CLIP 改进工作串讲(上)【论文精读·42】
????????大家好,今天这个串讲其实是主要想说一下在过去一年中,大家是怎么把 CLIP 这个模型或者 CLIP 这个思想应用到其他领域中去的。本来是想先做一下这个多模态的串讲的,但是就在前几天看到了 CLICK puzzle 这篇论文,获得了这个今年 c GRAPH 的最佳论文,所以突然觉得先串讲一下这个 CLIP 的一些后续工作,可能对讲接下来的这个多模态学习也有一些帮助,所以就先做了这一期的串讲。

????????那其实自从 CLIP 去年大概2月底的时候出来,在过去的一年半的时间里,已经被应用到方方面面的各个领域里去了,比如说用到分割里就有Lseg,还有group。VIT。用到目标检测里就有viewed,还有 clip V1, clip V2,当然在目标跟踪里也有对应。的工作。然后如果放在视频里也有 video clip,然后 clip four clip,还有。action clip。还要把 clip 用到很多别的领域,比如说用到 Optical flow depth 里,这有 depth clip,然后还有这个 3D 里的这个 point clip,然后还有甚至用到这个语音里的 Audio clip,然后在图像生成这边也有这种 clip puzzle 或者 VQ gan?clip,还有上次我们提到过的 clip draw 以及就到了这个多模态领域。最近也有一篇论文说这个 clip 模型,那到底能对这个 vision language 的下游任务起到一个怎样的提升作用?所以说 CLIP 真的是被用到了方方面面,那鉴于有这么多论文,可能我一次串讲也讲不完,今天可能主要就先说的是这个分割和目标检测。
1 CLIP简单回顾
????????那在开始之前我们先快速回顾一下CLIP,就是用对比学习的方式去训练一个视觉语言的多模态模型,它的训练方式非常简单,就是给定一个图像。文本,对。图像通过这个图像的编码器文本,通过文本的这个编码器就会得到一系列的这些图像文本的特征。那这个对应的图像文本,对,也就是这种 IET 一I2、 T2 一直到INTN,它们就都算是正样本,因为这个文本描述的就是这个图片,但是所有不是对焦线上的元素,它就都是负样本了。作者这里就假设,比如说TN,它肯定就不是在描述I3,它们之间没有对应关系,所以就是负样本。然后就用这么一个简单的对比学习的目标函数,在超大规模的这个 4 个亿的图像文本对上,训练完之后,这个 CLIP 模型就获得了强大的性能,尤其是这个 Zero shot 的能力,简直是让人。叹为观止。那在推理的时候,如果你想给任意的一张图片去做这个分类,你这时候就可以把它可能的那些标签全都通通的做一个这个template,就说这是一个什么什么样的图片,然后把这些所有的文本都传给这个文本编码器,你就会得到一系列的这个文本特征,那你这里有多少个标签,你最后就会得到多少个文本特征,就相当于你给定一张图片之后,你不停地问它,你这个图片里有没有个狗?你这个图片里有没有个飞机?你这个图片里有没有只。鸟?然后你通过这样不停地问,其实就是不停地去算这个图像特征和这些所有的文本特征之间的相似度,最后你就会得到一个。最大的相似度。CLIP 模型就认为这个最大的相似度所对应的那个文本标签就是你这张图片的标签。类别。所以说做起推理栏非常的灵活,真的是 Zero shot。
2 领域一:分割
????????那简单回顾完了CLIP,那接下来我们就来串一下今天要讲的第一个领域就是分割,这个任务其实跟分类很像,它无非就是把这个图片上的这个分类变成了这个像素级别的分类,但是往往在图片分类那边用的这个技术都能直接用到这个像素级别的分类上来。这也就是为什么过去几年分割这个领域这么的卷,而且论文非常的多。如果你去看 paper with code,你去查每个领域的论文,你就会惊奇地发现分割的论文竟然是最多的,我记着我去年查的时候就有几千篇。因为每当分类那边有什么技术出来以后,分割这边就可以直接拿来用,那这个模型的backbone,这样就不用多说了,那分类那边用了自注意力,分割这边也有了自注意力。分类那边有对比学习,分割这边紧接着就出了这个密集对比学习,那分类那边用了Transformer,分割这边迅速 set tra SEC former, mask former 就全来了。分类那边用了 seed labeling,分割这边也很快用了 seed labeling,
2.1 Lseg:分割的 Zero shot
????????那这回也不例外,分类有了CLIP,那怎么能少了分割的 Zero shot 呢?
