Bounding boxes augmentation for object detection
Different annotations formats?
Bounding boxes are rectangles that mark objects on an image. There are multiple formats of bounding boxes annotations. Each format uses its specific representation of bouning boxes coordinates 每种格式都使用其特定的边界框坐标表示。. Albumentations supports four formats:?pascal_voc,?albumentations,?coco, and?yolo?.
Let's take a look at each of those formats and how they represent coordinates?坐标 of bounding boxes.
As an example, we will use an image from the dataset named?Common Objects in Context. It contains one bounding box that marks a cat. The image width is 640 pixels, and its height is 480 pixels. The width of the bounding box is 322 pixels, and its height is 117 pixels.

?An example image with a bounding box from the COCO dataset
pascal_voc?
pascal_voc?is a format used by the?Pascal VOC dataset. Coordinates of a bounding box are encoded with four values in pixels:?[x_min, y_min, x_max, y_max].?x_min?and?y_min?are coordinates of the top-left corner of the bounding box.?x_max?and?y_max?are coordinates of bottom-right corner of the bounding box.
Coordinates of the example bounding box in this format are?[98, 345, 420, 462].
albumentations?
albumentations?is similar to?pascal_voc, because it also uses four values?[x_min, y_min, x_max, y_max]?to represent a bounding box. But unlike?pascal_voc,?albumentations?uses normalized values. To normalize values, we divide coordinates in pixels for the x- and y-axis by the width and the height of the image.
Coordinates of the example bounding box in this format are?[98 / 640, 345 / 480, 420 / 640, 462 / 480]?which are?[0.153125, 0.71875, 0.65625, 0.9625].
Albumentations uses this format internally 内部 to work with bounding boxes and augment them.
coco?
coco?is a format used by the?Common Objects in Context?COCOCOCO?dataset.
In?coco, a bounding box is defined by four values in pixels?[x_min, y_min, width, height]. They are coordinates of the top-left corner along with the width and height of the bounding box.
Coordinates of the example bounding box in this format are?[98, 345, 322, 117].
yolo?
In?yolo, a bounding box is represented by four values?[x_center, y_center, width, height].?x_center?and?y_center?are the normalized coordinates of the center of the bounding box. To make coordinates normalized, we take pixel values of x and y, which marks the center of the bounding box on the x- and y-axis. Then we divide the value of x by the width of the image and value of y by the height of the image.?width?and?height?represent the width and the height of the bounding box. They are normalized as well.
Coordinates of the example bounding box in this format are?[((420 + 98) / 2) / 640, ((462 + 345) / 2) / 480, 322 / 640, 117 / 480]?which are?[0.4046875, 0.840625, 0.503125, 0.24375].

Bounding boxes augmentation?
Just like with?images?and?masks?augmentation, the process of augmenting bounding boxes consists of 4 steps.
- You import the required libraries.
- You define an augmentation pipeline.
- You read images and bounding boxes from the disk.
- You pass an image and bounding boxes to the augmentation pipeline and receive augmented images and boxes.
Note
Some transforms in Albumentation don't support bounding boxes. If you try to use them you will get an exception. Please refer to?this article?to check whether a transform can augment bounding boxes.
Step 1. Import the required libraries.?
import albumentations as A
import cv2Step 2. Define an augmentation pipeline.?
Here an example of a minimal declaration of an augmentation pipeline that works with bounding boxes.
transform = A.Compose([
A.RandomCrop(width=450, height=450),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
], bbox_params=A.BboxParams(format='coco'))Note that unlike image and masks augmentation,?Compose?now has an additional parameter?bbox_params. You need to pass an instance of?A.BboxParams?to that argument.?A.BboxParams?specifies settings for working with bounding boxes.?format?sets the format for bounding boxes coordinates.
It can either be?pascal_voc,?albumentations,?coco?or?yolo. This value is required because Albumentation needs to know the coordinates' source format for bounding boxes to apply augmentations correctly.
Besides?format,?A.BboxParams?supports a few more settings.
