【图像分类】【深度学习】【轻量级网络】【Pytorch版本】ShuffleNet_V1模型算法详解
【图像分类】【深度学习】【轻量级网络】【Pytorch版本】ShuffleNet_V1模型算法详解
文章目录
前言
ShuffleNet_V1是由旷视科技的Zhang, Xiangyu等人在《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices【CVPR-2018】》【论文地址】一文中提出的模型,是一种采用了逐点组卷积和通道混洗的轻量级CNN网络,在保持精度的同时大大降低了计算成本。
ShuffleNet_V1讲解
一般的卷积是全通道卷积,即在所有输入特征图上进行卷积,这是一种通道密集连接方式(channel dense connection),而组卷积(group convolution)相比则是一种通道稀疏连接方式(channel sparse connection)。组卷积将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行组内卷积,这样会降低卷积的计算量。ShuffleNet_V1的核心设计理念是对不同的通道进行随机组合重排(shuffle)来解决组卷积带来的弊端。
group convolution(分组卷积)
组卷积在ResNeXt【参考】中已经有效地证明了其有效性。组卷积是一种将输入特征图分成多个组,并对每个组进行独立卷积的技术,这种方法可以增加模型的非线性能力和表示能力,同时减少了计算量。

最近,MobileNet【参考】利用了深度可分离卷积获得轻量级模型,并在轻量级模型中获得了显著的效果。ShuffleNet_V1将组卷积和深度可分卷积以一种新的形式进行了推广。
Channel Shuffle(通道混洗)
分组卷积存在缺点:当前网络层的某个输出通道只与某几个输入通道相关,也就是某个通道的输出只来自一小部分的输入通道,这阻碍了通道组之间的信息交流。
下图是ShuffleNet_V1论文中普通分组卷积和通道混洗的分组卷积之间的详细示意图:

图(a)中不同颜色代表不同的分组,每个分组的输入的没有掺杂其他分组的特征,这就相当于各自管各自的,导致了分组之间信息的闭塞。如果允许每个分组卷积获取不同组的特征,如图(b)所示,将GConv1所有分组的输出特征Feature都根据组数均匀分发,作为GConv2每个分组的输入,那么输出(Output)和输入(Input)通道就完全相关了。这种混洗操作可以通过图(c)的通道混洗高效优雅地实现。
