LLMs之Mixtral:Mixtral 8x7B(高质量的稀疏专家混合模型)的简介、安装、使用方法之详细攻略
LLMs之Mixtral:Mixtral 8x7B(高质量的稀疏专家混合模型)的简介、安装、使用方法之详细攻略
导读:2023年12月11日,Mistral AI团队发布了高质量的稀疏专家混合模型Mixtral 8x7B。这篇文章描述了Mistral AI推出的一个开源混合专家模型Mixtral 8x7B。
>> 背景:传统单一模型在表征能力和计算效率上存在一定限制。Mistral AI通过采用混合专家网络结构,旨在突破这一限制。
>> 痛点:单一模型难以兼顾强大表征能力和高计算效率的要求。
>> 解决方案:Mixtral采用混合专家网络结构,它由8个不同专家组成,每个Token仅选择其中2个专家进行处理,这样在保证表征能力的同时大幅提高计算效率。
>> 优点:相比于同行量级模型,Mixtral在综合考虑质量和计算成本方面具有明显优势。它可以流利处理3.2万Token的输入,支持5种语言,在代码生成等任务上表现出色。
>> 应用前景:Mistral AI还推出了Mixtral优化过的指令跟随模型,在MT-Bench指标测评中表现领先。未来该模型有望在需要大规模表征能力又追求高效率的应用中得到广泛应用。
>> 开源运用:Mistral AI将模型和部署工具完全开源,为研发人员和合作伙伴提供开放使用Mixtral的可能。
目录
Mixtral 8x7B的简介
2023年12月11日,Mistral AI团队发布了高质量的稀疏专家混合模型Mixtral 8x7B。Mistral AI继续致力于向开发者社区提供最优秀的开放模型。在人工智能领域取得更大进展需要超越重新利用众所周知的架构和训练范式,更重要的是,需要让社区从原创模型中受益,促进新的发明和用途。
Mixtral 8x7B是一款高质量的稀疏专家混合模型(SMoE),具有开放的权重。采用Apache 2.0许可证。Mixtral在大多数基准测试中表现优于Llama 2 70B,推断速度快6倍。它是最强大的开放权模型,具有宽松的许可证,并在成本/性能权衡方面是最佳模型。特别是,在大多数标准基准测试中,它与或胜过了GPT3.5。
Mixtral具有以下特点:
>> 优雅地处理32k标记的上下文。
>> 支持英语、法语、意大利语、德语和西班牙语。
>> 在代码生成方面表现出色。
>> 可以微调为一个遵循指令的模型,在MT-Bench上达到8.3的分数。
官网:Mixtral of experts | Mistral AI | Open source models
开发文档:Introduction | Mistral AI Large Language Models
1、推动开放模型与稀疏架构的前沿
Mixtral是一种稀疏专家混合网络。它是一种仅解码器的模型,其中前馈块从8个不同的参数组中选择。在每一层,对于每个标记,一个路由网络选择其中两组(“专家”)来处理标记并将它们的输出相加。
这种技术增加了模型的参数数量,同时控制成本和延迟,因为模型每标记只使用总参数集的一小部分。具体来说,Mixtral总共有46.7B个参数,但每标记仅使用12.9B个参数。因此,它以与12.9B模型相同的速度和成本处理输入并生成输出。
Mixtral在从开放网络中提取的数据上进行预训练 - 我们同时训练专家和路由器。
2、性能
我们将Mixtral与Llama 2家族和GPT3.5基础模型进行比较。Mixtral在大多数基准测试中与或优于Llama 2 70B以及GPT3.5。
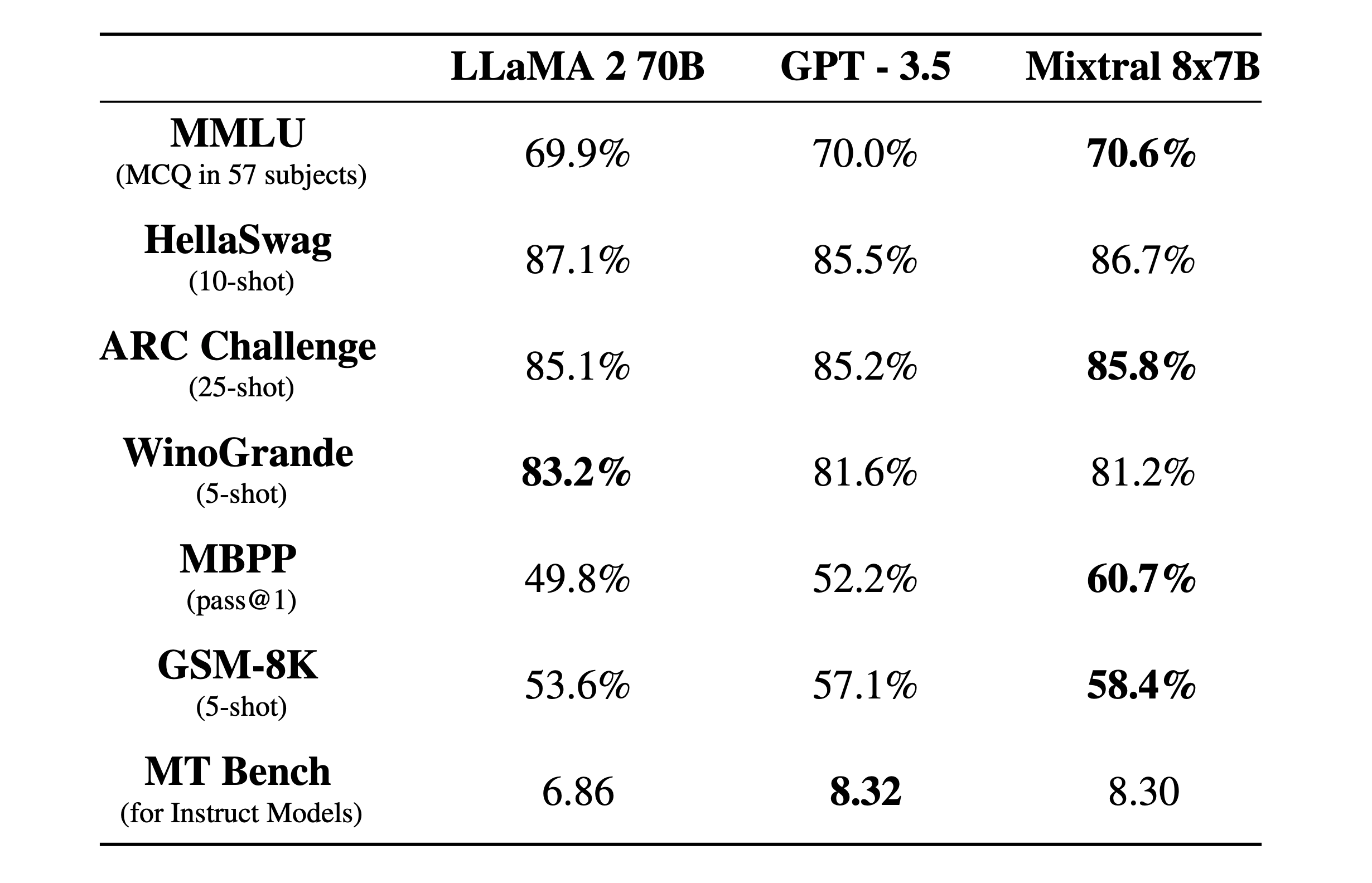
性能概述
在下图中,我们衡量了质量与推理预算权衡的情况。Mistral 7B和Mixtral 8x7B属于与Llama 2模型相比高效的模型系列。