Here is an example of?Compose?that shows all available settings with?A.BboxParams:
transform = A.Compose([
A.RandomCrop(width=450, height=450),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
], bbox_params=A.BboxParams(format='coco', min_area=1024, min_visibility=0.1, label_fields=['class_labels']))min_area?and?min_visibility?
min_area?and?min_visibility?parameters control what Albumentations should do to the augmented bounding boxes if their size has changed after augmentation. The size of bounding boxes could change if you apply spatial augmentations 空间增强 , for example, when you crop 裁剪 a part of an image or when you resize an image.
min_area?is a value in pixels 是以像素为单位的值. If the area of a bounding box after augmentation becomes smaller than?min_area, Albumentations will drop that box. So the returned list of augmented bounding boxes won't contain that bounding box.
min_visibility?is a value between 0 and 1. If the ratio of the bounding box area after augmentation to?the area of the bounding box before augmentation?becomes smaller than?min_visibility, Albumentations will drop that box. So if the augmentation process cuts the most of the bounding box, that box won't be present in the returned list of the augmented bounding boxes.
Here is an example image that contains two bounding boxes. Bounding boxes coordinates are declared using the?coco?format.

?An example image with two bounding boxes
First, we apply the?CenterCrop?augmentation without declaring parameters?min_area?and?min_visibility. The augmented image contains two bounding boxes.
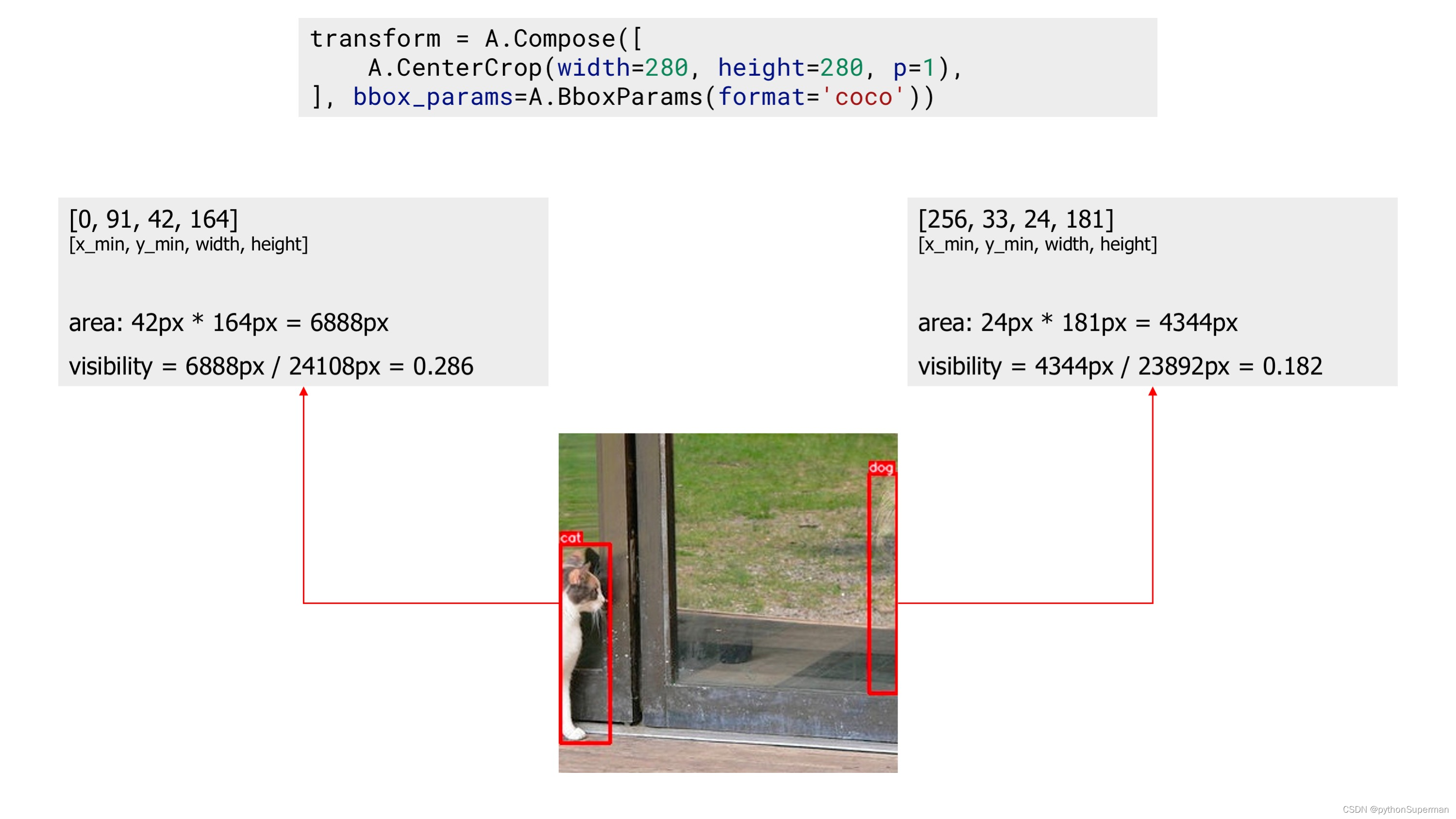
?An example image with two bounding boxes after applying augmentation
Next, we apply the same?CenterCrop?augmentation, but now we also use the?min_area?parameter. Now, the augmented image contains only one bounding box, because the other bounding box's area after augmentation became smaller than?min_area, so Albumentations dropped that bounding box.
