Human Perception of Visual Information (2)
Chap2?Exploring Deep Fusion Ensembling for Automatic Visual Interestingness Prediction
1 Introduction
考虑到与当前在线环境相关的多媒体数据的流行,以及业余和专业内容创作者上传的大量数据,对上传数据进行深入理解的需求已经出现。为了帮助用户在能够正确理解用户偏好和平台上托管的多媒体内容的质量的在线平台中导航,需要自动分类和推荐系统。研究和开发社区目前越来越关注主观内容属性的研究,因此寻求了解视觉内容如何影响观众并相应地调整他们的算法。这代表了研究重点从以前的方向的转变,例如通过目标检测等客观属性来理解图像和视频的内容(He等人)2017)和场景分类(Yalniz et al 2019)。
视觉趣味性是目前研究中最流行的概念之一,在牛津英语词典中被定义为“保持或吸引注意力”的能力(Stevenson 2010)。Berlyne在心理学方面的初步研究(Berlyne 1949)表明,兴趣严重影响人类的行为和动机,而最近研究图像兴趣的作品(Chamaret et al 2016)表明,兴趣与观看和研究媒体样本的意愿呈正相关。许多研究人员还指出,在创造和维持兴趣方面,其他因素也很重要(Silvia 2005;H d i & Anderson 1992),如新颖性、应对潜力、觉醒和审美质量。从情感的角度来看,Silvia(20052009)将兴趣包括在与理解、探索和学习相关的情感类别中。
在这种背景下,很容易理解为什么研究人员和开发人员开始把精力集中在多媒体趣味性的预测上。给每个媒体项目分配一个有趣的值,可以代表一个视频是否符合用户的观看特征而被推荐给用户和被遗忘的区别,对这个主观概念的准确评估可以产生更多的用户参与度和满意度。另一方面,对于内容创作者来说,它将是一个有用的工具,无论是在线创作者、教授为课程选择媒体样本还是广告代理商,因为它可以从大量图像和视频中选择最合适的媒体样本进行分发。最后,值得注意的是,在目前的文献中,“趣味性”的概念被用来描述两个不同的概念:社交趣味性,通常与社交媒体概念,如人气和病毒式传播有关;视觉趣味性,被定义为媒体样本吸引和保持观众注意力的能力。
该领域之前的研究表明,这些概念既有Gygli和Soleymani(2016)的正相关,也有Hsieh等人(2014)的负相关,因此概念之间的联系仍然是一个开放的研究方向。然而,在本章的其余部分,我们将使用“趣味性”作为视觉趣味性的同义词。
在本章中,我们通过实现深度神经网络作为主要的集成函数,探讨了采用一组集成方法进行兴趣预测的可能性。据我们所知,这种类型的方法呈现出高度的新颖性,因为深度神经网络在当前最先进的文献中被用作诱导器,而不是作为主要的集成函数。我们的方法由几种架构组成,包括密集层、注意层、卷积层和新颖的跨空间融合层,以及两种输入修饰方法,有助于分析相似诱导因子之间的相关性。我们的方法在公开可用的Interestingness10k数据集(Constantin et al .)上进行了测试
2021a),在2017年中世纪期间得到验证。1预测媒体兴趣任务(Demarty et al . 2017a)。关于媒体兴趣度,Constantin et al(2019)代表了对兴趣度和协变量概念的深入文献综述,从心理学、用户中心和计算机视觉的角度分析了这些概念及其相关性,而(Constantin et al 2021a)代表了对中世纪预测媒体兴趣度任务的回顾,分析了最佳实践、方法、用户注释统计和数据本身。从集成的角度来看,有三篇论文介绍了我们将在这项工作中部署的一些深度神经网络架构:(Stefan et al 2020;Constantin等人2021年,2021 b)。我们将提供的建议方法对应的代码可以在网上获得,2是在Python 3中使用Keras 2.2.4和Tensorflow 1.12库开发的。
本章的其余部分组织如下。第2节分析了当前的最新技术,包括兴趣预测和后期融合系统。在第3节中,我们提出了媒体兴趣预测的方法。第4节给出了结果及其分析,指出了关于系统性能的趋势和一般建议。最后,第五部分对全文进行了总结,并对未来的发展进行了展望。
2.1 Media Interestingness
从计算机视觉的角度来看,媒体兴趣预测,通常指的是图像或视频样本的预测,在社区中获得了相当大的吸引力,近年来发表的关于该主题的论文数量显著增加(Constantin et al 2021a)。然而,这仍然被认为是一个开放的研究方向,因为改进结果的方法不断发表。预测有趣性的主要困难之一来自人类注释者的主观性。因此,当设计媒体兴趣度数据集或计算机视觉方法来解决这个问题时,可能会期望更低的注释者一致性和更小程度的有趣和非有趣样本之间的分离。已经使用了几种测量对人类兴趣的方法。例如,对于趣味性10k (Constantin et al .)
2021a)数据集,向注释者展示一对图像或视频,并要求他们选择两个样本中哪一个对他们更感兴趣,并要求他们考虑“所选的视频摘录/关键帧应该适合帮助用户决定他/她是否有兴趣观看电影”(Demarty et al . 2017b)。
