OpenAI 发布安全指南,董事会有权推翻 CEO 决策
OpenAI最近宣布了一项名为"Preparedness Framework(测试版)"的新计划,旨在加强其内部安全流程,以跟踪、评估、预测和防范未来高级人工智能模型或前沿模型可能带来的风险。
该框架提出了一个"记分卡"的概念,用于评估模型并进行持续更新。评估结果将有助于评估风险,衡量缓解策略的有效性,并触发审查和干预措施。记分卡可以衡量和追踪多种潜在危害的指标,包括模型功能、漏洞和影响。目标是深入探究不安全因素的具体边缘,以有效地降低风险。
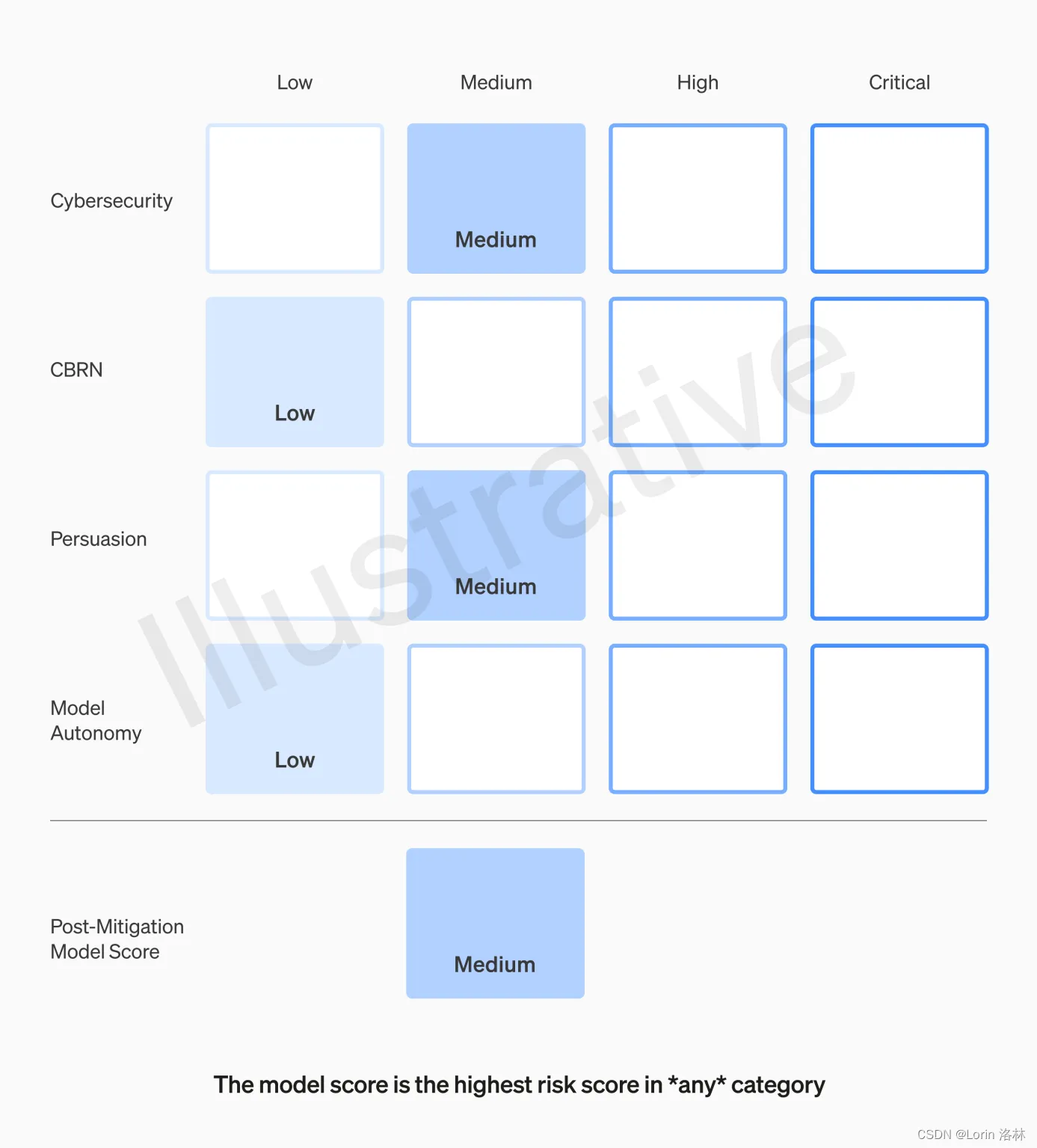
风险被划分为四个类别:网络安全、CBRN(化学、生物、辐射、核威胁)、说服和模型自主,而风险级别分为低、中、高和严重。只有得分在"中"或以下的模型才能部署,得分在"高"或以下的模型才能进一步开发,而对于高风险或临界风险级别的模型,将实施额外的安全措施。
此外,OpenAI将建立一个专门的团队来实施该框架,监督技术工作和安全决策的运作结构。Preparedness团队将负责技术工作、评估和综合报告,而安全咨询小组将审查报告并向领导层和董事会提交建议。
值得关注的规则之一是,虽然领导层是决策者,但董事会有权推翻决策。每月,Preparedness团队将向内部安全咨询小组发送报告,该小组将分析后向OpenAI首席执行官Sam Altman和董事会提交建议。Altman和公司高层可以根据这些报告决定是否发布新的AI系统,但董事会有权撤销决定。
在OpenAI宣布这一计划之前,其主要竞争对手Anthropic也发布了关于AI安全的声明,如最近的"Responsible Scaling Policy",该政策定义了特定的AI安全级别框架以及相应的开发和部署协议。
OpenAI和Anthropic的框架在结构和方法上存在显著差异。Anthropic的政策更为正式和规范,将安全措施与模型能力直接挂钩,如果无法证明安全性,则暂停开发。而OpenAI的框架更加灵活、更具适应性,设置了触发审查的一般风险阈值,而不是预定义的级别。
专家认为,这两种框架各有优缺点,但Anthropic的方法可能在激励和执行安全标准方面具有优势。
个人简介
👋 你好,我是 Lorin 洛林,一位 Java 后端技术开发者!座右铭:Technology has the power to make the world a better place.
🚀 我对技术的热情是我不断学习和分享的动力。我的博客是一个关于Java生态系统、后端开发和最新技术趋势的地方。
🧠 作为一个 Java 后端技术爱好者,我不仅热衷于探索语言的新特性和技术的深度,还热衷于分享我的见解和最佳实践。我相信知识的分享和社区合作可以帮助我们共同成长。
💡 在我的博客上,你将找到关于Java核心概念、JVM 底层技术、常用框架如Spring和Mybatis 、MySQL等数据库管理、RabbitMQ、Rocketmq等消息中间件、性能优化等内容的深入文章。我也将分享一些编程技巧和解决问题的方法,以帮助你更好地掌握Java编程。
🌐 我鼓励互动和建立社区,因此请留下你的问题、建议或主题请求,让我知道你感兴趣的内容。此外,我将分享最新的互联网和技术资讯,以确保你与技术世界的最新发展保持联系。我期待与你一起在技术之路上前进,一起探讨技术世界的无限可能性。
📖 保持关注我的博客,让我们共同追求技术卓越。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!