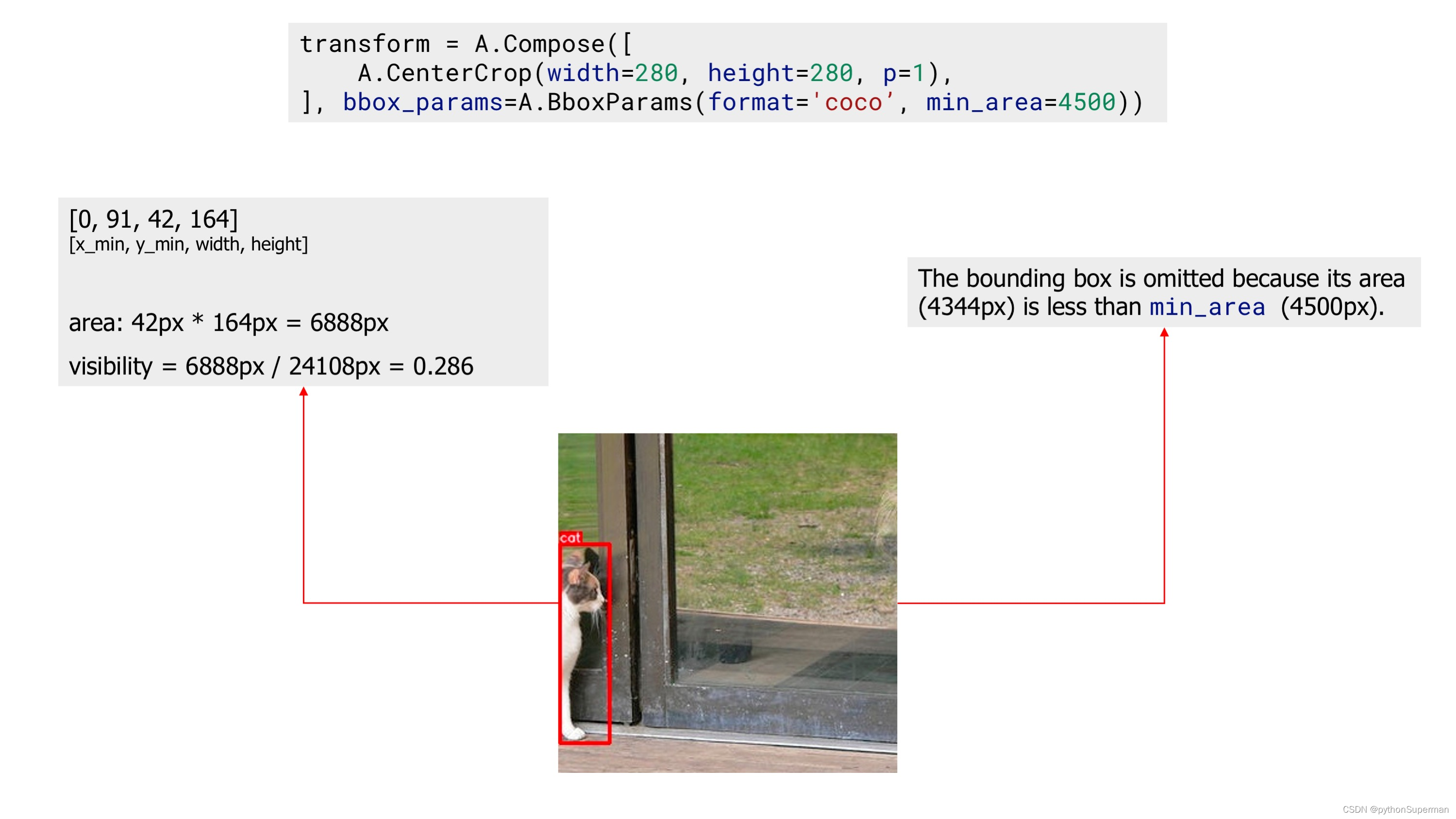
?An example image with one bounding box after applying augmentation with 'min_area'
Finally, we apply the?CenterCrop?augmentation with the?min_visibility. After that augmentation, the resulting image doesn't contain any bounding box, because visibility of all bounding boxes after augmentation are below threshold set by?min_visibility.