早期的兴趣预测工作采用了几种传统的视觉特征。Gygli等人(2013)使用新颖性、美学和一般偏好作为图像有趣性的线索。新颖性通过局部异常因子方法编码,美学通过一组描述符编码色彩,唤醒,复杂性,对比度和边缘分布,一般偏好通过分析原始RGB(红绿蓝颜色空间)值,SIFT (Lowe 1999)和GIST (Oliva & Torralba 2001)特征和颜色直方图来计算。对于视频兴趣度的预测(Jiang et al . 2013),使用视觉、音频和高级属性在排序支持向量机(svm)方法。作者表明,由颜色直方图、SIFT、GIST、MFCC (Stein & Stanford 2008)、自相似性(Shechtman & Irani 2007)和光谱图SIFT (Ke et al 2005)组成的音频和视觉特征的多模态融合得到了最好的结果,预测精度为71.4%。Grabner等人(2013)也使用了类似的方法,利用传统描述符计算不同的概念。情感特征(Jou et al . 2015)和C3D模型(Tran et al . 2015)的性能Gygli和Soleymani(2016)比较了2015),有趣的是,情绪特征取得了更好的结果,Spearman的相关等级为ρ = 0.53。另一个有趣的结论来自Fan等人(2016),表明多个数据源的融合可以提高系统性能。
虽然这些研究提出了有趣的方法,但很难对它们进行比较,并提出一组可以增加良好性能的想法,因为它们使用不同的数据集、分裂和开发条件。
在这种背景下,MediaEval 2016和2017预测媒体兴趣竞赛(Demarty et al 2016, 2017a)通过创建一个共同的评估框架来解决这个问题,该框架由带有人工注释的兴趣值的图像和视频数据集、参与团队的共同分割和评估指标以及数据的开放可用性组成。大量系统被提交到两个版本的基准竞赛中,60个系统用于图像任务,69个系统用于视频任务,但在竞赛之外,在最先进的论文中,有17个图像处理系统和46个视频处理系统(Constantin et al 2021a)。虽然有许多不同的方法,但一个值得注意的方面是,这两个任务的最高结果可以被认为相当低,特别是与其他更传统和客观的任务(如物体检测或场景分类)相比。
例如,在基准测试比赛中,关于官方度量,平均精度(MAP)的最佳结果是,Permadi等人(2017)在图像预测任务中MAP = 0.3075, BenAhmed等人(2017)在视频预测任务中MAP = 0.2094。这些结果在竞争之外得到了进一步的改进,Parekh等人(2018)获得了图像任务的MAP = 0.3125的结果,Wang等人(2018)获得了MAP = 0.2228的结果。然而,Constantin等人(2021a)发表的一项关于标注过程的研究表明,考虑到表现最好的标注者的得分从未超过MAP = 0.7,人类标注者也没有达到近乎完美的分数。这进一步强化了这样一种观点,即这种任务的主观性是其主要挑战之一。虽然方法多种多样,而且在中世纪竞赛的背景下,大量的系统被用于图像和视频预测,但一个值得注意的趋势是,许多表现最好的系统都使用了某种融合方案。一般来说,融合被定义为“一种能够结合来自多个来源的信息以形成统一图像的技术”(Khaleghi et al . 2013),因此它涉及到结合多个检测系统的能力,以创建一个更好的最终系统。对于本文中分析的方法,融合应用于特征级(也称为早期融合),决策级(也称为后期融合或集成学习)或两者的结合。
2.2 Ensembling Systems
后期融合,也称为集成系统或决策级融合,由一组称为诱导器的初始预测器组成,这些预测器在数据集上进行训练和测试,其预测输出在最后一步中进行组合,以创建一组新的和改进的预测。这些系统有很长的历史,并且在单系统方法的性能不能令人满意的情况下被证明特别有用。虽然它们的有用性甚至在一些传统任务中得到了证明,例如视频动作识别(Sudhakaran et al . 2020b),但最近在主观任务中采用这种方法的趋势很明显,这些任务试图分析人类对多媒体数据的感知。这一趋势的一些例子包括媒体记忆性预测(Azcona等人2020年)、视频中的暴力检测(Dai等人2015年)、情感内容分析(Sun等人2015年)2018)和媒体趣味性预测(Wang et al . 2018)。
Wolpert(2002)阐述了集成系统的一个重要理论方面,他指出,给定以类似方式训练的N个诱导器的集成,这些诱导器的预测输出完全不相关是不可能的。因此,促进诱导组的高水平多样性可能会改善整体的最终结果。最近,Liu等(2019)表明,随着诱导剂误差的减小和诱导剂多样性的增加,集成误差可能会减小。在几篇综合文献综述论文(Gomes et al . 2017;Sagi and Rokach 2018)。
对于集成函数,用于组合诱导器预测输出的方法,虽然其中种类繁多,但深度神经网络仍然是该领域的新事物。据我们所知,我们使用深度神经网络作为主要集成函数的工作是在这个方向上的第一次尝试之一。到目前为止,集成函数主要采用简单的统计方法(Kittler et al . 1998),如通过加权算术平均值计算的后期融合、投票系统等。其他更复杂的方法采用需要初始学习步骤的方法,包括boost方法,如AdaBoost (Freund et al . 1999), Gradient Boosting (Friedman 2001)或XGBoost (Chen & Guestrin 2016), Bagging (Breiman 1996)或Random Forests (Breiman 2001)。虽然这些方法已经在几个任务中成功实现,但我们的假设是,随着深度神经网络作为主要集成函数的引入,后期融合结果将显著改善。在我们的工作中,我们将使用两种方法作为我们提出的预测方法的比较基线,即统计方法和boosting方法。
统计方法的一个例子是加权后期融合。在此格式下,给定一组N个诱导器方法,a = [a1, a2,…]。, aN],创建一组预测输出,表示为Y = [y1, y2,…], n],加权后期融合方法的目标是创建一组权重,W = [w1, w2,…],一旦应用于预测输出Y,就代表了对数据集的更好预测在研究中。也就是说,加权后期融合产生一个新的预测输出yw,计算公式如下:

该方法的目标是使预测误差最小化,使预测输出最小?w <
i, i ∈ [1, N]。在选择w值时可以采用几种策略,最常见的策略是根据诱导器的性能对Y向量排序,即
1 <
2 <…<
n。这将允许系统为更好的诱导剂分配更高的权重,从而确保表现最好的诱导剂决定最终结果。在向量是有序的假设下工作,一些这样的方案将是:?

Boosting代表了另一类重要的集成学习技术。一般来说,升压可以定义为在最终的集成系统中添加诱导器的迭代方式,同时随着系统中添加更多的诱导器而更新分配给每个诱导器的权重。虽然AdaBoost和Gradient boosting等不同的增强方法之间存在主要差异,但总体思路是诱导器权重的顺序训练,即尝试调整学习过程,以便纠正之前的错误。
AdaBoost识别每个学习步骤中诱导器的弱点,用未分类的数据点表示,并为这些点分配更高的内部权重,假设这将允许集成方案中的下一个分类器纠正这些错误。因此,给定一组数据点xi, i∈[1,M],初始这些数据点的所有权值设为wi = 1/M。每个诱导因子aj, j∈[1,N]的总误差可计算为:

?其中I是一个函数,对于真正或真负预测输出1,对于假正或假负预测输出0,C表示由集成方案创建的新分类规则。此外,给定每个诱导器的α因子,系统将相应地更新wi权重:
因此,考虑k是与预测任务关联的可能预测类的集合,则新的输出可以表示为:?

Gradient boosting:另一方面,不关注单个数据点,而是寻找预测集和真实数据之间的差异。因此,该方法的目标是最小化损失函数L(g, y),其中y表示该方法的预测输出,而g表示给定样本的基本真值。实际上,我们的目标是创建一个新的集合函数F,它最接近数据集的真实值:
?
在连续调用训练循环的过程中,梯度增强方法寻求应用梯度下降来优化集成结果。因此,最终版本的集成函数F可以表示为对一组近似函数h计算的加权和,从该函数的初始版本F0开始:?

式中,M表示训练步数。然后,根据先前的值更新函数,如下所示:?
3 Deep Ensembling?
在一般意义上,集成系统由一个算法或函数F表示,即给定一组M个数据集样本,记为S和一系列N个算法,记为a,使用所有N个算法的分类或回归输出,称为诱导器,并通过组合它们可以为M个样本中的每个样本创建一个新的输出。样本集的单个元素可以表示为si, i∈[1, M],表示向量S = [s1, s2,…?sM],而一系列算法可以用一组函数aj, j∈[1,N]来表示,表示向量a = [a1, a2,…aN]。
因此,可以构造包含元素yi,j, i∈[1,M],j∈[1,N]的矩阵Y(见式11),其中包含每个单独样本的每个诱导器的预测输出,其中每一行表示某个样本的诱导器输出。
获得单个样本i的最终集成预测输出包括使用[yi,1, yi,2,…], yi,N]电感器输出向量作为集成函数F的输入,从而得到最终预测值oi。整个过程如图1所示。虽然组合方法的一些变体可以用简单的数学函数来表示,即计算诱导器输出矢量的平均值,但其他函数可能更复杂,并且可能需要初步的学习阶段,如提升方法,如第节所示。2.2。我们提出了一种不同的观点,其中集成函数由深度神经网络表示,深度神经网络将处理诱导器预测输出值。

