3_并发编程可见性(volatile)之缓存锁内存屏障过程
并发编程可见性volatile
1.背景原来
从下面的程序可以知道main线程把stop修改成false,而在t1线程没有中没有读取到stop值为false,所以导致了t1线程不能够停止。
从而说明stop值在线程t1不可见,解决这个问题在stop变量上添加volatile即可(public static volatile boolean stop = true;)
public class VolatileDemo {
public static boolean stop=true;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
//t1线程执行
int i=0;
while(!stop){
i++;
}
});
t1.start();
//main主线程执行的
System.out.println("begin start thread");
Thread.sleep(1000);
stop=false;
}
}
// 结果:t1线程并没有按照期望的结果执行,而是一值执行

并发编程可见性volatile
1.背景原来
从下面的程序可以知道main线程把stop修改成false,而在t1线程没有中没有读取到stop值为false,所以导致了t1线程不能够停止。
从而说明stop值在线程t1不可见,解决这个问题在stop变量上添加volatile即可(public static volatile boolean stop = true;)
public class VolatileDemo {
public static boolean stop=true;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
//t1线程执行
int i=0;
while(!stop){
i++;
}
});
t1.start();
//main主线程执行的
System.out.println("begin start thread");
Thread.sleep(1000);
stop=false;
}
}
// 结果:t1线程并没有按照期望的结果执行,而是一值执行
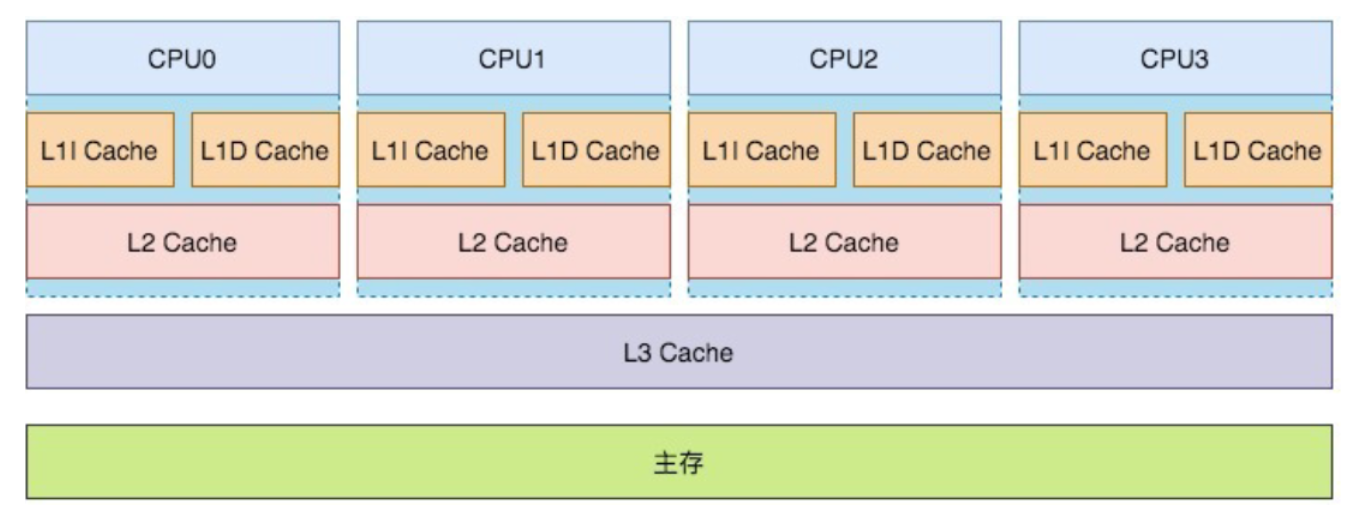
在整个计算机的发展历程中,除了CPU、内存以及I/O设备不断迭代升级来提升计算机处理性能之外,还有一个非常核心的矛盾点,就是这三者在处理速度的差异。如果内存和磁盘的处理性能没有跟上,就意味着整体的计算效率取决于最慢的设备,为了平衡这三者之间的速度差异,最大化的利用CPU。所以在硬件层面、操作系统层面、编译器层面做出了很多的优化。
- CPU增加了高速缓存
- 操作系统增加了进程、线程。通过CPU的时间片切换最大化的提升CPU的使用率
- 编译器的指令优化,更合理的去利用好CPU的高速缓存
2.基本使用
public class VolatileExample {
public volatile static boolean stop=true;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
int i=0;
while(stop){
i++;
}
});
t1.start();
System.out.println("begin start thread");
Thread.sleep(1000);
stop=false;
}
}
// 结果(程序可以正常结束):begin start thread
3.注意事项
4.底层原理
4.1 高速缓存
这个缓存行可以缓存存储在内存中的数据,CPU每次会先从缓存行中读取需要运算的数据,如果缓存行中不存在该数据,才会从内存中加载,通过
这样一个机制可以减少CPU和内存的交互开销从而提升CPU的利用率。cpu的缓存行(cache)分为L1、L2、L3总共3级, 其中L3缓存是共享.
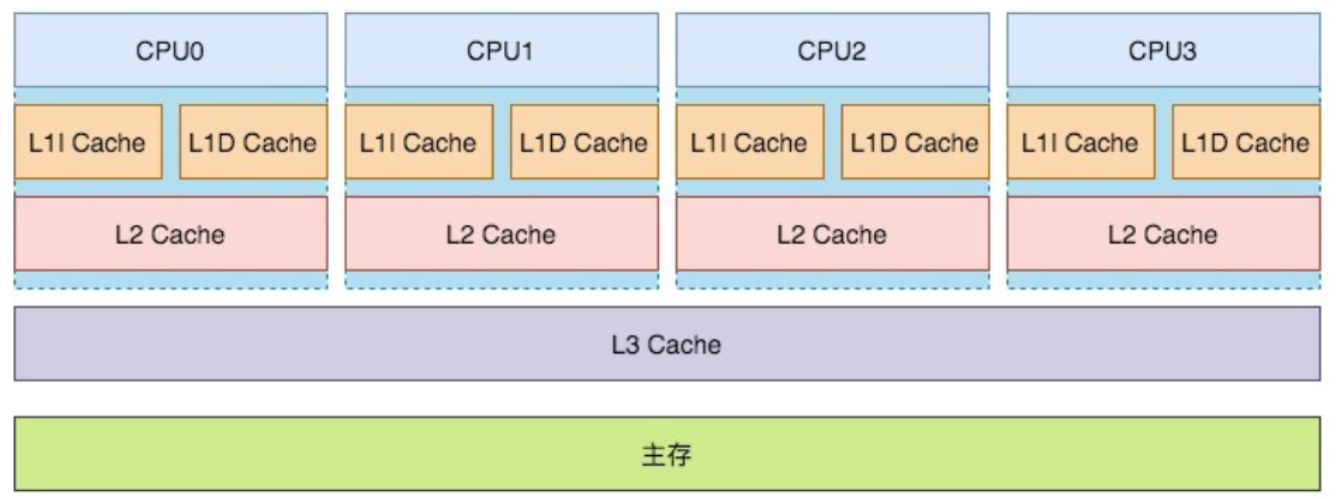
4.2 缓存行
cup缓存是由缓存行主成的,缓存行是cup中最小单元。
伪共享问题?