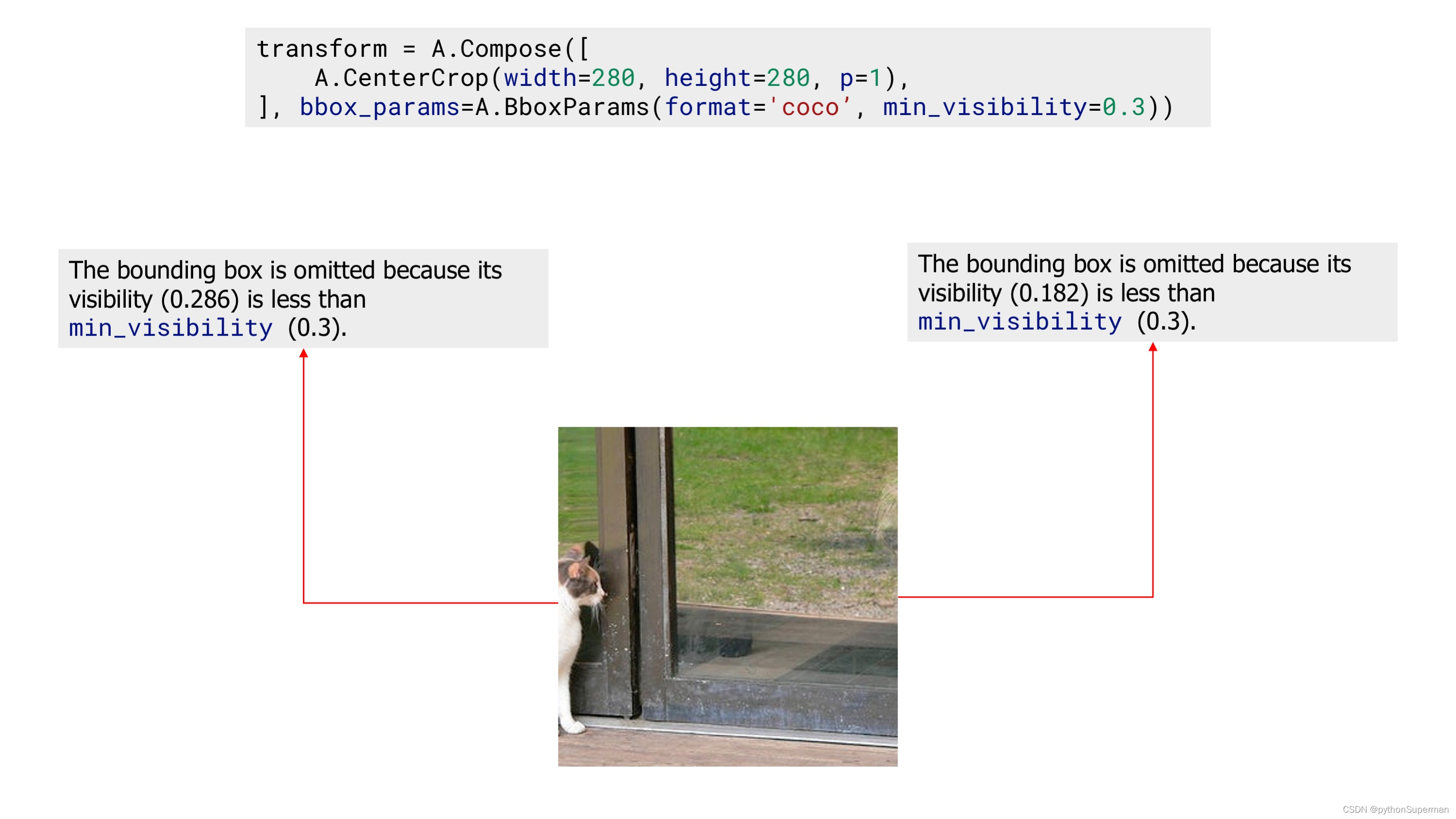
An example image with zero bounding boxes after applying augmentation with 'min_visibility'?