同样值得注意的是,虽然在更复杂的情况下,如多标签回归,由诱导器创建的预测并不表示单个值,因为一个输出概率分配给每个可能的标签,在我们的情况下,诱导器输出单个值,表示分配给每个图像或视频样本的兴趣程度。因此yi,j值是单维的。
考虑到这个总体框架,我们将在以下章节中提出一些新的观点,包括几种类型的深度神经网络,它们被用作预测媒体兴趣的集成函数。
在这种情况下,我们的假设是dnn能够更好地理解单个诱导器对数据集中样本的模式和偏差。我们提出的深度神经网络模型将只使用诱导器输出来确定最终的预测分数,因此图像和视频样本不会被馈送到集成算法中。
我们研究了以下四种类型的DNN架构:(i)基于密集层的方法,即(ii)注意层的增强,(iii)卷积层,以及(iv)跨空间融合层(CSF),这是一种用于解析诱导向量的新方法。前两种网络不需要任何特殊的数据预处理,后两种网络,即卷积网络和CSF网络,旨在根据数据的空间排列来处理数据,并了解如何解释矩阵中的相邻元素以获得预测。
虽然卷积层在图像和视频中大量利用了这一点,但诱导输出向量没有内在的空间排列和相关性,因此,对于这两种最终类型的神经网络来说,创建空间信息的一些数据预处理和装饰方案是必要的,我们将与各自的DNN模型的实现一起介绍。
我们推测这种结构能够创建更好的集成系统的主要原因之一是神经网络能够准确地使用各种类型的输入数据并将这些数据分类为输出预测。虽然没有直接尝试模拟人类行为和对视觉趣味性的理解,但我们相信这些模型能够模拟诱导者的行为和理解,从而能够学习诱导者对视觉样本的积极和消极偏见。
因此,虽然这里提出的方法都是围绕着视觉趣味性的预测,但它们是独立于领域的,在其他任务中也很有用(Constantin et al . 2021b)。
3.1 Dense Networks
由完全连接(或密集)层组成的密集网络可以说是最流行的深度神经网络实现之一。考虑到致密层固有的正确检测输入数据模式和准确分类样本的能力,我们的理论是,通过使用一组连接的密集层,我们提出的方法将能够准确地学习诱导偏差之间的相关性(Mitchell 1980),允许基于网络学习模式的诱导组合支持或否定它们的预测。
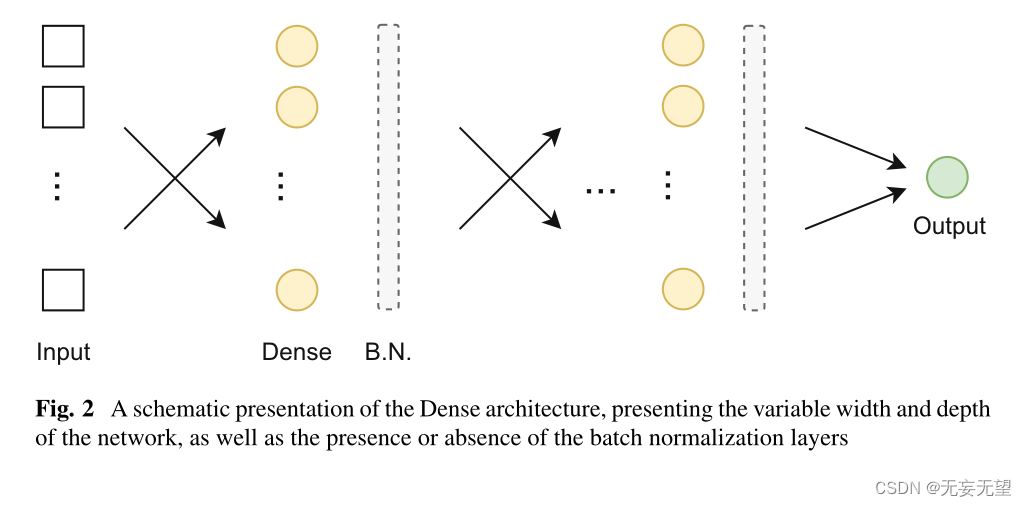
最终网络的另一个组成部分是通过在各个密集层之间添加批归一化层(Ioffe & Szegedy 2015)来表示的,其作用是帮助改善网络的学习过程并加快其速度。为了确保最优的性能,我们测试了几种不同的密集网络设置。在算法1中提出了最优网络结构搜索方法。因此,我们通过测试网络中的不同层数(5,10,15,20,25)来改变网络的深度,通过改变每层神经元的数量(25,50,500,1000,2000)来改变网络的宽度。该搜索算法中的第三个参数由批规范化层的存在与否表示。同样,在算法1中,processDense函数既具有根据三个变量参数创建网络的作用,又具有训练和测试创建的网络的作用。密集网络架构的示意图如图2所示。
?
3.2 Attention Augmented Dense Networks?
尽管计算注意力机制(Bahdanau et al . 2014)最初主要用于处理文本处理和翻译的作品,但它很快被应用于其他领域,包括计算机视觉(Xu et al . 2015)。一般来说,注意机制的作用是理解和检测输入空间中对最终预测阶段最重要的部分,并为重要部分分配更高的权重。虽然在一般的计算机视觉中,这些机制会推断出图像或视频中最重要的部分,但在我们的集成系统中,直觉是注意层将创建一组权重w,这将表明来自诱导器输出向量[yi,1, yi,2,…]的每个值的相关性。, yi,N]。
我们为实验选择的实现包括将一个软注意层插入到3.1节所示的密集架构中,如图3所示。使用Eq. 12中的符号表示单个样本i的网络输入空间,软注意向量为attni,其值在0到1之间,系统将创建一个适当的注意掩码?attni,作为输入向量和注意向量的元素明智乘积计算,如Eq. 13所示。注意机制的学习过程基于监督反向传播方法:

 ?
?
3.3 Convolutional Augmented Dense Networks?
卷积网络代表了计算机视觉领域深度学习的一大进步,得益于硬件处理能力和软件库的进步,这些网络可以轻松部署并降低处理时间,从AlexNet在ILSVRC 2012基准测试比赛中的表现开始(Krizhevsky et al 2012)。虽然输入空间的形状并不重要,但作为一维、二维或三维卷积网络的实现,它们都依赖于检测和学习输入空间中相邻元素之间的局部相关性。
更重要的是,卷积可以用一组预先确定形状的过滤器来表示,这些过滤器覆盖并处理整个输入空间。虽然这种方法在图像和视频中表现良好,在输入空间中本质上具有空间排列和相关性,但在我们的特殊情况下,在yi向量中诱导器预测输出的顺序没有任何内在的空间相关性,而且,在这个阶段,没有计算单个诱导器之间的关系。因此,我们必须通过我们称之为输入装饰的过程来创建这些关联和关系。
在这种情况下,我们的假设是,通过为每个样本i创建卷积处理dci的装饰输入向量,并对这个新输入应用卷积滤波器,我们将能够创建一个系统,其中类似的诱导器可以安排在紧密的空间邻近,并且可以根据它们的空间关系支持或撤销它们的预测决策。因此,为了将卷积引入集成网络,必须解决两个问题:(i)找到检测诱导体之间相似性的标准,以及(ii)基于相似性创建空间安排。
对于第一个问题,可以借助用于测量任务中系统性能的官方度量来计算单个诱导器之间的相似性。在使用10个元素的兴趣度平均精度的情况下(mAP@10),在广义方法中,度量可以表示为自动视觉兴趣度预测45函数M的探索深度融合集成,该函数将两个向量作为输入(ground truth数据和预测数据或来自两个独立系统的两个预测向量),并输出它们之间的相似度值,表示为r。给出预测向量pj = [y1,j, y2,j,…]的一般形式。, yM,j],表示诱导剂j对数据集中所有M个样本创建的预测向量,则两个诱导剂M和n之间的相似性值可计算如式14所示。
最后,通过排序诱导因子m与所有其他诱导因子之间的相似性得分向量,我们可以为N个诱导因子中的每一个创建一个最相似的诱导因子列表。

第二个问题涉及使用前一步计算的相似性值,并根据r值修饰每个样本的预测。样本i的修饰输入向量如Eq. 15所示,它由围绕初始诱导器预测输出值构建的质心组成,表示为s1, s2,…。, sN。每个质心中的元素如下:(i)中心元素sj表示初始值;(ii)前四个最相似的诱导因子的相似度得分,记为r1,j,…。R4,j和(iii)从前四个最相似的诱导剂中提取的样本I的预测输出,表示为c1,j,…c4, j。算法2给出了单个样本i的修饰过程,可以很容易地推广到数据集中的所有样本。

?装饰好的dci阵列将代表卷积集成系统的新输入,如图4所示。最后,对dci数组进行逐质心的卷积层处理。公式16显示了单个质心i的这个过程,其中质心是按元素与卷积滤波器中的权重相乘。在我们的例子中,最后一步涉及到一个平均池化层,该层将为卷积步骤输出单个元素,该步骤表示逐元素乘法结果矩阵的平均值。