下图:内存的xyz数据被cpu一次加载到一个缓存行中,这时线程core0读取缓存行中的X值,core1读取缓存行中Y值,正好X和Y值正好在一个缓存行中。就会2个线程存在竞争,当core0线程抢到,就会是core1缓存失效。这样来回就会影响性能。xyz中的缓存一个缓存行中,就存在伪共享,缓存行就会失效。所以缓存行中的数据,使用对齐填充来解决。
对齐填充:(解决缓存行伪共享)
对齐填充是以空间换时间,使数据存在一个缓存行中,不足使用对齐填充。这样cup之间就不存在抢一个缓存行的数据,导致cup之间数据来回失效,从而提供了cup性能。
java8中使用 @Contended注解,来实现缓存填充。jvm需要参数:-XX:RestrictContended
4.3 缓存一致性
有了高速缓存后,就会出现出现缓存一致性问题,如下图:flag=false是初始值,当cup0和cpu1同时读取缓存值后,cpu0修改为flag为true,这时cpu1中的false不知道什么时候能读取到falg为true,这时就会出现缓存一致问题?
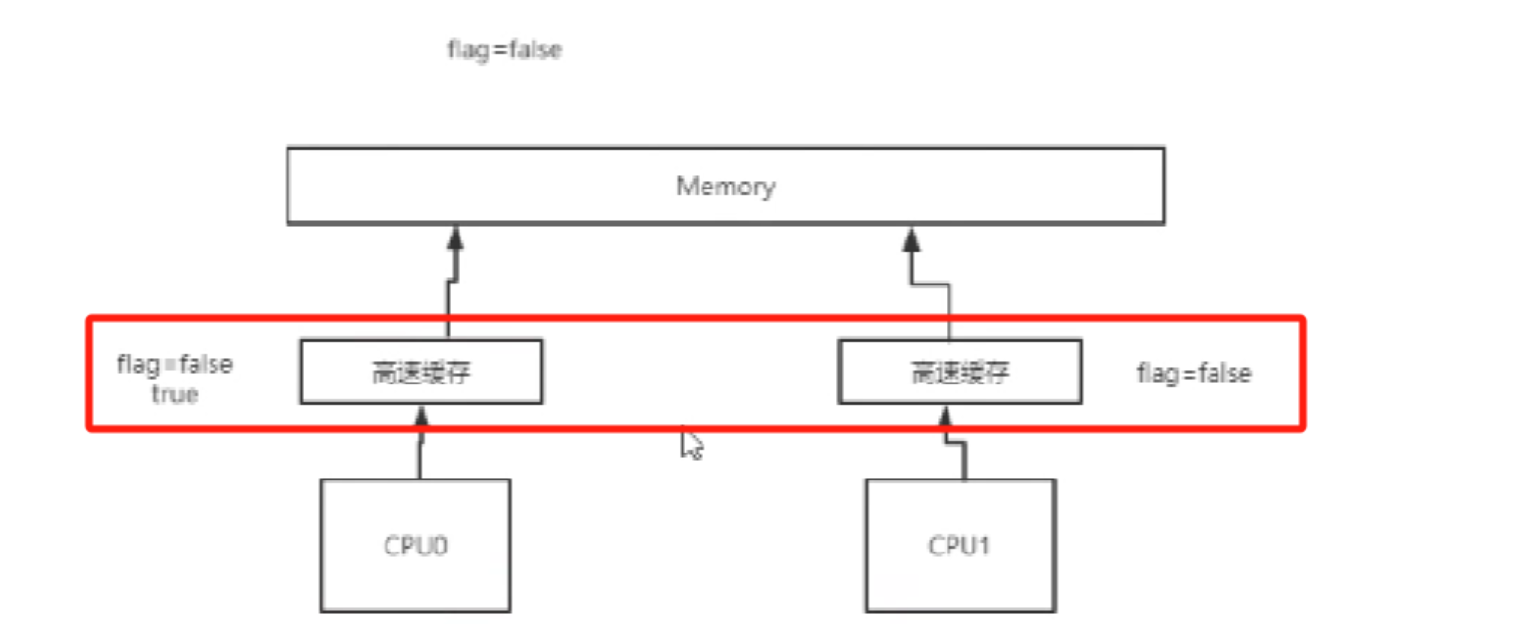

解决缓存一致性引入
总线锁:【加载上面图的Bus上,这样就大大降低的cpu性能】
缓存锁:【x=20加缓存锁】
缓存一致性协议(MESI,MOSI)
MESI 有4种状态 [m修改缓存 i失效缓存 e独占缓存 s共享缓存 ]

cpu缓存中有一个Snoopy嗅探器,来监视缓存的状态,并通知其他cup。
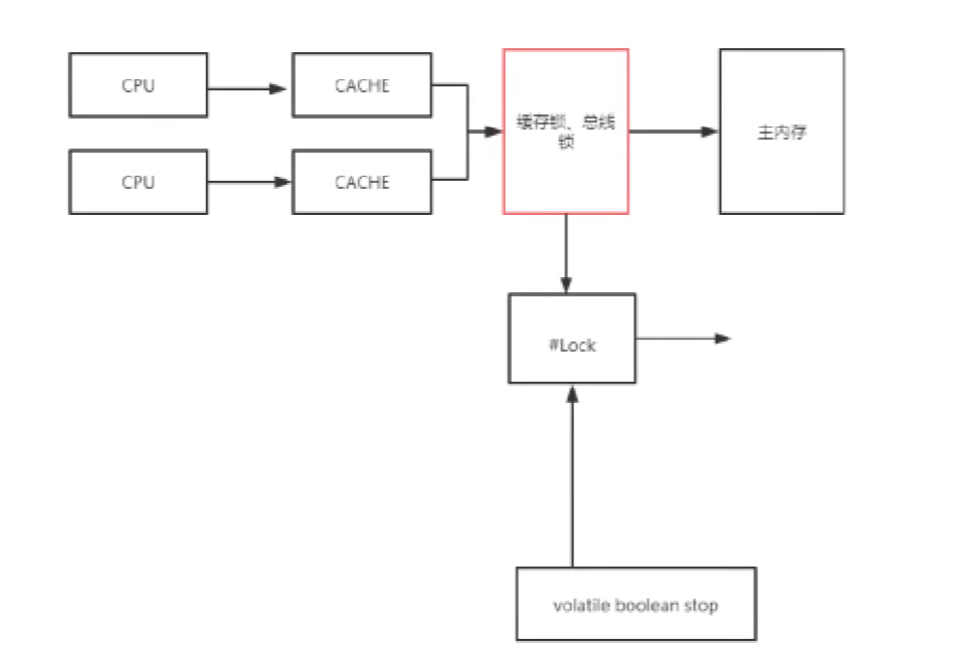
cup访问–> 缓存-> 缓存锁,总线锁 --> 主存
volatie --> #lock --> 缓存锁,总线锁
4.4 cup指令重排序
public class SeqExample {
private volatile static int x=0,y=0;
private volatile static int a=0,b=0;
public static void main(String[] args) throws InterruptedException {
int i=0;
for(;;){
i++;
x=0;y=0;
a=0;b=0;
Thread t1=new Thread(()->{
a=1;
x=b;
//
x=b;
a=1;
});
Thread t2=new Thread(()->{
b=1;
y=a;
//
y=a;
b=1;
});
t1.start();
t2.start();
t1.join();
t2.join();
String result="第"+i+"次("+x+","+y+")";
if(x==0&&y==0){
System.out.println(result);
break;
}else{
}
}
}
}
// 结果:第3243次(0,0);
//分析:就会出现指令从排序
Thread t1=new Thread(()->{
a=1;
x=b;
//变成下面执行顺序
x=b;
a=1;
});
Thread t2=new Thread(()->{
b=1;
y=a;
//变成下面执行顺序
y=a;
b=1;
});
cpu如何导致指令重排序?