ShuffleNet Uint(ShuffleNet基础单元)
基于ResNet【参考】的残差模块,新增了了通道混洗操作和深度可分离卷积操作。
下图是ShuffleNet_V1论文中ShuffleNet单元的详细示意图:
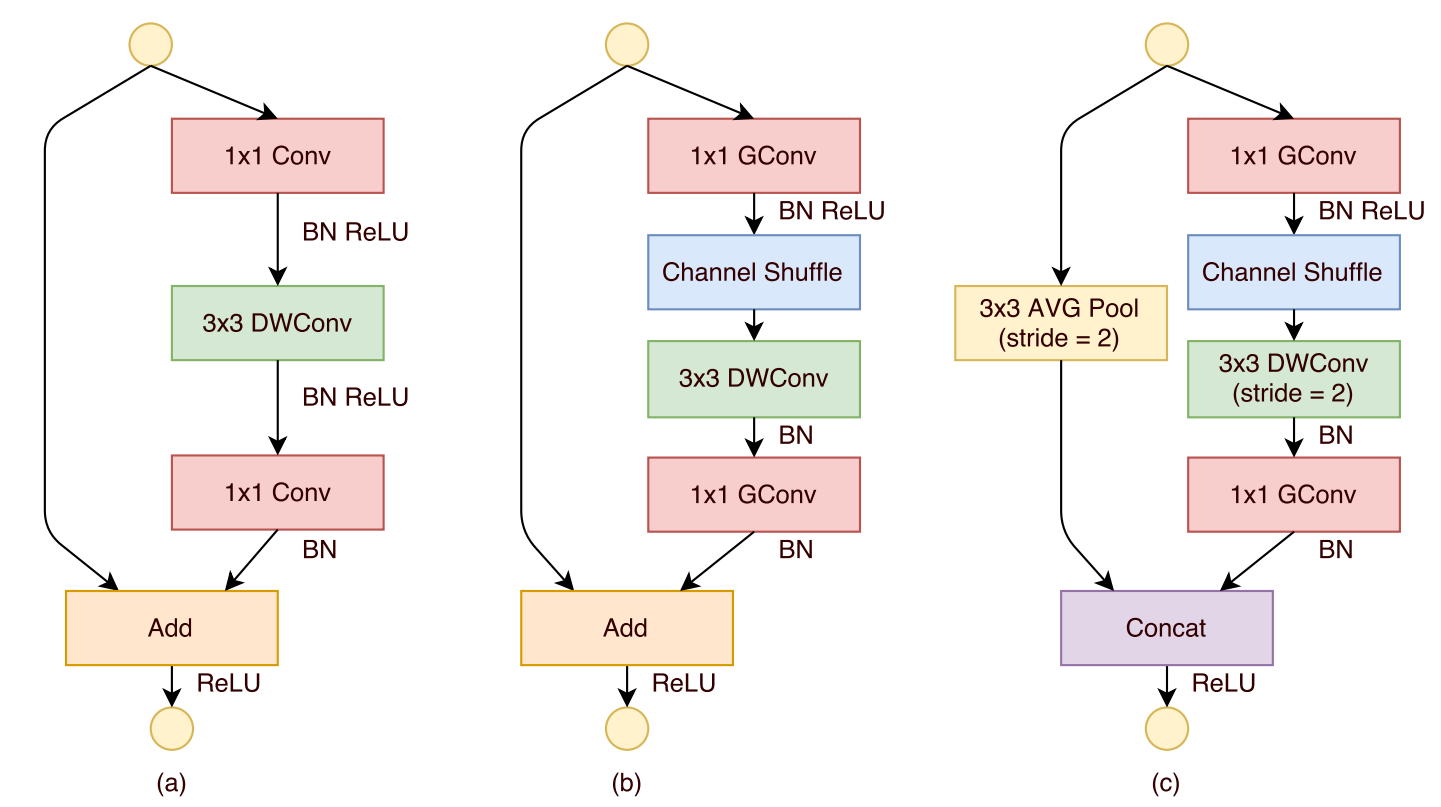
图(a)是一个典型的带有深度可分离卷积【参考】的残差结构,ShuffleNet_V1在此基础上设计出ShuffleNet单元。图(b)则是stride=1时的ShuffleNet单元,使用1x1分组卷积代替密集的1x1卷积,降低原1x1卷积的开销,同时加入Channel Shuffle实现跨通道信息交流。图(c)则是stride=2时的ShuffleNet单元,因为需要对特征图进行下采样,因此在图(b)结构基础上对残差连接分支采用stride=2的3x3全局平局池化,然后将主干输出特征和分支特征进行concat,而不再是add,大大的降低计算量与参数大小。
ShuffleNet_V1模型结构
下图是原论文给出的关于ShuffleNet_V1模型结构的详细示意图:

ShuffleNet_V1在图像分类中分为两部分:backbone部分: 主要由ShuffleNet基础单元、卷积层和池化层(汇聚层)组成,分类器部分:由全局池化层和全连接层组成 。
在ShuffleNet_V1基础单元中,组数g控制1×1卷积的连接稀疏性,在给定相同的参数量限制下,如果分组数g更大,那么网络的通道数可以更大,即分组数越大,则允许输出通道数越大,而网络参数可以大致不变。
ShuffleNet_V1 Pytorch代码
ShuffleNet Uint的组成部分: 首先使用1×1分组卷积进行降维,然后通道混洗后使用3×3深度卷积进行特征提取,最后在使用1×1分组卷积进行升维。
# 1×1卷积(降维/升维)
def conv1x1(in_chans, out_chans, n_groups=1):
return nn.Conv2d(in_chans, out_chans, kernel_size=1, stride=1, groups=n_groups)
# 3×3深度卷积
def conv3x3(in_chans, out_chans, stride, n_groups=1):