 ?3.4 Cross-Space-Fusion Augmented Dense Networks
?3.4 Cross-Space-Fusion Augmented Dense Networks
通过在网络中引入卷积层,建立了一种处理诱导因子之间相似性的方法。然而,卷积网络是以图像处理为主要目标而创建的,并且使用相同的过滤器来处理整个图像,因此,在集成系统的情况下,不同质心之间共享相同的权重。虽然这确实代表了在处理诱导剂相关性方面向前迈进了一步,但我们的假设是每个单独的诱导剂之间的相关性是不同的,因此权重不应该在质心之间共享。鉴于这一假设,我们建议创建一种新型的深层神经网络层,我们将其命名为“交叉空间融合”,即CSF层。CSF层的实现是基于创建一个新的输入装饰方法和层本身的创建。
为了充分利用我们生成的相关数据并克服卷积处理可能的限制,必须采取一些架构决策。首先,如Eq. 16所示,诱导器输出和相似度得分没有一起处理,而是分别与对应的卷积权值相乘。这可能会破坏两个元素之间的相关性,使神经网络更难处理和学习。其次,无论我们使用哪种类型的卷积层,都可能出现同样的问题,因为三维卷积层不处理维度间的相关性。因此,我们提出了一种新颖的输入修饰方法,它将创建一个额外的第三维度,它将分别记住相似的诱导器输出和相似分数。
此外,CSF层需要在阵列的第三个维度上处理这些细节,同时处理诱导器输出和相应的相似性得分,同时使用Eq. 14函数中提供的相同M来计算相似性得分。最后,如前所述,我们必须考虑到常规卷积过滤器可能不是学习相关性的最佳方法,因为它们可能在质心之间不同。因此,必须在CSF层中设计更多的参数,虽然这可能代表神经网络的应变,但添加的参数数量仍然很少,特别是与密集结构的深度和宽度相比。?

考虑到这种方法的特殊性,Eq. 17给出了修饰输入的新版本,其中Ci表示8个最相似的诱导因子对诱导因子i的预测输出矩阵,而Ri表示它们各自的相似性得分,通过M函数计算。这两个矩阵创建了装饰输入的第三个维度,如图5所示。与卷积方法类似,在本例中,c1,i和r1,i对表示最相似系统的预测输出和相似度评分,其中诱导因子i, c2,i和r2,i是第二相似的系统,以此类推。
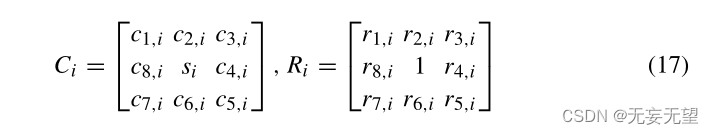
虽然很明显,通过使用这种装饰方案,可以将更多类似的诱导器添加到系统中,但在类似的卷积方法中,它们对该任务的效用问题仍然存在,并将进行分析,因为插入到系统中的新数据可能是有噪声的或者系统之间几乎不存在实际相关性。?
算法3给出了输入修饰算法。值得注意的是,在CSF方法的情况下,dci装饰输入数组的形状再次发生变化,从卷积方法中的(3×N, 3)变为(3×N, 3,2),大小增加了一倍。在装饰步骤之后,输入被送入CSF层。对于每一组(ci, ri)质心,网络必须创建并学习一组权重,这些权重可以将初始诱导器预测与质心中分组的预测输出和相似性分数结合起来。因此,脑脊液层包含一组必须学习的α和β参数。公式18描述了CSF层所执行的操作,其中α用于控制每个诱导剂i的预测输出,β参数用于控制与i相似的诱导剂的预测输出和相似分数。

 ?
?
图6给出了这种方法的概要。如上所述,该方法的CSF增强部分的最后一步是通过添加一个平均池化层来表示,从而获得一个等维的输入作为密集结构的初始输入。同样,在诱导剂数目N不变的情况下,CSF层的最终参数数为16×N,其中α和β参数为8×N。如前所述,我们还必须考虑这样一种可能性,即在质心中添加如此多的类似电感可能会给输入增加噪声并损坏最终结果。
因此,我们决定测试CSF架构的两种不同设置:4S仅在(ci, ri)质心对中填充前4个最相似的诱导器,在8S中,质心对中完全填充了8个诱导器。值得注意的是,虽然我们的实验可能显示出对两种设置中的一种的偏好,但在其他可能使用其他数据集或诱导剂的实验中,这些结果可能相反,或者使用不同数量的填充相似诱导剂的其他设置可能产生更好的结果

