_ECDSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
# CLI flag: -<prefix>.etcd.tls-cipher-suites
[tls_cipher_suites: <string> | default = ""]
# Override the default minimum TLS version. Allowed values: VersionTLS10,
# VersionTLS11, VersionTLS12, VersionTLS13
# CLI flag: -<prefix>.etcd.tls-min-version
[tls_min_version: <string> | default = ""]
# Etcd username.
# CLI flag: -<prefix>.etcd.username
[username: <string> | default = ""]
# Etcd password.
# CLI flag: -<prefix>.etcd.password
[password: <string> | default = ""]
memberlist
# Name of the node in memberlist cluster. Defaults to hostname.
# CLI flag: -memberlist.nodename
[node_name: <string> | default = ""]
# Add random suffix to the node name.
# CLI flag: -memberlist.randomize-node-name
[randomize_node_name: <boolean> | default = true]
# The timeout for establishing a connection with a remote node, and for
# read/write operations.
# CLI flag: -memberlist.stream-timeout
[stream_timeout: <duration> | default = 10s]
# Multiplication factor used when sending out messages (factor * log(N+1)).
# CLI flag: -memberlist.retransmit-factor
[retransmit_factor: <int> | default = 4]
# How often to use pull/push sync.
# CLI flag: -memberlist.pullpush-interval
[pull_push_interval: <duration> | default = 30s]
# How often to gossip.
# CLI flag: -memberlist.gossip-interval
[gossip_interval: <duration> | default = 200ms]
# How many nodes to gossip to.
# CLI flag: -memberlist.gossip-nodes
[gossip_nodes: <int> | default = 3]
# How long to keep gossiping to dead nodes, to give them chance to refute their
# death.
# CLI flag: -memberlist.gossip-to-dead-nodes-time
[gossip_to_dead_nodes_time: <duration> | default = 30s]
# How soon can dead node's name be reclaimed with new address. 0 to disable.
# CLI flag: -memberlist.dead-node-reclaim-time
[dead_node_reclaim_time: <duration> | default = 0s]
# Enable message compression. This can be used to reduce bandwidth usage at the
# cost of slightly more CPU utilization.
# CLI flag: -memberlist.compression-enabled
[compression_enabled: <boolean> | default = true]
# Gossip address to advertise to other members in the cluster. Used for NAT
# traversal.
# CLI flag: -memberlist.advertise-addr
[advertise_addr: <string> | default = ""]
# Gossip port to advertise to other members in the cluster. Used for NAT
# traversal.
# CLI flag: -memberlist.advertise-port
[advertise_port: <int> | default = 7946]
# The cluster label is an optional string to include in outbound packets and
# gossip streams. Other members in the memberlist cluster will discard any
# message whose label doesn't match the configured one, unless the
# 'cluster-label-verification-disabled' configuration option is set to true.
# CLI flag: -memberlist.cluster-label
[cluster_label: <string> | default = ""]
# When true, memberlist doesn't verify that inbound packets and gossip streams
# have the cluster label matching the configured one. This verification should
# be disabled while rolling out the change to the configured cluster label in a
# live memberlist cluster.
# CLI flag: -memberlist.cluster-label-verification-disabled
[cluster_label_verification_disabled: <boolean> | default = false]
# Other cluster members to join. Can be specified multiple times. It can be an
# IP, hostname or an entry specified in the DNS Service Discovery format.
# CLI flag: -memberlist.join
[join_members: <list of strings> | default = []]
# Min backoff duration to join other cluster members.
# CLI flag: -memberlist.min-join-backoff
[min_join_backoff: <duration> | default = 1s]
# Max backoff duration to join other cluster members.
# CLI flag: -memberlist.max-join-backoff
[max_join_backoff: <duration> | default = 1m]
# Max number of retries to join other cluster members.
# CLI flag: -memberlist.max-join-retries
[max_join_retries: <int> | default = 10]
