6种大模型的使用方式总结,使用领域数据集持续做无监督预训练可能是一个好选择
本文原文来自DataLearnerAI官方网站:6种大模型的使用方式总结,使用领域数据集持续做无监督预训练可能是一个好选择 | 数据学习者官方网站(Datalearner)![]() https://www.datalearner.com/blog/1051703426665726
https://www.datalearner.com/blog/1051703426665726
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的见解,也贡献了许多有价值的内容。在最新的一期推文中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于领域大模型的一些争论引起了DataLeanerAI的注意,也可能是当前一个广受关注的大模型路线,即使用领域数据集做无监督预训练是否有前途。

本文将先简单介绍一下这6种大模型的使用方式,然后就其中的领域大模型做进一步讨论。
6种大模型的使用方法简述
简单来说,Sebastian Raschka将大模型的使用分为2个阶段,一个阶段是预训练阶段,另一个阶段是使用阶段(有监督微调/上下文学习)。前者当前有3种范式,后者有2种范式,组合之后有6种情况,就是下图的6个选项。
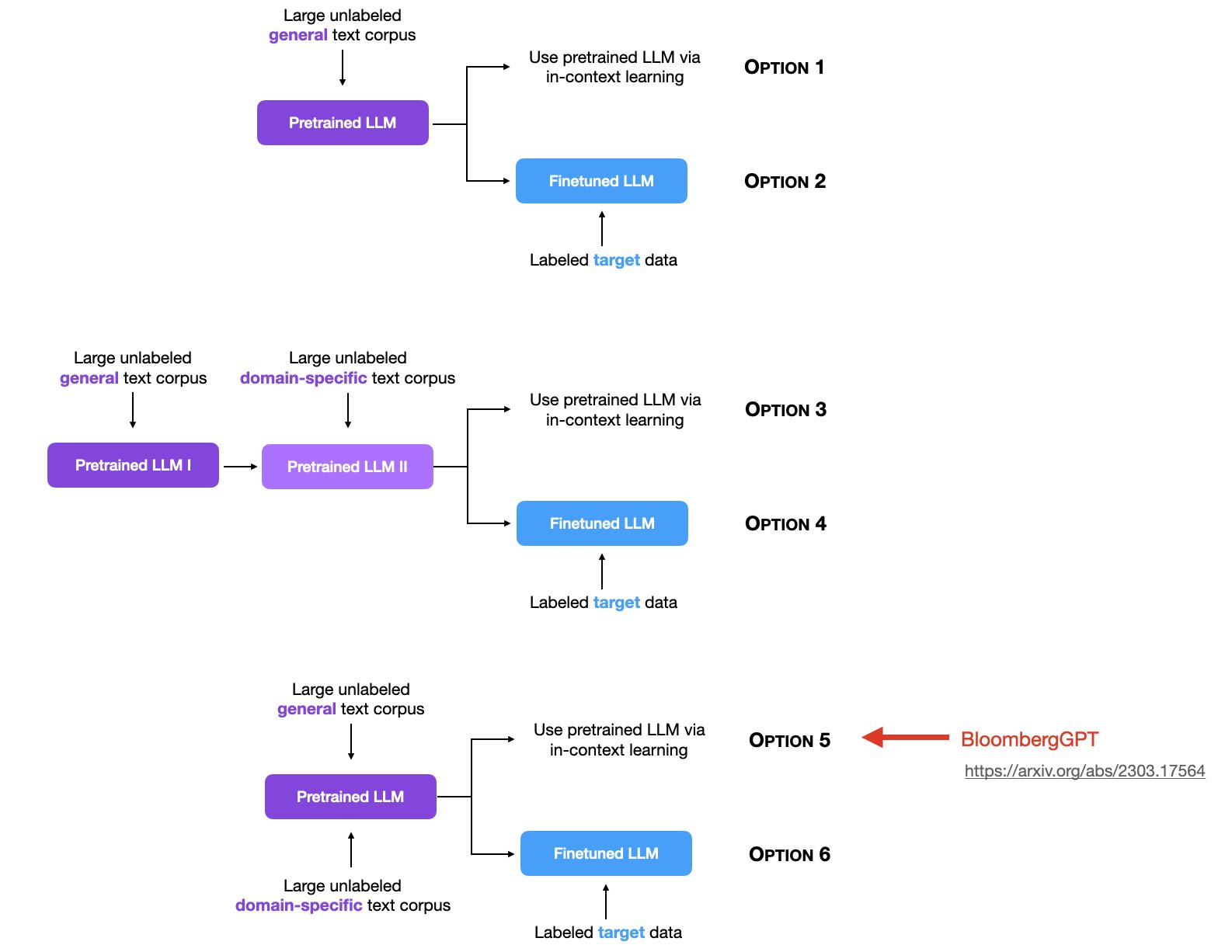
预训练的目标是让大模型学习通用知识,提高模型在广泛任务和数据上的泛化能力(即见更多更广的数据),而后续使用则是针对目标任务进行上下文学习或者是有监督微调。
大模型的2种使用方式
我们先简单描述一下大模型的2种使用方法。在ChatGPT爆火之后,大模型已经是当前技术领域最火爆的话题。与传统机器学习算法不同的是,大模型因为训练成本和强大的能力导致了两种新的使用方法,即In-context learning(上下文学习)和Fine tuning(微调)。
上下文学习(In-Context Learning)
简单来说,大模型因为本身已经有了非常强的能力,可以完成很多任务。即使是在训练过程中没有遇到过的任务,也可以通过一种叫做In-context Learning的方式完成。这种技术使得模型能够在没有改变自身参数的情况下,通过阅读和分析输入的上下文来适应和执行特定的任务。
微调(Fine Tuning)
而微调则是另一种大模型使用方式。即使大模型有很强的上下文学习,但也不是可以解决所有目标任务,对于一些非常具有领域特征的任务来说,使用领域有标注数据对大模型进行微调则是另一种高效的方式。与上下文学习不同的是,微调会改变大模型的参数。通过微调,模型在保留了通用语言处理能力的同时,还获得了处理特定任务的能力。这就像篮球运动员已经懂得篮球的基础,但通过特别训练,他们可以在特定的技能(如三分球)上变得更加专业。