Class labels for bounding boxes?
Besides coordinates, each bounding box should have an associated class label that tells which object lies inside the bounding box. There are two ways to pass a label for a bounding box.
Let's say you have an example image with three objects:?dog,?cat, and?sports ball. Bounding boxes coordinates in the?coco?format for those objects are?[23, 74, 295, 388],?[377, 294, 252, 161], and?[333, 421, 49, 49].
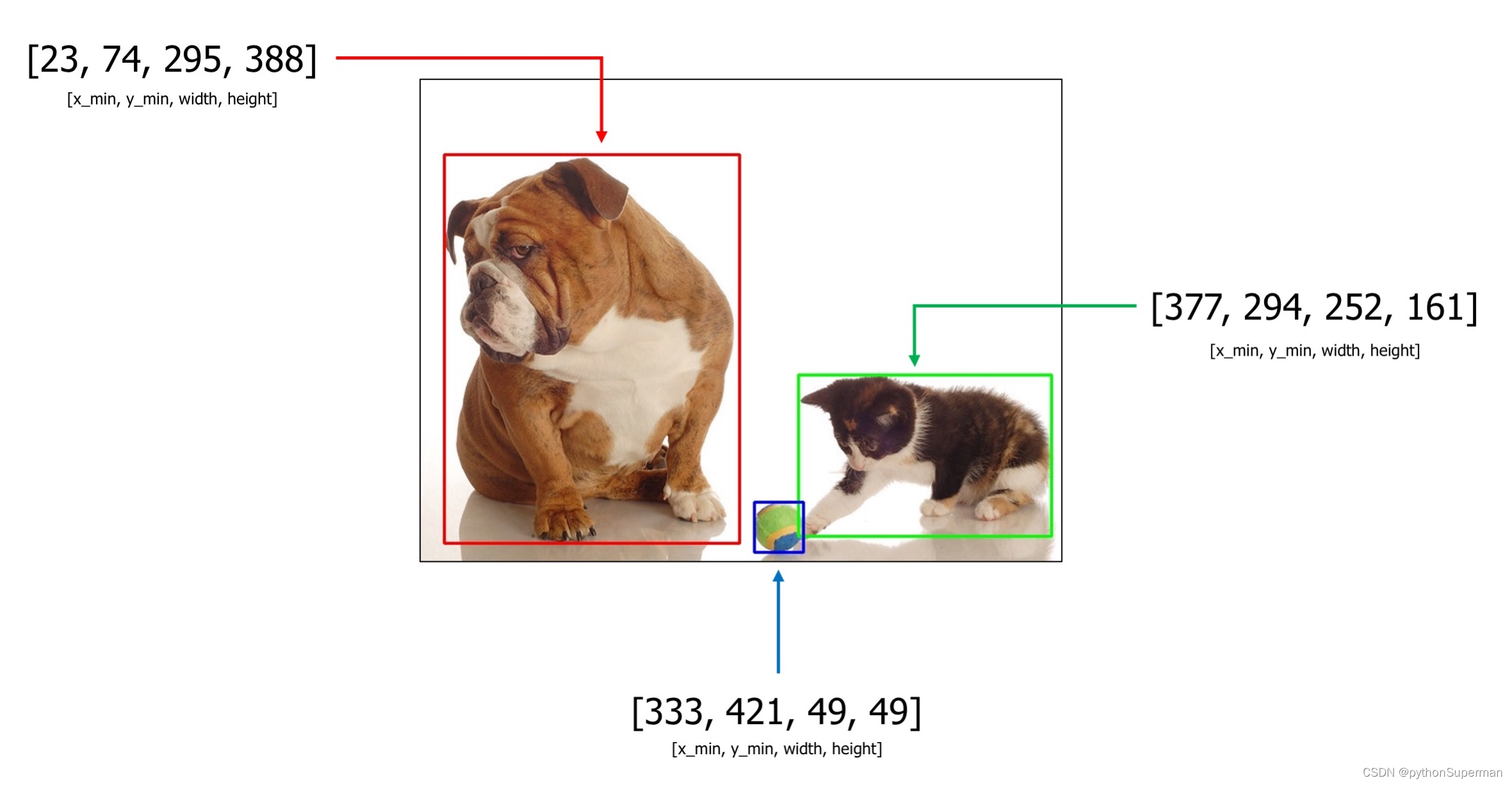
An example image with 3 bounding boxes from the COCO dataset
1. You can pass labels along with bounding boxes coordinates by adding them as additional values to the list of coordinates.?