2.1.1 分割效果非常好
????????很快今年的这个ICLEAR。2022。就有一篇论文,直接拿 clip 预训练的模型去做这种 language driven 的语义风格,而且这篇论文的方法非常的简单,写的也很好,所以我们就从这篇文章开始。那我们先来看一下这篇论文的图一看一看 Zero shot 的分割效果有多么的好。

????????在这用了这个 CLIP 之后,确实效果很拔群。我们先来看一下这个第一个例子,看看它这个灵活性,这个就是说草地上有只狗,如果我现在要对它进行分割,假如说我的这个文本给的是 other 和dog,就是说狗或者其他的物体。他就把这个狗完美的这个分割出来了,然后剩下的其他都是黑色的这个背景也就是other。那如果这个时候你说我想检测点别的东西,我想把这个树也检测出来,那你就在这个文本这把这个数也加上,你就会发现树它也给你分割出来了,狗还是很好的分割出来了。
????????然后这个时候作者还想再展示一下这个模型的能力,一个就是它的这个容错能力。比如说如果我多给了一个这个汽车的标签,那这张图里是没有汽车的,那无论如何他都不应该给出来这个汽车的mask,那确实在下面这个图里却没有标出来汽车。
????????另外一个它想展现的就是这种强大的 Zero shot的能力。就是它能检测这个类别的这个子类或者父类。因为之前这里躺着一只狗,所以你知道它是个狗,那现在作者给了pet,也就是宠物,相当于是狗的一个超集(superset)。那这个时候模型还是能检测出来,因为在整张图片里也就只有这一块儿看起来像pet。所以说它还是把这块儿分割成了pet。
????????那我们再来看一个更难的例子,就是他这里的第三张图是一个室内的图片,那他上来先说检测一个椅子,那他就把这个椅子给检测出来了,然后别的全都是背景,然后这个时候作者又多加了一些,比如说把这个墙加上,就会发现这个墙非常完美的这个分割出来了,然后剩下的就还是这个背景。
????????然后这个时候作者想检测更多的东西,更细致的这种分类,作者就把这个窗户、地板、天花板全都加上,然后你就会发现天花板也标出来了。两个大窗户也标出来了,这个地板它也标出来了,所以说真的感觉很神奇,像指哪儿打哪儿一样。不过确实现在这种 language guided 的这个分割做的是挺好的,所以这就让这个图像 PS 达到了一个新的高度。就我直接可以说我想把这边这个人给 PS 掉,因为我现在能做非常完美的这种分割,所以我就可以把这个人从这里抠掉,然后再换上别的东西。
2.1.2 模型总览图
????????那看完了这个很好的结果,那我们现在就直接来看这个模型的总览图
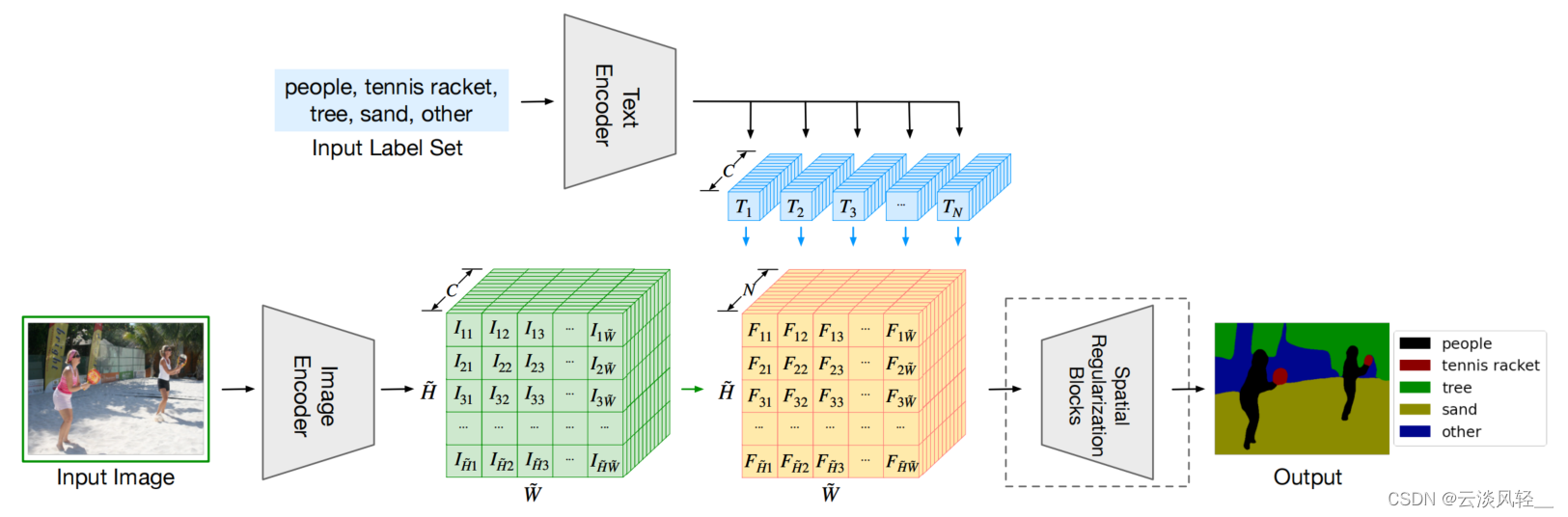
????????然后你一看这个图 2 你就会发现,诶它跟这个 CLIP 的这个模型总览图怎么这么像呢?都是这块有一个图片,这块有一些文字,然后图像通过图像编码器,文字通过文本编码器,然后得到了一些文本特征,然后图像这边只不过是从简单的这种图像特征变成了这种比较密集的 dence features,然后通过做点击,你也有类似的这么一个矩阵,然后最后得到一些结果。看起来非常的像。
????????那现在我们先假设没有上面的这个文本这一支,我们就看底下这个图像这一支,我们就会发现其实它跟这种正儿八经的有监督的语义分割其实没有任何的区别,它都是有一个图片,然后进了一个这个分割的模型,最后就能得到一个特征图,然后这个特征图通过一些 upscaling 就把它放大。因为我们现在做的是一个密集任务,它最后的这个输出应该跟原来图像的大小是一致的,所以这块就要做一些升维的操作,然后最后模型的输出去跟那个 ground truth 的 supervision 去做一个 cross entrpy?loss 就可以。那细致点来说,这个图像的编码器这边其实是一个 DPT 的结构,也是这篇论文的几个作者之前做的一篇语义分割的工作,是拿 vision Transformer 去做有监督的语义风格的。简单来说,这个 DPT 的结构就是前面有一个 vision Transformer,后面加了一个decoder。decoder 的作用就是把一个 bottleneck feature 慢慢的把它upscale上去。就像我们之前说的 PSP 或者 ASPP 这种层一样。然后我们就相当于把一个 H*w*3 的一个图像就变成了一个 H'*T*'C一个特征图。那 H'*T*'C其实就是跟原图相比,它可能降维了一些。比如说是原来的 1/ 4 或者 1/ 16 这样的大小。 c 是指这个特征的维度,一般就是 512 或者768,然后视觉特征其实就算抽完了。
