从仿写持久层框架到MyBatis核心源码阅读
接上篇手写持久层框架:https://blog.csdn.net/liwenyang1992/article/details/134884703
MyBatis源码
MyBatis架构原理&主要组件
MyBatis架构设计

MyBatis架构四层作用是什么呢?
API接口层:提供API,增加、删除、修改、查询等接口,通过API接口对数据库进行操作。
数据处理层:主要负责SQL的 查询、解析、执行以及结果映射的处理,主要作用解析SQL根据调用请求完成一次数据库操作。
框架支撑层:负责通用基础服务支撑,包含事务管理、连接池管理、缓存管理等共用组件的封装,为上层提供基础服务支撑。

包路径org.apache.ibatis
| 包路径 | 作用备注 |
|---|---|
| annotations | Mapper映射器接口中使用到的注解 |
| binding | Mapper映射器接口与映射语句关系绑定构建 |
| builder | Configuration配置的构建包 |
| cache | 缓存实现与定义(包含一级/二级缓存) |
| cursor | 游标(针对查询结果集的获取与遍历等) |
| datasource | 数据源/连接池 |
| exceptions | 异常包 |
| executor | 语句执行器(包含参数/结果集/语句处理等) |
| io | 资源读取辅助包 |
| jdbc | MyBatis内部的SQL脚本运行的测试包 |
| logging | 一套日志接口和适配器包 |
| mapping | Mapper映射器相关参数/语句/结果/类型等对象包 |
| parsing | XML解析包(例如#{}占位符解析) |
| plugin | 插件包 |
| reflection | 反射处理工具包 |
| scripting | SQL执行脚本的解析处理包 |
| session | 数据库连接会话核心包(会话创建/管理/调用) |
| transaction | 事务 |
| type | 类型处理器(定义bean与数据库类型的转换关系) |
XML映射器
MyBatis的真正强大在于它的语句映射,这是它的魔力所在,由于它的异常强大,映射器的XML文件就显得相对简单。如果拿它跟具有相同功能的JDBC代码进行对比,你会立即发现省掉了将近95% 的代码。MyBatis致力于减少使用成本,让用户能更专注于 SQL 代码。
SQL 映射文件只有很少的几个顶级元素(按照应被定义的顺序列出):
- cache:该命名空间的缓存配置
- cache-ref:引用其它命名空间的缓存配置。
- resultMap:描述如何从数据库结果集中加载对象,是最复杂也是最强人的元素
- sql:可被其它语句引用的可重用语句块。
- insert:映射插入语句。
- update:映射更新语句
- delete:映射删除语句。
- select:映射查询语句。
select
select元素允许你配置很多属性来配置每条语句的行为细节
<select
id="select"
parameterType="int"
resultType="resultType"
resultMap="resultMap"
flushCache="false"
useCache="true"
timeout="10"
fetchSize="256"
statementType="PREPARED"
resultSetType="FORWARD_ONLY"></select>
insert, update 和 delete
数据变更语句insert, update 和 delete 的实现非常接近
动态SQL
借助功能强大的基于OGNL的表达式,MyBatis 3 替换了之前的大部分元素,大大精简了元素种类
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
XMLScriptBuilder
public SqlSource parseScriptNode()方法:
- 解析select、insert、update、delete标签中的SQL语句
- 最终将解析到的SqlNode封装到MixedSqlNode中的List集合中
- 将带有${}号的SQL信息封装到TextSqlNode
- 将带有#{}号的SQL信息封装到StaticTextSqlNode
- 将动态SQL标签中的SQL信息分别封装到不同的SqlNode中
- 如果SQL中包含${}和动态SQL语句,则将SqlNode封装到DynamicSqlSource

相关类与接口
DefaultSqlSession
SqlSession接口的默认实现类
Executor接口:

