大型语言模型(LLM)和向量数据库(Vector Databases)的使用
我的新书《Android App开发入门与实战》已于2020年8月由人民邮电出版社出版,欢迎购买。点击进入详情
目录
1. 使用 Sentence Transformer 生成嵌入
L随着最近发布的生成式 AI 工具(例如 Chat-GPT、Bard 等),大型语言模型 (LLM) 在机器学习社区中引起了全球关注。这些解决方案背后的核心思想之一是计算非结构化数据(例如文本和图像)的数字表示并找到这些表示之间的相似性。
在本文中,我介绍了两个旨在解决这些问题的开源解决方案:
- Sentence Transformers?[1]:一种基于文本信息的嵌入生成技术;
- Qdrant:一个矢量数据库,能够存储嵌入并提供一个简单的界面来查询它们。
这些工具适用于 NPR [2],这是一个新闻门户推荐数据集(在?Kaggle?上公开提供),旨在支持学术界开发推荐算法。在文章结束时,您将了解如何:
- 使用句子转换器生成新闻嵌入
- 使用 Qdrant 存储嵌入
- 查询嵌入来推荐新闻文章
1. 使用 Sentence Transformer 生成嵌入
首先,我们需要找到一种将输入数据转换为向量的方法,我们将其称为嵌入(如果您想更深入地了解嵌入概念,我推荐 Boykis 的文章 [3])。什么是嵌入(Embeddings)?
那么让我们看一下 NPR 数据集可以处理哪些类型的数据:
import pandas as pd
df = pd.read_parquet("articles.parquet")
df.tail()
示例数据来自 NPR
我们可以看到 NPR 有一些有趣的文本数据,例如文章“?标题和正文内容。我们可以在嵌入生成过程中使用它们,如下图所示:
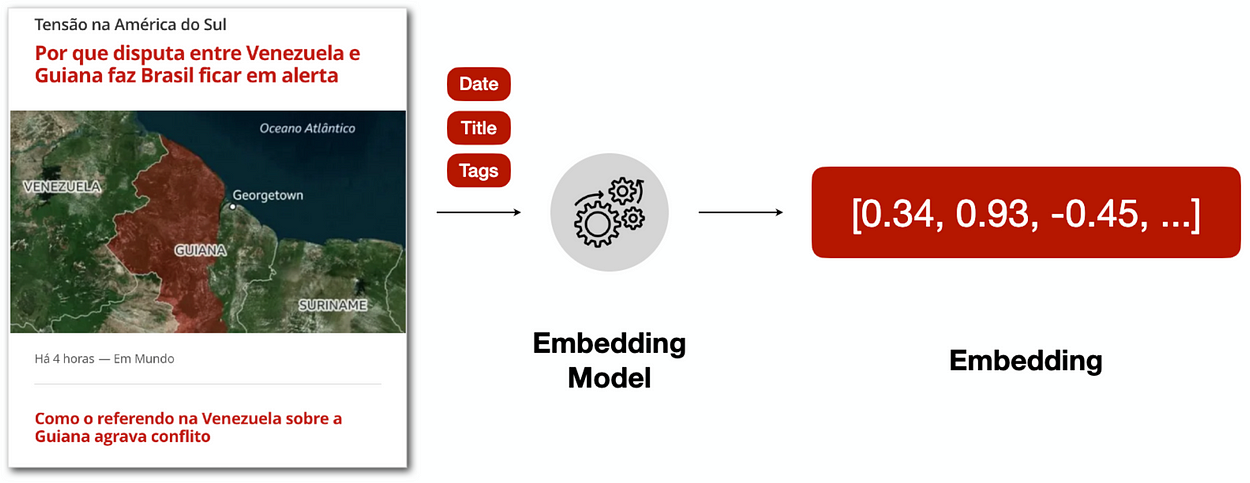
嵌入生成过程
因此,一旦我们从输入数据中定义了文本特征,我们就需要建立一个嵌入模型来生成我们的数字表示。对我们来说幸运的是,有像?HuggingFace?这样的网站,您可以在其中查找适合特定语言或任务的预训练模型。在我们的示例中,我们可以使用?neuralmind/bert-base-portuguese-cased?模型,该模型已用巴西葡萄牙语进行训练,用于执行以下任务:
- 命名实体识别
- 句子文本相似度
- 识别文本蕴含
从代码角度来看,这就是我们如何翻译嵌入生成过程:
from sentence_transformers import SentenceTransformer
model_name = "neuralmind/bert-base-portuguese-cased"
encoder = SentenceTransformer(model_name_or_path=model_name)
title = """
Paraguaios v?o às urnas neste domingo (30) para escolher novo presidente
"""
sentence = title
sentence_embedding = encoder.encode(sentence)
print (sentence_embedding)