For the image above, bounding boxes with class labels will become?[23, 74, 295, 388, 'dog'],?[377, 294, 252, 161, 'cat'], and?[333, 421, 49, 49, 'sports ball'].
Class labels could be of any type: integer, string, or any other Python data type. For example, integer values as class labels will look the following:?
[23, 74, 295, 388, 18],?[377, 294, 252, 161, 17], and?[333, 421, 49, 49, 37].
?Also, you can use multiple class values for each bounding box, for example?[23, 74, 295, 388, 'dog', 'animal'],?[377, 294, 252, 161, 'cat', 'animal'], and?[333, 421, 49, 49, 'sports ball', 'item'].
2.You can pass labels for bounding boxes as a separate list (the preferred way).?
?For example, if you have three bounding boxes like?[23, 74, 295, 388],?[377, 294, 252, 161], and?[333, 421, 49, 49]?you can create a separate list with values like?['cat', 'dog', 'sports ball'], or?[18, 17, 37]?that contains class labels for those bounding boxes. Next, you pass that list with class labels as a separate argument to the?transform?function. Albumentations needs to know the names of all those lists with class labels to join them with augmented bounding boxes correctly. Then, if a bounding box is dropped after augmentation because it is no longer visible, Albumentations will drop the class label for that box as well. Use?label_fields?parameter to set names for all arguments in?transform?that will contain label descriptions for bounding boxes (more on that in Step 4).
Step 3. Read images and bounding boxes from the disk.?
Read an image from the disk.
image = cv2.imread("/path/to/image.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)Bounding boxes can be stored on the disk in different serialization formats: JSON, XML, YAML, CSV, etc. So the code to read bounding boxes depends on the actual format of data on the disk.
After you read the data from the disk, you need to prepare bounding boxes for Albumentations.
Albumentations expects that bounding boxes will be represented 表示 as a list of lists. Each list contains information about a single bounding box. A bounding box definition should have at list four elements that represent the coordinates of that bounding box. The actual meaning of those four values depends on the format of bounding boxes (either?pascal_voc,?albumentations,?coco, or?yolo). Besides four coordinates, each definition of a bounding box may contain one or more extra values. You can use those extra values to store additional information about the bounding box, such as a class label of the object inside the box. During augmentation, Albumentations will not process those extra values. The library will return them as is along with the updated coordinates of the augmented bounding box 库将按原样返回它们以及增强边界框的更新坐标.
Step 4. Pass an image and bounding boxes to the augmentation pipeline and receive augmented images and boxes.?
As discussed in Step 2, there are two ways of passing class labels along with bounding boxes coordinates:
1. Pass class labels along with coordinates.?
So, if you have coordinates of three bounding boxes that look like this:
bboxes = [
[23, 74, 295, 388],
[377, 294, 252, 161],
[333, 421, 49, 49],
]you can add a class label for each bounding box as an additional element of the list along with four coordinates. So now a list with bounding boxes and their coordinates will look the following:
bboxes = [
[23, 74, 295, 388, 'dog'],
[377, 294, 252, 161, 'cat'],
[333, 421, 49, 49, 'sports ball'],
]or with multiple labels per each bounding box:
bboxes = [
[23, 74, 295, 388, 'dog', 'animal'],
[377, 294, 252, 161, 'cat', 'animal'],
[333, 421, 49, 49, 'sports ball', 'item'],
]You can use any data type for declaring class labels. It can be string, integer, or any other Python data type.
Next, you pass an image and bounding boxes for it to the?transform?function and receive the augmented image and bounding boxes.