# If this node fails to join memberlist cluster, abort.
# CLI flag: -memberlist.abort-if-join-fails
[abort_if_cluster_join_fails: <boolean> | default = false]
# If not 0, how often to rejoin the cluster. Occasional rejoin can help to fix
# the cluster split issue, and is harmless otherwise. For example when using
# only few components as a seed nodes (via -memberlist.join), then it's
# recommended to use rejoin. If -memberlist.join points to dynamic service that
# resolves to all gossiping nodes (eg. Kubernetes headless service), then rejoin
# is not needed.
# CLI flag: -memberlist.rejoin-interval
[rejoin_interval: <duration> | default = 0s]
# How long to keep LEFT ingesters in the ring.
# CLI flag: -memberlist.left-ingesters-timeout
[left_ingesters_timeout: <duration> | default = 5m]
# Timeout for leaving memberlist cluster.
# CLI flag: -memberlist.leave-timeout
[leave_timeout: <duration> | default = 20s]
# How much space to use for keeping received and sent messages in memory for
# troubleshooting (two buffers). 0 to disable.
# CLI flag: -memberlist.message-history-buffer-bytes
[message_history_buffer_bytes: <int> | default = 0]
# IP address to listen on for gossip messages. Multiple addresses may be
# specified. Defaults to 0.0.0.0
# CLI flag: -memberlist.bind-addr
[bind_addr: <list of strings> | default = []]
# Port to listen on for gossip messages.
# CLI flag: -memberlist.bind-port
[bind_port: <int> | default = 7946]
# Timeout used when connecting to other nodes to send packet.
# CLI flag: -memberlist.packet-dial-timeout
[packet_dial_timeout: <duration> | default = 2s]
# Timeout for writing 'packet' data.
# CLI flag: -memberlist.packet-write-timeout
[packet_write_timeout: <duration> | default = 5s]
# Enable TLS on the memberlist transport layer.
# CLI flag: -memberlist.tls-enabled
[tls_enabled: <boolean> | default = false]
# Path to the client certificate, which will be used for authenticating with the
# server. Also requires the key path to be configured.
# CLI flag: -memberlist.tls-cert-path
[tls_cert_path: <string> | default = ""]
# Path to the key for the client certificate. Also requires the client
# certificate to be configured.
# CLI flag: -memberlist.tls-key-path
[tls_key_path: <string> | default = ""]
# Path to the CA certificates to validate server certificate against. If not
# set, the host's root CA certificates are used.
# CLI flag: -memberlist.tls-ca-path
[tls_ca_path: <string> | default = ""]
# Override the expected name on the server certificate.
# CLI flag: -memberlist.tls-server-name
[tls_server_name: <string> | default = ""]
# Skip validating server certificate.
# CLI flag: -memberlist.tls-insecure-skip-verify
[tls_insecure_skip_verify: <boolean> | default = false]
# Override the default cipher suite list (separated by commas). Allowed values:
#
# Secure Ciphers:
# - TLS_RSA_WITH_AES_128_CBC_SHA
# - TLS_RSA_WITH_AES_256_CBC_SHA
# - TLS_RSA_WITH_AES_128_GCM_SHA256
# - TLS_RSA_WITH_AES_256_GCM_SHA384
# - TLS_AES_128_GCM_SHA256
# - TLS_AES_256_GCM_SHA384
# - TLS_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256
#
# Insecure Ciphers:
# - TLS_RSA_WITH_RC4_128_SHA
# - TLS_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_RSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_ECDSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
# CLI flag: -memberlist.tls-cipher-suites
[tls_cipher_suites: <string> | default = ""]
# Override the default minimum TLS version. Allowed values: VersionTLS10,
# VersionTLS11, VersionTLS12, VersionTLS13
# CLI flag: -memberlist.tls-min-version
[tls_min_version: <string> | default = ""]
grpc_client
# gRPC client max receive message size (bytes).
# CLI flag: -<prefix>.grpc-max-recv-msg-size
[max_recv_msg_size: <int> | default = 104857600]
# gRPC client max send message size (bytes).
# CLI flag: -<prefix>.grpc-max-send-msg-size
[max_send_msg_size: <int> | default = 104857600]
# Use compression when sending messages. Supported values are: 'gzip', 'snappy'
# and '' (disable compression)
# CLI flag: -<prefix>.grpc-compression
[grpc_compression: <string> | default = ""]
