Redis 主从、哨兵和分片集群简单介绍
Redis 主从集群架构
单节点 redis 并发能力有上限,要进一步提高 redis 并发能力,就要搭建主从集群,实现读写分离

主从同步原理?
Replicaition id:每台 master 机器都一个 repl_id,是数据集的表示,若 salve 的 repl_id 与 master 的一样,则表示它们属于同一个集群
offset:偏移量,表示 master 在 repl_backlong 的位置。而同步时 salve 也会保存一个 offset,若 master 的 offset 大于 salve 的 offset,则表示 salve 的数据落后于 master,需要进行更新
主从同步方式
全量同步
Redis 主从、哨兵和分片集群
2023-04-27 09:16·爱做梦的程序员

Redis 主从集群架构
单节点 redis 并发能力有上限,要进一步提高 redis 并发能力,就要搭建主从集群,实现读写分离
主从同步原理
Replicaition id:每台 master 机器都一个 repl_id,是数据集的表示,若 salve 的 repl_id 与 master 的一样,则表示它们属于同一个集群
offset:偏移量,表示 master 在 repl_backlong 的位置。而同步时 salve 也会保存一个 offset,若 master 的 offset 大于 salve 的 offset,则表示 salve 的数据落后于 master,需要进行更新
主从同步方式
全量同步
执行时机
- salve 第一次连接 master 时;
- slave 断开时间太久,repl_backlog 中的 offset 已经被覆盖
执行过程
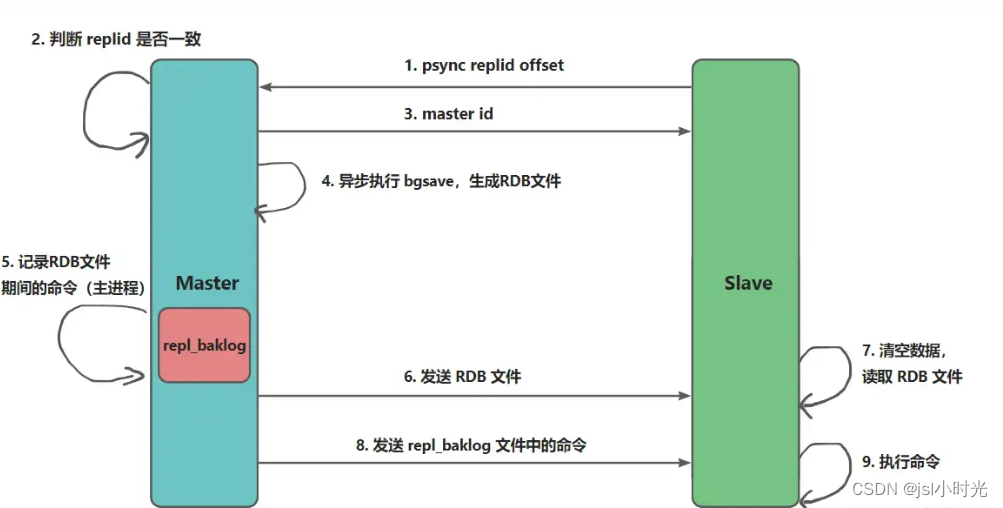
- salve?向 master 发送?offset、repl_id,master?判断该 repl_id 为空或与自己的不同,则进行全量同步
- master?调用?bgsave?命令异步生成 RDB 文件,同时把生成 RDB 文件过程中接收到命令写入?repl_baklog?缓冲区 中,
- master?生成完 RDB 文件后,把 RDB 文件和?repl_baklog?缓冲区中的命令一并发送给 salve;
- slave?根据命令和 RDB 文件进行数据同步即可;
?
?
增量同步
执行时机
- salve 断开又恢复,并且能在 repl_backlog 中找到 offset
执行过程
- salve?向 master 发送?offset、repl_id,master?判断该 repl_id 与自己的相同,则进行增量同步
- master 根据 salve 发送过来的 offset,读取 repl_backlog 位于 offset 后的命令,发送给 salve;
- salve 根据接收的命令进行同步即可;
 ?区别:
?区别:
全量同步:?master 执行 bgsave 命令,生成 RDB 文件发送给 slave,并将后续的命令存储在?repl_backlog?中,持续发送给 slave
增量同步:?master 获取 slave 发送的 offset,将?repl_backlog?中 offset 之后的数据发送给 slave 进行同步
?优化:
- 使用无磁盘复制,将数据流直接读入网络 IO?中;
- 适当控制 Redis 内存的使用量,避免生成的 RDB 文件过大;
- 当 slave 宕机时,要尽快进行恢复,避免进行全量复制;
- 可以使用?主-从-从?的链式模式,减少 master 的压力;
Redis 哨兵?
哨兵作用
服务状态监控:sentinel 不断监控 Redis 集群中 master 和 salve 的状态;
自动故障转移:当 master 宕机后,sentinel 会在所有的 slave 中选举出一个 master,当宕机后的机器恢复后,也以新选择的 master 为主
通知:sentinel 充当 Redis 的客户端服务发现来源,当集群发送故障时,会把最新的消息发送到客户端

