爬虫入门与urllib&requests
2024-01-07 17:57:21
前情摘要
一、web请求全过程剖析
我们浏览器在输入完网址到我们看到网页的整体内容, 这个过程中究竟发生了些什么?
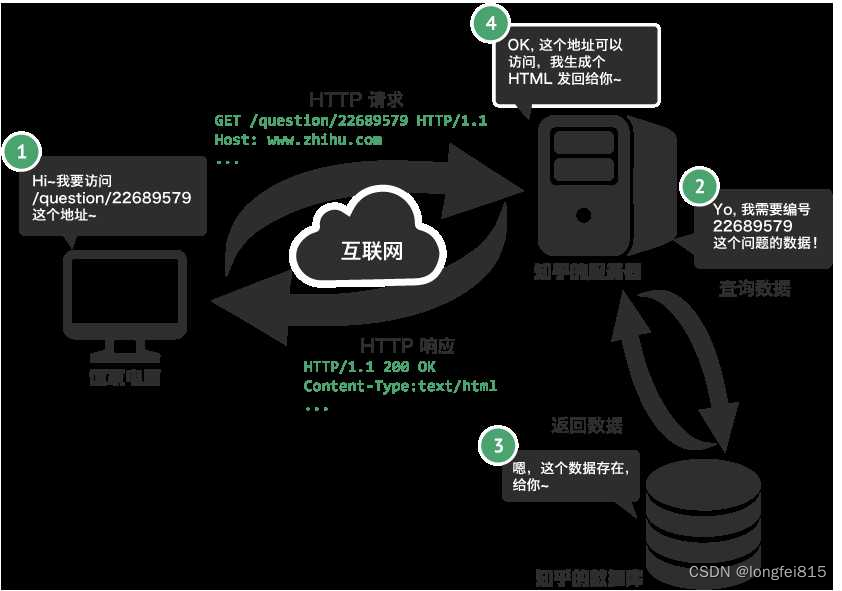
我们看一下一个浏览器请求的全过程


接下来就是一个比较重要的事情了. 所有的数据都在页面源代码里么? 非也~ 这里要介绍一个新的概念
那就是页面渲染数据的过程, 我们常见的页面渲染过程有两种,
-
服务器渲染, 你需要的数据直接在页面源代码里能搜到
这个最容易理解, 也是最简单的. 含义呢就是我们在请求到服务器的时候, 服务器直接把数据全部写入到html中, 我们浏览器就能直接拿到带有数据的html内容. 比如,

由于数据是直接写在html中的, 所以我们能看到的数据都在页面源代码中能找的到的.
这种网页一般都相对比较容易就能抓取到页面内容.
-
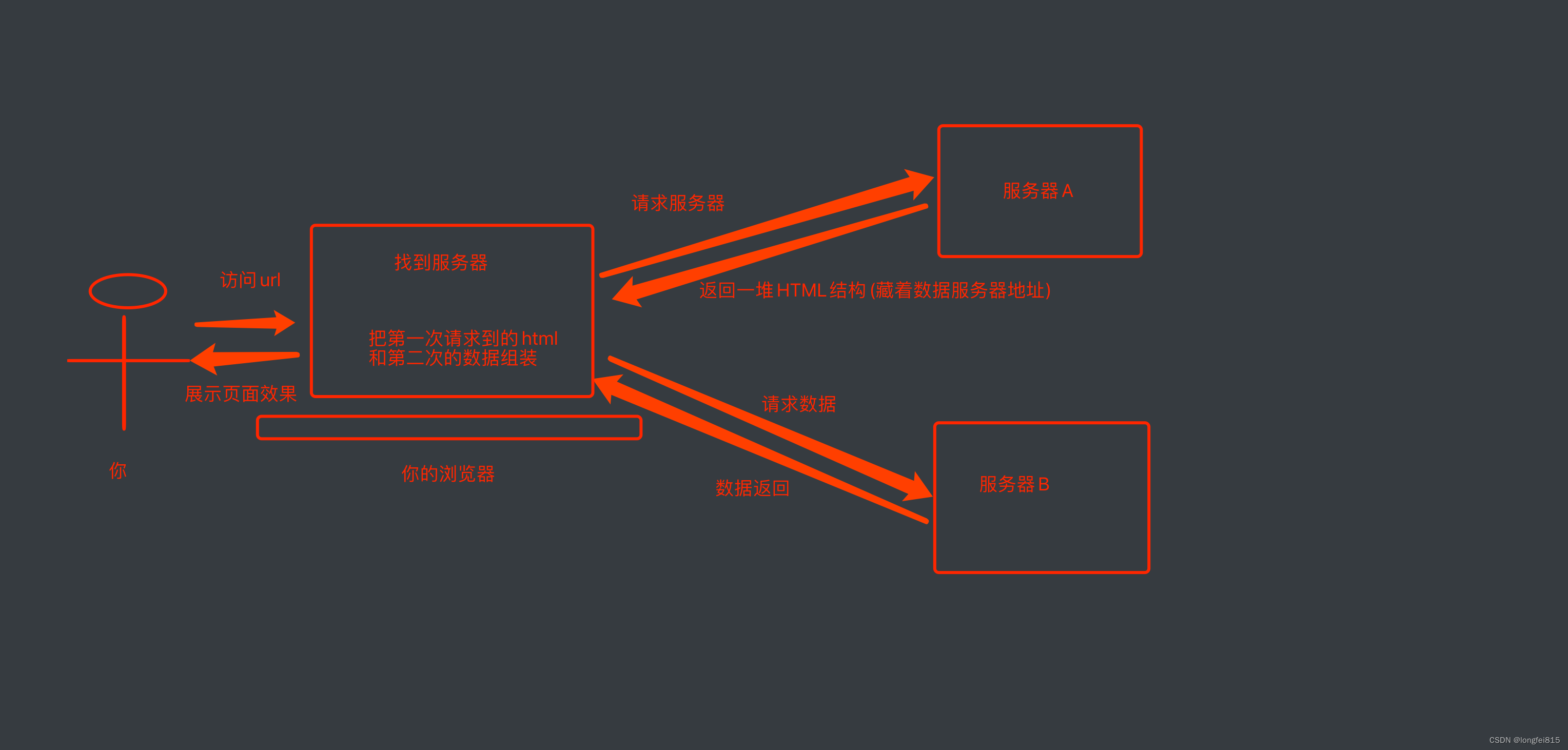
前端JS渲染, 你需要的数据在页面源代码里搜不到
这种就稍显麻烦了. 这种机制一般是第一次请求服务器返回一堆HTML框架结构. 然后再次请求到真正保存数据的服务器, 由这个服务器返回数据, 最后在浏览器上对数据进行加载. 就像这样:
js渲染代码(示例)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF
文章来源:https://blog.csdn.net/jolinoy/article/details/135371967
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!