BaseExecutor:基础执行器,封装了子类的公共方法及公共变量,包括一级缓存、延迟加载、回滚、关闭等功能;
SimpleExecutor:简单执行器,每执行一条SQL,都会打开一个 Statement,执行完成后关闭;
ReuseExecutor:重用执行器,相较于 SimpleExecutor多了 Statement 的缓存功能,其内部维护一个Map<String, Statement>,每次编译完成的Statement 都会进行缓存,不会关闭;
BatchExecutor:批量执行器,基于JDBC的addBatch、executeBatch功能,并且在当前SQL和上一条SQL完全一样的时候,重用Statement,在调用doFlushStatements的时候,将数据刷新到数据库;
CachingExecutor:缓存执行器,装饰器模式,在开启缓存的时候。会在上面三种执行器的外面包上 CachingExecutor;
缓存执行过程

SimpleExecutor#doQuery
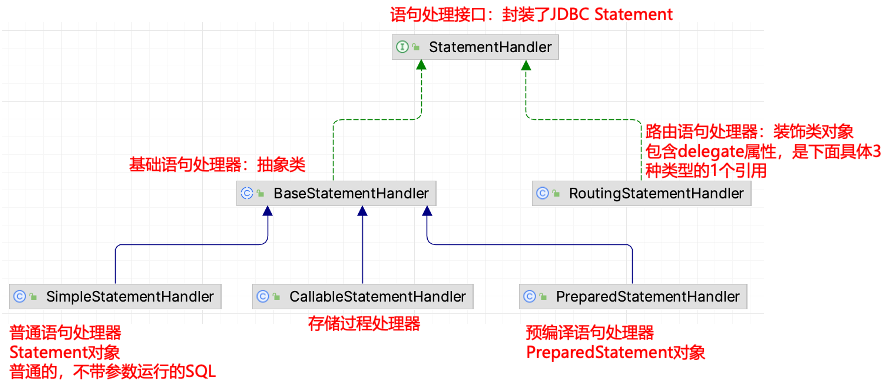
- BaseStatementHandler:基础语句处理器(抽象类),它基本把语句处理器接口的核心部分都实现了,包括配置绑定、执行器绑定、映射器绑定、参数处理器构建、结果集处理器构建、语句超时设置、语句关闭等,并另外定义了新的方法 instantiateStatement供不同子类实现以使获取不同类型的语句连接,子类可以普通执行 SQL语句,也可以做预编译执行,还可以执行存储过程等
- SimpleStatementHandler:普通语句处理器,继承
BaseStatementHandler抽象类,对应 java.sql.Statement 对象的外理,处理普通的不带动态参数运行的SQL,即执行简单拼接的字符串语句,同时由于 Statement 的特性,SimpleStatementHandler 每次执行都需要编译 SQL**(注意:我们知道 SQL 的执行是需要编译和解析的)。** - PreparedStatementHandler:预编译语句处理器,继承
BaseStatementHandler抽象类,对应 java.sql.PrepareStatement 对象的处理,相比上面的普通语句处理器,它支持可变参数 SQL执行,由于 PrepareStatement 的特性,它会进行预编译,在缓存中一旦发现有预编译的命令,会直接解析执行,所以减少了再次编译环节,能够有效提高系统性能,并预防 SQL 注入攻击**(所以是系统默认也是我们推荐的语句处理器)** - CallableStatementHandler:存储过程外理器,继承
BaseStatementHandler抽象类,对应 java.sql.CallableStatement 对象的处理,很明了,它是用来调用存储过程的,增加了存储过程的函数调用以及输出/输入参数的处理支持。 - RoutingStatementHandler:路由语句处理器,直接实现了 StatementHandler 接口,作用如其名称,确确实实只是起到了路由功能,并把上面介绍到的三个语句处理器实例作为自身的委托对象而已,所以执行器在构建语句处理器时,都是直接 new了RoutingStatementHandler实例。
附件中包含测试用例代码,可设置jdk17调试运行,带注解。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!