实时AI绘画模型SDXL Turbo核心基础知识详解 | 【算法兵器谱】

Rocky Ding
公众号:WeThinkIn
写在前面
【算法兵器谱】栏目专注分享AI行业中的前沿/经典/必备的模型&论文,并对具备划时代意义的模型&论文进行全方位系统的解析。也欢迎大家提出宝贵的优化建议,一起交流学习💪
大家好,我是Rocky。
如果说2022年,Stable Diffusion横空出世,成为AI行业从传统深度学习时代过渡至AIGC时代的标志模型,并为工业界和投资界注入了新的活力,让AI再次性感。
那么2023年1129日,StabilityAI官方发布的最新的快速文生图模型SDXL Turbo/SD Turbo,则让AI绘画领域进入了“实时生成”时代。

那么在本文中,Rocky就深入浅出的讲解SDXL Turbo/SD Turbo模型的核心知识,一起看看这个关键AI绘画模型的价值。
本文节选自Rocky知乎上的两篇文章:Stable Diffusion XL全方位的解析文章:https://zhuanlan.zhihu.com/p/643420260,以及Stable Diffusion全方位的解析文章:https://zhuanlan.zhihu.com/p/632809634。这两篇文章目前在持续完善中,也希望大家给这两篇文章多多点赞,让Rocky有更多的动力!(也欢迎大家关注Rocky的知乎号:Rocky Ding)
话不多说,在Rocky毫无保留的分享下,让我们开始学习吧!
So,enjoy(与本文的BGM一起食用更佳哦):
正文开始
----【目录先行】----
-
SDXL Turbo整体架构初识
-
SDXL Turbo核心原理详解
-
SDXL Turbo效果测试
-
SD Turbo模型介绍
SDXL Turbo整体架构初识
SDXL Turbo模型是在SDXL 1.0模型的基础上设计了全新的蒸馏训练方案(Adversarial Diffusion Distillation,ADD),经过蒸馏训练得到的。SDXL Turbo模型只需要1-4步就能够生成高质量图像,这接近实时的性能,无异让AI绘画领域的发展更具爆炸性,同时也为未来AI视频的爆发奠定坚实的基础。
SDXL Turbo模型本质上依旧是SDXL模型,其网络架构与SDXL一致,可以理解为一种经过蒸馏训练后的SDXL模型。
不过SDXL Turbo模型并不包含Refiner部分,只包含U-Net(Base)、VAE和CLIP Text Encoder三个模块。在FP16精度下SDXL Turbo模型大小6.94G(FP32:13.88G),其中U-Net(Base)大小5.14G,VAE模型大小167M以及两个CLIP Text Encoder一大一小分别是1.39G和246M。
SDXL Turbo核心原理详解
既然我们已经知道SDXL Turbo模型结构本质上是和SDXL一致,那么其接近实时的生图性能主要还是得益于最新的Adversarial Diffusion Distillation(ADD)蒸馏方案。
模型蒸馏技术在传统深度学习时代就应用广泛,只是传统深度学习的落地场景只局限于ToB,任务范围不大且目标定义明确,大家往往人工设计轻量型的目标检测、分割、分类小模型来满足实际应用需求,所以当时模型蒸馏技术显得有些尴尬。
但是到了AIGC时代,大模型逻辑走通,模型蒸馏技术重新繁荣,应用于各个大模型的性能实时化中,Rocky相信模型蒸馏技术未来在AIGC时代将是一个非常关键的AI技术工具。
那么,就让我们一起来解析ADD的蒸馏方案的核心知识吧。首先ADD蒸馏方案的整体架构如下图所示:

ADD蒸馏方案的主要流程是这样的:将预训练好的SDXL模型作为学生模型(预训练好的网络能显著提高对抗性损失(adversarial loss)的训练效果),它接收经过forward diffusion process后的噪声图片,并输出去噪后的图片,然后用这个去噪后的图片与原图输入判别器中计算adversarial loss以及与教师模型输出的去噪图片计算distillation loss。ADD蒸馏算法中主要通过优化这两个loss来对SDXL Turbo进行训练:
-
**adversarial loss:**借鉴了GAN的思想,设计了Hinge loss(支持向量机SVM中常用的损失函数)作为SDXL的adversarial loss,通过一个Discriminator来辨别学生模型(SDXL Turbo)生成的图像和真实的图像,以确保即使在一个或两个采样步数的低步数状态下也能确保高图像保真度,同时避免了其他蒸馏方法中常见的失真或模糊问题。
-
**distillation loss:**经典的蒸馏损失函数,让SDXL 1.0模型作为教师模型并冻结参数,让学生模型(SDXL Turbo)的输出和教师模型的输出尽量一致,具体计算方式使用的是跨周期的L2损失。
最后,ADD蒸馏训练中总的损失函数就是adversarial loss和distillation loss的加权和,如下图所示,其中权重 λ \lambda λ设置2.5:

SDXL Turbo效果测试
目前StabilityAI官网已经上线SDXL Turbo模型,大家可以免费体验:https://clipdrop.co/stable-diffusion-turbo
因为SDXL Turbo网络结构与SDXL一致,所以大家也可以直接在Stable Diffusion WebUI上使用SDXL Turbo模型,我们只需按照本文3.3章中的教程使用Stable Diffusion WebUI即可。
同时ComfyUI上也已经支持SDXL Turbo的使用:https://comfyanonymous.github.io/ComfyUI_examples/sdturbo/,然后我们按照本文3.1章的教程使用ComfyUI工作流即可运行SDXL Turbo。

当然的,diffusers库也已经支持SDXL Turbo的使用运行了,可以进行文生图和图生图的任务,相关代码和操作流程如下所示:
# 加载diffusers和torch依赖库
from diffusers import AutoPipelineForText2Image
import torch
# 构建SDXL Turbo模型的Pipeline,加载SDXL Turbo模型
pipe = AutoPipelineForText2Image.from_pretrained("/本地路径/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
# "本地路径/sdxl-turbo"表示我们需要加载的SDXL Turbo模型,
# 大家可以关注Rocky的公众号WeThinkIn,后台回复:SDXLTurbo模型,即可获得资源链接
# "fp16"代表启动fp16精度。比起fp32,fp16可以使模型显存占用减半。
# 使用GPU进行Pipeline的推理
pipe.to("cuda")
# 输入提示词
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
# Pipeline进行推理
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
# Pipeline生成的images包含在一个list中:[<PIL.Image.Image image mode=RGB size=1024x1024>]
#所以需要使用images[0]来获取list中的PIL图像
完成上面的整个代码流程,我们就能生成一张小浣熊的图片了。这里要注意的是,SDXL Turbo模型在diffusers库中进行文生图操作时不需要使用guidance_scale和negative_prompt参数,所以我们设置guidance_scale=0.0。

接下来,Rocky再带大家完成SDXL Turbo模型在diffusers中图生图的整个流程:
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image
pipe = AutoPipelineForImage2Image.from_pretrained("/本地路径/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
init_image = load_image("/本地路径/用于图生图的原始图片").resize((913, 512))
prompt = "Miniature model, axis shifting, reality, clarity, details, panoramic view, suburban mountain range, game suburban mountain range, master work, ultra-high quality, bird's-eye view, best picture quality, 8K, higher quality, high details, ultra-high resolution, masterpiece, full of tension, realistic scene, top-level texture, top-level light and shadow, golden ratio point composition, full of creativity, color, future city, technology, smart city, aerial three-dimensional transportation, pedestrian and vehicle separation, green building, macaron color, gorgeous, bright"
image = pipe(prompt, image=init_image, num_inference_steps=2, strength=0.5, guidance_scale=0.0).images[0]
完成上面的整个代码流程,我们就能生成一张新的城郊山脉的图片。需要注意的是,当在diffusers中使用SDXL Turbo模型进行图生图操作时,需要确保num_inference_steps*strength大于或等于1。因为前向推理的步数等于int(num_inference_steps * strength)步。比如上面的例子中,我们就使用SDXL-Turbo模型前向推理了0.5 * 2.0 = 1 步。