# Attention: no matter what the stride is, the padding will always be 1.
return nn.Conv2d(in_chans, out_chans, kernel_size=3, padding=1, stride=stride, groups=n_groups)
通道混洗: 更强的特征交互性和表达能力。
def channel_shuffle(x, n_groups):
# 获得特征图的所以维度的数据
batch_size, chans, height, width = x.shape
# 对特征通道进行分组
chans_group = chans // n_groups
# reshape新增特征图的维度
x = x.view(batch_size, n_groups, chans_group, height, width)
# 通道混洗(将输入张量的指定维度进行交换)
x = torch.transpose(x, 1, 2).contiguous()
# reshape降低特征图的维度
x = x.view(batch_size, -1, height, width)
return x
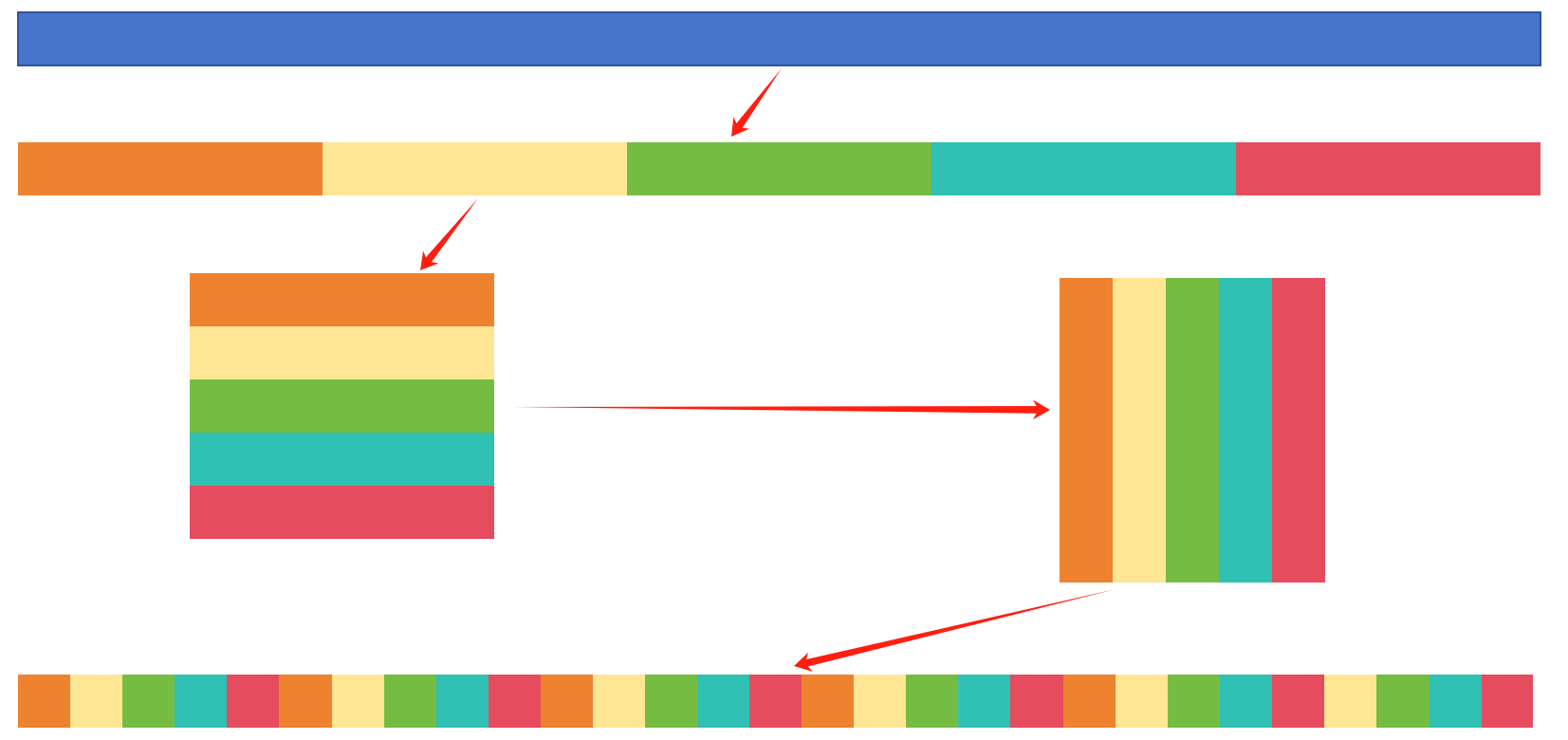
通道混洗的代码示意图如下图所示:
ShuffleNet Uint基础单元): 分组卷积层和深度可分离卷积层+BN层+激活函数
class ShuffleUnit(nn.Module):
def __init__(self, in_chans, out_chans, stride, n_groups=1):
super(ShuffleUnit, self).__init__()
# 1×1分组卷积降维后的维度
self.bottle_chans = out_chans // 4
# 分组卷积的分组数
self.n_groups = n_groups
# 是否进行下采样()
if stride == 1:
# 不进行下采样,分支和主干特征形状完全一致,直接执行add相加
self.end_op = 'Add'
self.out_chans = out_chans
elif stride == 2:
# 进行下采样,分支和主干特征形状不一致,分支也需进行下采样,而后再进行concat拼接
self.end_op = 'Concat'
self.out_chans = out_chans - in_chans