????????那我们先来再来看文本的这一支文本就是假设你这个数据集你有 n 个label,也就这里说的people, tennis record 这些标签,你就把这些标签通过这个文本编码器,你就会得到 n 个这个文本特征,那这里对 n 其实是没有限制的,也就跟我们刚才的样例一样,你也可以只检测狗,你也可以检测狗和树或者更多的东西。这个 n 是可以随时都可以改变的。然而这个文本通过文本编码器之后,就会得到一个 n *c的一个矩阵, c 依旧是特征的维度,也就是 512 或者768。那到这儿其实我们就把文本的特征也算抽出来了
????????那现在如果我们来仔细看一下它的这个特征维度,我们就会发现文本这边你得到了一个 n *c矩阵,然后图像这边你得到一个H'*T*'C的一个tensor。然后你对这两个矩阵在这个 C这个 dimension 上进行一下相乘的话,你就会得到一个 h 乘 w 乘n的一个tenser。n就是你有多少个标签,也就是多少个类别。那其实做到这就跟传统的有监督的分割没有任何区别了。因为传统的有监督的分割也是会得到这么一个 h 乘 w 乘 n 的一个特征,然后拿这个特征去跟最后的 ground truth 去做 cross centrip loss。
????????那这篇论文它虽然说是用了CLIP,它虽然说是 Zero shot,但其实它的训练过程是有监督的训练。它是在 7 个分割数据集上一起训练出来的,也就是说它最后是有 ground truth mask 的,它的目标函数就是跟那些 ground truth mask 去做的cross entry loss。而不是像 CLIP 一样是对比学习的loss,它不是一个无监督训练的工作。那这篇论文的意义其实就是把文本的这一支加入到了这个传统的有监督分割的模型的这个 pipeline 里来,通过这块的这么一乘,它就把这个文本特征和这个图像特征给结合起来了,那它这个模型再去做训练的时候,就能学到一些 language aware 的这种视觉特征,从而在最后你在做推理的时候,你能用文本的这种 prompt 就任意的得到你最后想要的这种分割的效果。
2.1.3 Lseg和CLIP的关系
????????那最后来说一下这个工作跟 CLIP 的关系,虽然这篇文章的作者说它这里这个图像编码器可以用任意的这个网络结构,它这里的这个文本编码器也可以用任意的网络结构或者那些预训练的模型参数。但是在这篇论文里,为了达到最好的效果,它这里的文本编码器其实就是用了 CLIP 里的那个文本编码器,一点儿都没动,而且在训练的时候也都没有动,就是自始至终而这个文本编码器都是锁住的,并没有进行训练。 clip 是什么样,它这就是什么样。这个可能也是作者担心,因为在这个 7 个 segmentation 数据异常训练的时候,虽然你听起来好像有 7 个数据集,但其实分割这边的数据集都很小,即使是 7 个,它的规模也还是非常小的,可能也就是十几万 20 万张图片。那这个时候如果你在这么小的数据集上,你想去 fine tuning CLIP 的那个预训练参数,你很有可能就把那个参数给带跑偏了。所以说为了不让模型训练变得更加困难,为了不让原来的 CLIP 模型这么好的特征又被学坏了。所以说作者这里就没有动这个文本的编码器。
????????然后图像抽取特征这边其实就是 VIT 加了一个decoder,那 VIT 这边作者也试了,要么呢用 clip 提供的那个 VIT 预训练参数,要么呢就是用之前别的工作,比如说原始的 VIT 或者 DEIT 那些工作预训练的参数。结果作者最后发现用那些 VIT DEIT 训练的参数效果更好,用 CLIP 的反而不太行。当然作者也没有解释说为什么不行,我其实也想不出一个合理的解释,就全当是实验科学了。
2.1.4 Spatial regularization blocks可以忽略
????????然而这篇论文技术上作者其实还提出了另外一个东西,叫做 special regularly block。但不知道是为了增加一些 novelty 还是说增加一些内容。其实这个 block 也就是一些 conv 或者 depth wise com的层。
????????作者应该是觉得在你这个文本和视觉特征进行相乘之后,我应该还有一些可学习的模型参数在它后面,然后去多理解一下这个文本和视觉到底应该怎么去交互,从而达到最好的这个效果。所以作者就在这块又额外的加了一些这种block。但是作者也没有过多强调后面的消重实验也做得比较短,比如说他发现加两个这种 block 效果最好,但是加到四个 block 的时候突然这个性能就崩了,但是作者也没有说为什么会崩,也没有任何解释,所以我们其实完全可以忽略这个东西。这个其实对整篇文章的理解或者说最后的性能都没有多大的影响。
2.1.5 实验结果
????????因为是论文串讲,我们还有很多内容,所以说实验部分我们就只挑最有意思的那些实验结果,大概看一下就好了。这篇论文它选择的数据集和这个评价的标准至少对于我来说其实不是很常见。