StabilityAI官方发布的报告中表示SDXL Turbo在推理速度上提供了重大改进。在A100上,SDXL Turbo以207ms的速度生成一张512x512的图像(prompt encoding + a single denoising step + decoding, fp16),其中U-Net部分耗时占用了67ms。
Rocky也测试了一下SDXL Turbo的图像生成效率,确实非常快,在V100上,4 steps生成512x512尺寸的图像基本可以做到实时响应(1.02秒,平均1 step仅需250ms)。
在我们输入完最后一个prompt后,新生成的图像就能马上显示,推理速度确实超过了Midjourney、DALL·E 3以及之前的Stable Difusion系列模型,可谓是“天下武功,无坚不破,唯快不破”的典范。SDXL Turbo在生成速度快的同时,生成的图像质量也非常高,可以比较精准地还原prompt的描述。
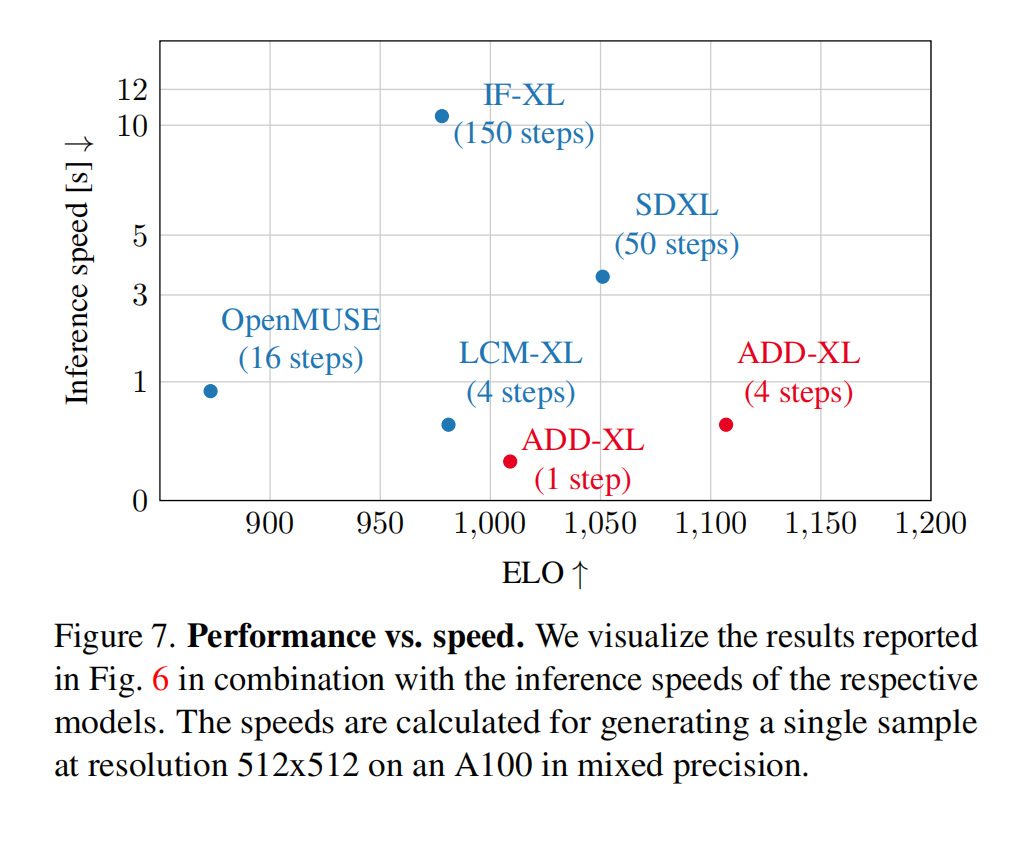
