浪花 - 根据标签搜索用户
2024-01-09 19:22:03
用户中心:集中提供用户的检索、操作、注册、登录、鉴权
此接口与用户关系紧密,在【用户中心】项目后端新增一个接口——根据标签搜索用户
- AND:允许用户传入多个标签,多个标签都存在才能搜索出来
- OR:允许用户传入多个标签,有任何一个标签存在就能搜索出来
本文演示两种方式进行标签搜索:
- 使用 SQL 查询:通过 Mybatis-plus 的 like 方法实现标签信息 tags 的模糊匹配,优点是实现简单
- 使用内存查询:优点是可以在代码中呈现,使用灵活
方式一:使用 SQL 查询
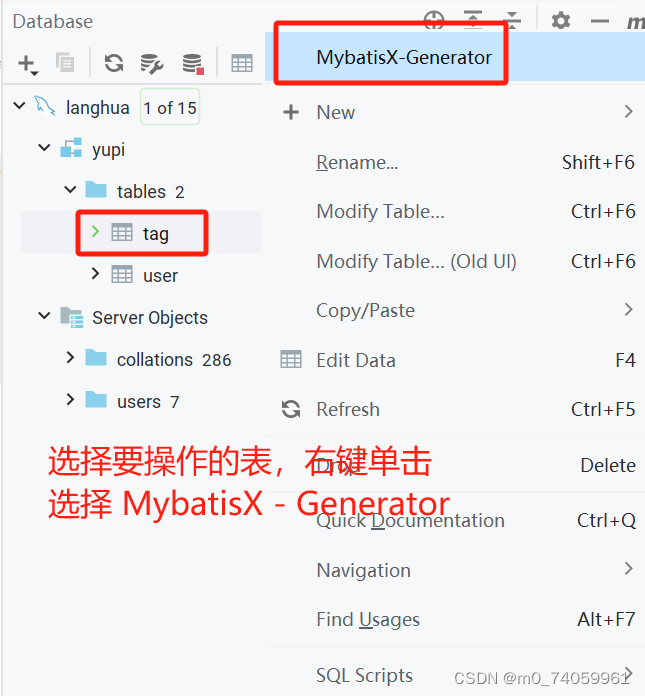
1. 使用 MybatisX 插件简化开发(在插件商店直接搜索 MybatisX 点击 install 进行插件的安装)
-
选择要操作的表,自动生成下列文件,提高开发效率
-
数据库表 - Java 实体类映射文件:Tag.java
-
针对 tag 表的数据库业务层操作:TagService.java 和 TagServiceImpl.java
-
针对 tag 表的数据库持久层操作:TagMapper.java
-
数据库操作映射 SQL(较复杂的 SQL 语句)文件:TagMapper.xml
-
2.?编写模糊查询匹配用户标签的业务代码
/**
* 根据标签搜索用户
* @param tagNameList 用户的标签列表
* @return 匹配该标签列表的用户列表
*/
public List<User> searchUsersByTags(List<String> tagNameList) {
// 1. 判断参数是否为空
if (CollectionUtils.isEmpty(tagNameList)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
// 2. 构造查询器
QueryWrapper<User> queryWrapper = new QueryWrapper();
for (String tagName : tagNameList) {
queryWrapper = queryWrapper.like("tags", tagName);
}
// 3. 根据标签列表查找用户
List<User> userList = userMapper.selectList(queryWrapper);
// 4. 返回脱敏后的用户列表
return userList.stream().map(this::getSafetyUser).collect(Collectors.toList());
}3. 开启 Mybatis-plus 的 SQL 语句日志输出:在项目配置文件 application.yml 中添加下列配置信息
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #开启sql日志
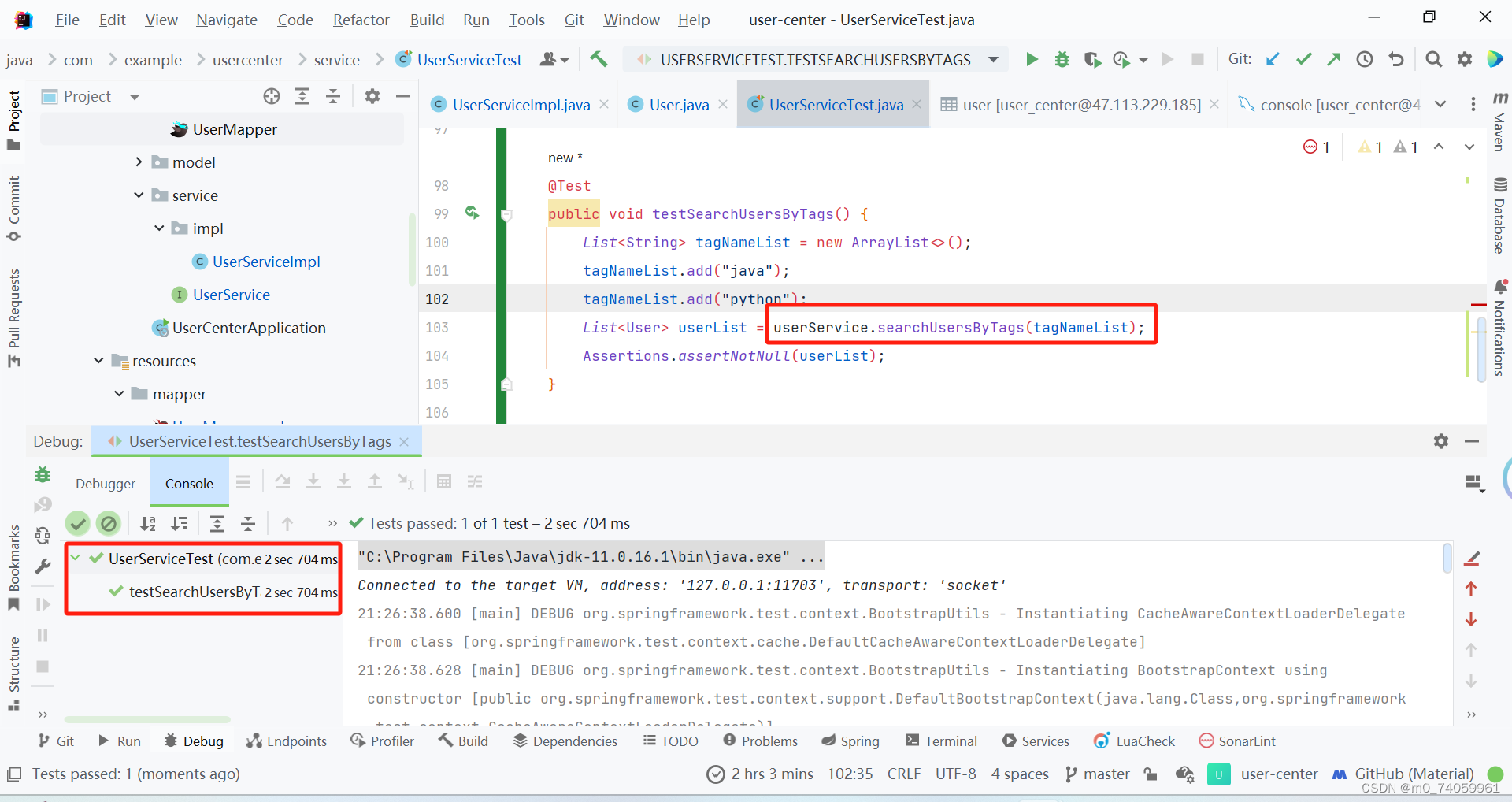
?4. Junit 单元测试
@Test
public void testSearchUsersByTags() {
List<String> tagNameList = new ArrayList<>();
tagNameList.add("java");
tagNameList.add("python");
List<User> userList = userService.searchUsersByTags(tagNameList);
Assertions.assertNotNull(userList);
}
方式二:使用内存查询
使用 SQL 全量查询出所有用户,在内存中计算过滤符合条件的用户
1. 先查询所有用户,遍历用户并取出用户的标签信息
2. 在内存中判断 tags 是否包含所要求的标签