????????他是 follow 了之前几个做 few-shot分割的这个工作,他是在 Pascal 五、 Coco 二十和 FSS 1000 上做的这个评价,它其实的意思就是说把原来的一个数据集分成了四份,比如说 Pascal 的话,它本来有 20 类,它现在把这 20 类分成四份儿,每一份儿就有五类。然后这样当前的 5 类其实就是我们知道的类,剩下的 15 类我们就当不知道的类,这样你就可以去做这种 Zero shot 或者 feel shot 这个实验。然后这里这个 i 其实就代表你选你这里选的第几份。
????????那同样的道理,这个 COCO 20 也就是把 80 类分成了 4 份,那如果是 COCO 20 也就是第一类,也就是说把前 20 类当成我们知道的类,把后 60 类当成我们不知道的类,然后你就可以在后 60 类上去做这种 Zero shot 或者few。shot 的实验了。
????????然后这个 FSS 1000 这个数据集也很有意思,它有 1000 类。我之前还不知道分割有数据集有这么多类别的
????????那我们简单看一下表格,那我们先看 Pascal 上的结果,其实这篇文章这个LSEG提出的方式,它是 Zero shot,它这个结果比之前的这种 Zero shot 方法还是提升不少的,大概提了十几二十个点。但是跟之前哪怕是 one shot 的这种方式比,它还是差得挺远的。而且如果你考虑到之前的方法还都用的是rise。101。而 l SEC 这篇论文已经是用 VIP large 模型了,你的模型其实比 rise 101 大了非常多倍,也就是说现在 Zero shot 分割跟这个有监督的分割距离还是非常远的。中间能提升的空间至少是几十个点。
????????那同样如果我们来看 Coco 二十的话,也是一样的道理,它的这个 Zero shot 比之前的 Zero shot 好一些,但是哪怕是跟之前 one shot 的比,还不是跟用所有的数据比,它们之间的这个差距也还是非常明显。
2.1.6 failure case
????????那作者最后还展示了一些这个 failure case,这个还比较有意思。当然之前他还列举了很多成功的情况,那些就跟我们刚开始看的图差不多了,所以我们就不一一过了。这里如果我们来看这个例子

????????这图里还是草地和狗,但是我的文本给的是草地和玩具。那最后就把这个狗判断成了玩具,所以这里还是同样的问题,就是说这个模型还有跟clip,或者说一切用了 clip 模型的这些工作因为本质上它都是在算这个图像特征和文本特征之间的相似性,他并不是真的在做一个分类,所以说谁跟他最接近,他就选谁在这里这只小狗肯定不是草,而这种样子的小狗看起来其实跟玩具也差不多,所以就把这只狗分类分给了玩具。
????????而且其实更有意思就是这篇论文是有代码,而且是有预训练模型的。我之前也玩过。其实如果你把这里的词再换一换,会有很多有意思的情况,就比如说你如果把这里的 toy 换成 face 就是脸。那它其实就会把脸也分给狗。还有这篇论文里经常使用的这个 other 就是代表背景的这种other,你也可以把它换成别的词,你可以把它换成 a an 这种没有意义的词,或者那种 and but i me you 这种没有明确的物体语义的这个词。你就会发现它们都可以拿来替代这个other,当成是这个背景类的这个提示词。所以总之这个 Zero shot 去做分割,能提升的空间还非常的大,要走的路也非常的远。最近也陆陆续续又出来了一些工作,比如马上我们就要讲group VIT。这个方向其实算是个不错的坑,有兴趣的同学都可以来玩一玩。
2.2 groupViT:摆脱手工标注,用文本做监督信号做无监督的训练
????????那说完了 l SEC,那接下来我们来看一下更新的一篇 C V P R 2022 的论文,叫做groupV I T。那其实我们刚才也强调过了,那 LSEG那篇论文,它虽然用了 clip 的这个预训练参数,而且这个图画的也很像clip。但是终究它的目标函数也不是对比学习,它也不是无监督学习的框架,它其实并没有把文本当成一个监督信号来使用。这就会导致一个什么问题:就是它还是依赖于这个手工标注的这个segmentation mask。这个就比较难办,因为就像我们刚才说的一样,虽然他用了七个数据集去训练,但其实这所有的这七个数据集也没有很大。跟别的任务相比,不论是有监督还是无监督,一二十万的这个训练量都非常非常的小。对于分割来说,你去手工标注的那个 Mask 是非常非常贵的一件事情,所以说如何能摆脱掉这个手工标注,如何能真的去做到用文本来做这个监督信号,从而能达到无监督的训练,这个才是大家更想要的东西。
????????那 group i t 就算是这个方向上比较有贡献的一个工作了,你从题目里也可以看出来,它的监督信号就是来自于文本,它并不依赖于 segmentation mask 的这种手工标注,而是可以像 CLIP 那样就利用图像文本堆来进行这种无监督的训练,能让模型进行简单的这种分割的任务。
2.2.1?模型到底是怎么工作的?为什么要叫groupVIT?
