Java集合框架深度解析:HashMap
Java中的HashMap是一种基于哈希表的实现,提供了快速的查找性能。在这篇深度解析中,我们将深入探讨HashMap**的实现原理、适用场景、潜在问题以及并发控制策略。
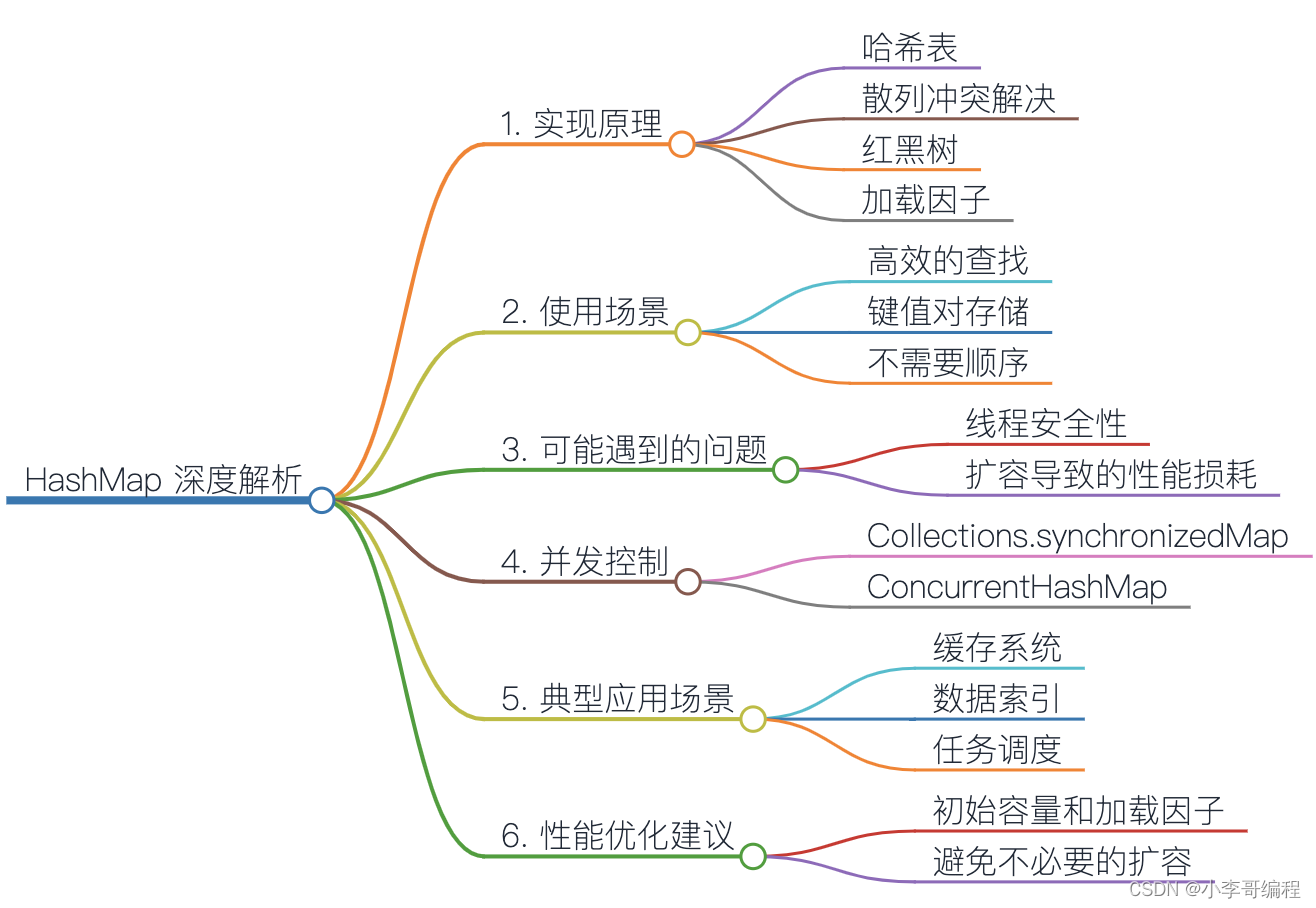
1. HashMap的实现原理
1.1 哈希表
HashMap内部基于哈希表实现,通过散列函数将键映射到存储桶的位置。这使得查找操作的时间复杂度接近O(1)。
1.2 散列冲突解决
由于哈希函数的值域远远小于键的集合,不同的键可能映射到相同的位置,产生冲突。HashMap采用链地址法解决冲突,即在相同位置的链表中存储冲突的元素。
1.3 红黑树
为了提高性能,JDK8引入了红黑树(RB-Tree)来优化链表。当链表长度超过一定阈值时,链表会转化为红黑树,提高查找的效率。
1.4 加载因子
为了保持性能,HashMap在存储元素的过程中,当元素数量达到一定比例(加载因子)时,会触发哈希表的扩容操作,重新分配存储空间。
2. HashMap的使用场景
2.1 高效的查找
HashMap适用于需要快速查找的场景,例如,缓存系统中通过缓存键快速定位对应的值。
2.2 键值对存储
HashMap以键值对的形式存储数据,适用于需要以键唯一标识值的场景。
2.3 不需要顺序
与LinkedHashMap不同,HashMap不关心元素的插入顺序,适用于对元素顺序没有特殊要求的场景。
3. 使用过程中可能遇到的问题
3.1 线程安全性
HashMap是非线程安全的,如果在多线程环境中使用,可能需要通过额外的同步手段来确保线程安全。
3.2 扩容导致的性能损耗
HashMap在扩容时需要重新计算哈希,重新分配存储空间,这可能导致性能的瞬时损耗。
4. 并发控制
4.1 Collections.synchronizedMap
通过 Collections.synchronizedMap** 方法可以将 HashMap 转换为线程安全的 **Map。这是通过在每个公共方法上加锁来实现的,从而保证线程安全。
4.2 ConcurrentHashMap
更先进的选择是使用 ConcurrentHashMap,它提供了更好的并发性能。ConcurrentHashMap使用分段锁的机制,可以支持更高的并发度。
5. 典型应用场景
5.1 缓存系统
在缓存系统中,HashMap常被用于存储键值对,以快速查找缓存数据。
5.2 数据索引
HashMap可以用于构建数据的索引结构,加速数据检索。
5.3 任务调度
在任务调度系统中,HashMap可以用于存储任务和对应的执行时间,以便快速定位任务。
6. 性能优化建议
6.1 初始容量和加载因子
在创建 HashMap 时,如果能够估计元素的数量,最好指定初始容量,以减少扩容操作的次数。同时,合理设置加载因子,平衡空间利用和性能。
6.2 避免不必要的扩容
在元素数量不断增加的过程中,避免不必要的扩容是提高性能的一种手段。如果能够预估元素的最大数量,可以直接设置大一些的初始容量,避免中途扩容。
结论
HashMap作为Java集合框架的核心之一,在实际应用中有着广泛的使用。深入理解其内部实现和使用场景,有助于在不同的业务场景中更好地利用和优化性能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!