1/7文章
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
本周主要阅读了2023CVPR的文章,具有运动模糊的大规模场景的混合神经绘制,文章提出了一种混合神经渲染模型,用于合成高质量、视角一致的新视角图像。通过结合基于图像的表示和神经3D表示,以及模拟模糊效果,该模型能够有效地处理大型场景中的复杂结构和细节,并减轻运动模糊等缺陷对渲染图像质量的影响。另外我还对VAE的相关知识进行了复习。
Abstract
This week, I mainly read the article 2023CVPR on hybrid neural rendering of large-scale scenes with motion blur. The article proposes a hybrid neural rendering model for synthesizing high-quality, consistent new perspective images. By combining image-based representation and neural 3D representation, as well as simulating blur effects, this model can effectively handle complex structures and details in large scenes, and reduce the impact of motion blur and other defects on rendered image quality. In addition, I also reviewed the relevant knowledge of VAE.
文献阅读:具有运动模糊的大规模场景的混合神经绘制
Title: Hybrid Neural Rendering for Large-Scale Scenes with Motion Blur
Author:Peng Dai,Yinda Zhang,Xin Yu, Xiaoyang Lyu, Xiaojuan Qi
From:2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
1、研究背景
在许多应用中,如虚拟现实、增强现实和场景重建等,都需要从已有的图像中生成新的视图。尽管近年来在这方面取得了一些进展,但仍然存在一些挑战。这些挑战主要来自于如何在大规模场景中,从原始图像中生成高质量且与目标视图一致的新视图。原始图像在采集过程中可能会产生一些不可避免的缺陷,如运动模糊等,这些缺陷会严重影响渲染出的新视图的质量。
2、方法提出
文章提出了一种混合神经渲染模型,该模型结合了基于图像的表示和神经3D表示,以生成高质量且与目标视图一致的新视图。此外,文章还提出了一些策略来模拟渲染图像中的模糊效果,以减轻模糊对渲染质量的影响。这些策略基于预计算的质量感知权重,在训练过程中对模糊图像的重要性进行降低。
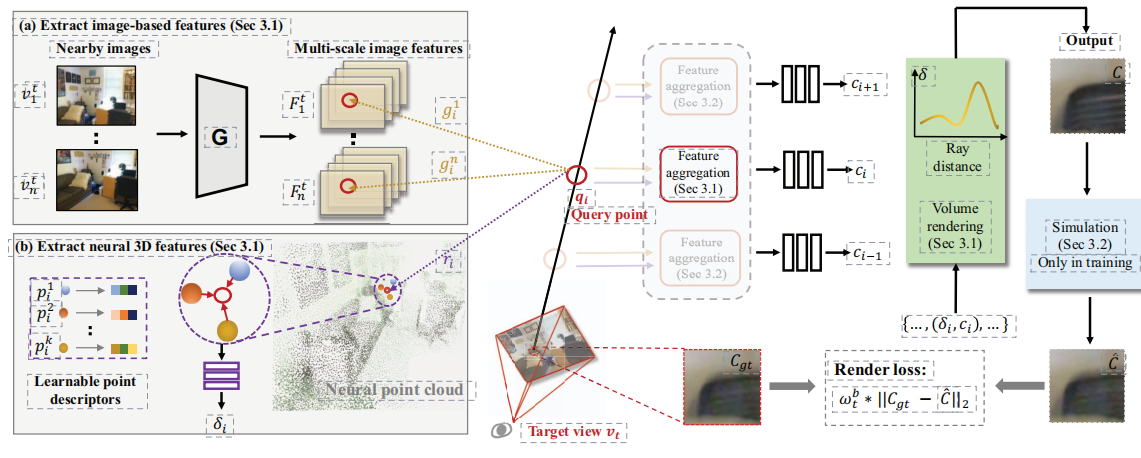
3、相关方法
3.1、混合神经渲染模型(Hybrid Neural Rendering Model)
一种混合神经渲染模型,结合了基于图像的表示和神经3D表示的优点,以生成高质量且与目标视图一致的新视图。这种模型包含两个主要部分:神经特征提取模块和神经特征融合模块。
1、神经特征提取模块从两种表示形式中提取信息。对于基于图像的表示,我们使用轻量级的CNN从附近的视图中提取多尺度图像特征。对于神经3D表示,我们使用光线与表面交点的信息来提取特征。
2、神经特征融合模块以数据驱动的方式聚合提取的神经特征。我们设计了一个可学习的聚合方法,该方法根据每个查询点的图像基础特征和神经3D特征生成混合特征。这些混合特征考虑了颜色、纹理和几何信息,从而提供了更丰富的视觉信息。
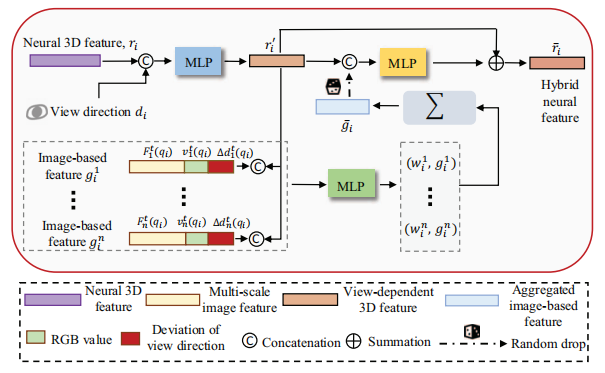
一旦获得了混合特征,使用体积渲染技术来生成最终的输出图像。体积渲染是一种可视化技术,用于从三维数据场中生成图像。它通过将三维数据场表示为一系列体素,并将每个体素的值映射到颜色和透明度来工作。然后使用光线追踪或其他类似技术将体素转换为图像。
3.2、模糊模拟与检测(Blur Simulation and Detection)
