java springboot+jsoup写一段爬虫脚本 将指定地址的 图片链接 文本 超链接地址存入自己的属性类对象中
2023-12-14 12:38:48
首先 还是最基本的 要在 pom.xml 引入依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.1</version>
</dependency>
然后 我们可以在项目中创建一个属性类 我这里就叫 WebContent了
参考代码如下
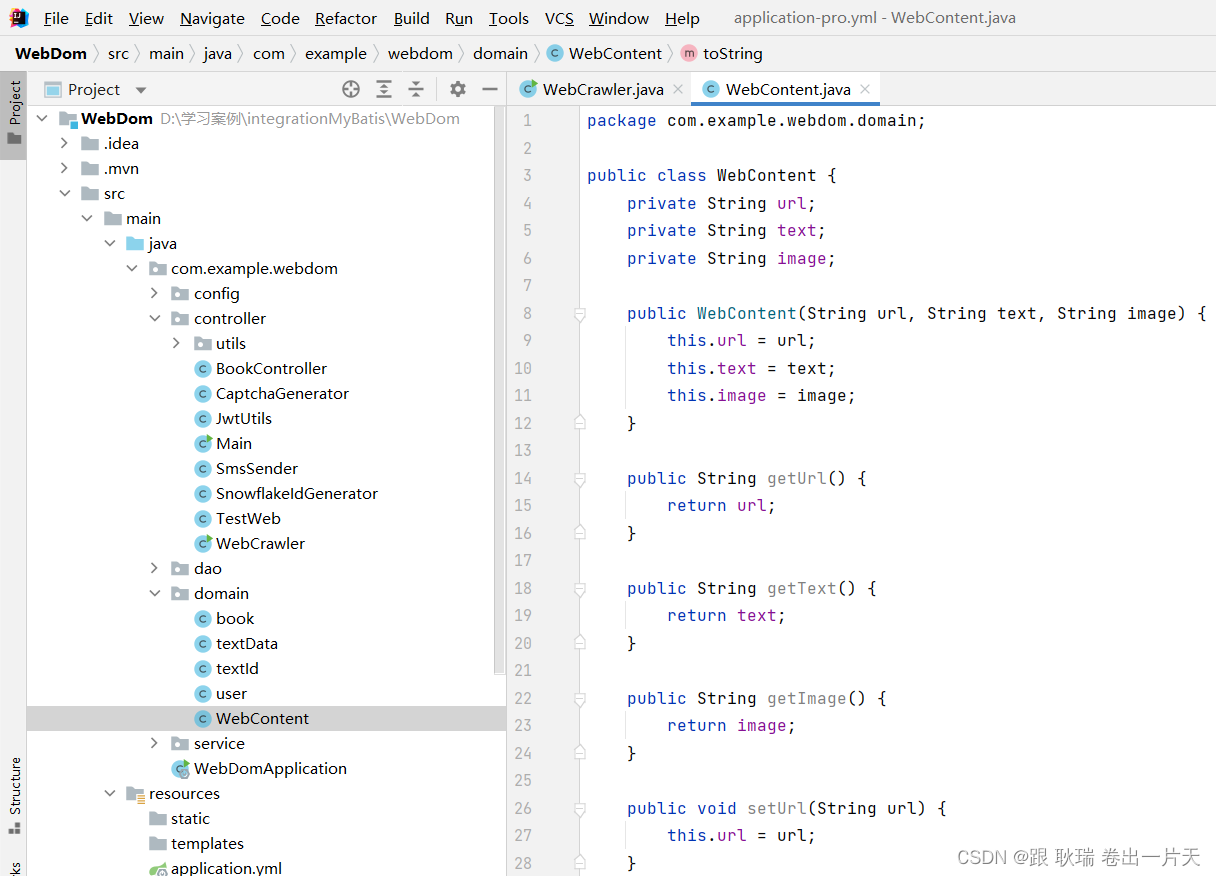
package com.example.webdom.domain;
public class WebContent {
private String url;
private String text;
private String image;
public WebContent(String url, String text, String image) {
this.url = url;
this.text = text;
this.image = image;
}
public String getUrl() {
return url;
}
public String getText() {
return text;
}
public String getImage() {
return image;
}
public void setUrl(String url) {
this.url = url;
}
public void setText(String text) {
this.text = text;
}
public void setImage(String image) {
this.image = image;
}
@Override
public String toString() {
return "WebContent{" +
"a标签链接='" + url + '\'' +
", 文本内容='" + text + '\'' +
", 图片路径='" + image + '\'' +
'}';
}
}
这里 我们定义了三个变量 url 用来存 a标签的链接地址 text用来存a标签的文本信息 又或者图片的 alt内容 image用来存图片的url
定义了他们的get set方法 这里为了方便大家看 写了 toString函数
然后 我们在逻辑类 编写代码如下
package com.example.webdom.controller;
import com.example.webdom.domain.WebContent;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class WebCrawler {
public static void main(String[] args) {