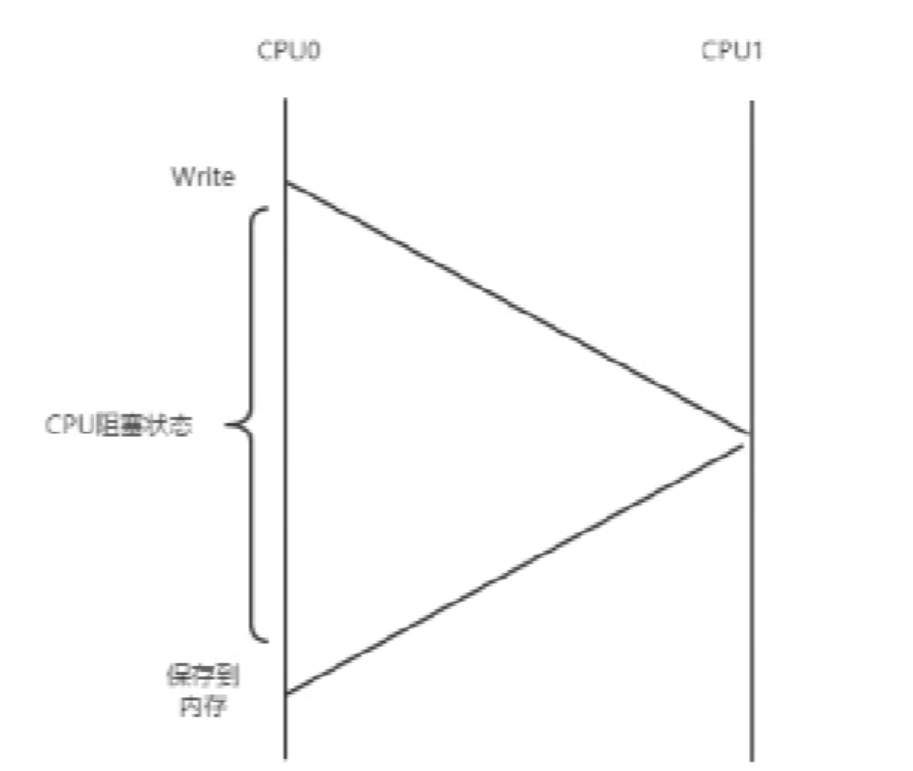
cpu0写数据到保存到内存,这里会议缓存失效,从而使用cpu阻塞状态或空闲状态。

4.5 storebuffer
下图:cpu阻塞状态优化引入一个storebuffer, 异步处理。当cpu0读一个缓存数据后,发现缓存数据失效了,就放到storebuffer中。继续执行下面代码,直到cpu1执行这个为缓存数据为可以读到缓存数据,然后通知cpu0后面再把缓存失效数据处理写到内存中。–》这边就cpu就会出现cpu指令重排。
int a =0;
function(){
a=1;
b=a+1;
assert(b==2);//false 断言
}
//false就出现,指令重排序
b=a+1;
a=1;
下图:过程图解
cpu0 把a=1放到storebuffer中,因为cpu1把a=1失效了
cpu0 把内存a=0读到独占缓存中
cpu0 把内存b=0读到独占缓存中
cup0 把b=a+1,b=1修改为写缓存中
cpu0收到cpu1[responese invalidat ack],把soter buffer中a=1读到 ,这个时候 a=1; b=1; 导致b==2为false

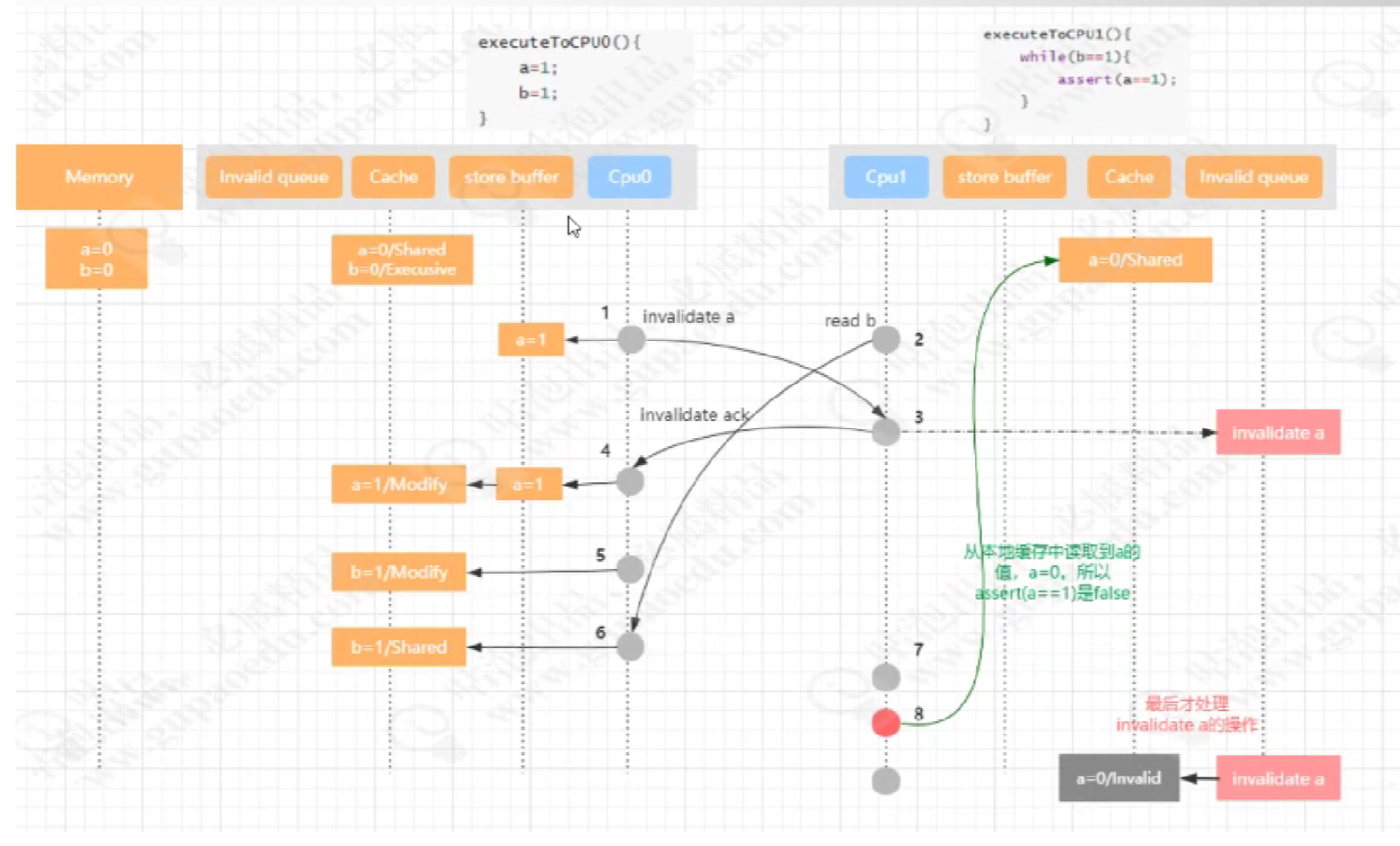
4.6 Store Forwarding
int a=0,b=0;
executeToCpu0(){
a=1;
b=1;
}
executeToCpu1(){
while(b==1){
assert(a==1);
}
}
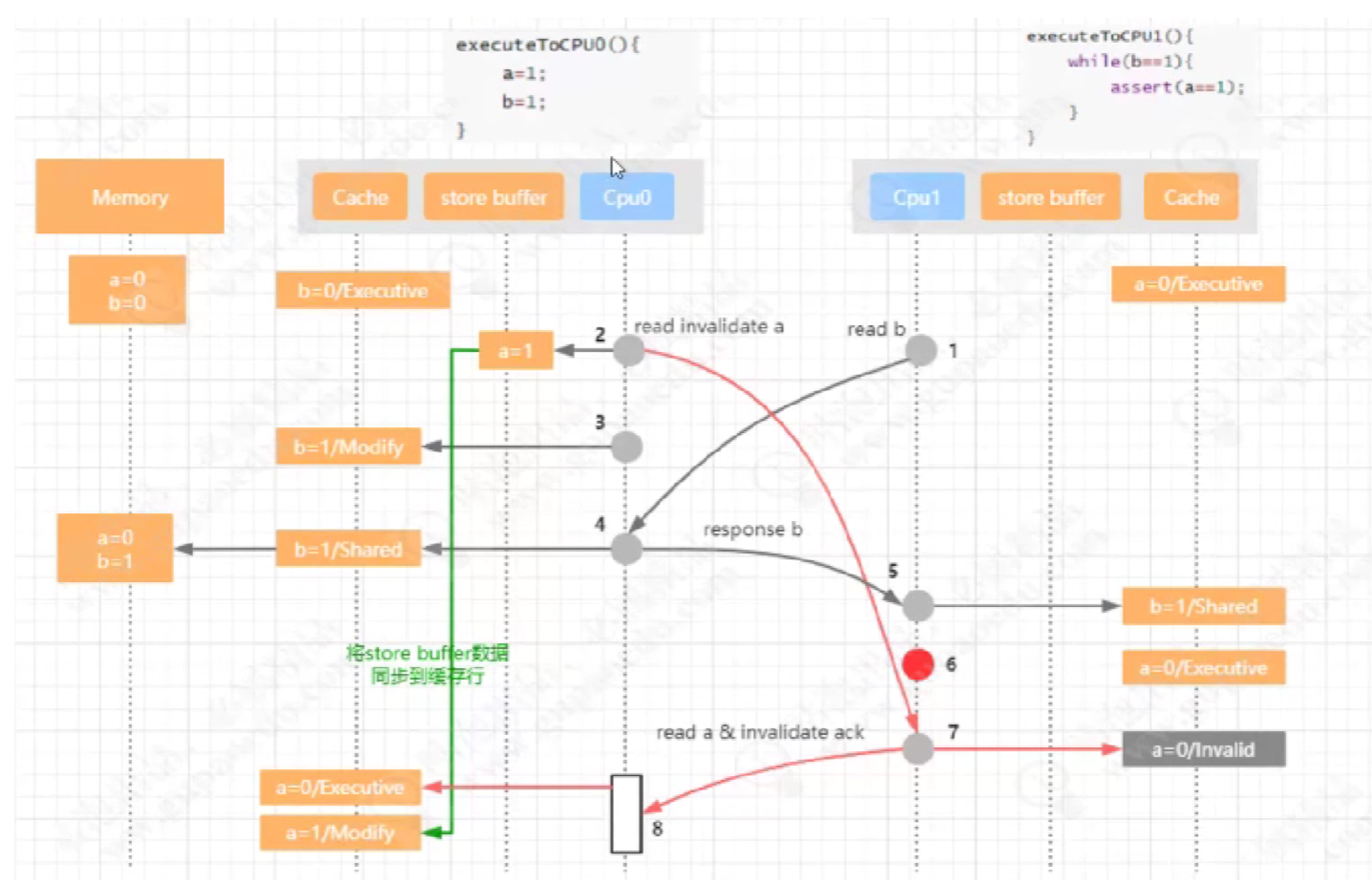
下图:

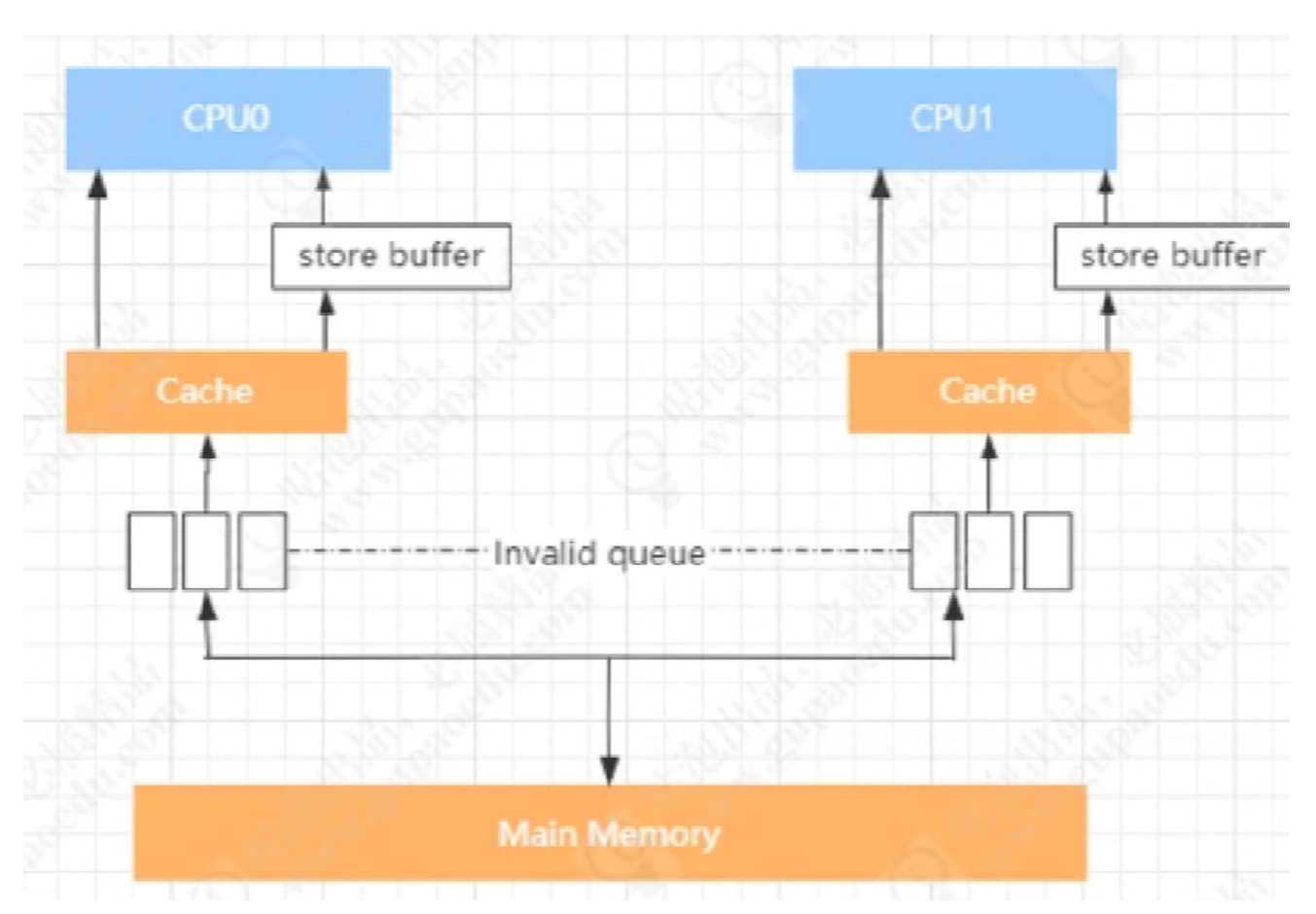
4.9 失效队列

1步骤中 cpu0写a=1时通知,
2步骤cpu1写b=1。
6步骤 读内存数据并放到cpu0共享缓存中
3步骤 cpu1中a缓存值失效,这时cpu1直接把值存到失效队列