?4 Experimental Setup
本节将介绍实验的主要组成部分以及这些组成部分如何相互作用。我们将描述用于实验的训练协议,数据集和用于获得结果的评估协议。
4.1 Training Protocol
在第3节中介绍的所有方法中的共同成分由密集结构深度神经网络表示。因此,我们的实验将从寻找关于网络深度和宽度以及批归一化层的积极或消极影响的最佳密集架构开始,使用第3.1节中提供的值。这是通过收集整个诱导器集的预测输出并将它们输入到密集架构网络的不同变体中来完成的。算法1描述了这一步。在接下来的步骤中,对最优密集网络进行注意层、卷积层和脑脊液层的增强。作为卷积层和CSF层的特殊实现,根据卷积方法的算法2和CSF方法的算法3,对由预测输出组成的输入进行装饰。
对于网络的每个变化,使用64个样本的批处理大小、均方误差损失函数和学习率为0.01的Adam (Kingma & Ba 2014)优化器,执行50个epoch的训练过程。我们感兴趣的是指出最优的密集架构,给定一组搜索参数,以及用三种类型的层(注意力层、卷积层和CSF层)增强密集网络的效果。
4.2 Dataset
在我们的实验中,我们使用了最新版本的Interestingness10k (Constantin et al . 2021a)数据集,该数据集在MediaEval 2017预测媒体兴趣任务(Demarty et al . 2017a)中进行了验证和使用。该数据集由9831个图像和视频组成,分为开发集(devset)中的7396个样本和测试集(testset)中的2435个样本。基准测试竞赛的参与者的任务是在devset上开发和训练他们的媒体兴趣预测方法,在测试集样本上运行系统,并将他们的测试集预测提交给任务组织者进行性能计算。
考虑到在基准测试竞赛中提交的大量系统,即图像任务33个,视频任务42个,以及为创建它们而进行的大量研究和工作,我们认为这些系统是在我们提出的方法中用作诱导器的理想候选者。在任务组织者的帮助和协作下,我们收集了参与者提交文件,并将其用作系统的输入。然而,考虑到参与者只提交了测试集样本的预测,以及重建如此大量不同系统的固有问题,我们必然只使用这些预测并创建一个新的评估协议,该协议将用于训练我们的系统,仅基于测试集中的特征样本。
因此,我们必须创建一组新的数据分割,并选择使用两种协议:(i) RSKF75,具有随机分层k-fold,使用75%的样本进行训练,25%用于测试,以及(ii) RSKF50,生成50%的训练样本和50%的测试。值得注意的是,为了避免任何可能为我们的方法创造不公平优势的“幸运”数据分割,分割样本是随机的,并且使用不同的随机分割重复实验,为每个网络架构变化生成100个分区。因此,我们在第6节中给出的结果是在100个分区上计算的平均值。
系统性能是通过使用MediaEval基准测试竞赛的官方度量来计算的,即MAP@10。
5 Experimental Results
本节介绍了实验结果,包括与一组基线系统、一组基线集成方法的比较,并确定了性能最佳的体系结构
5.1 Baseline Systems
为了正确定位和分析所提出方法的结果,我们将它们与文献中的一些方法进行了比较,包括
(i)最好的中世纪竞赛者
(ii)在Interestingness10k数据集上的最佳整体表现,以及
(iii)一套传统的合奏方法。从中世纪竞赛中获得的最佳表现也代表了我们系统的诱导因子,以及所提议系统的重要目标。对于图像预测任务,我们使用Permadi等人(2017)开发的系统,其MAP@10性能为0.1385,而对于视频预测,我们使用Ben-Ahmed等人(2017)开发的系统,其MAP@10性能为0.0827。
总体执行者包括在MediaEval场所之外发布的方法,但使用相同的基准测试协议和指标。对于图像任务,我们有Parekh等人(2018)的工作,其性能为MAP @10 = 0.156,而对于视频任务,Wang等人(2018)实现了MAP @10 = 0.093。
最后一组基线系统由一组传统的集成方法组成,我们使用与我们提出的方法相同的协议和一组诱导剂创建了这些方法。测试了几种类型的集成方法,从简单的策略(Kittler et al . 1998)开始,如取诱导器预测输出的最大值(LFMax)、平均值和平均值(LF Avg和LFMean)和加权平均值(LFWeight),以及涉及学习步骤的更复杂的方法,如AdaBoost (Freund et al . 1999) (BAda)和Gradient Boosting (Friedman 2001) (BGrad)。
5.2 Results
结果如表1所示。乍一看,值得注意的是,所提出的系统超过了所有基线系统,包括性能最好的基线集成系统,这对于图像和视频都是AdaBoost方法。此外,所建议系统的最佳性能变体大大提高了性能。考虑RSKF75分割,图像子任务比最佳MediaEval系统增加了148.08%,比最佳整体系统增加了73.09%,比最佳传统集成系统增加了105.25%,而视频子任务分别增加了241.59%,203.76%和150.22%。