- 引入 Gson 依赖:将 tags 序列化为 Java 对象,使用 Set 集合接收
- 遍历要搜索的标签列表,判断用户是否拥有该标签
/**
* 根据标签搜索用户
* @param tagNameList 用户的标签列表
* @return 匹配该标签列表的用户列表
*/
public List<User> searchUsersByTags(List<String> tagNameList) {
// 1. 判断参数是否为空
if (CollectionUtils.isEmpty(tagNameList)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
/**
* 方式二:使用内存查询
*/
// 1. 查询所有用户
QueryWrapper<User> queryWrapper = new QueryWrapper();
List<User> userList = userMapper.selectList(queryWrapper);
Gson gson = new Gson();
return userList.stream().filter(user -> {
// 2. 遍历用户取出标签信息
String tagsStr = user.getTags();
if (StringUtils.isEmpty(tagsStr)) {
return false;
}
// 3. 在内存中判断是否包含要求标签
Set<String> tempTagsNameSet = gson.fromJson(tagsStr, new TypeToken<Set<String>>(){}.getType());
for (String tagName : tagNameList) {
if (!tempTagsNameSet.contains(tagName)) {// 用户标签不包含所要求的标签
return false;
}
}
return true;
}).map(this::getSafetyUser).collect(Collectors.toList());
}3. Junit 单元测试

4. 判断两种方式的效率
- 通过实际测试(计算)两种方法的运行时间来分析
- 数据量大时效果更明显
5. 思路扩展:如果两种查询不相上下,时而 SQL 查询快,时而内存查询快,如何选择?
- 如果参数可以分析,可以根据用户的参数(比如搜索标签的数目)来选择适合的查询方式
- 如果参数不可分析,且数据库连接足够,内存空间足够,可以并发使用两种方式同时查询,哪种方式先返回数据就用谁的数据
- SQL 查询与内存运算相结合,先用 SQL 过滤一部分用户:例如要查询包含 "java" 等几十个标签用户,可以先使用 "java" 标签进行过滤,只剩下包含 "java" 标签的用户,再到内存中计算用户的其他标签
序列化和反序列化
1. 序列化和反序列化:将对象转换为字节流以便在网络中进行传输和存储的过程
- 序列化:将 Java 对象转为 JSON 字符串
- 反序列化:将 JSON 字符串转为 Java 对象
2. 几种 JSON 序列化库
- fastjson(ali 出品)
- gson(google 的,推荐)?(本文使用方式)
- jackson
- kryo
- hutool 工具中的 JSONUtil?
- 引入依赖
- 序列化:JSONUtil.toBean(json, Object.class); 这里不适用,需要指定一个 Java 对象的字节码类型,但是我们的 tags 不是一个 Java 对象
- 反序列化:JSONUtil.toJsonStr(obj);
文章来源:https://blog.csdn.net/m0_74059961/article/details/135436403
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!