String url = "https://www.baidu.com/?tn=48021271_25_hao_pg"; // 要爬取的网页URL
try {
Document doc = Jsoup.connect(url).get(); // 通过Jsoup连接并获取网页内容
List<WebContent> webContents = new ArrayList<>(); // 创建属性类对象列表
Elements links = doc.select("a[href]"); // 选择所有带有href属性的<a>元素
for (Element link : links) {
String linkText = link.text(); // 获取链接文本
String linkHref = link.attr("href"); // 获取链接URL
WebContent webContent = new WebContent(linkHref, linkText, null); // 创建属性类对象
webContents.add(webContent); // 添加到对象列表
}
Elements images = doc.select("img[src]"); // 选择所有带有src属性的<img>元素
for (Element image : images) {
String imageUrl = image.attr("src"); // 获取图片URL
String imageAlt = image.attr("alt"); // 获取图片alt属性
WebContent webContent = new WebContent(null, imageAlt, imageUrl); // 创建属性类对象
webContents.add(webContent); // 添加到对象列表
}
for (WebContent webContent : webContents) {
System.out.println("----------------");
System.out.println(webContent);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
这里 我们用的百度首页的链接做测试 因为百度肯定技术是很好的 不怕我们访问
然后 我们拿取a标签 通过text函数 拿到文本 通过attr获取href 属性 拿到链接地址
然后 拿到所有的 img图 或许 src 与 alt属性
最后 输出list集合
运行代码如下
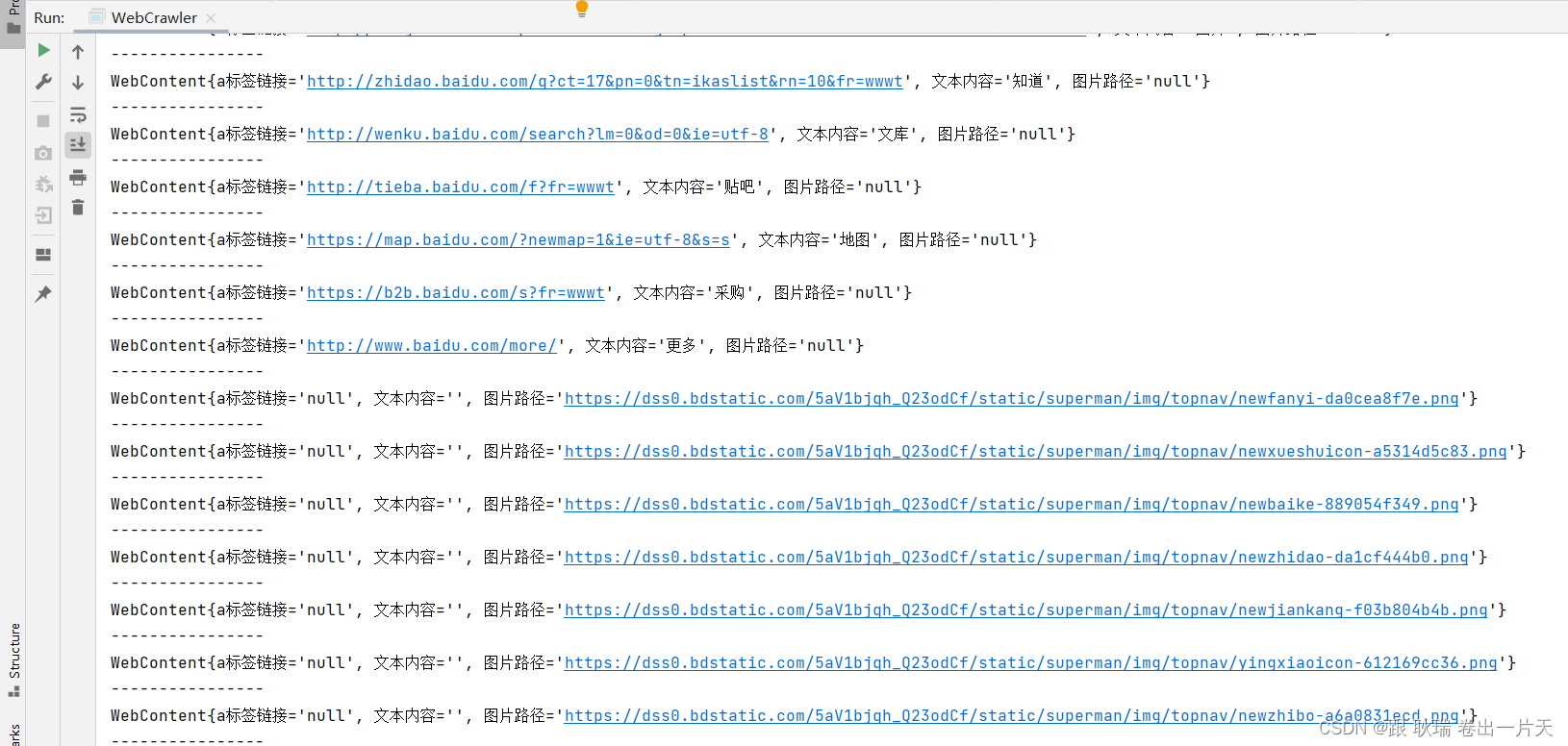
也是非常的完美
文章来源:https://blog.csdn.net/weixin_45966674/article/details/134991984
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!