服务状态监控?
sentinel 基于心跳的机制来判断 master 或者 slave 是否正常工作,每隔1秒向集群中的每个实例发送 ping 命令
- 若该实例没有在规定的时间范围内得到 pong 响应,则认为该机器?主观下线
- 若超过指定数量(quorum)台 sentinel 没有在规定的时间范围内得到该实例 pong 响应,则认为该机器?客观下线,quorum 的值最好超过 sentinel 机器数的一半
自动故障转移?
选举原则
- 判断 salve 和 master 断开时间的长短,若超过 10 *?down-after-milliseconds?,则该 slave 不会被选举为 master
- 判断?salve-priority?的大小,最小则优先级越高,但该值为 0 却不会被选到;
- 判断?offset?的大小,offset 值越大表示数据越新;
- 判断 salve 的 id 大小,id 越小,节点的优先级越高;
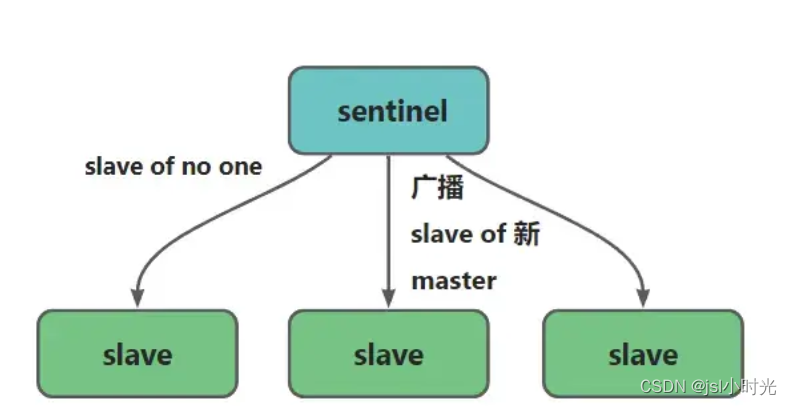
选举过程
- 向某个选举为 master 的 salve 机器发送?salve of one
- 向所有的机器发送?salve of 新 master
- 最后更改宕机的 master 配置,添加?slave of 新master
 ?
?
?Redis 分片集群
主从和哨兵解决了高并发和高可用的问题,但是有两个问题没有解决:
- 海量数据存储;
- 高并发写入;
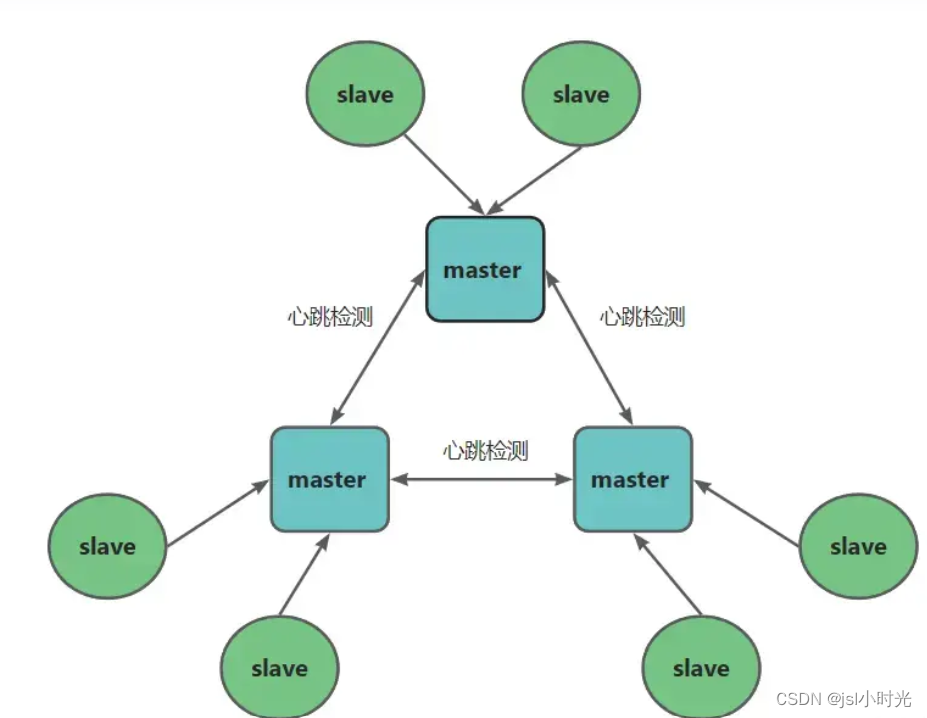
分片集群的特征
- 拥有多个 master,每个 master 可以存储不同的信息;
- 每个 master 拥有多个 salve;
- master 之间通过心跳来监控健康状态;
- 客户端可以访问任意节点,但最后都会被路由到正确的节点;
散列插槽
Redis 分片集群把每个 master 映射到不同的散列插槽中
会根据 key 的有效部分来计算插槽的位置,所以 key 不是跟节点绑定,而是跟插槽绑定
- 将 16384 个插槽分配到不同的实例上;
- 根据 key 的有效部分取 hash 值,对 16384 取余即可;
- 余数作为插槽,寻找查找对应的实例即可;
- 若有效部分的余数相同,则可以实现把同类的信息放到同一个 master 节点上;
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!