对于整体表现最好的方法,结果各不相同,卷积方法在使用RSKF75分割的图像任务(MAP@10 = 0.3436)和使用RSKF50分割的视频任务(MAP@10 = 0.1692)上的结果最好,而CSF方法在使用其他两种变体时的结果最好,在RSKF50设置下的图像预测得到的MAP@10值为0.2403,在RSKF75设置下的视频预测得到的MAP@10值为0.2825。
同样重要的是要注意导致这些结果的结构变化,即最佳的密集、卷积和CSF结构设置。对于图像预测,最优的密集架构使用10层,每层1000个神经元,不进行批处理归一化,RSKF50的MAP@10值为0.2316,RSKF75的MAP@10值为0.3355,而表现最好的卷积架构使用5个滤波器。此外,在这种情况下,最佳的CSF设置是4S。
对于视频预测,
最优密集设置由25层组成,每层2000个神经元,并具有批处理归一化特征,RSKF50的MAP@10值为0.1563,RSKF75的MAP@10值为0.2677。关于卷积结构,最佳设置再次具有5个卷积滤波器,而4S再次代表CSF层的最佳设置。虽然密集网络的性能很好,但注意层,特别是卷积层和CSF层的增强过程进一步提高了结果
关于网络设置的最后一个观察结果见表2。
在我们的实验中,我们观察到网络在某些点上停止学习并达到饱和。虽然表2给出了一个特殊的设置,对于具有批处理规范化层和RSKF75分割的视频任务,无论任务、批处理规范化层的存在或分割,都可以观察到相同的行为。在本例中,在保持层数不变为5的情况下,增加超过1000个神经元的数量只会降低性能,而增加54个神经元的数量也是如此
层数超过20层时,每层保持恒定数量的25个神经元。最重要的是,这似乎表明,最优网络设置并不在我们在实验中测试的一组值之外。另一个重要的一点是,即使在最基本的设置(5层,每层25个神经元)的值上,所提出的方法也具有很高的性能,得分MAP@10值为0.2414,比性能最好的密集架构低9.82%,但仍然明显优于所有选择的基线方法。

6 Conclusions?
这项工作提出了一系列基于深度神经网络的集成系统的创建和部署,用于图像和视频兴趣的预测。
我们的实验中使用了最新的Interestingness10k数据集,该数据集之前在MediaEval 2017预测媒体兴趣任务中使用并验证过。尽管大量的系统在MediaEval基准测试竞赛期间和它之外,在不同的期刊和会议上使用该数据集,但与其他任务相比,系统性能通常较低,即图像兴趣预测的最大MAP@10性能为0.1985,视频预测的最大MAP@10性能为0.093。
虽然对于这样的任务来说,并不一定期望非常高的、近乎完美的性能,在这些任务中,注释者的主观性起着重要的作用,但我们认为集成系统的实现可以提高整体性能。此外,将深度神经网络作为集成函数的探索在当前文献中呈现出高度的新颖性,因为当前文献表明它们仅被用作诱导器而不是集成函数。
本文提出并测试了不同的网络设置,包括基于密集层、注意力层、卷积层和CSF层的架构,介绍了将这些架构作为集成函数实现的理论背景,并介绍了输入修饰算法,该算法允许使用诱导器预测输出数据,并在这些架构的帮助下学习诱导器相关性。
实验结果表明,与最先进的系统相比,性能有了显著提高。我们提出的方法在图像预测任务中的性能比最好的中世纪系统提高了148.08%,比最好的最先进的系统提高了73.09%,而在视频预测任务中的性能提高更高:241.59%和203.76%。此外,将所提出的集成方法与传统的集成方法进行了比较,结果表明,在相同条件下,所提出的集成方法在图像任务和视频任务上的性能分别提高了105.25%和150.22%。虽然使用其他网络设置(具有不同数量的层或神经元,或不同的架构)当然可能获得更好的结果,但我们相信深度融合系统的优势将得到充分展示。
考虑到结果,目前尚不清楚两种基于诱导剂相关性的架构(卷积或CSF)中哪一种在这项任务中表现更好,最优结果将在它们之间分配。然而,重要的是要注意诱导相关处理确实改善了密集网络和基于注意的网络的结果,从而表明了诱导相关计算、输入修饰和相关处理的有效性
最后,另一个重要的点,不仅是对于我们提出的方法,而且对于一般的集成系统,是对所提出系统的可部署性的分析。考虑到诱导器必须单独进行训练、测试和运行,并且在提供最终预测之前进行最后的集成步骤,因此使用晚期聚变方法可能成本很高,因此在某些情况下,开发晚期聚变系统可能是必要的。关键基础设施应用,其中非常准确的预测结果是一个持续的需求,代表了一个很好的例子,但是,更接近兴趣预测领域,由于固有的多模态或正在预测的概念的复杂性,单方法方法不能很好地执行的应用,代表了另一个很好的例子。
虽然部署集成方法可能会被证明成本更高,但它也可能是实现市场水平性能的唯一方法之一,允许引入可以大大提高用户满意度的新功能。在这种情况下,我们还考虑这样一种可能性,即降低诱导器的数量可能不会对系统性能产生很大的影响,因此可以用微不足道的性能换取更高的执行速度和更低的硬件需求。虽然诱导剂选择方法的创建对于我们的方法来说仍然是一个悬而未决的问题,但我们建议未来的发展可以通过分析诱导剂相关性或通过在递归的留一个场景中测试性能来解决这个问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!