# Rate limit for gRPC client; 0 means disabled.
# CLI flag: -<prefix>.grpc-client-rate-limit
[rate_limit: <float> | default = 0]
# Rate limit burst for gRPC client.
# CLI flag: -<prefix>.grpc-client-rate-limit-burst
[rate_limit_burst: <int> | default = 0]
# Enable backoff and retry when we hit rate limits.
# CLI flag: -<prefix>.backoff-on-ratelimits
[backoff_on_ratelimits: <boolean> | default = false]
backoff_config:
# Minimum delay when backing off.
# CLI flag: -<prefix>.backoff-min-period
[min_period: <duration> | default = 100ms]
# Maximum delay when backing off.
# CLI flag: -<prefix>.backoff-max-period
[max_period: <duration> | default = 10s]
# Number of times to backoff and retry before failing.
# CLI flag: -<prefix>.backoff-retries
[max_retries: <int> | default = 10]
# Initial stream window size. Values less than the default are not supported and
# are ignored. Setting this to a value other than the default disables the BDP
# estimator.
# CLI flag: -<prefix>.initial-stream-window-size
[initial_stream_window_size: <int> | default = 63KiB1023B]
# Initial connection window size. Values less than the default are not supported
# and are ignored. Setting this to a value other than the default disables the
# BDP estimator.
# CLI flag: -<prefix>.initial-connection-window-size
[initial_connection_window_size: <int> | default = 63KiB1023B]
# Enable TLS in the gRPC client. This flag needs to be enabled when any other
# TLS flag is set. If set to false, insecure connection to gRPC server will be
# used.
# CLI flag: -<prefix>.tls-enabled
[tls_enabled: <boolean> | default = false]
# Path to the client certificate, which will be used for authenticating with the
# server. Also requires the key path to be configured.
# CLI flag: -<prefix>.tls-cert-path
[tls_cert_path: <string> | default = ""]
# Path to the key for the client certificate. Also requires the client
# certificate to be configured.
# CLI flag: -<prefix>.tls-key-path
[tls_key_path: <string> | default = ""]
# Path to the CA certificates to validate server certificate against. If not
# set, the host's root CA certificates are used.
# CLI flag: -<prefix>.tls-ca-path
[tls_ca_path: <string> | default = ""]
# Override the expected name on the server certificate.
# CLI flag: -<prefix>.tls-server-name
[tls_server_name: <string> | default = ""]
# Skip validating server certificate.
# CLI flag: -<prefix>.tls-insecure-skip-verify
[tls_insecure_skip_verify: <boolean> | default = false]
# Override the default cipher suite list (separated by commas). Allowed values:
#
# Secure Ciphers:
# - TLS_RSA_WITH_AES_128_CBC_SHA
# - TLS_RSA_WITH_AES_256_CBC_SHA
# - TLS_RSA_WITH_AES_128_GCM_SHA256
# - TLS_RSA_WITH_AES_256_GCM_SHA384
# - TLS_AES_128_GCM_SHA256
# - TLS_AES_256_GCM_SHA384
# - TLS_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256
#
# Insecure Ciphers:
# - TLS_RSA_WITH_RC4_128_SHA
# - TLS_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_RSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_ECDSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
# CLI flag: -<prefix>.tls-cipher-suites
[tls_cipher_suites: <string> | default = ""]
# Override the default minimum TLS version. Allowed values: VersionTLS10,
# VersionTLS11, VersionTLS12, VersionTLS13
# CLI flag: -<prefix>.tls-min-version
[tls_min_version: <string> | default = ""]
# The maximum amount of time to establish a connection. A value of 0 means
# default gRPC client connect timeout and backoff.
# CLI flag: -<prefix>.connect-timeout
[connect_timeout: <duration> | default = 5s]
# Initial backoff delay after first connection failure. Only relevant if
# ConnectTimeout > 0.
# CLI flag: -<prefix>.connect-backoff-base-delay
[connect_backoff_base_delay: <duration> | default = 1s]