在渲染图像上模拟模糊效果并检测模糊是一个挑战。传统的模糊模拟方法通常需要额外的模糊源信息,这在实际应用中是不可行的。为了解决这个问题,我们提出了一种简单而有效的模糊模拟方法。首先,我们利用高斯分布来模拟运动模糊,并将其作为混合神经渲染模型的输入。这种模糊模拟方法仅需要输入图像和运动信息,而不需要额外的模糊源信息。
在模糊检测方面,我们采用了一种基于特征的方法来检测图像中的模糊区域。首先,我们提取输入图像的特征,并使用这些特征来训练一个分类器。然后,我们使用该分类器来预测图像中每个像素的模糊程度。通过这种方式,我们可以快速地检测出图像中的模糊区域,并为混合神经渲染模型提供有用的信息。
通过模糊模拟和检测,我们的混合神经渲染模型能够更好地理解源图像中的模糊信息,从而在渲染过程中更好地模拟模糊效果。这种模糊模拟和检测方法对于生成高质量和视图一致的渲染图像至关重要。
4、文章贡献
本文提出了一种混合神经渲染模型,用于合成高质量、视角一致的新视角图像。通过结合基于图像的表示和神经3D表示,以及模拟模糊效果,该模型能够有效地处理大型场景中的复杂结构和细节,并减轻运动模糊等缺陷对渲染图像质量的影响。实验结果表明,该模型在合成高质量新视角图像方面优于现有方法,为增强现实/虚拟现实、机器人技术和视频游戏等领域提供了重要的技术支持。通过使用该模型,可以合成高质量、视角一致的新视角图像,从而为这些领域的应用提供更加真实和生动的视觉效果。此外,该模型还可以用于电影制作和游戏开发等领域,以生成高质量的场景和角色渲染。
VAE理论回顾
1、VAE与Auto-encoder
VAE在本质上看与Auto-encoder的大致结构是相同的,都是拥有着一个Encoder以及一个Decoder,将输入经过两个单元处理后得到一个相应的输出。但是VAE的工作过程在其中有些许差异,VAE是在输入的数据中加入noise,然后再让加入noise的数据进行处理输出。
详细的步骤为,输入的数据经过Encoder处理得到两个向量mi和
σ
\sigma
σi,除此之外还从normal distribution中的产出一个向量ei,紧接着将这些向量进行这样的处理得到ci,ci = exp (
σ
\sigma
σi) x ei + mi,其中exp (
σ
\sigma
σi) x ei便是加入的noise此外为了让输入和输出越接近,给出了一下限制条件,使式子
∑
n
i
=
0
\underset{i=0}{\overset{n}{\sum}}
i=0∑n?? exp (
σ
\sigma
σi) - ( 1 +
σ
\sigma
σi ) + ( mi )2 达到最小。
2、VAE对于Auto-encoder的提升
- Auto-encoder的不足之处:生成的数据是一一对应,而无法做到两组相近的数据达到一个渐变效果。就比如一张满月的照片,以及弦月的照片,在Auto-encoder中无法在两者数据之间有效地得出一张介于满月以及弦月的照片,因为这些数据都是一一对应的,很难预测两组数据之间的数据的表现形式。
- VAE相比之下的提升:VAE在转化的过程中,会在数据中加入noise,从而让某个范围内的数据的输出都表现为该数据,这样当两组加入noise后范围增大的数据会形成一个交集,这样就能获得一个渐变的数据,实现Auto-encoder无法做到的情况。但是需要注意的是因为加入的noise是机器自己学习的,机器可能会存在偷懒的情况,让参数 σ \sigma σi变为0,从而无法加入noise,因此需要限制条件,使式子 ∑ n i = 0 \underset{i=0}{\overset{n}{\sum}} i=0∑n?? exp ( σ \sigma σi) - ( 1 + σ \sigma σi ) + ( mi )2 达到最小。
3、VAE过程的再理解
从上面小点可以知道,VAE整个的工作流程是将输入数据加入noise后,再通过Decoder将数据解码出来。换一个思路对这个过程的理解,就是不同的Distribution之间的转换,由开始输入数据的Distribution
经过添加noise得出一个新的Distribution,最后在经过转化得出一个与原来大致一样的Distribution。接下来的问题就应该是如何对这个Distribution用函数进行描述。
4、Gaussian Mixture Model
目标Distribution的函数P(x)可以理解为一个由多个Gaussian合成的集合体,由多个Gaussian进行sample后,由这些sample进行融合得出目标P(x),从这个角度上看,x是属于一个Cluster,在这些cluster中sample出对应的x构成P(x)。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!