????????那模型到底是怎么工作的?为什么要叫groupVIT?其实在视觉这边,很早之前做无监督分割的时候,经常就是用一类方法叫做Grouping。它就类似于说如果你有一些聚类的那个中心点,然后我从这个点开始发散,然后把附近周围相似的点逐渐扩充成一个group,那这个 group 其实就相当于是一个 segmentation mask 了,是一种自下而上的方式。那在这里作者其实相当于是重新审视了一下这个 Grouping 的方法,发现其实能把 Grouping 完美的用到当前的这个框架中来。

????????他们提出了一个计算单元,也就是右边儿的这个东西叫做 grouping block。然后还有一些可以学习的这个 group tokens,它主要的目的就是想让这个模型在初始学习的时候,就能慢慢地一点一点地。把这个相邻相近的像素点都慢慢地 group 起来,变成一个又一个的这个 segmentation mask 就跟它右边图里画出来一养。在模型刚开始的浅层的时候,他学到这些 group token,这个分割的效果还不是很好,我们这里还能看到一些五颜六色的颜色块,但是经过模型的学习,等到深层一点的这些 group token 的时候,我们就可以看到它的这个分割已经做得相当不错了,已经能够把这几个大象房子后面的树林和草地全都分割出来了。
????????所以 group VIT 的贡献就是在一个已有的 VIT 的框架之中加入了这个 Grouping block,同时加入了这个可学习的group tokens。
2.2.2 什么是 Grouping block,什么是 group token?
????????那接下来我们就来仔细的看一下什么是 Grouping block,什么是 group token?
????????那老样子我们还是用一个具体的例子来说明这个情况。首先对于图像编码器来说,它这边就是一个 vision Transformer,从头到尾一共有 12 层,也就是说有 12 个这个 transformer layers。
????????那图像编码器这边的输入其实有两个部分,一个就是来自于原始图像的这个 patching bedding,另外一个就是这篇文章提出来的这个可学习的group tokens。
- patch embedding,其实就是假如我们这儿有个 224 *224 的图片,然后我们的 patch size 选成 16 * 16,那其实我们就有一个 14 * 14,一个 196 序列长度的一个序列。然后经过这个 linear projection 就得到了一些这个Patch embedding。它的维度其实就是 196 乘384,因为这里用的是 VIT small,所以这个特征的维度是384,那另外一个输入 group tokens 作者这里刚开始设的是 64 * 384,384是为了保持维度不变,所以能够和这个 196 * 384 去做直接的拼接。那这个 64 是希望你刚开始的时候有尽可能多的这个聚类中心,因为反正你回头还可以合并。所以刚开始就设了一个不大不小的值64。
- 这个 group token 你其实就可以理解为是这个之前我们说的 cl s token,就是说他想用这个 token 就代表整个这个图片,但是我们这里是用了 64 个 group token,而不是一个 group token。为什么呢?也很简单,因为过去你用一个的原因是因为你想代表整个图片有一个特征,但是你现在你是想做分割,所以你是想每一个类别或者说每一个小块它都有一个特征去表示它。所以说在这篇论文里它刚开始设的就是 64 个,也就是说你有 64 个起始点,或者说你有 64 个聚类中心。把那些看起来相似的或者语义接近的像素点都归结到这 64 个 cluster 里面。至于学习的过程,其实 group token 和这个 cls token 学习都是一样的,就是通过这个 transformer layer 里这个自注意力去不停地学习到底这些图像的 patch 哪些属于这个token哪些属于这个token,然后经过了几层 consumer layer 的学习之后。比如说在这篇论文里经过了 6 层 Transformer layer 之后,然后就在这 6 层之后加了一个 grouping block,就是作者认为你现在已经互相教会了 6 个 Transformer layer 了,这个 group token 可能已经学的差不多了,这个 clustering center 也学的差不多好了,那这个时候。