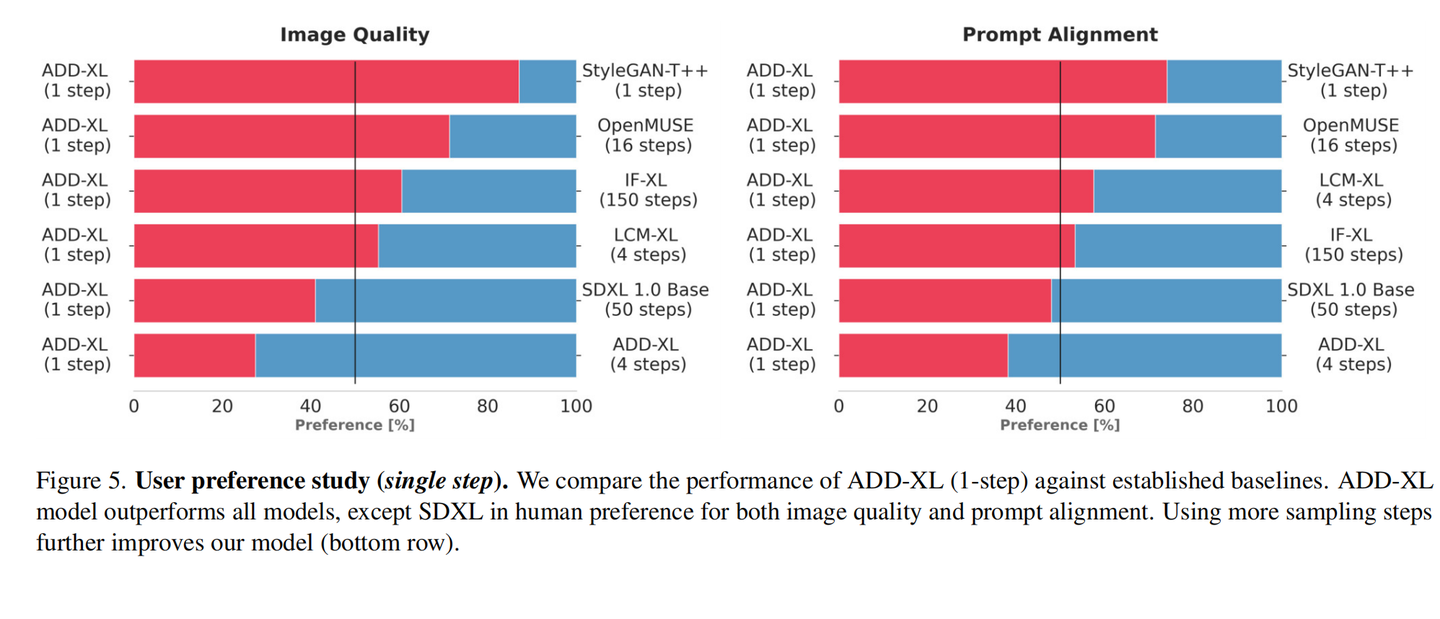
为了测试SDXL Turbo的性能,StabilityAI使用相同的文本提示,将SDXL Turbo与SDXL和LCM-XL等不同版本的文生图模型进行了比较。测试结果显示,在图像质量和Prompt对齐方面,SDXL Turbo只用1个step,就击败了LCM-XL的4个steps生成的图像,以及达到SDXL 1.0 Base通过50个steps生成的图像效果。
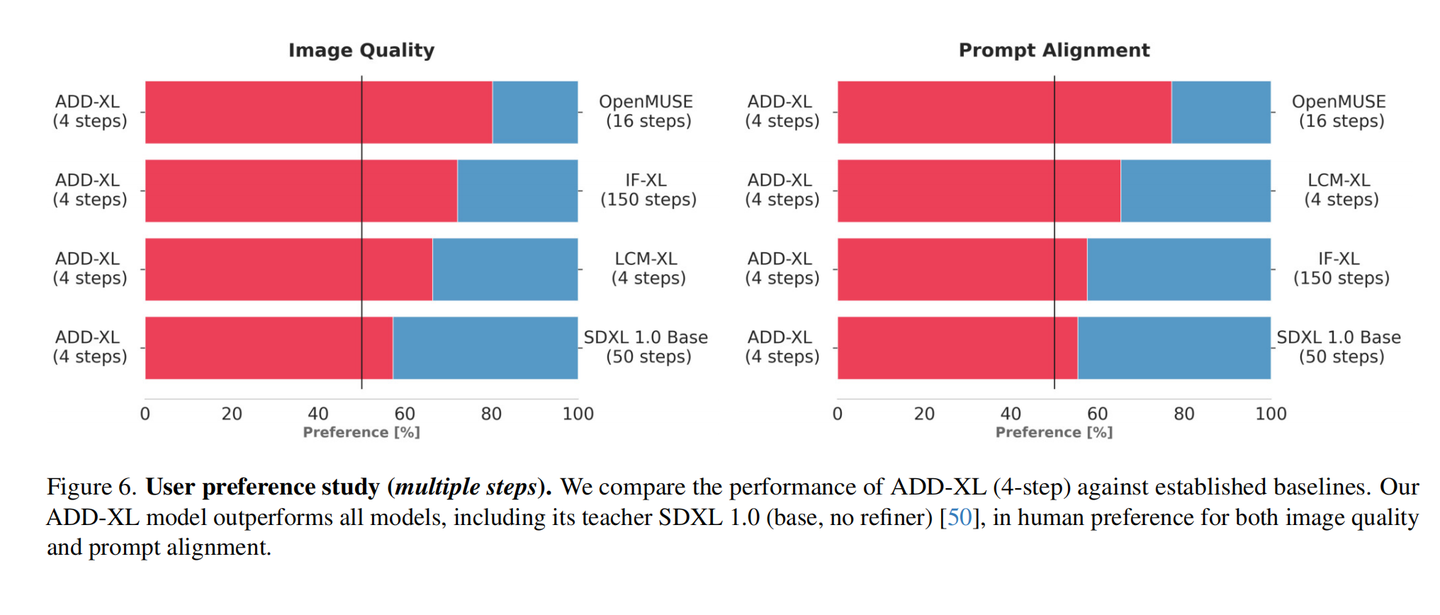
接着当我们将采样步数提高到4时,SDXL Turbo在图像质量和Prompt对齐方面都已经略微超过SDXL 1.0 Base:
论文里表示目前SDXL Turbo只能生成512x512像素的图片,Rocky推测当前开源的SDXL Turbo只在单一尺寸上进行了蒸馏训练,后续估计会有更多优化版本发布。Rocky也在512x512像素下测试了不同steps(1-8 steps)时SDXL Turbo的出图效果,对比结果如下所示:

可以看到当steps为1和4时,效果都非常好,并且4steps比1step效果更好,这是可以理解的。不过当steps大于4之后,生成的图像明显开始出现过拟合现象。总的来说,如果是急速出图的场景,可以选择1 step;如果想要更高质量,推荐选择4 steps。
同时Rocky测试了一下SDXL Turbo在不同尺寸(768x768,1024x1024,512x768,768x1024,768x512,1024x768共6中尺寸)下的图像生成质量,可以看到除了1024x1024存在一定的图片特征不完善的情况,其余也具备一定的效果,但是整体上确实不如512x512的效果好。

SDXL Turbo的一个直接应用,就是与游戏相结合,获得2fps的风格迁移后的游戏画面:
SDXL Turbo发布后,未来AI绘画和AI视频领域有了更多的想象空间。一定程度上再次整合加速了生成领域的各种工作流应用,未来的潜力非常大。不过由于SDXL Turbo模型需要通过蒸馏训练获得,并且其中包含了GAN的对抗损失训练,在开源生态中像训练特定SDXL模型一样的训练出特定SDXL Turbo模型,并且能保证出图的质量,目前来看是有一定难度的。
SD Turbo模型介绍
SD Turbo模型是在Stable Diffusion V2.1的基础上,通过蒸馏训练得到的精简版本,其本质上还是一个Stable Diffusion V2.1模型,其网络架构不变。