# output: np.array([-0.2875876, 0.0356041, 0.31462672, 0.06252239, ...])
因此,给定一个示例输入数据,我们可以连接?标题?和?标签?将内容转换为单个文本并将其传递给编码器以生成文本嵌入。
我们可以对 NPR 数据集中的所有其他文章应用相同的过程:
def generate_item_sentence(item: pd.Series, text_columns=["title"]) -> str:
return ' '.join([item[column] for column in text_columns])
df["sentence"] = df.apply(generate_item_sentence, axis=1)
df["sentence_embedding"] = df["sentence"].apply(encoder.encode)注意:请记住,此过程可能需要更长的时间,具体取决于您计算机的处理能力。
一旦我们获得了所有新闻文章的嵌入,我们就可以定义一个存储它们的策略。
2. 存储嵌入
由于生成嵌入可能是一个昂贵的过程,因此我们可以使用向量数据库来存储这些嵌入并根据不同的策略执行查询。
有多种矢量数据库软件可以完成此任务,但在本文中我将使用Qdrant,这是一个开放的- 源解决方案,具有可用于流行编程语言的 API,例如?Python、Go、?和?打字稿。为了更好地比较这些矢量数据库,请查看这篇文章?[4]。
设置Qdrant
为了处理所有 Qdrant 操作,我们需要创建一个指向矢量数据库的客户端对象。 Qdrant 允许您创建免费层服务来测试与数据库的远程连接,但为了简单起见,我将在本地创建并保留数据库:
from qdrant_client import QdrantClient
client = QdrantClient(path="./qdrant_data")建立此连接后,我们可以在数据库中创建一个集合来存储新闻文章嵌入:
from qdrant_client import models
from qdrant_client.http.models import Distance, VectorParams
client.create_collection(
collection_name = "news-articles",
vectors_config = models.VectorParams(
size = encoder.get_sentence_embedding_dimension(),
distance = models.Distance.COSINE,
),
)
print (client.get_collections())
# output: CollectionsResponse(collections=[CollectionDescription(name='news-articles')])请注意,矢量配置参数用于创建集合。这些参数告诉 Qdrant 向量的一些属性,例如它们的?大小?和?距离?比较向量时使用的度量(我将使用余弦相似度,但您也可以使用其他策略,例如内积或欧几里得距离).
生成向量点
在最终填充数据库之前,我们需要创建适当的要上传的对象。在 Qdrant 中,可以使用?PointStruct?类存储向量,您可以使用该类定义以下属性:
- id:载体的 ID(在 NPR 情况下,是?newsId?)