我得试着来 cluster 你一下把你合并成为更大的group,学到一些更有语义的这个信息。所以它就利用这个 grouping block,把之前的这些图像 patch embedding 直接 assign 到这 64 个 group token 上,相当于做了一次这个聚类的分配,那你一旦分配完,那你有 64 个聚类中心,那你就当然只剩下64个 token 了。所以做完这一步操作之后得到的这个 segment token,也就是这些颜色相间的token,它的这个维度就是 64 * 384 了。当然这里 grouping block 还有另外一个好处就是它相当于变相的把这个序列长度给降低了,那这个模型的计算复杂度,还有这个训练时间也就相应的都减少,它就跟 swin Transformer 一样,是一个层级式的网络结构。
????????那我们现在具体来看一下 Grouping block 是怎么操作。其实 grouping block 就是用类似于自助意义的方式,先算了一个相似度矩阵,然后用这个相似度矩阵去帮助原来的这个 image token 做一些这个聚类中心的分配,从而完成了把这个输入从 196 * 384 降维到这个 64 * 384 的这个过程。当然大家都知道你做这种聚类中心的分配这个过程,它其实是不可导的。所以作者这里用了一个trick,也就是用个gumbles of the Max。从而把这个过程变成可导的,这样整个模型就可以端到端的进行训练了。那到这儿其实我们就完成了第一阶段的这个grouping,就把这个输入序列从 196 加 64 的这个长度变成了一个 64 * 384 的序列。

????????然后因为一般的数据集或者说常见的这个图片里,它的种类也不会太多,所以作者希望能把这 64 个聚类中心变得再小一点,把一些相似的小的这个类别块,尽量的把它再合并成大的这种块,所以它就又加了新的 8 个这个 group tokens,也就是8 *。384。希望能通过进一步 translora 这个学习,能把这 64 个 segment token 再次映射到这 8 个聚类中心上。那在文章中,作者其实是在第九层 consumer layer 之后又加了一次grouping block。也就是说在这个 grouping blog 之后,又过了 3 层transmer layer 的学习,作者觉得新加的这八个 segment token 其实就学得差不多了,于是乎再做一次这个 grouping block,就把这个 64 + 8 的这个序列分配到这 8 * 384 的这个token 上了。也就是说这个图像分成了八大块儿,然后每个块儿对应的有一个特征。
2.2.3 模型怎么训练?
????????那说到这儿,其实已经把这个 grouping block 和 group token 都已经说完了,那整个这个模型该怎么去训练?其实这也就是 group VIT 和 clip 的这个相似之处了,它们都是通过这个图像文本堆儿去算了一个对比学习的loss,从而训练整个网络的。但是这里问题就来了,你原来做 clip 的时候,你是一个图片有一个特征,然后那个文本有一个特征,所以你图像文本的特征很容易算一个对比学习的loss。但是现在你的文本端还是通过文本编码器得到了一个这个文本特征ZT。但是你的图像因为做这种 group token 和 group MERGING 的操作,它到目前为止得到的是一个序列长度为 8 的这个特征序列,那怎么能把这 8 大块的特征融合成一块,变成整个图像的这个 image level 的特征?那作者这里就选择了最简单的一种方式,就是我直接做一下这个 average pulling,直接把这些特征平均一下不就完了?那它就得到了一个384的特征。那这个特征通过一层 MLP 就得到了整个图像对应的这个特征ZL。那这样接下来就跟 clip 完全一样。
????????总体而言, group VIP 还是一个非常简单的方法,它没有在这个 vision Transformer 的基础上加什么特别复杂的模块,它的目标函数也跟 CLIP 保持一致,所以就意味着它的这个 skill 的性能非常的好。如果你把它这个模型变大,或者说如果你给它更多的数据,它有可能就能给你更好的学习结果。当然,在这篇论文里,作者就选择了 vision consumer small,而且数据集最大也直到 29 million,也就是 2900 万个图像文本对儿,如果像 CLIP 那样用 4 个亿的图像文本盾儿训练,不知道最后的这个分割效果。会不会更好?
2.2.4 怎么做zeroshot推理?