4步骤 然后返回invalidate ack给cpu0
5步骤 cpu0把b=1变成可改缓存状态
7步骤 cpu1 b==1 为true
8步骤 cpu1 a=0 共享状态
最后才把失效队列中的a=0设置成失效缓存。

4.8 内存屏障
#lock指令可以解决 : 缓存锁/总线锁和内存屏障的问题
CPU在性能优化道路上导致的顺序一致性问题,在CPU层面无法被解决,原因是CPU只是一个运算工
具,它只接收指令并且执行指令,并不清楚当前执行的整个逻辑中是否存在不能优化的问题,也就是说
硬件层面也无法优化这种顺序一致性带来的可见性问题。
因此,在CPU层面提供了写屏障、读屏障、全屏障这样的指令,在x86架构中,这三种指令分别是SFENCE、LFENCE、MFENCE指令,
sfence:也就是save fence,写屏障指令。在sfence指令前的写操作必须在sfence指令后的写操作前完成。
lfence:也就是load fence,读屏障指令。在lfence指令前的读操作必须在lfence指令后的读操作前完成。
mfence:也就是modify/mix,混合屏障指令,在mfence前得读写操作必须在mfence指令后的读写操作前完成。
在Linux系统中,将这三种指令分别封装成了, smp_wmb-写屏障 、 smp_rmb-读屏障 、 smp_mb-读写屏障 三个方法
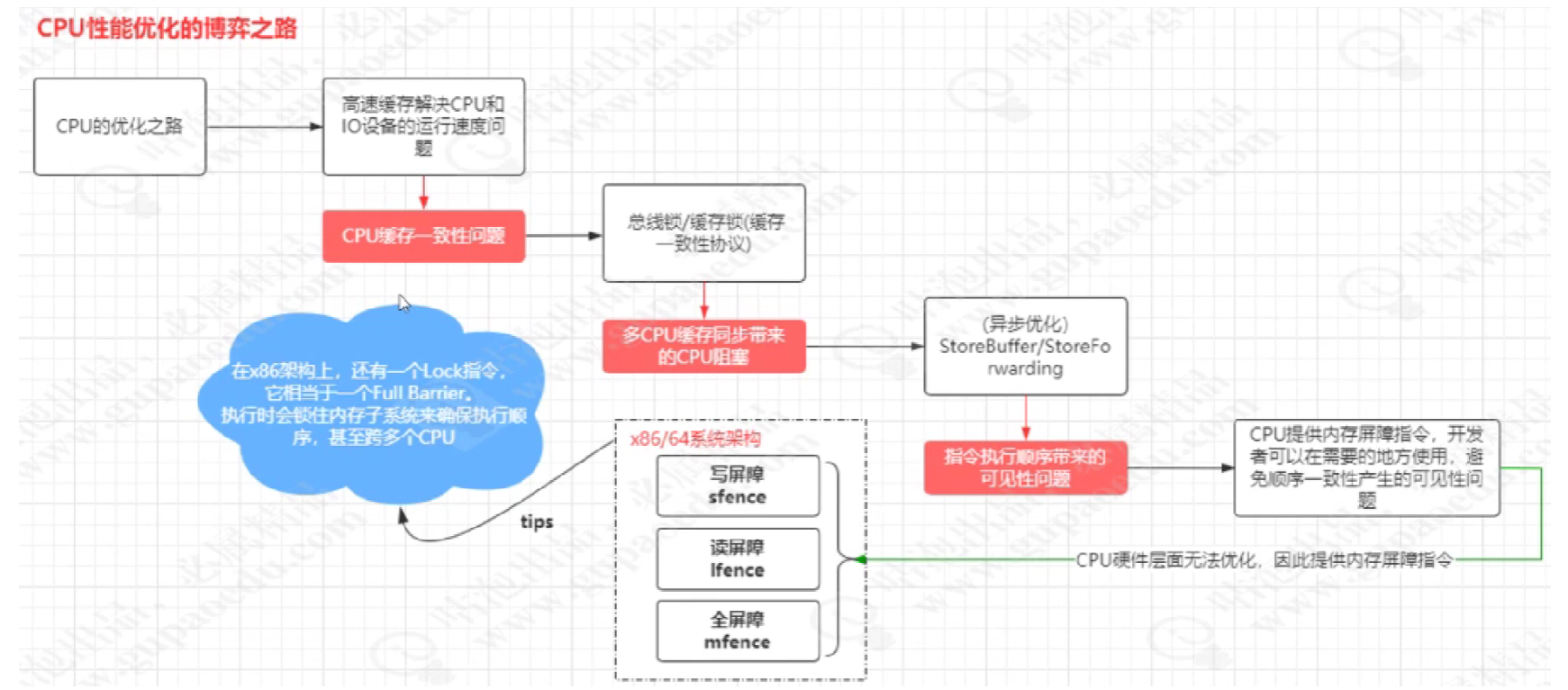
4.9 cup性能优化的过程

5.技术关联性
简单说一下volitale的认识
1.解决多线程下变量的可见性问题的。
2.解决过程中用到内存屏障 和 缓存锁和总线锁。
3.内存屏障是指在cup执行指令并处理指令过程中,不知道这些指令逻辑关系,只能有开发者知道,所以开发者在相关的地方可能发现指令重排序加上对于写屏障读屏障全屏障。
4.缓存锁有storebuffer 和 Store Forwarding ,总线锁是在cpu 高速缓存L3级缓存上加锁。
