Pandas缺失数据处理
好多数据集都含缺失数据,缺失数据有多重表现形式 数据库中,缺失数据表示为NULL 在某些编程语言中用NA表示 缺失值也可能是空字符串(’’)或数值 在Pandas中使用NaN表示缺失值;
NaN简介
Pandas中的NaN值来自NumPy库,NumPy中缺失值有几种表示形式:NaN,NAN,nan,他们都一样 缺失值和其它类型的数据不同,它毫无意义,NaN不等于0,也不等于空串
print(pd.isnull(NaN))
print(pd.isnull(nan))
结果:
True
True缺失数据的产生:数据录入的时候, 就没有传进来
????????在数据传输过程中, 出现了异常, 导致缺失
????????两个表之间做join也有可能join出
删除缺失值
填充 删除
titanic_train.dropna(axis=,subset=,how=,inplace=)
axis, subset 如何考虑是否是缺失值, 默认是判断缺失值的时候会考虑所有列, 传入了subset只会考虑subset中传入的列
how any 只要有缺失就删除 all 只有整行/整列数据所有的都是缺失值才会删除
?inplace 是否在原始数据中删除缺失值
填充缺失值
titanic_train['Age'].isnull().sum()
# 177
titanic_train['Age'].fillna(0).isnull().sum() # 用0来填充
# 0titanic_train['Age'].fillna(titanic_train['Age'].mean()).value_counts()
# 使用Age的平均值来当初填充值,再进行数值统计时序数据的缺失值填充
city_day.fillna(method='bfill')['Xylene'][50:64]
# bfill表示使用后一个非空值进行填充
# 使用前一个非空值填充:df.fillna(method='ffill')apply自定义函数
Pandas提供了很多数据处理的API,但当提供的API不能满足需求的时候,需要自己编写数据处理函数, 这个时候可以使用apply函数 apply函数可以接收一个自定义函数, 可以将DataFrame的行/列数据传递给自定义函数处理 apply函数类似于编写一个for循环, 遍历行/列的每一个元素,但比使用for循环效率高很多????????
import pandas as pd
df = pd.DataFrame({'a':[10,20,30],'b':[20,30,40]})
def my_sq(x):
return x**2
df['a'].apply(my_sq)
# 结果
0 100
1 400
2 900# apply传入多个参数
def my_exp(x,e):
return x**e
df['a'].apply(my_exp,e =3)
# 结果
0 1000
1 8000
2 27000把上面创建的my_sq, 直接应用到整个DataFrame中:
?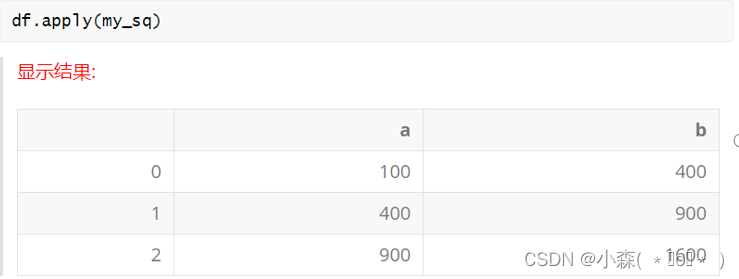
使用apply的时候,可以通过axis参数指定按行/ 按列 传入数据 axis = 0 (默认) 按列处理 axis = 1 按行处理,上面是按列都执行了函数
def avg_3_apply(col): # dataframe默认是传入一列一列
x=col[0]
y=col[1]
z=col[2]
return (x+y+z)/3
df.apply(avg_3_apply)按一列一列执行结果:(一共两列,所以显示两行结果)
?
创建一个新的列'new_column',其值为'column1'中每个元素的两倍,当原来的元素大于10的时候,将新列里面的值赋0:
import pandas as pd
data = {'column1':[1, 2, 15, 4, 8]}
df = pd.DataFrame(data)
df['new_column'] =df['column1'].apply(lambda x:x*2)
# 检查'column1'中的每个元素是否大于10,如果是,则将新列'new_column'中的值赋为0
df['new_column'] = df.apply(lambda row: 0 if row['column1'] > 10 else row['new_column'], axis=1) # 按行
# 可以翻译为:df['new_column']=0 或 row['new_column']
请创建一个两列的DataFrame数据,自定义一个lambda函数用来两列之和,并将最终的结果添加到新的列'sum_columns'当中
import pandas as pd
data = {'column1': [1, 2, 3, 4, 5], 'column2': [6, 7, 8, 9, 10]}
df = pd.DataFrame(data)
sum_columns =df.apply(lambda row:row['column1']+row['column2'],axis=1) # 按行
# 可以翻译为:sum_columns = row['column1']+row['column2']
# row['column1']+row['column2']相当于return的值
df['sum_columns'] = sum_columnsSeries和DataFrame均可以通过apply传入自定义函数,传入时要想清楚是行还是列
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!