比起SDXL Turbo,SD Turbo模型更小、速度更快,但是生成图像的质量和Prompt对齐方面不如前者。
但是在AI视频领域,SD Turbo模型有很大的想象空间,因为Stable Video Diffusion的基础模型是Stable Diffusion V2.1,所以未来SD Turbo模型在AI视频领域很可能成为AI视频加速生产的有力工具之一。
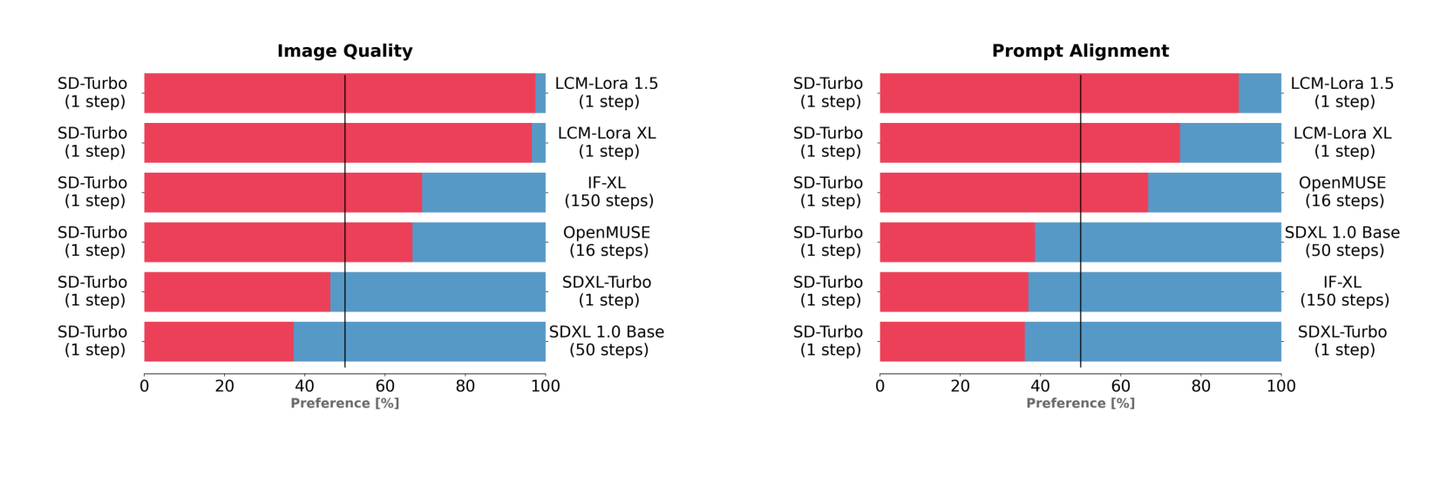
为了测试SD Turbo的性能,StabilityAI使用相同的文本提示,将SD Turbo与LCM-LoRA 1.5和LCM-LoRA XL等不同版本的文生图模型进行了比较。测试结果显示,在图像质量和Prompt对齐方面,SD Turbo只用1个step,就击败了LCM-LoRA 1.5和LCM-LoRA XL生成的图像。
diffusers库已经支持SDXL Turbo的使用运行了,可以进行文生图和图生图的任务,相关代码和操作流程如下所示:
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("/本地路径/sd-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
这里要注意的是,SD Turbo模型在diffusers库中进行文生图操作时不需要使用guidance_scale和negative_prompt参数,所以我们设置guidance_scale=0.0。
接下来,Rocky再带大家完成SD Turbo模型在diffusers中图生图的整个流程:
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image
import torch
pipe = AutoPipelineForImage2Image.from_pretrained("/本地路径/sd-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
init_image = load_image("/本地路径/test.png").resize((512, 512))
prompt = "cat wizard, gandalf, lord of the rings, detailed, fantasy, cute, adorable, Pixar, Disney, 8k"
image = pipe(prompt, image=init_image, num_inference_steps=2, strength=0.5, guidance_scale=0.0).images[0]
需要注意的是,当在diffusers中使用SD Turbo模型进行图生图操作时,需要确保num_inference_steps*strength大于或等于1。因为前向推理的步数等于int(num_inference_steps * strength)步。比如上面的例子中,我们就使用SD Turbo模型前向推理了0.5 * 2.0 = 1 步。
推荐阅读
1、加入AIGCmagic社区知识星球
AIGCmagic社区知识星球不同于市面上其他的AI知识星球,AIGCmagic社区知识星球是国内首个以AIGC全栈技术与应用为主线的学习交流平台,涉及AI绘画、AI视频、ChatGPT等大模型、数字人、全行业AIGC赋能等50+应用方向,内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AIGC模型、AIGC数据集和源码等。
那该如何加入星球呢?很简单,我们只需要扫下方的二维码即可。知识星球原价:299元/年,目前限量活动价,第一年只需要199元/年。大家只需要扫描下面的星球优惠卷即可享受最大优惠:


2、GPT-4,ChatGPT Plus稳定使用教程
一文读懂GPTs的构建与玩法(GPTs保姆级教程)|【WeThinkIn出品】
3、Stable Diffusion XL核心基础知识,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
4、Stable DiffusionV1-V2核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
5、ControlNet核心基础知识、核心网络结构、从0到1在WebUI中使用ControlNet进行AI绘画、从0到1上手构建ControlNet高级应用等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
6、最全面的AIGC面经《手把手教你如何成为AIGC算法工程师,斩获AIGC算法offer!》文章发布
码字不易,欢迎大家多多点赞:
文章地址:https://zhuanlan.zhihu.com/p/651076114
7、10万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章发布
码字不易,欢迎大家多多点赞:
文章地址:https://zhuanlan.zhihu.com/p/545374303
8、其他
除此之外Rocky还将YOLOv1-v7全系列大解析也制作成相应的pdf版本,大家可在公众号后台 【精华干货】菜单或者回复关键词“YOLO” 进行取用。
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!