5.storebuffer 是在cup写缓存数据异步通知其他cup对于缓存值失效,并返回ack, 提高了cup的性能。
6.Store Forwarding是在storebuffer 是在cup写缓存数据异步通知其他cup对于缓存值失效,直接放到失效队列中。缩短了等待缓存值失效返回ack时间。
在整个计算机的发展历程中,除了CPU、内存以及I/O设备不断迭代升级来提升计算机处理性能之外,还有一个非常核心的矛盾点,就是这三者在处理速度的差异。如果内存和磁盘的处理性能没有跟上,就意味着整体的计算效率取决于最慢的设备,为了平衡这三者之间的速度差异,最大化的利用CPU。所以在硬件层面、操作系统层面、编译器层面做出了很多的优化。
- CPU增加了高速缓存
- 操作系统增加了进程、线程。通过CPU的时间片切换最大化的提升CPU的使用率
- 编译器的指令优化,更合理的去利用好CPU的高速缓存
2.基本使用
public class VolatileExample {
public volatile static boolean stop=true;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
int i=0;
while(stop){
i++;
}
});
t1.start();
System.out.println("begin start thread");
Thread.sleep(1000);
stop=false;
}
}
// 结果(程序可以正常结束):begin start thread
3.注意事项
4.底层原理
4.1 高速缓存
这个缓存行可以缓存存储在内存中的数据,CPU每次会先从缓存行中读取需要运算的数据,如果缓存行中不存在该数据,才会从内存中加载,通过
这样一个机制可以减少CPU和内存的交互开销从而提升CPU的利用率。cpu的缓存行(cache)分为L1、L2、L3总共3级, 其中L3缓存是共享.