详细基准测试
下表给出了上图的详细结果。

幻觉和偏见,BOLD基准测试
为了识别需要通过精细调整/偏好建模来纠正的可能缺陷,我们在TruthfulQA/BBQ/BOLD上测量了基础模型的性能。

与Llama 2相比,Mixtral在TruthfulQA基准测试上更真实(73.9% vs 50.2%),在BBQ基准测试上呈现出更少的偏见。总体而言,Mixtral在BOLD上显示出比Llama 2更积极的情绪,各个维度内的变化相似。
多语言基准测试
语言。Mixtral 8x7B掌握法语、德语、西班牙语、意大利语和英语。

3、指导模型
我们发布了Mixtral 8x7B Instruct,与Mixtral 8x7B一起发布。通过监督微调和直接偏好优化(DPO),该模型已经优化为仔细遵循指令。在MT-Bench上,它达到了8.30的分数,使其成为性能与GPT3.5相媲美的最佳开源模型。
注意:Mixtral可以被优雅地提示以禁止构建某些需要强烈的调整模式的应用,如此例所示。适当的偏好调整也可以起到这个作用。请记住,没有这样的提示,模型将按照给定的任何指令执行。
Mixtral 8x7B的安装
1、使用开源部署堆栈部署Mixtral
为了使社区能够使用完全开源的堆栈运行Mixtral,我们已向vLLM项目提交了更改,该项目集成了用于高效推断的Megablocks CUDA内核。
Skypilot允许在云中的任何实例上部署vLLM端点。
Mixtral 8x7B的使用方法
1、在平台上使用Mixtral。
我们目前在我们的端点mistral-small后面使用Mixtral 8x7B,该端点目前在beta版中可用。注册以提前获得所有生成和嵌入端点的早期访问。
地址:La plateforme | Mistral AI | Open source models

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!