大模型的3种预训练方式
无标注通用数据预训练
这也是最早大模型预训练使用的方法。包括GPT-3/GPT-4、LLaMA1/LLaMA2系列等。都是通过收集大量无标注的通用数据集,使用transformer架构的模型进行预训练得到。预训练结果的模型已经足够强大,然后大家就使用这样的预训练结果做上下文学习使用或者针对特定任务微调。
这里特定任务微调包括针对聊天进行对话优化或者是针对特定任务做指令优化。这应该也是目前最主流的大模型预训练方式。
先做无标注通用数据预训练,再做领域无标注数据预训练
这也是训练领域大模型常用的方法,如EleutherAI提出的LLEMMA大模型,就是将Code LLaMA模型继续在大量的科学、数学领域的数据集上进一步做无监督预训练得到的。结果显示,这样训练得到的模型在GSM8K任务上是原始CodeLLaMA成绩的3倍,在MATH评测上的4倍。
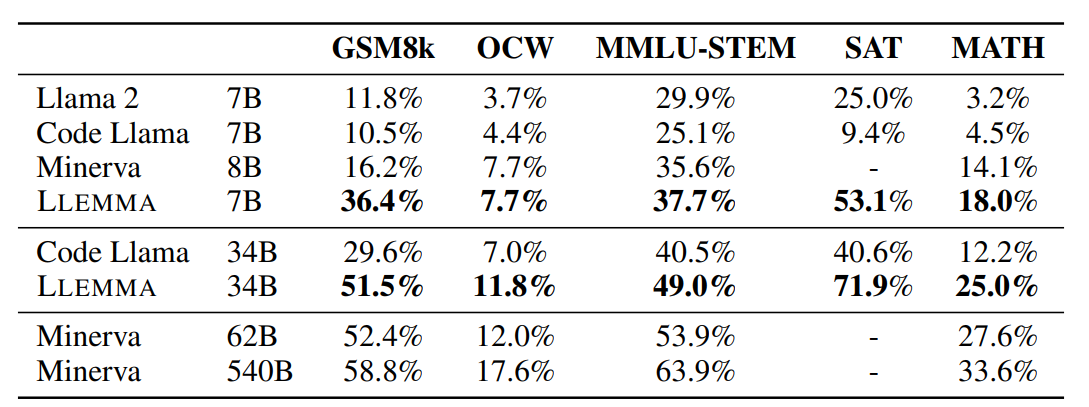
需要注意的是,这里是一个顺序预训练,即先在通用数据集上预训练一个大模型,再在特定领域的无标注数据集上进一步预训练。
通用无标注数据与领域无标注数据混合预训练
这是另一种思路,与第二种顺序预训练不同。这是只做一次预训练过程。但是在一开始就把通用数据和特定领域的无标注数据混合在一起。这个训练方式最有名的就是彭博社发布的BloombergGPT。
BloombergGPT是2023年4月份由彭博社发布的金融领域大模型,参数规模500亿,但是在7000亿tokens数据集上预训练得到。其中金融领域数据约3630亿个tokens。这已经是非常早的领域大模型了。而且方式也非常独特,在预训练阶段就把通用数据和领域数据混合(详情参考:彭博社发布金融领域的ChatGPT模型——BloombergGPT | 数据学习者官方网站(Datalearner)?)
领域数据该怎么用?领域数据无监督预训练vs领域数据有监督微调
二者对比如下:
| 特定领域的有监督微调 | 特定领域的无监督预训练 | |
|---|---|---|
| 特点 | 针对性强,适用于具体任务 | 提高对领域的通用理解 |
| 方法 | 使用特定领域的标记数据 | 使用特定领域的大量未标记文本 |
| 优点 | 模型能精准执行特定任务 | 增强对领域内通用语言和概念的理解 |
| 缺点 | 可能过拟合,泛化能力较弱 | 缺乏针对性任务的优化能力 |
| 适用场景 | 任务非常具体,且有高质量的标记数据 | 需要广泛理解特定领域,但无具体任务目标 |
| 例子 | 医学图像分类 | 理解医学术语和概念 |
更多详细的解释参考原文:6种大模型的使用方式总结,使用领域数据集持续做无监督预训练可能是一个好选择 | 数据学习者官方网站(Datalearner)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!