Python网络爬虫环境的安装指南
2023-12-13 03:27:07
????? 网络爬虫是一种自动化的网页数据抓取技术,广泛用于数据挖掘、信息搜集和互联网研究等领域。Python作为一种强大的编程语言,拥有丰富的库支持网络爬虫的开发。本文将为你详细介绍如何在你的计算机上安装Python网络爬虫环境。
一、安装python开发环境
进去官网www.python.org
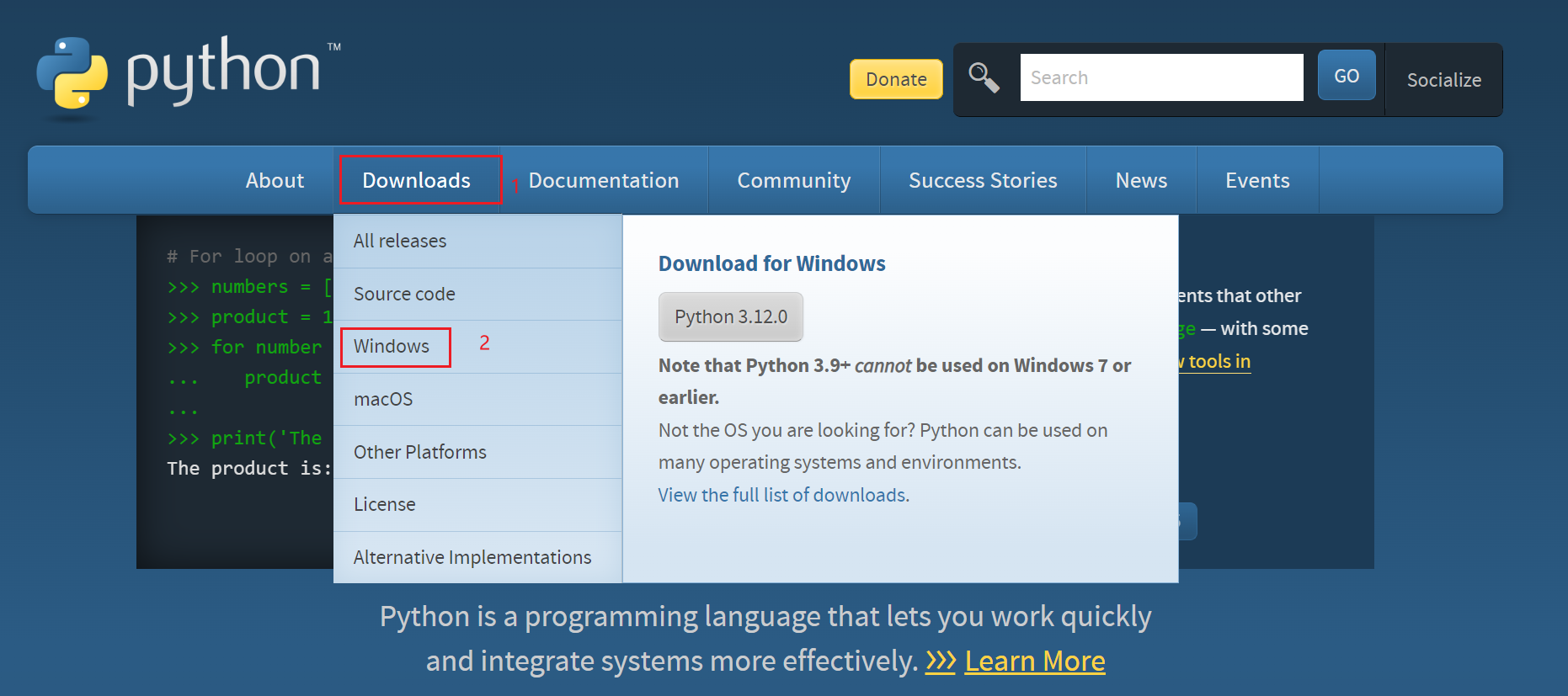
选择相应的python版本下载

双击下载的安装包
勾选即把python路径添加到环境变量中(不勾选的话在 doc命令窗口使用不了python指令)


安装完成后 WIN键+R 输入CDM 然后在DOC命令行输入python显示如下信息说明安装成功了
输入exit()退出

二、安装对应的库
1、安装Scrapy框架(一个快速高级的爬虫框架)
-i表示下载库的地址(使用的是国内清华镜像源,快)
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple

输入 pip list? 查看
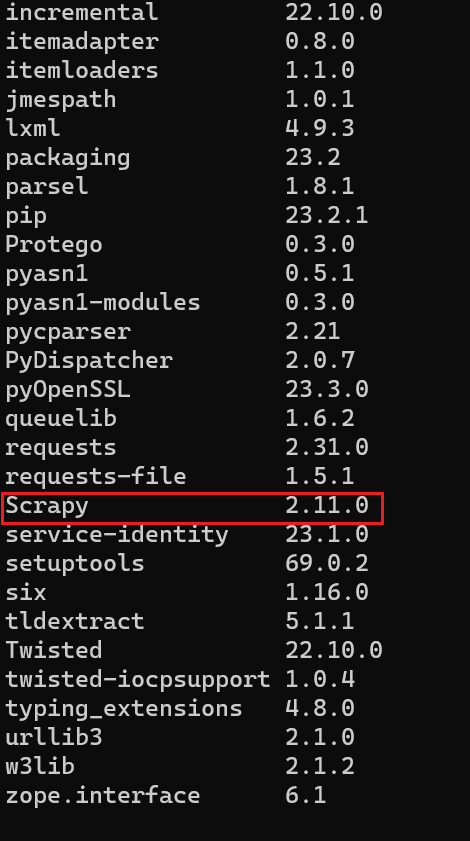
2、安装Jupyter(一个开源的交互式计算环境)
pip install? jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple

3、登录Jupyter
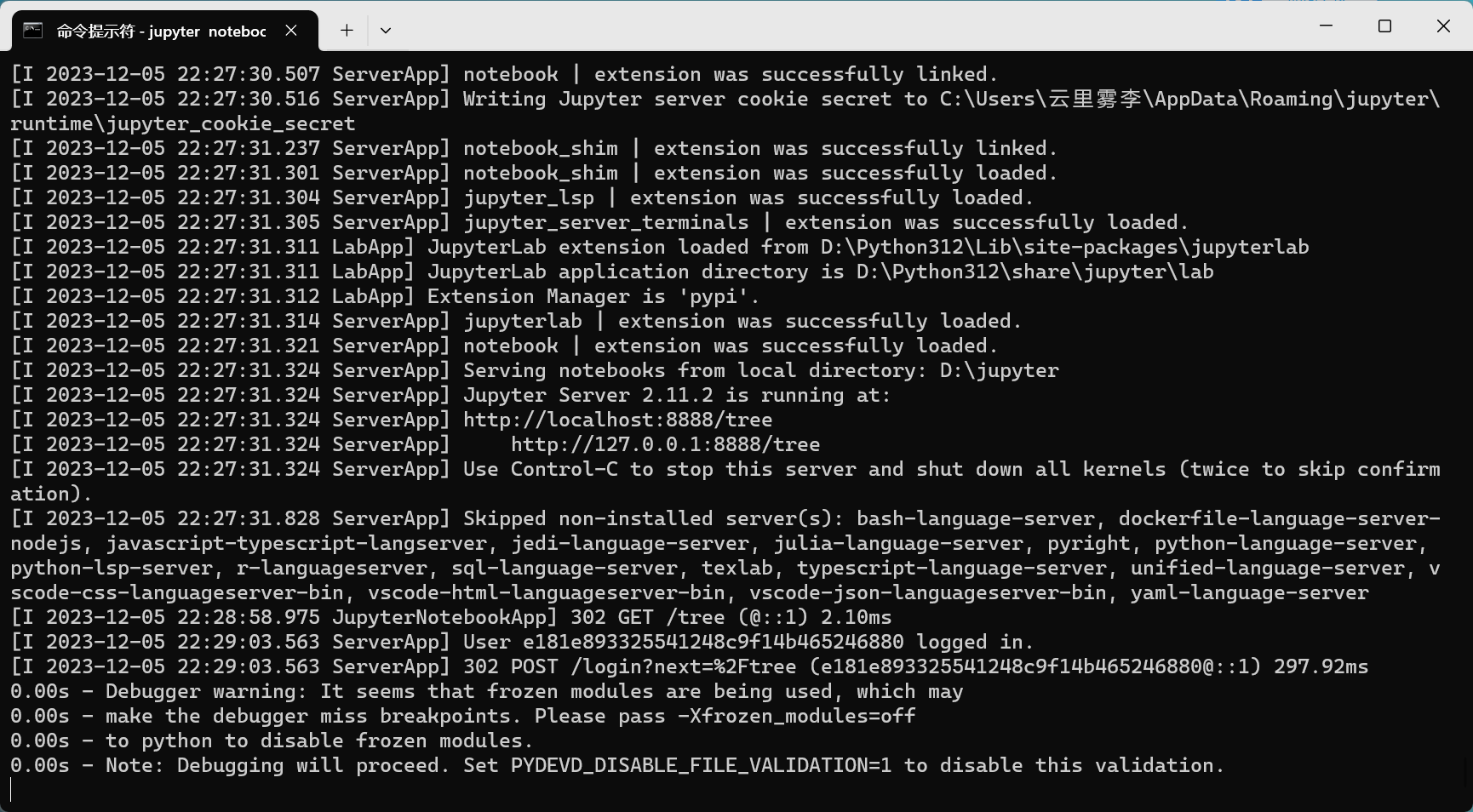
①在Doc命令窗口 输入? jupyter notebook

②网页中输入下面网址http://localhost:8888/tree

③刚才打开的Doc界面千万不要关闭(不然就默认退出了jupyter了),需要doc窗口就新开一个。
结语
??? Python网络爬虫的环境搭建相对简单,但网络爬虫的开发涉及许多技术细节。在进行爬虫开发时,你应当遵守目标网站的robots.txt规则,并尊重网站的版权和隐私政策。此外,合理控制爬取频率以避免对网站服务器造成不必要的负担。祝你在Python网络爬虫的世界中探索愉快!
文章来源:https://blog.csdn.net/qq_44709053/article/details/134818108
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!