# 1×1卷积进行降维
self.unit_1 = nn.Sequential(conv1x1(in_chans, self.bottle_chans, n_groups=n_groups),
nn.BatchNorm2d(self.bottle_chans),
nn.ReLU())
# 3×3深度卷积进行特征提取
self.unit_2 = nn.Sequential(conv3x3(self.bottle_chans, self.bottle_chans, stride, n_groups=n_groups),
nn.BatchNorm2d(self.bottle_chans))
# 1×1卷积进行升维
self.unit_3 = nn.Sequential(conv1x1(self.bottle_chans, self.out_chans, n_groups=n_groups),
nn.BatchNorm2d(self.out_chans))
self.relu = nn.ReLU(inplace=True)
def forward(self, inp):
# 分支的处理方式(是否需要下采样)
if self.end_op == 'Add':
residual = inp
else:
residual = F.avg_pool2d(inp, kernel_size=3, stride=2, padding=1)
x = self.unit_1(inp)
x = channel_shuffle(x, self.n_groups)
x = self.unit_2(x)
x = self.unit_3(x)
# 分支与主干的融合方式
if self.end_op == 'Add':
return self.relu(residual + x)
else:
return self.relu(torch.cat((residual, x), 1))
完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
from collections import OrderedDict
from torchsummary import summary
# 1×1卷积(降维/升维)
def conv1x1(in_chans, out_chans, n_groups=1):
return nn.Conv2d(in_chans, out_chans, kernel_size=1, stride=1, groups=n_groups)
# 3×3深度卷积
def conv3x3(in_chans, out_chans, stride, n_groups=1):
