【深度学习-图像分类】02 - AlexNet 论文学习与总结
论文地址:ImageNet Classification with Deep Convolutional
Neural Networks
论文学习
1. 摘要
- 本研究训练了一个大型深度卷积神经网络(CNN),用于对ImageNet LSVRC-2010比赛中的1.2百万高分辨率图像进行分类,这些图像分布在1000个不同的类别中。
- 在测试数据上,该网络实现了37.5%的top-1错误率和17.0%的top-5错误率,这显著优于之前的最佳成果。
- 神经网络包含6000万个参数和650,000个神经元,由五个卷积层组成,其中一些后接最大池化层,以及三个全连接层,最后是一个1000路softmax输出。
- 为了加快训练速度,研究者使用了非饱和神经元(ReLU)和高效的GPU实现卷积操作。
- 为了减少全连接层的过拟合,采用了一种名为“dropout”的新型正则化方法,证明非常有效。
- 研究者还在ILSVRC-2012比赛中使用了这个模型的变体,取得了15.3%的获胜top-5测试错误率,相比之下,第二名的成绩为26.2%。
2. 引言
- 论文开头指出,当前对象识别的方法主要依赖于机器学习技术。为了提高性能,可以通过收集更大的数据集、学习更强大的模型以及使用更好的过拟合防止技术来实现。(提高对象识别方法性能:1. 更大数据集 2.更强大的模型结构 3. 更好的防止过拟合的方法)
- 作者提到,尽管过去的标记图像数据集相对较小(例如,NORB、Caltech-101/256、CIFAR-10/100等),但对于简单的识别任务来说,这些数据集的规模已经足够。然而,由于现实环境中对象的多样性,识别这些对象需要更大规模的训练集。(现阶段需要更大规模的训练集)
- 论文强调了大型数据集的重要性,并提到了ImageNet数据集,它包含超过1500万个标记的高分辨率图像,覆盖了超过22000个类别。(ImageNet数据集)
- 为了从数百万图像中学习识别成千上万的对象,需要一个具有大学习能力的模型。但是,由于对象识别任务的复杂性,即使是像ImageNet这样大的数据集也无法完全指定问题,因此模型需要具有大量的先验知识来弥补数据的不足。(对象识别、图片分类任务的复杂性)
- 作者提到,卷积神经网络(CNNs)是一类具有这种能力的模型。通过调整其深度和宽度,可以控制CNN的容量。CNN对图像的性质(如统计的平稳性和像素依赖性的局部性)做出了强而正确的假设,因此相比于同等规模层的标准前馈神经网络,CNN有更少的连接和参数,更易于训练,同时理论上的最佳性能也只略有下降。(卷积神经网络CNN的优势)
3. 数据集
- ImageNet数据集的概述
- 论文中提到的ImageNet是一个大规模的图像数据库,包含超过1500万个标记的高分辨率图像,这些图像分布在大约22000个类别中。
- 数据收集与标记
- ImageNet中的图像是从互联网上收集的,并通过使用亚马逊的Mechanical Turk众包工具由人工进行标记。
- ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)
- 自2010年起,作为Pascal Visual Object Challenge的一部分,每年举办一次名为ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)的年度比赛。ILSVRC使用ImageNet的一个子集,其中大约包含1000个类别,每个类别大约有1000张图像。总计大约有120万张训练图像、5万张验证图像和15万张测试图像。
- 数据集的特点与挑战
- ImageNet数据集的特点在于其规模之大以及类别之多,提供了一个挑战性极高的平台,用于测试和改进各种视觉对象识别算法。
- ILSVRC-2010是唯一一个公开测试集标签的版本,因此成为了作者进行大部分实验的数据集。论文中也提到了在ILSVRC-2012版本上的实验结果。
- 数据集的处理