4.2 缓存行
cup缓存是由缓存行主成的,缓存行是cup中最小单元。
伪共享问题?
下图:内存的xyz数据被cpu一次加载到一个缓存行中,这时线程core0读取缓存行中的X值,core1读取缓存行中Y值,正好X和Y值正好在一个缓存行中。就会2个线程存在竞争,当core0线程抢到,就会是core1缓存失效。这样来回就会影响性能。xyz中的缓存一个缓存行中,就存在伪共享,缓存行就会失效。所以缓存行中的数据,使用对齐填充来解决。
对齐填充:(解决缓存行伪共享)
对齐填充是以空间换时间,使数据存在一个缓存行中,不足使用对齐填充。这样cup之间就不存在抢一个缓存行的数据,导致cup之间数据来回失效,从而提供了cup性能。
java8中使用 @Contended注解,来实现缓存填充。jvm需要参数:-XX:RestrictContended
4.3 缓存一致性
有了高速缓存后,就会出现出现缓存一致性问题,如下图:flag=false是初始值,当cup0和cpu1同时读取缓存值后,cpu0修改为flag为true,这时cpu1中的false不知道什么时候能读取到falg为true,这时就会出现缓存一致问题?
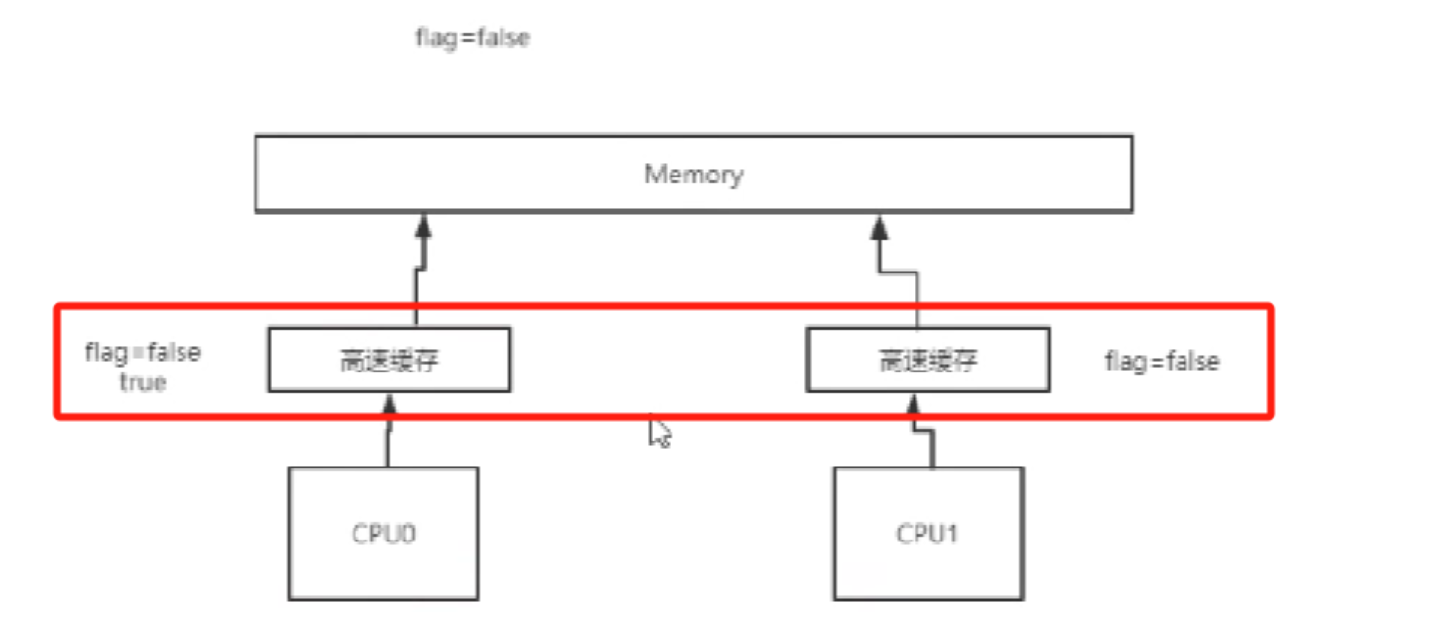
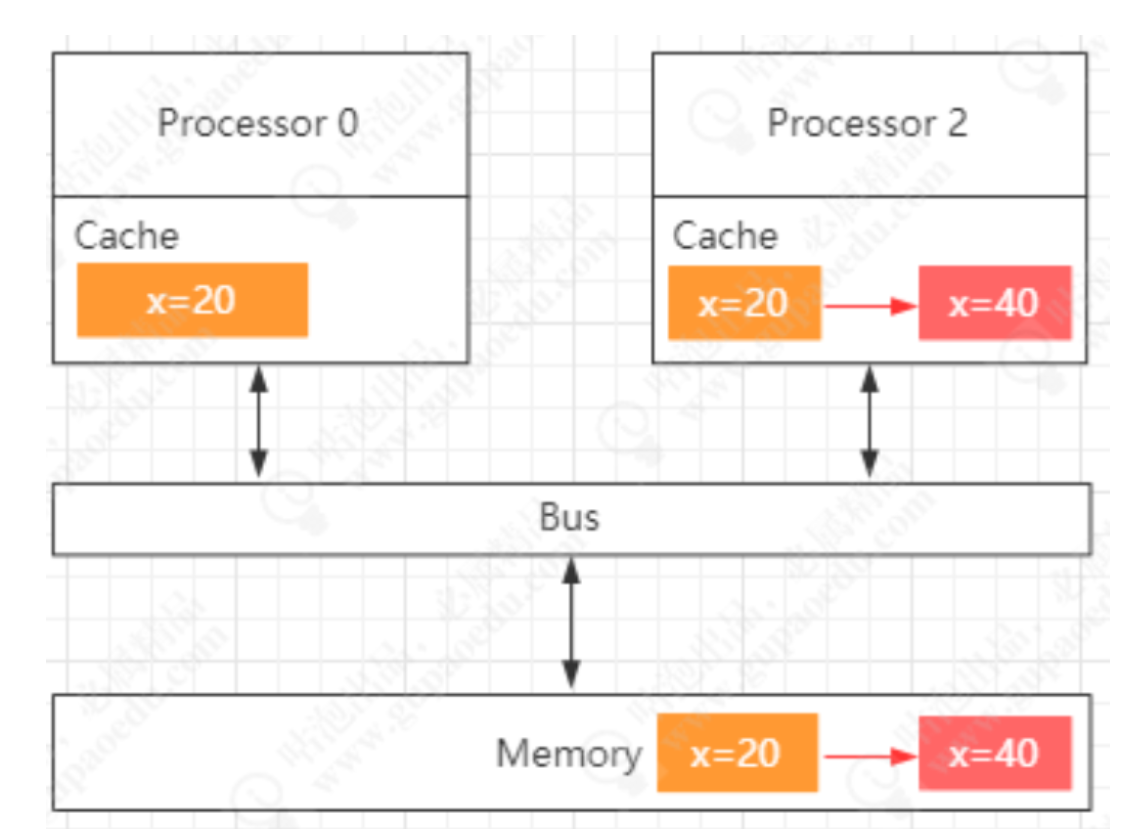
解决缓存一致性引入
总线锁:【加载上面图的Bus上,这样就大大降低的cpu性能】
缓存锁:【x=20加缓存锁】
缓存一致性协议(MESI,MOSI)
MESI 有4种状态 [m修改缓存 i失效缓存 e独占缓存 s共享缓存 ]
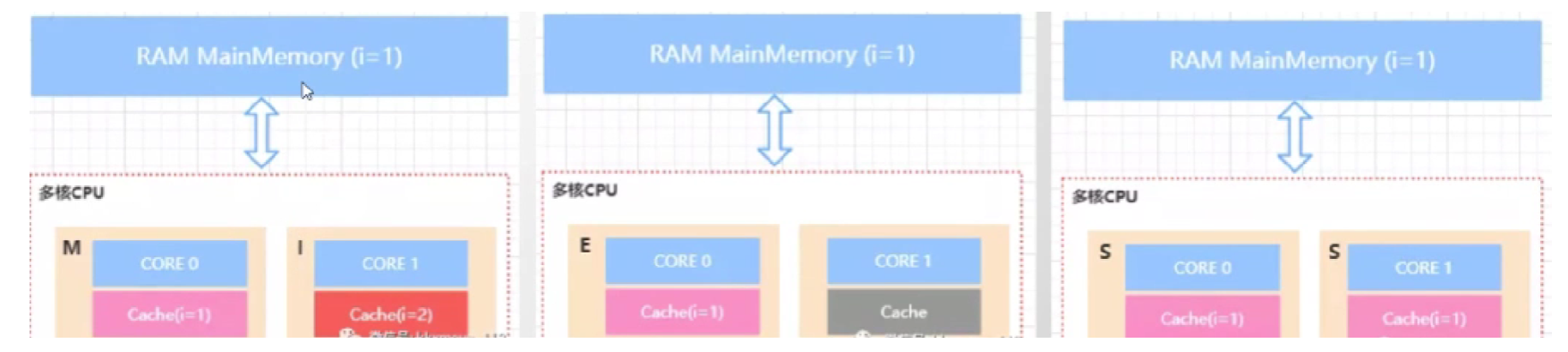
cpu缓存中有一个Snoopy嗅探器,来监视缓存的状态,并通知其他cup。