# Attention: no matter what the stride is, the padding will always be 1.
return nn.Conv2d(in_chans, out_chans, kernel_size=3, padding=1, stride=stride, groups=n_groups)
def channel_shuffle(x, n_groups):
# 获得特征图的所以维度的数据
batch_size, chans, height, width = x.shape
# 对特征通道进行分组
chans_group = chans // n_groups
# reshape新增特征图的维度
x = x.view(batch_size, n_groups, chans_group, height, width)
# 通道混洗(将输入张量的指定维度进行交换)
x = torch.transpose(x, 1, 2).contiguous()
# reshape降低特征图的维度
x = x.view(batch_size, -1, height, width)
return x
class ShuffleUnit(nn.Module):
def __init__(self, in_chans, out_chans, stride, n_groups=1):
super(ShuffleUnit, self).__init__()
# 1×1分组卷积降维后的维度
self.bottle_chans = out_chans // 4
# 分组卷积的分组数
self.n_groups = n_groups
# 是否进行下采样()
if stride == 1:
# 不进行下采样,分支和主干特征形状完全一致,直接执行add相加
self.end_op = 'Add'
self.out_chans = out_chans
elif stride == 2:
# 进行下采样,分支和主干特征形状不一致,分支也需进行下采样,而后再进行concat拼接
self.end_op = 'Concat'
self.out_chans = out_chans - in_chans
# 1×1卷积进行降维
self.unit_1 = nn.Sequential(conv1x1(in_chans, self.bottle_chans, n_groups=n_groups),
nn.BatchNorm2d(self.bottle_chans),
nn.ReLU())
# 3×3深度卷积进行特征提取
self.unit_2 = nn.Sequential(conv3x3(self.bottle_chans, self.bottle_chans, stride, n_groups=n_groups),
nn.BatchNorm2d(self.bottle_chans))
# 1×1卷积进行升维
self.unit_3 = nn.Sequential(conv1x1(self.bottle_chans, self.out_chans, n_groups=n_groups),
nn.BatchNorm2d(self.out_chans))
self.relu = nn.ReLU(inplace=True)
def forward(self, inp):
# 分支的处理方式(是否需要下采样)
if self.end_op == 'Add':
residual = inp
else:
residual = F.avg_pool2d(inp, kernel_size=3, stride=2, padding=1)
x = self.unit_1(inp)
x = channel_shuffle(x, self.n_groups)
x = self.unit_2(x)
x = self.unit_3(x)
# 分支与主干的融合方式
if self.end_op == 'Add':
return self.relu(residual + x)
else:
return self.relu(torch.cat((residual, x), 1))
class ShuffleNetV1(nn.Module):
def __init__(self, n_groups, n_classes, stage_out_chans):
super(ShuffleNetV1, self).__init__()
# 输入通道
self.in_chans = 3
# 分组组数
self.n_groups = n_groups
# 分类个数
self.n_classes = n_classes
self.conv1 = conv3x3(self.in_chans, 24, 2)
self.maxpool = nn.MaxPool2d(3, 2, 1)
# Stage 2
op = OrderedDict()
unit_prefix = 'stage_2_unit_'
# 每个Stage的首个基础单元都需要进行下采样,其他单元不需要
op[unit_prefix+'0'] = ShuffleUnit(24, stage_out_chans[0], 2, self.n_groups)
for i in range(3):