- 由于ImageNet包含的是变分分辨率的图像,而神经网络需要固定输入维度,因此研究者将图像下采样到固定的256x256分辨率。对于矩形图像,首先将较短的一边缩放到256像素,然后从缩放后的图像中裁剪出中心的256x256区域。除了从每个像素中减去训练集上的平均活动外,没有进行其他预处理。
4. 架构
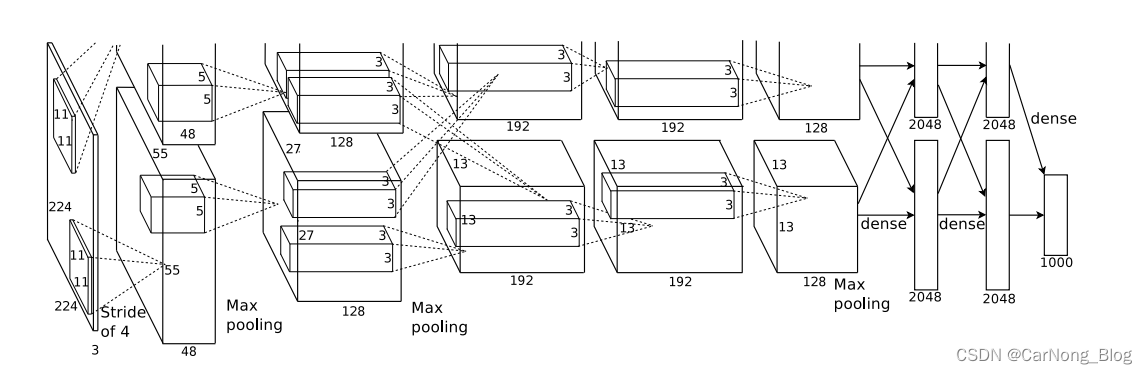
- 网络架构概述
- 论文中描述的卷积神经网络包含8个带权重的层:前5层是卷积层,后3层是全连接层。网络的最后输出是一个1000路的softmax,用于生成1000个类别标签的分布。
- 卷积层的设计
- 网络的第一层使用96个大小为11x11x3的卷积核,步长为4个像素。
第二层包含256个5x5x48的卷积核。 - 第三、四、五层的卷积核数量分别为384、384和256,核大小均为3x3,且这些层之间没有池化或归一化层。
- 网络的第一层使用96个大小为11x11x3的卷积核,步长为4个像素。
- 全连接层的设计
- 网络的三个全连接层每层都有4096个神经元。
- 特殊的网络特性
- 论文中提到了一些网络的新颖或不寻常的特性,这些特性有助于提高性能和减少训练时间。例如,使用了ReLU(修正线性单元)作为激活函数,实现了局部响应归一化,采用了重叠的池化等。
- ReLU(修正线性单元)作为激活函数
定义与优势:ReLU是一种非线性激活函数,定义为f(x) = max(0, x)。它的主要优势在于解决了梯度消失问题,这在深层网络中尤为重要。由于ReLU在正区间的梯度恒定,它允许更快的训练和更深的网络结构。
实现效率:ReLU的计算效率高于传统的Sigmoid和Tanh激活函数,因为它只涉及简单的阈值操作。- 局部响应归一化
作用:局部响应归一化(Local Response Normalization, LRN)是一种在卷积神经网络中常用的正则化技术。它模仿生物神经系统中的“侧抑制”机制,通过对局部输入区域进行归一化,增强了模型的泛化能力。
实现方式:在实践中,LRN沿着通道维度对每个像素位置的活动进行归一化,使得响应较大的神经元抑制其邻近神经元,从而增强了模型对高频特征的敏感性。- 重叠的池化
池化概念:池化层在卷积神经网络中用于降低特征维度和提取重要特征。传统的池化操作(如最大池化)通常在不重叠的区域上进行。
重叠池化:重叠池化意味着池化窗口的步长小于其大小,导致池化窗口之间存在重叠。例如,可以使用大小为3x3的池化窗口和步长2来进行操作。
优势:重叠池化有助于减少网络对特定池化窗口位置的敏感性,从而提高了特征的平移不变性。此外,它还可以在一定程度上减少过拟合。
- GPU并行化
- 为了处理大型网络和大量数据,研究者将网络分布在两个GPU上进行训练。这种并行化策略不仅加快了训练过程,还通过在某些层中限制GPU间的通信来减少了计算负担。
- 防止过拟合的策略
- 为了防止过拟合,网络在全连接层中使用了Dropout技术。
- Dropout 定义与原理:
定义:Dropout是一种在训练深度神经网络时使用的正则化技术。它通过在训练过程中随机“丢弃”(即暂时移除)网络中的一部分神经元来工作。
实现方式:在每次训练迭代中,每个神经元有一定概率(例如50%)被随机选择并临时从网络中移除,即其在这次前向和反向传播中不会被激活。这种随机性意味着网络不能依赖于任何一组特定的神经元激活模式。- Dropout的优势:
减少过拟合:Dropout减少了神经元之间复杂的共适应关系。由于网络的每个神经元不能依赖于其他神经元的激活,它们被迫学习更加健壮的特征,这有助于提高网络的泛化能力。
模型平均:Dropout可以被看作是一种廉价的集成学习。每次训练迭代中使用的是原始网络的一个“子网络”,在测试时,使用整个网络可以近似为所有子网络的平均。
在论文中的应用- 应用层级:在论文中,dropout被应用于全连接层。这是因为全连接层通常包含大量的参数,更容易发生过拟合。
效果:使用dropout后,网络需要更多的训练迭代来收敛,但最终可以达到更好的泛化性能。- 测试时的处理:
测试时的调整:在测试时,所有的神经元都被保留,但其输出需要乘以训练时dropout的保留概率(例如50%),以补偿训练时神经元被随机丢弃的影响。
5. 减少过拟合
- 过拟合的挑战:
- 论文中指出,由于神经网络架构拥有大量的参数(约6000万个),即使在拥有大约120万个训练样本的ImageNet数据集上,也面临着严重的过拟合问题。
- 数据增强:
- 图像翻译和水平翻转:作为减少过拟合的一种方法,论文中采用了图像翻译和水平翻转的数据增强技术。通过从256x256像素的图像中随机裁剪出224x224像素的区域,并进行水平翻转,从而人为地扩大了训练集。
- 改变RGB通道强度:另一种数据增强方法是改变训练图像中RGB通道的强度。这是通过在ImageNet训练集上对RGB像素值进行主成分分析(PCA),然后对每个训练图像的每个RGB像素值添加多个主成分,其中每个成分乘以一个随机变量。
- Dropout技术:
- 定义与应用:Dropout是一种正则化技术,它在训练过程中随机地“丢弃”网络中的一部分神经元。在这篇论文中,dropout被应用于全连接层。
- 效果:使用dropout可以显著减少过拟合,尽管它会使得网络需要更多的训练迭代来收敛。
- 效果评估:
- 论文中提到,这些技术显著减少了过拟合,使得网络能够在大规模的ImageNet数据集上实现更好的泛化性能。
主要通过 数据增强 + Dropout 来减少过拟合。
6. 学习细节
- 训练方法:
- 论文中使用的是随机梯度下降(Stochastic Gradient Descent, SGD)方法来训练深度卷积神经网络。
- 使用了动量(momentum)为0.9,这有助于加速训练过程并减少训练过程中的振荡。
- 权重衰减和正则化:
- 为了进一步减少过拟合,论文中采用了权重衰减(weight decay),即L2正则化,其系数设置为0.0005。
- 权重衰减不仅作为正则化使用,还有助于改善模型的训练误差。
- 权重和偏置的初始化:
- 网络中每层的权重初始化为均值为0,标准差为0.01的高斯分布。
- 第二、四和第五卷积层以及全连接隐藏层的偏置初始化为1,这有助于ReLU单元更早地开始学习。
- 其他层的偏置初始化为0。
- 学习率的调整:
- 论文中使用了相同的学习率对所有层进行训练,并在验证错误率不再改善时手动调整学习率。
- 初始学习率设置为0.01,并在训练过程中逐步减小。
- 训练时间和硬件:
- 训练网络大约需要90个周期(epoch)通过整个ImageNet训练集(大约120万图像),在两个NVIDIA GTX 580 3GB GPU上训练大约需要五到六天。
- 批处理大小:
- 训练时使用的批处理大小为128个样本。
7. 结果
- ILSVRC-2010结果
- 论文中的网络在ILSVRC-2010测试集上取得了37.5%的top-1错误率和17.0%的top-5错误率,这显著优于之前的最佳成绩。此前的最佳成绩是使用六个稀疏编码模型的平均预测结果,top-1错误率为47.1%,top-5错误率为28.2%。
- ILSVRC-2012结果
- 论文还报告了在ILSVRC-2012比赛中的结果。由于ILSVRC-2012的测试集标签不公开,因此主要报告了验证集上的错误率。
- 在ILSVRC-2012上,单个CNN模型的top-5验证错误率为18.2%。通过平均五个类似CNN模型的预测,错误率降至16.4%。
- 训练一个额外的CNN模型,该模型首先在整个ImageNet 2011 Fall release(大约1500万图像,22000类别)上进行预训练,然后在ILSVRC-2012上进行微调,其top-5验证错误率为16.6%。
- 将上述模型与另外五个CNN模型的预测结果平均,最终达到了15.3%的top-5测试错误率,而第二名的成绩为26.2%。
- ImageNet 2009 Fall release结果
- 论文还在ImageNet 2009 Fall release数据集上测试了模型,该数据集包含10184个类别和890万图像。