# Maximum backoff delay when establishing a connection. Only relevant if
# ConnectTimeout > 0.
# CLI flag: -<prefix>.connect-backoff-max-delay
[connect_backoff_max_delay: <duration> | default = 5s]
tls_config
# Path to the client certificate, which will be used for authenticating with the
# server. Also requires the key path to be configured.
# CLI flag: -frontend.tail-tls-config.tls-cert-path
[tls_cert_path: <string> | default = ""]
# Path to the key for the client certificate. Also requires the client
# certificate to be configured.
# CLI flag: -frontend.tail-tls-config.tls-key-path
[tls_key_path: <string> | default = ""]
# Path to the CA certificates to validate server certificate against. If not
# set, the host's root CA certificates are used.
# CLI flag: -frontend.tail-tls-config.tls-ca-path
[tls_ca_path: <string> | default = ""]
# Override the expected name on the server certificate.
# CLI flag: -frontend.tail-tls-config.tls-server-name
[tls_server_name: <string> | default = ""]
# Skip validating server certificate.
# CLI flag: -frontend.tail-tls-config.tls-insecure-skip-verify
[tls_insecure_skip_verify: <boolean> | default = false]
# Override the default cipher suite list (separated by commas). Allowed values:
#
# Secure Ciphers:
# - TLS_RSA_WITH_AES_128_CBC_SHA
# - TLS_RSA_WITH_AES_256_CBC_SHA
# - TLS_RSA_WITH_AES_128_GCM_SHA256
# - TLS_RSA_WITH_AES_256_GCM_SHA384
# - TLS_AES_128_GCM_SHA256
# - TLS_AES_256_GCM_SHA384
# - TLS_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
# - TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
# - TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
# - TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
# - TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256
#
# Insecure Ciphers:
# - TLS_RSA_WITH_RC4_128_SHA
# - TLS_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_RSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_ECDSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_RC4_128_SHA
# - TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA
# - TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256
# - TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
# CLI flag: -frontend.tail-tls-config.tls-cipher-suites
[tls_cipher_suites: <string> | default = ""]
# Override the default minimum TLS version. Allowed values: VersionTLS10,
# VersionTLS11, VersionTLS12, VersionTLS13
# CLI flag: -frontend.tail-tls-config.tls-min-version
[tls_min_version: <string> | default = ""]
cache_config
# (deprecated: use embedded-cache instead) Enable in-memory cache (auto-enabled
# for the chunks & query results cache if no other cache is configured).
# CLI flag: -<prefix>.cache.enable-fifocache
[enable_fifocache: <boolean> | default = false]
# The default validity of entries for caches unless overridden.
# CLI flag: -<prefix>.default-validity
[default_validity: <duration> | default = 1h]
background:
# At what concurrency to write back to cache.
# CLI flag: -<prefix>.background.write-back-concurrency
[writeback_goroutines: <int> | default = 10]
# How many key batches to buffer for background write-back.
# CLI flag: -<prefix>.background.write-back-buffer
[writeback_buffer: <int> | default = 10000]
# Size limit in bytes for background write-back.
# CLI flag: -<prefix>.background.write-back-size-limit
[writeback_size_limit: <int> | default = 1GB]
memcached:
# How long keys stay in the memcache.
# CLI flag: -<prefix>.memcached.expiration
[expiration: <duration> | default = 0s]
# How many keys to fetch in each batch.
# CLI flag: -<prefix>.memcached.batchsize
[batch_size: <int> | default = 1024]
# Maximum active requests to memcache.
# CLI flag: -<prefix>.memcached.parallelism
[parallelism: <int> | default = 100]
memcached_client:
# Hostname for memcached service to use. If empty and if addresses is unset,
# no memcached will be used.
# CLI flag: -<prefix>.memcached.hostname
[host: <string> | default = ""]
# SRV service used to discover memcache servers.
# CLI flag: -<prefix>.memcached.service
[service: <string> | default = "memcached"]
# EXPERIMENTAL: Comma separated addresses list in DNS Service Discovery
# format:
# https://cortexmetrics.io/docs/configuration/arguments/#dns-service-discovery
# CLI flag: -<prefix>.memcached.addresses
[addresses: <string> | default = ""]
# Maximum time to wait before giving up on memcached requests.
# CLI flag: -<prefix>.memcached.timeout
[timeout: <duration> | default = 100ms]