op[unit_prefix+str(i+1)] = ShuffleUnit(stage_out_chans[0], stage_out_chans[0], 1, self.n_groups)
self.stage2 = nn.Sequential(op)
# Stage 3
op = OrderedDict()
unit_prefix = 'stage_3_unit_'
op[unit_prefix+'0'] = ShuffleUnit(stage_out_chans[0], stage_out_chans[1], 2, self.n_groups)
for i in range(7):
op[unit_prefix+str(i+1)] = ShuffleUnit(stage_out_chans[1], stage_out_chans[1], 1, self.n_groups)
self.stage3 = nn.Sequential(op)
# Stage 4
op = OrderedDict()
unit_prefix = 'stage_4_unit_'
op[unit_prefix+'0'] = ShuffleUnit(stage_out_chans[1], stage_out_chans[2], 2, self.n_groups)
for i in range(3):
op[unit_prefix+str(i+1)] = ShuffleUnit(stage_out_chans[2], stage_out_chans[2], 1, self.n_groups)
self.stage4 = nn.Sequential(op)
# 全局平局池化
self.global_pool =nn.AdaptiveAvgPool2d((1, 1))
# 全连接层
self.fc = nn.Linear(stage_out_chans[-1], self.n_classes)
# 权重初始化
self.init_params()
# 权重初始化
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.global_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 不同分组数对应的通道数也不同
stage_out_chans_list = [[144, 288, 576], [200, 400, 800], [240, 480, 960],
[272, 544, 1088], [384, 768, 1536]]
def shufflenet_v1_groups1(n_groups=1, n_classes=1000):
model = ShuffleNetV1(n_groups=n_groups, n_classes=n_classes, stage_out_chans=stage_out_chans_list[n_groups-1])
return model
def shufflenet_v1_groups2(n_groups=2, n_classes=1000):
model = ShuffleNetV1(n_groups=n_groups, n_classes=n_classes, stage_out_chans=stage_out_chans_list[n_groups-1])
return model
def shufflenet_v1_groups3(n_groups=3, n_classes=1000):
model = ShuffleNetV1(n_groups=n_groups, n_classes=n_classes, stage_out_chans=stage_out_chans_list[n_groups-1])
return model
def shufflenet_v1_groups4(n_groups=4, n_classes=1000):
model = ShuffleNetV1(n_groups=n_groups, n_classes=n_classes, stage_out_chans=stage_out_chans_list[n_groups-1])
return model
def shufflenet_v1_groupsother(n_groups=5, n_classes=1000):
# groups>4
model = ShuffleNetV1(n_groups=n_groups, n_classes=n_classes, stage_out_chans=stage_out_chans_list[-1])
return model
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = shufflenet_v1_groups1().to(device)
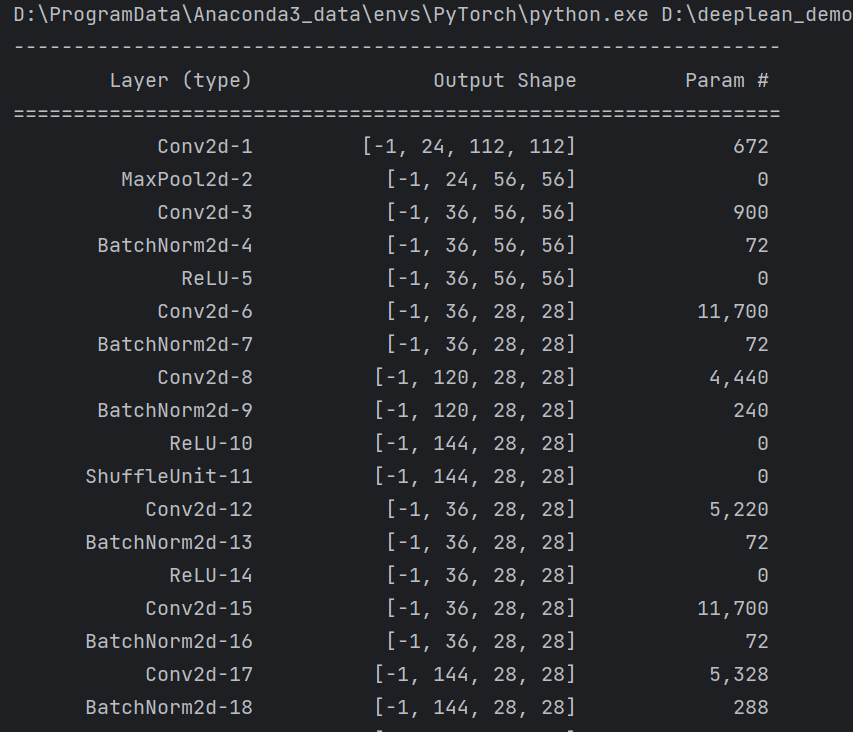
summary(model, input_size=(3, 224, 224))
summary可以打印网络结构和参数,方便查看搭建好的网络结构。
总结
尽可能简单、详细的介绍了分组卷积通道混洗的原理和过程,讲解了ShuffleNet_V1模型的结构和pytorch代码。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!