- 在这个数据集上,使用增加了一个额外卷积层的网络模型,top-1和top-5错误率分别为67.4%和40.9%,这也优于之前的最佳成绩。
- 结果的意义
- 这些结果展示了深度卷积神经网络在大规模图像分类任务上的强大性能,特别是在处理非常大的数据集和类别数量时。
- 论文中的模型不仅在单个测试集上表现出色,而且在多个版本的ImageNet数据集上都显示了其优越的性能和泛化能力。
8. 定性评估
- 卷积层特征的可视化
- 论文中展示了第一卷积层学习到的96个卷积核(滤波器)。这些可视化的卷积核揭示了网络如何响应不同类型的图像特征,例如边缘、颜色和纹理等。
- 通过观察这些卷积核,可以看出网络在两个GPU上的学习是有所不同的,其中一个GPU倾向于学习颜色无关的特征,而另一个GPU倾向于学习颜色相关的特征。
- 高层特征的图像检索
- 论文还探讨了使用最后一个隐藏层(4096维特征向量)进行图像检索的效果。通过计算测试图像和训练集图像在该特征空间中的欧几里得距离,可以找到与测试图像最相似的训练图像。
- 这种方法展示了网络高层次如何捕捉图像内容的抽象和语义信息,即使这些图像在像素级别上可能看起来截然不同。
- 错误分析
- 论文中还包括了对网络错误分类的分析。例如,展示了一些网络错误分类的图像以及网络认为可能的前五个类别。
- 这种分析有助于理解网络在哪些类型的图像上表现良好,以及它在哪些方面还有改进的空间。
- 网络对图像的理解
- 通过这些定性评估,论文展示了网络不仅能够识别出图像中的主要对象,而且能够捕捉到更复杂的视觉模式和对象之间的关系。
- 这些评估结果表明,深度卷积神经网络能够学习到丰富的图像表示,这些表示在很大程度上与人类的视觉感知相似。
9. 讨论
- 模型性能的突破
- 论文总结指出,通过使用大型深度卷积神经网络,研究团队在ImageNet数据集上取得了前所未有的分类性能。这一成果标志着深度学习在图像分类任务中的重大突破。
- 网络深度的重要性
- 论文强调了网络深度对于实现高性能的重要性。实验表明,移除任何一个卷积层都会导致性能显著下降,证明了深层结构在处理复杂视觉任务中的关键作用。
- 未来的发展方向
- 论文提出,尽管已经取得了显著的进展,但与人类视觉系统相比,还有很大的发展空间。作者期望未来能够训练更大、更深的网络,并利用未标记的数据来进一步提升性能。
作者还提到了将这种深度网络应用于视频数据和其他领域的可能性,以及利用时间信息来提高模型性能的潜力。
- 论文提出,尽管已经取得了显著的进展,但与人类视觉系统相比,还有很大的发展空间。作者期望未来能够训练更大、更深的网络,并利用未标记的数据来进一步提升性能。
- 对深度学习领域的影响
- 论文总结了该研究对深度学习领域的影响,特别是在计算机视觉任务中的应用。这项工作不仅推动了深度神经网络在学术界的研究,也促进了它们在工业界的广泛应用。
- 开放问题和挑战
- 最后,论文提出了一些仍待解决的开放性问题和挑战,如如何有效地训练更大规模的网络,以及如何更好地理解和解释深度网络的内部工作机制。
这篇论文《ImageNet Classification with Deep Convolutional Neural Networks》的主要创新点以及找重要贡献如下:
- 大规模深度卷积神经网络的成功应用
- 论文中成功训练了一个非常大型的深度卷积神经网络(CNN),这在当时是前所未有的。这个网络有60百万个参数和650,000个神经元,包含五个卷积层和三个全连接层。
- 在ImageNet数据集上取得突破性成果
- 论文的模型在ImageNet LSVRC-2010和LSVRC-2012数据集上取得了当时最好的结果,显著降低了图像分类任务的错误率。
- ReLU(修正线性单元)的有效应用
- 论文中采用ReLU作为激活函数,这是在大型神经网络中的首次应用。ReLU帮助解决了梯度消失问题,使得网络能够更快地训练。
- Dropout技术减少过拟合
- 论文中使用了Dropout技术来有效地减少过拟合,这对于训练如此大规模的网络尤为重要。
- 数据增强方法
- 论文采用了多种数据增强技术,如图像翻译、水平翻转和改变RGB通道强度,这些方法显著提高了网络的泛化能力。