transformed = transform(image=image, bboxes=bboxes)
transformed_image = transformed['image']
transformed_bboxes = transformed['bboxes']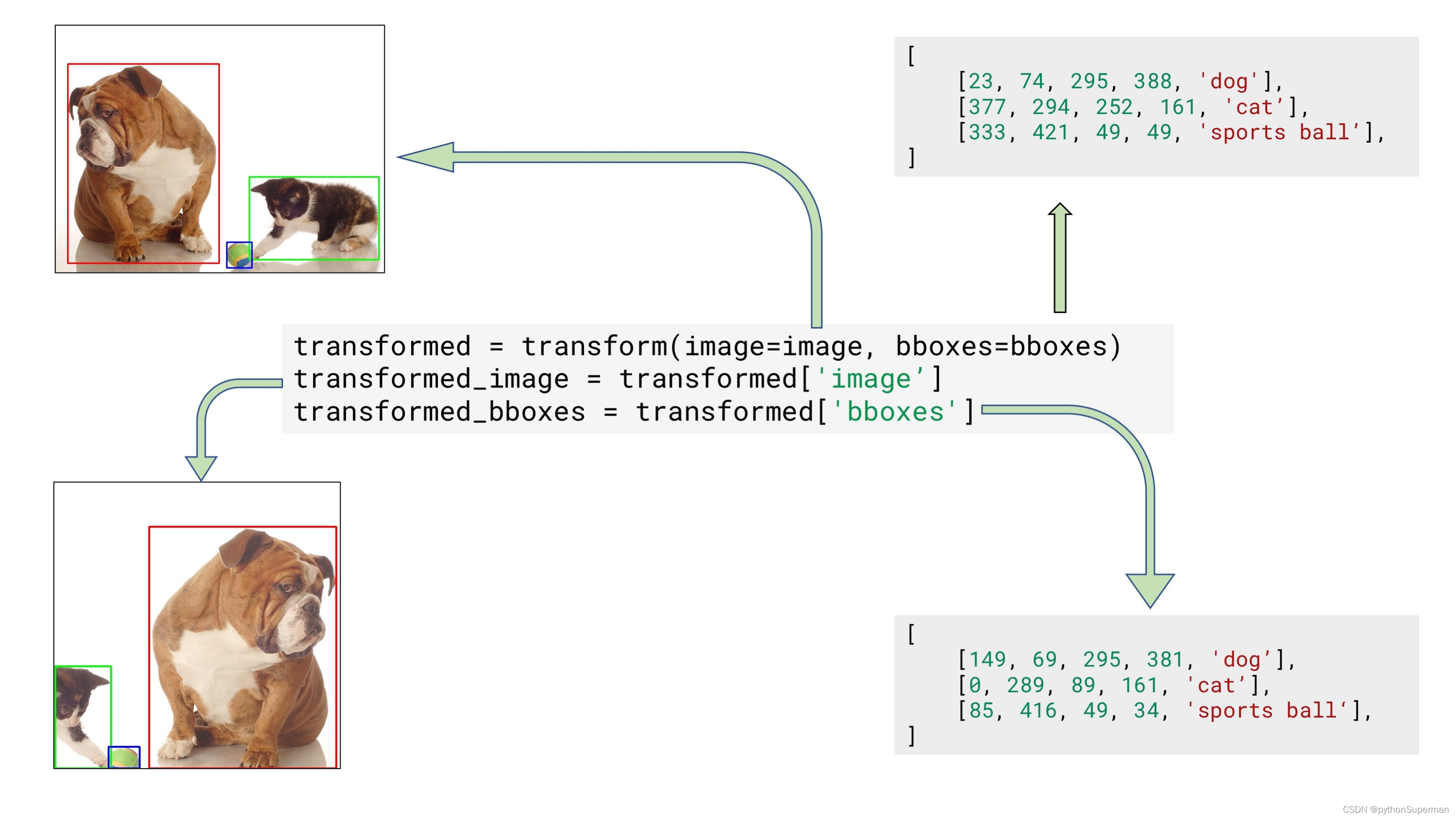
?Example input and output data for bounding boxes augmentation
2. Pass class labels in a separate argument to?transform?(the preferred way).?
?Let's say you have coordinates of three bounding boxes
bboxes = [
[23, 74, 295, 388],
[377, 294, 252, 161],
[333, 421, 49, 49],
]You can create a separate list that contains class labels for those bounding boxes:
class_labels = ['cat', 'dog', 'parrot']Then you pass both bounding boxes and class labels to?transform. Note that to pass class labels, you need to use the name of the argument that you declared in?label_fields?when creating an instance of Compose in step 2. In our case, we set the name of the argument to?class_labels.