????????那说完了模型是怎么训练的?那接下来就说一下这个模型是怎么去做 Zero shot 的推理的,其实跟 CLIP 还是非常的像,比如说给定一个图片。

????????图片首先经过 group i t 的这个结构,也就是左边的那个图像编码器,它就会得到最后的这八个这个 group embedding。然后这个时候我们再把有可能这些标签,通过这个文本编码器得到一系列的这个文本特征![]() 。那接下来我们只要算这些图像的 grouping embedding
。那接下来我们只要算这些图像的 grouping embedding 和这些文本的特征之间的相似度,就可以知道每个这个 grouping embedding 到底对应什么样的class。
和这些文本的特征之间的相似度,就可以知道每个这个 grouping embedding 到底对应什么样的class。
????????当然这里我们能看到一个很明显的一个局限性,也就是说因为这个模型最后只有 8 个这个 group embedding,也就意味着其实这个图片的分割最多只能检测到 8 类,再多就不可能了。因为这边这个维度只有 Z1 到 Z 8 只有 8 个group token。了,这个使用多少个这个 group token,或者最后用多少个 output token,这些都是可以调的超参数。作者这里也试了一下各种各样的这个 group token 和 output token,比如这里一路从 16 试到64,这边从 4 试到16,但是作者发现就用最后这 8 个 output token,最后结果是最好的。所以就选择了这个设定。
2.2.5 有意思的可视化
????????那接下来我们看一个比较有意思的。可视化。因为说白了你加了这些 group token,你加了这个 grouping stage,它到底工作没工作?它到底是怎么工作的?其实你不知道,那作者这里就把第一个 stage 还有第二个 stage 里的一些这个 group token 拿出来可视化了一下,看看这些 token 到底有没有成为一个聚类中心,那是不是某一个token,它就对应的具体的某一个类别?我们发现,诶还确实如此。比如说在前面的这个 stage 一的时候,一般他关注的就是比较小的区域,因为那个时候还有 64 个token。作者这里就发现说假如说第五个group,其实它对应的就是眼睛,不光是人的眼睛,还有狗的眼睛,各种各样的眼睛其实都能被它分割出来。那如果我们换一个token,换到这个第 36 个group token。我们就会发现其实他说的是这个四肢,而如果我们换到第二个阶段,我们就可以看到它对应的这个区域明显就扩大了很多,因为这个时候已经是 8 大类了。比如这个时候我们看这个第六个 group token,就会发现它对应的全都是这个草地,那或者说这个第七个 token 对应的就全都是人脸。所以确实如你所愿,这个 group VIP 里的这个 group token 起到了这个聚类中心的作用,真的用 grouping 的这种思想完成了这种无监督的分割。
2.2.6 数值上的比较
????????那最后我们来看一下这个数值这样的比较,在 Pascal VOC 和 Pascal context 这两个数据集上,这个 group it 分别取得了 52. 3 和 22. 4 的这个结果。跟他这里说的这些 baseline 方法比起来,确实有很大的提升。而且也确实是用这个文本做监督信号的第一个工作,而且还可以做 Zero shot 的inference所以还是相当厉害的。但如果我们考虑一下它这个有监督的这个上限是多少,我们就会发现这里这个差距还是非常非常的大的。比如说在 Pascal VOC 上之前最好的方法,比如说 deep lab V3 plus,我记得好像已经是 8788 的这个 MLU 了,也就说比这里的 52. 3 高了30多个点。那 Pascal context 的数据集也一样,最好的有监督的方法应该也是五六十的准确度,所以也是差了 30 多个点,所以说无监督的这个分割还是很难的。能做的东西非常多
2.2.7 局限性
????????作者这里也列举出来了它的两个这个limitation,大概说了一下它未来可能才会做哪些改进。那其中的一个局限性就是说现在这个 group it 的结构其实还是更偏向于是一个图像的编码器,它没有很好的利用这种 dence prediction 的特性,比如说之前在分割这边用的很火的这种 dilated convolution 或者 pyramid pooling 或者 unit 的这种结构,从而你能获得更多的这个上下文信息,而且能获得更多的这个多尺度的信息能帮助你更好地去做分割任务。但目前 group it 这边都还没有考虑这些。所以每一个刚才说的东西都有可能未来成为一篇论文。
????????那另外一个局限性就是分割这边存在的一个东西叫做背景类,那 group VIT 在这个推理的过程中是怎么考虑这个背景类的?这个刚才我也忘了说,就是我们在做 Zero shot 的这个推理的时候,不光是选择最大的那个相似度,因为有的时候你这个最大的相似度可能也比较小,可能最后就只有 0. 20. 3 这样,那作者这里为了尽可能提高前景类的这个分割性能,所以它设置了一个阈值,就是这个相似度的阈值。比如说对于 Pascal VOC 这个数据集来说,它的阈值就设置了 0. 9 还是 0. 95。也就是说这个 grouping embedding 和这个文本的特征,它的这个相似度必须超过 0 点儿九,而且是取的最大的那一个,你才能说这个 group embedding 属于这一类。如果你这个 group embedding 跟所有的这个文本的特征的相似度都没有超过零点儿9,那 group i t 就认为你就是个背景类,你就不是一个前景。