- GPU的高效利用
- 论文中的网络利用了多个GPU进行并行训练,这在当时是对GPU计算能力的一种创新利用,为训练大型深度学习模型提供了一个可行的途径。
- 网络架构的创新设计
- 包括局部响应归一化和重叠池化等网络架构上的创新设计,这些设计有助于提高网络的性能和训练效率。
AlexNet
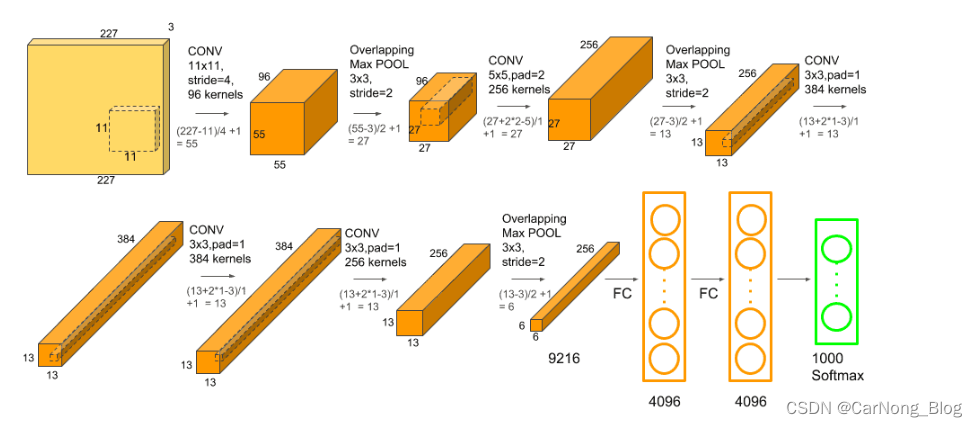
这幅流程图详细描述了AlexNet卷积神经网络(CNN)的架构,这是一种特别为图像识别任务设计的网络。从左侧的输入层到右侧的输出层,下面是该过程的详细分解:
-
输入:输入层接收一个227x227像素的图像,具有3个颜色通道(通常是RGB)。
-
第一卷积层(CONV):这一层使用96个11x11大小的卷积核(或滤波器),步长为4,这意味着滤波器在输入图像上滑动时每次移动4个像素。这一层将图像的空间尺寸降低到55x55。
-
第一个最大池化层(Max POOL):这一层使用3x3的池化窗口和2的步长进行操作,进一步降低空间尺寸到27x27。
-
第二卷积层:接着是一个256核的5x5卷积,步长为1,并且填充(padding)设置为2,以保持尺寸为27x27。
-
第二个最大池化层:再次应用3x3大小和2步长的最大池化操作,减少尺寸到13x13。
-
第三、四、五卷积层:接下来是三个卷积层,它们都使用384个3x3大小的卷积核,步长为1,最后一个卷积层后面没有池化层。
-
第三个最大池化层:然后是最后一个3x3大小、步长为2的最大池化层,将尺寸降低到6x6。
-
全连接层(FC):卷积后的特征图被展平并通过两个全连接层,每个层有4096个神经元。
-
输出层(Softmax):最终通过一个有1000个单元的全连接层,每个单元对应一个分类标签。输出层使用softmax激活函数,将网络的原始输出转换为分类概率。
整个网络通过这种结构来提取输入图像中的特征,并进行分类。这种架构中包含了一些重要的深度学习概念,如ReLU激活函数、最大池化、丢弃(dropout)和数据增强等,这些都有助于网络在图像分类任务中取得良好的性能。
代码实现:
import torch
import torchvision.models
from torch import nn
from torch.hub import load_state_dict_from_url
class AlexNet(nn.Module):
def __init__(
self,
num_classes=1000, // 分类数
dropout=0.5 // dropout率
):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = nn.Flatten(x)
x = self.classifier(x)
return x
def alexnet(num_classes=1000, pretrained=True):
model = AlexNet()
if pretrained:
state_dict = load_state_dict_from_url(
url="https://download.pytorch.org/models/alexnet-owt-7be5be79.pth",
model_dir="./pretrained_model",
progress=True
)
model.load_state_dict(state_dict=state_dict, strict=False)
if num_classes != 1000:
model.classifier[-1] = nn.Linear(in_features=4096, out_features=num_classes)
return model
以上内容旨在记录自己的学习过程以及复习,如有错误,欢迎批评指正,谢谢阅读。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!