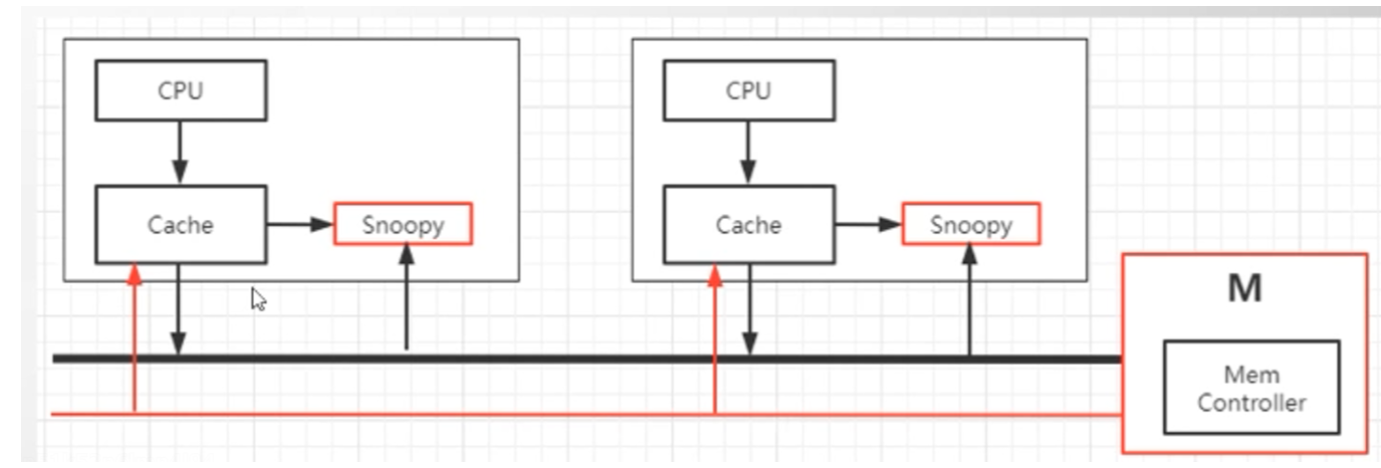
cup访问–> 缓存-> 缓存锁,总线锁 --> 主存
volatie --> #lock --> 缓存锁,总线锁
4.4 cup指令重排序
public class SeqExample {
private volatile static int x=0,y=0;
private volatile static int a=0,b=0;
public static void main(String[] args) throws InterruptedException {
int i=0;
for(;;){
i++;
x=0;y=0;
a=0;b=0;
Thread t1=new Thread(()->{
a=1;
x=b;
//
x=b;
a=1;
});
Thread t2=new Thread(()->{
b=1;
y=a;
//
y=a;
b=1;
});
t1.start();
t2.start();
t1.join();
t2.join();
String result="第"+i+"次("+x+","+y+")";
if(x==0&&y==0){
System.out.println(result);
break;
}else{
}
}
}
}
// 结果:第3243次(0,0);
//分析:就会出现指令从排序
Thread t1=new Thread(()->{
a=1;
x=b;
//变成下面执行顺序
x=b;
a=1;
});
Thread t2=new Thread(()->{
b=1;
y=a;
//变成下面执行顺序
y=a;
b=1;
});
cpu如何导致指令重排序?