# Maximum number of idle connections in pool.
# CLI flag: -<prefix>.memcached.max-idle-conns
[max_idle_conns: <int> | default = 16]
# The maximum size of an item stored in memcached. Bigger items are not
# stored. If set to 0, no maximum size is enforced.
# CLI flag: -<prefix>.memcached.max-item-size
[max_item_size: <int> | default = 0]
# Period with which to poll DNS for memcache servers.
# CLI flag: -<prefix>.memcached.update-interval
[update_interval: <duration> | default = 1m]
# Use consistent hashing to distribute to memcache servers.
# CLI flag: -<prefix>.memcached.consistent-hash
[consistent_hash: <boolean> | default = true]
# Trip circuit-breaker after this number of consecutive dial failures (if zero
# then circuit-breaker is disabled).
# CLI flag: -<prefix>.memcached.circuit-breaker-consecutive-failures
[circuit_breaker_consecutive_failures: <int> | default = 10]
# Duration circuit-breaker remains open after tripping (if zero then 60
# seconds is used).
# CLI flag: -<prefix>.memcached.circuit-breaker-timeout
[circuit_breaker_timeout: <duration> | default = 10s]
# Reset circuit-breaker counts after this long (if zero then never reset).
# CLI flag: -<prefix>.memcached.circuit-breaker-interval
[circuit_breaker_interval: <duration> | default = 10s]
redis:
# Redis Server or Cluster configuration endpoint to use for caching. A
# comma-separated list of endpoints for Redis Cluster or Redis Sentinel. If
# empty, no redis will be used.
# CLI flag: -<prefix>.redis.endpoint
[endpoint: <string> | default = ""]
# Redis Sentinel master name. An empty string for Redis Server or Redis
# Cluster.
# CLI flag: -<prefix>.redis.master-name
[master_name: <string> | default = ""]
# Maximum time to wait before giving up on redis requests.
# CLI flag: -<prefix>.redis.timeout
[timeout: <duration> | default = 500ms]
# How long keys stay in the redis.
# CLI flag: -<prefix>.redis.expiration
[expiration: <duration> | default = 0s]
# Database index.
# CLI flag: -<prefix>.redis.db
[db: <int> | default = 0]
# Maximum number of connections in the pool.
# CLI flag: -<prefix>.redis.pool-size
[pool_size: <int> | default = 0]
# Username to use when connecting to redis.
# CLI flag: -<prefix>.redis.username
[username: <string> | default = ""]
# Password to use when connecting to redis.
# CLI flag: -<prefix>.redis.password
[password: <string> | default = ""]
# Enable connecting to redis with TLS.
# CLI flag: -<prefix>.redis.tls-enabled
[tls_enabled: <boolean> | default = false]
# Skip validating server certificate.
# CLI flag: -<prefix>.redis.tls-insecure-skip-verify
[tls_insecure_skip_verify: <boolean> | default = false]
# Close connections after remaining idle for this duration. If the value is
# zero, then idle connections are not closed.
# CLI flag: -<prefix>.redis.idle-timeout
[idle_timeout: <duration> | default = 0s]
# Close connections older than this duration. If the value is zero, then the
# pool does not close connections based on age.
# CLI flag: -<prefix>.redis.max-connection-age
[max_connection_age: <duration> | default = 0s]
# By default, the Redis client only reads from the master node. Enabling this
# option can lower pressure on the master node by randomly routing read-only
# commands to the master and any available replicas.
# CLI flag: -<prefix>.redis.route-randomly
[route_randomly: <boolean> | default = false]
embedded_cache:
# Whether embedded cache is enabled.
# CLI flag: -<prefix>.embedded-cache.enabled
[enabled: <boolean> | default = false]
# Maximum memory size of the cache in MB.
# CLI flag: -<prefix>.embedded-cache.max-size-mb
[max_size_mb: <int> | default = 100]
# The time to live for items in the cache before they get purged.
# CLI flag: -<prefix>.embedded-cache.ttl
[ttl: <duration> | default = 1h]
fifocache:
# Maximum memory size of the cache in bytes. A unit suffix (KB, MB, GB) may be
# applied.
# CLI flag: -<prefix>.fifocache.max-size-bytes
[max_size_bytes: <string> | default = "1GB"]
# deprecated: Maximum number of entries in the cache.
# CLI flag: -<prefix>.fifocache.max-size-items
[max_size_items: <int> | default = 0]
# The time to live for items in the cache before they get purged.
# CLI flag: -<prefix>.fifocache.ttl
[ttl: <duration> | default = 1h]
# Deprecated (use ttl instead): The expiry duration for the cache.
# CLI flag: -<prefix>.fifocache.duration
[validity: <duration> | default = 0s]
# Deprecated (use max-size-items or max-size-bytes instead): The number of
# entries to cache.
# CLI flag: -<prefix>.fifocache.size
[size: <int> | default = 0]
[purgeinterval: <duration>]
# The maximum number of concurrent asynchronous writeback cache can occur.
# CLI flag: -<prefix>.max-async-cache-write-back-concurrency
[async_cache_write_back_concurrency: <int> | default = 16]
# The maximum number of enqueued asynchronous writeback cache allowed.
# CLI flag: -<prefix>.max-async-cache-write-back-buffer-size
[async_cache_write_back_buffer_size: <int> | default = 500]
period_config
# The date of the first day that index buckets should be created. Use a date in
# the past if this is your only period_config, otherwise use a date when you
# want the schema to switch over. In YYYY-MM-DD format, for example: 2018-04-15.
[from: <daytime>]
# store and object_store below affect which <storage_config> key is used. Which
# index to use. Either tsdb or boltdb-shipper. Following stores are deprecated:
# aws, aws-dynamo, gcp, gcp-columnkey, bigtable, bigtable-hashed, cassandra,
# grpc.
[store: <string> | default = ""]
# Which store to use for the chunks. Either aws (alias s3), azure, gcs,
# alibabacloud, bos, cos, swift, filesystem, or a named_store (refer to
# named_stores_config). Following stores are deprecated: aws-dynamo, gcp,
# gcp-columnkey, bigtable, bigtable-hashed, cassandra, grpc.
[object_store: <string> | default = ""]
# The schema version to use, current recommended schema is v12.
[schema: <string> | default = ""]
# Configures how the index is updated and stored.
index:
# Table prefix for all period tables.
[prefix: <string> | default = ""]
# Table period.
[period: <duration>]
# A map to be added to all managed tables.
[tags: <map of string to string>]
# Configured how the chunks are updated and stored.
chunks:
# Table prefix for all period tables.
[prefix: <string> | default = ""]
# Table period.
[period: <duration>]
# A map to be added to all managed tables.
[tags: <map of string to string>]
# How many shards will be created. Only used if schema is v10 or greater.
[row_shards: <int>]
alibabacloud_storage_config
# Name of OSS bucket.
# CLI flag: -common.storage.oss.bucketname
[bucket: <string> | default = ""]
# oss Endpoint to connect to.
# CLI flag: -common.storage.oss.endpoint
[endpoint: <string> | default = ""]
# alibabacloud Access Key ID
# CLI flag: -common.storage.oss.access-key-id
[access_key_id: <string> | default = ""]
# alibabacloud Secret Access Key
# CLI flag: -common.storage.oss.secret-access-key
[secret_access_key: <string> | default = ""]
bos_storage_config
# Name of BOS bucket.
# CLI flag: -<prefix>.bos.bucket-name
[bucket_name: <string> | default = ""]
# BOS endpoint to connect to.
# CLI flag: -<prefix>.bos.endpoint
[endpoint: <string> | default = "bj.bcebos.com"]
# Baidu Cloud Engine (BCE) Access Key ID.
# CLI flag: -<prefix>.bos.access-key-id
[access_key_id: <string> | default = ""]
# Baidu Cloud Engine (BCE) Secret Access Key.
# CLI flag: -<prefix>.bos.secret-access-key
[secret_access_key: <string> | default = ""]
local_storage_config
# Directory to store chunks in.
# CLI flag: -local.chunk-directory
[directory: <string> | default = ""]
文章来源:https://blog.csdn.net/weixin_40972073/article/details/135041962
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!