那这套推理方案对于 Pascal VOC 来说还好,因为本来它的这个类别数就少,而且一般都是实打实的这个物体有非常明确的语义信息,所以它不太存在这个背景类干扰的问题当然也有了,但是如果当你把这套框架移到 Pascal context 或者做 Coco 数据集的时候,这个问题就非常显著。因为这个时候你的类别非常的多,那你的这个置信度,或者说你这个相似度一般就会比较低,就很容易出现你的这个前景物体的置信度和你这个背景物体差不了多少,那这个时候怎么设置这个阈值就成为了一个很关键的问题。如果我们把这个阈值设得很高,那基本大多数全都变成背景物体了,那这这样前景类别的这个 MLU 分数肯定就会变得很低。那如果我们把这个阈值设得很低,就会造成一个错误分类的问题,就是有可能它相似度最高的那一类并不是真正正确的那一类。也就是论文作者自己这里发现的一个问题,就是他们通过这个肉眼的观察。他们发现其实 group VIP 这个 group token 学的挺好的,就是真正的那个分割已经做得很好了,还真的把那个人呐或者那个马呀,那个桌子都分割出来了。但是只不过最后的这个分类给分错了。那作者这里为了验证一下到底是不是因为分类的错误导致这个 Coco 和这个 context 数据集这个性能这么低。它就做出了一个上线的实验。如果 group VIT 给了它一个输出的这个 prediction mask,它就拿这个 mask 去跟所有的这个 ground truth mask 去做这个对比。一旦他发现哪个 IOU 最大,他就把那个 ground truth 的那个 label 直接就给这个 group VIT prediction mask 当成它的标签。那这样一来,只要你这个分割做得好,那你这个分类就肯定不会错,因为你相当于是直接从 ground truth 那边拿过来的这个标签。作者就发现不论是对 VOC 来说,还是后面这两个更难的数据集来说,它的这个上线的 MLU 一下就增加了二三十个点,现在就跟这个有监督的那边最高的这个性能就差不多了。这也就验证了,其实 group it 的这个结构,尤其是 group token 和 grouping block 其实非常的有效,因为它已经把这个 segmentation mask 生成的很好,它分割做得很好,它只是没有把语义分割做得很好。因为它分类错了很多。那这个怪谁?这个其实是怪这个 clip 的这种训练方式,因为 clip 的这种训练方式只能学到那种物体语义信息非常明确的东西,它学不到这种很模糊的。比如说什么是背景,因为背景可以代表很多很多类,它是一个很模糊的概念。所以说 CLIP 这种训练方式就没有办法学到这些背景类,那对于这个 limitation 其实也有很多的解决方案,比如说那个阈值该怎么设?是不是应该根据每一个类别去设?是不是应该可以有一个可学习的阈值,或者说整个把这个 Zero shot 的这个推理过程给改了,或者说你在训练的时候再加上一种约束,能把背景类这个概念融入到你的训练之中,所以这里也有很多可以挖掘的东西。
????????总之分割这边就讲 l SEG 和 group i t 这两篇工作,第一篇就是直接使用了 CLIP 的这个预训练模型,而且也使用了它的这个大概框架,从而把这个图像和文本的特征融合在了一起,能够去做这种 language driven 的语义分割,但是它还是一个有监督的学习。
????????那第二个工作 group it 它并没有使用 CLIP 的这个预训练参数,它反而是自己从头训练了一个分割模型。但是它的目标函数就用的是 CLIP 的目标函数,一点儿都没有变。
????????那接下来我们还会讲这个目标检测,还会讲这个视频,还会讲一些其他的领域。我们就都可以发现这个 CLAP 出来以后,大家一般刚开始就是先用下它这个预训练的参数,大家做一些简单的改动,然后再把 clip 的特性和这个下游任务的特性结合起来。要么呢是利用 clip 的这个目标函数,要么呢是利用 clip 的一些其他特性去把这个下游任务做得更好。
????????那说完了 clip 在分割里的应用,接下来我们就来看一下 clip 在目标检测这边是怎么使用目标检测的。这个网络结构一般是要比这个分类或者分割要复杂一些的,但是好像也丝毫没有影响这篇论文出来的。这个。速度。虽然这篇论文是 iclear 二的一篇中稿论文,但事实上它在 21 年的4月 28 号就已经上传到 ARCHIVE 上。我们之前在讲 clip 的时候也提到过 clip 这篇论文是在 21 年2月 26 号传到r。cap。上,意思就是说这篇论文从看到 clip 到写出来这个 21 页的 i clear 的论文,中间只花了两个月的。时间。而且后面我们也可以看到它训练模型用了 18 万个iteration,大概换算过来就是 460 个epoch。这是一个非常长的训练时间,有几十个上百个TPU,应该是没办法在这么短的时间内完成这么高质量的工作。那我们言归正传,这篇论文叫做viewed,就是 vision language knowledge distillation,然后你一看题目open。vocabulary。你就知道这多多少少跟 clip 肯定。有点关系。然后你再读到后面 vision language knowledge distillation,你就大概知道了他肯定是把 clip 模型当成了一个teacher,然后去蒸馏。他自己的那个网络。从而达到能 zero shot 去做目标检测这个目的。接下来我们直接跳到引言,这篇论文的引言写得非常好,我也想给大家安利一下这种写作的方法,它一上来就给了一张图,然后根据这张图,作者就问了一个问题,直接就把这篇文章到底要做什么给引出来了。真的就是一句话,把这篇文章的研究动机说得。明明白白。的。紧接着就直接说,在这篇论文里,我们就是想做一个 open vocabulary 的目标检测,从而能够检测到任意的这个新的物体类别。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!