transformed = transform(image=image, bboxes=bboxes, class_labels=class_labels)
transformed_image = transformed['image']
transformed_bboxes = transformed['bboxes']
transformed_class_labels = transformed['class_labels']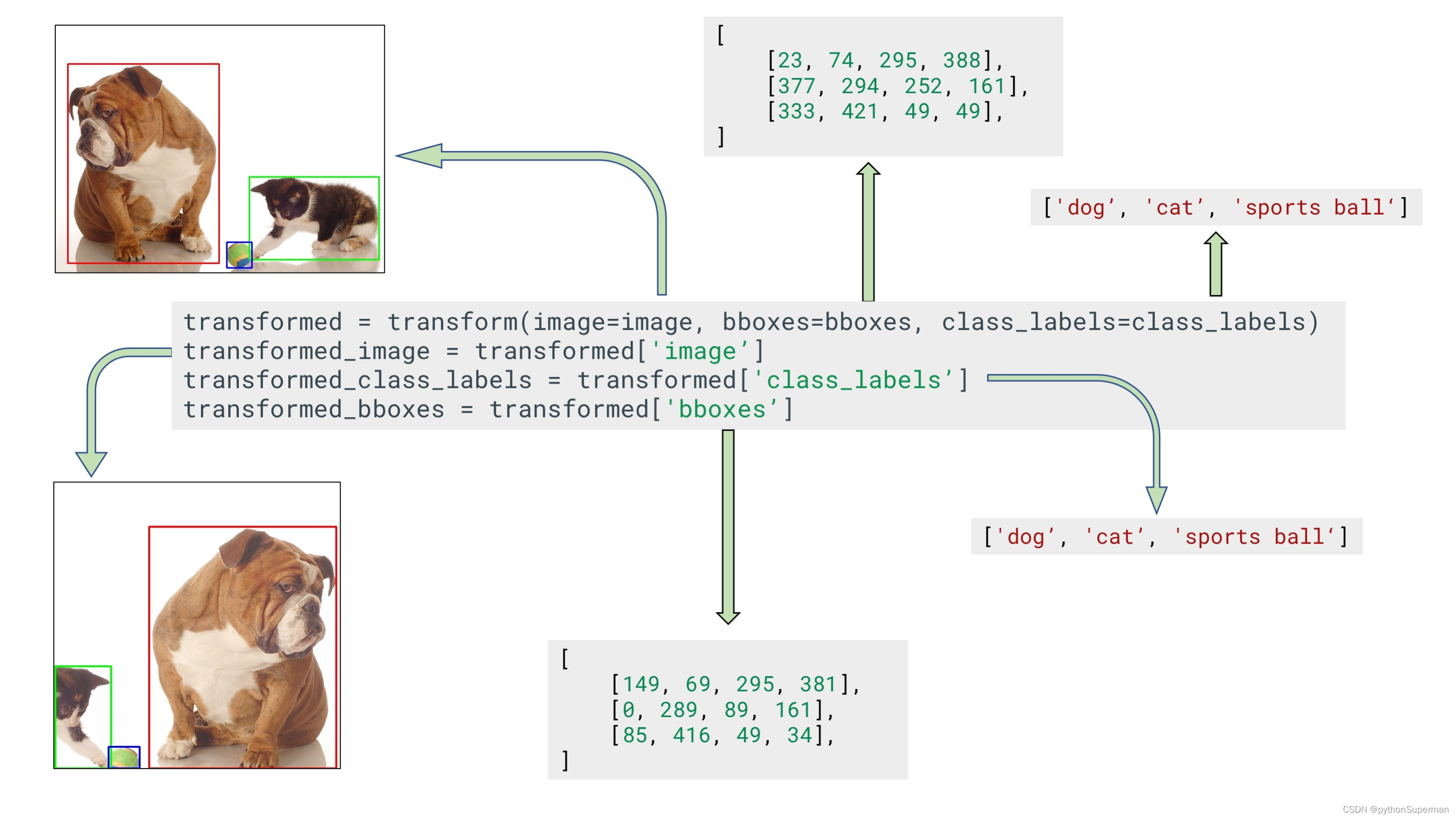
Example input and output data for bounding boxes augmentation with a separate argument for class labels?
Note that label_fields expects a list, so you can set multiple fields that contain labels for your bounding boxes. So if you declare Compose like
transform = A.Compose([
A.RandomCrop(width=450, height=450),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
], bbox_params=A.BboxParams(format='coco', label_fields=['class_labels', 'class_categories'])))you can use those multiple arguments to pass info about class labels, like
class_labels = ['cat', 'dog', 'parrot']
class_categories = ['animal', 'animal', 'item']
transformed = transform(image=image, bboxes=bboxes, class_labels=class_labels, class_categories=class_categories)
transformed_image = transformed['image']
transformed_bboxes = transformed['bboxes']
transformed_class_labels = transformed['class_labels']
transformed_class_categories = transformed['class_categories']本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!