- 向量:表示向量的一维数组(由嵌入模型生成)
- payload:包含任何其他相关元数据的字典,稍后可用于查询集合中的向量(在 NPR 案例中,文章的?标题、正文、和标签)
from qdrant_client.http.models import PointStruct
metadata_columns = df.drop(["newsId", "sentence", "sentence_embedding"], axis=1).columns
def create_vector_point(item:pd.Series) -> PointStruct:
"""Turn vectors into PointStruct"""
return PointStruct(
id = item["newsId"],
vector = item["sentence_embedding"].tolist(),
payload = {
field: item[field]
for field in metadata_columns
if (str(item[field]) not in ['None', 'nan'])
}
)
points = df.apply(create_vector_point, axis=1).tolist()上传矢量
最后,在所有项目都变成点结构后,我们可以将它们分块上传到数据库:
CHUNK_SIZE = 500
n_chunks = np.ceil(len(points)/CHUNK_SIZE)
for i, points_chunk in enumerate(np.array_split(points, n_chunks)):
client.upsert(
collection_name="news-articles",
wait=True,
points=points_chunk.tolist()
)3. 查询向量
现在集合终于填充了向量,我们可以开始查询数据库了。我们可以通过多种方式输入信息来查询数据库,但我认为我们可以使用两种非常有用的输入:
- 输入文本
- 输入向量 ID
3.1 使用输入向量查询向量
假设我们构建了这个矢量数据库以用于搜索引擎。在这种情况下,我们期望用户的输入是输入文本,并且我们必须返回最相关的项目。
由于向量数据库中的所有操作都是通过...向量完成的,因此我们首先需要将用户的输入文本转换为向量,以便我们可以根据该输入找到相似的项目。回想一下,我们使用句子转换器将文本数据编码为嵌入,因此我们可以使用相同的编码器为用户的输入文本生成数字表示。
由于 NPR 包含新闻文章,假设用户输入?“Tom Jerry”?:
query_text = "Tom Jerry"
query_vector = encoder.encode(query_text).tolist()
print (query_vector)
# output: [-0.048, -0.120, 0.695, ...]计算出输入查询向量后,我们就可以在集合中搜索最接近的向量,并定义我们想要从这些向量中得到什么样的输出,例如它们的?newsId主题和标题
from qdrant_client.models import Filter
from qdrant_client.http import models
client.search(
collection_name="news-articles",
query_vector=query_vector,
with_payload=["newsId", "title", "topics"],
query_filter=None
)注意:默认情况下,Qdrant 使用近似最近邻快速扫描嵌入,但您也可以进行全面扫描并带来精确最近邻?- 请记住,这是一个昂贵得多的操作。
此外,我还遗漏了query_filter?参数。如果您想指定输出必须满足某些给定条件,这是一个非常有用的工具。例如,在新闻门户中,仅过滤最新的文章(例如从过去 7 天开始)通常很重要。因此,您可以查询满足最小发布时间戳的新闻文章。
注意:在新闻推荐环境中,需要考虑多个方面,例如公平性和多样性。这是一个开放的讨论主题,但如果您对此领域感兴趣,请查看?NORMalize Workshop?中的文章。
3.2 使用输入向量ID查询向量
最后,我们可以要求矢量数据库“推荐”更接近某些所需向量 ID 但远离不需要的向量 ID 的项目。所需和不需要的 ID 分别称为?正例?和?负例它们被认为是推荐的种子。
例如,假设我们有以下positive?ID:
seed_id = '8bc22460-532c-449b-ad71-28dd86790ca2'
# title (translated): 'Learn how to learn Embeddings'然后我们可以请求类似于此示例的项目:
client.recommend(
collection_name="news-articles",
positive=[seed_id],
negative=None,
with_payload=["newsId", "title", "topics"]
)结论
本文演示了如何结合大语言模型和向量数据库来提供推荐服务。特别是,句子转换器被用来从 NPR 数据集中的文本新闻文章生成数字表示(嵌入)。一旦计算出这些嵌入,它们就可以填充向量数据库,例如 Qdrant,这有助于基于多种策略查询向量。
在本文中的示例之后可以进行很多改进,例如:
- 测试其他嵌入模型
- 测试其他距离指标
- 测试其他向量数据库
- 使用基于编译的编程语言(例如 Go)以获得更好的性能
- 创建 API 来提供建议
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!