cpu0写数据到保存到内存,这里会议缓存失效,从而使用cpu阻塞状态或空闲状态。
4.5 storebuffer
下图:cpu阻塞状态优化引入一个storebuffer, 异步处理。当cpu0读一个缓存数据后,发现缓存数据失效了,就放到storebuffer中。继续执行下面代码,直到cpu1执行这个为缓存数据为可以读到缓存数据,然后通知cpu0后面再把缓存失效数据处理写到内存中。–》这边就cpu就会出现cpu指令重排。
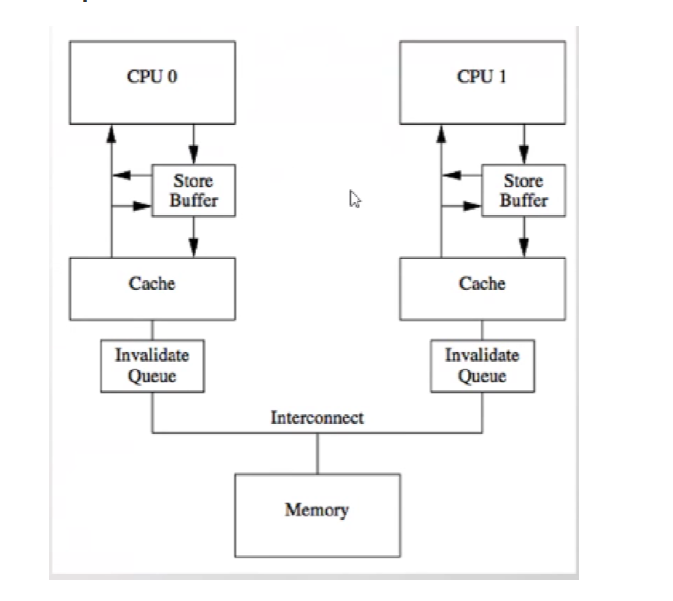
int a =0;
function(){
a=1;
b=a+1;
assert(b==2);//false 断言
}
//false就出现,指令重排序
b=a+1;
a=1;
下图:过程图解
cpu0 把a=1放到storebuffer中,因为cpu1把a=1失效了
cpu0 把内存a=0读到独占缓存中
cpu0 把内存b=0读到独占缓存中
cup0 把b=a+1,b=1修改为写缓存中
cpu0收到cpu1[responese invalidat ack],把soter buffer中a=1读到 ,这个时候 a=1; b=1; 导致b==2为false
4.6 Store Forwarding
int a=0,b=0;
executeToCpu0(){
a=1;
b=1;
}
executeToCpu1(){
while(b==1){
assert(a==1);
}
}
下图:
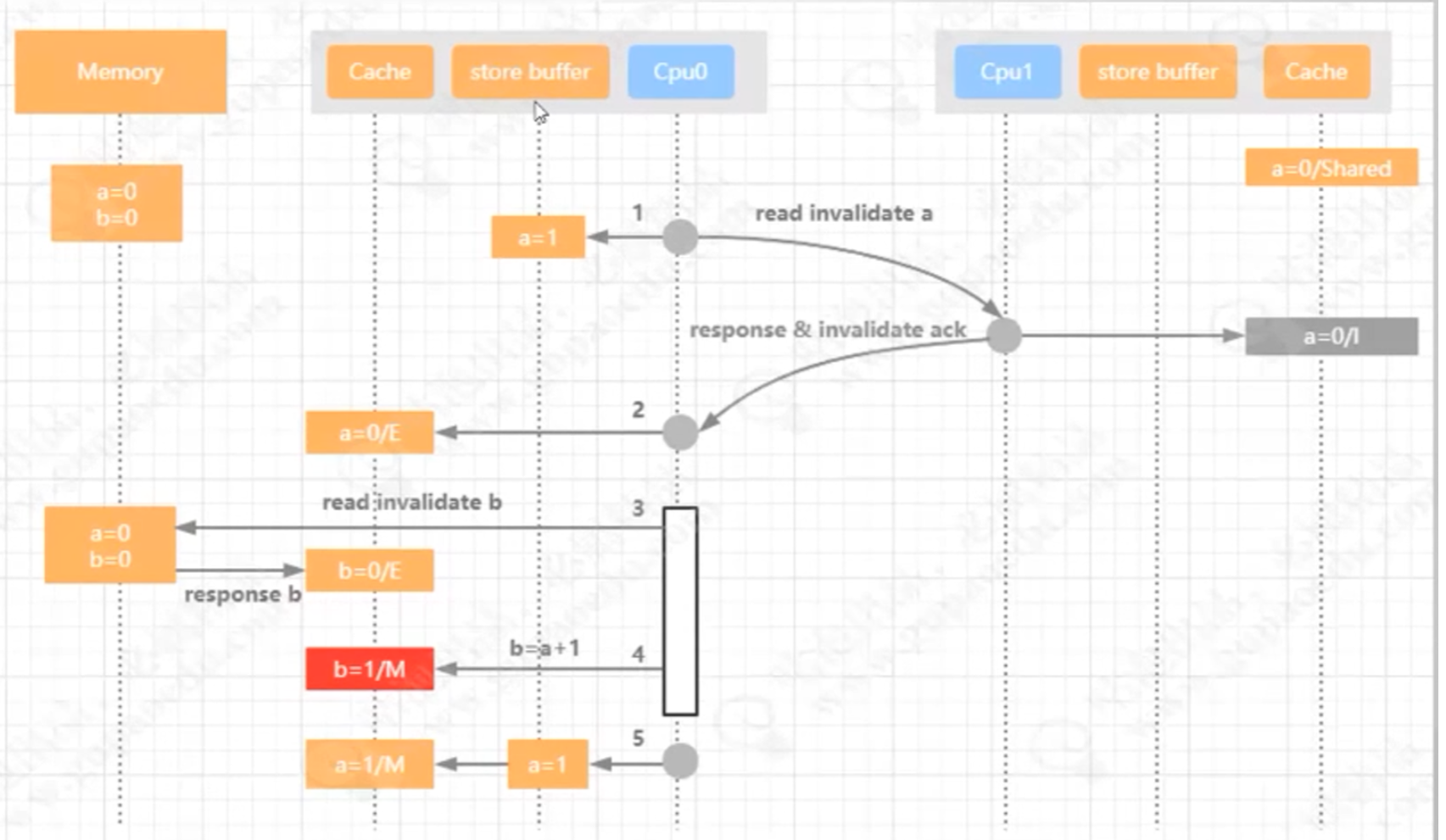
4.9 失效队列
1步骤中 cpu0写a=1时通知,
2步骤cpu1写b=1。
6步骤 读内存数据并放到cpu0共享缓存中
3步骤 cpu1中a缓存值失效,这时cpu1直接把值存到失效队列
4步骤 然后返回invalidate ack给cpu0
5步骤 cpu0把b=1变成可改缓存状态
7步骤 cpu1 b==1 为true
8步骤 cpu1 a=0 共享状态
最后才把失效队列中的a=0设置成失效缓存。
4.8 内存屏障
#lock指令可以解决 : 缓存锁/总线锁和内存屏障的问题
CPU在性能优化道路上导致的顺序一致性问题,在CPU层面无法被解决,原因是CPU只是一个运算工
具,它只接收指令并且执行指令,并不清楚当前执行的整个逻辑中是否存在不能优化的问题,也就是说
硬件层面也无法优化这种顺序一致性带来的可见性问题。
因此,在CPU层面提供了写屏障、读屏障、全屏障这样的指令,在x86架构中,这三种指令分别是SFENCE、LFENCE、MFENCE指令,
sfence:也就是save fence,写屏障指令。在sfence指令前的写操作必须在sfence指令后的写操作前完成。
lfence:也就是load fence,读屏障指令。在lfence指令前的读操作必须在lfence指令后的读操作前完成。
mfence:也就是modify/mix,混合屏障指令,在mfence前得读写操作必须在mfence指令后的读写操作前完成。
在Linux系统中,将这三种指令分别封装成了, smp_wmb-写屏障 、 smp_rmb-读屏障 、 smp_mb-读写屏障 三个方法
4.9 cup性能优化的过程
5.技术关联性
简单说一下volitale的认识
1.解决多线程下变量的可见性问题的。
2.解决过程中用到内存屏障 和 缓存锁和总线锁。
3.内存屏障是指在cup执行指令并处理指令过程中,不知道这些指令逻辑关系,只能有开发者知道,所以开发者在相关的地方可能发现指令重排序加上对于写屏障读屏障全屏障。
4.缓存锁有storebuffer 和 Store Forwarding ,总线锁是在cpu 高速缓存L3级缓存上加锁。
5.storebuffer 是在cup写缓存数据异步通知其他cup对于缓存值失效,并返回ack, 提高了cup的性能。
6.Store Forwarding是在storebuffer 是在cup写缓存数据异步通知其他cup对于缓存值失效,直接放到失效队列中。缩短了等待缓存值失效返回ack时间。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!