图片速览(数据集相关) DrugOOD:分布外 (OOD) 数据集管理器和人工智能辅助药物发现的基准
????????传统的药物发现过程非常耗时且昂贵。人工智能辅助药物发现在制药领域的应用正在不断扩展,其中,虚拟筛选是最重要但最具挑战性的应用之一。虚拟筛选的目的是在存在大量候选化合物的情况下,精确定位对给定靶蛋白具有高结合亲和力的一小部分化合物。解决虚拟筛选问题的关键任务是开发计算方法来预测给定药物-靶标对的结合亲和力,这是本文研究的主要任务。
????????在人工智能辅助药物发现领域,训练分布与测试分布不同的分布偏移问题无处不在。人工智能辅助药物发现领域的另一个重要问题是标签噪声,AI模型通常是在公共数据集(例如ChEMBL)上训练的,而数据集中的生物测定数据通常是嘈杂的。
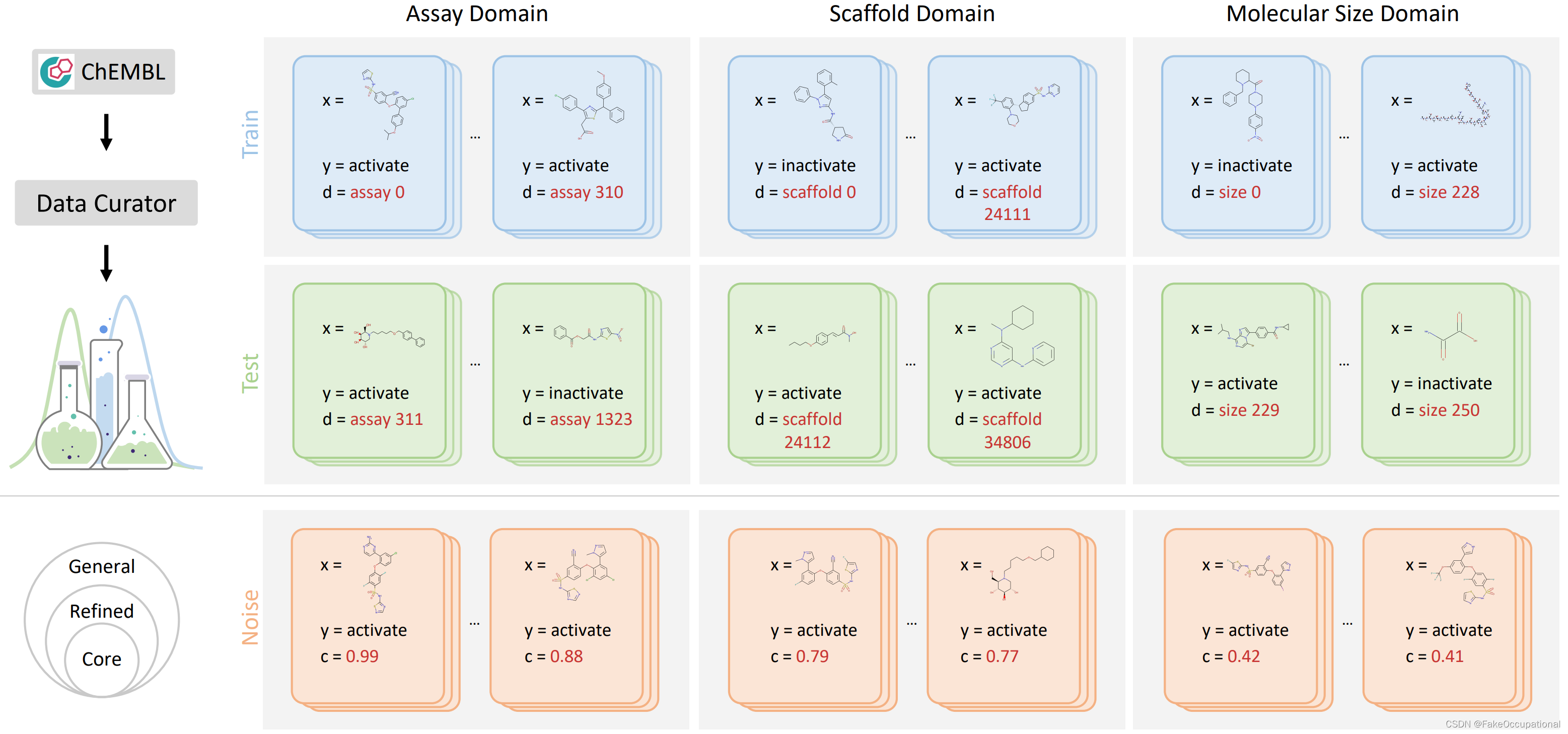
????????左上:基于 ChEMBL 数据库,我们提出了一个自动化数据集管理器,用于灵活地自定义 OOD 数据集。右上:DrugOOD 发布了跨越不同领域转移的已实现示例数据集。在每个数据集中,每个数据样本 (x, y, d) 都与一个域注释 d 相关联。我们使用背景颜色蓝色和绿色来表示看得见的数据和看不见的测试数据。
????????下图:DrugOOD 数据集中具有不同噪声水平的示例。 DrugOOD 根据几个标准识别和注释三个噪声级别(从左到右:核心、精炼、通用),随着级别的增加,数据量增加,涉及更多噪声源。
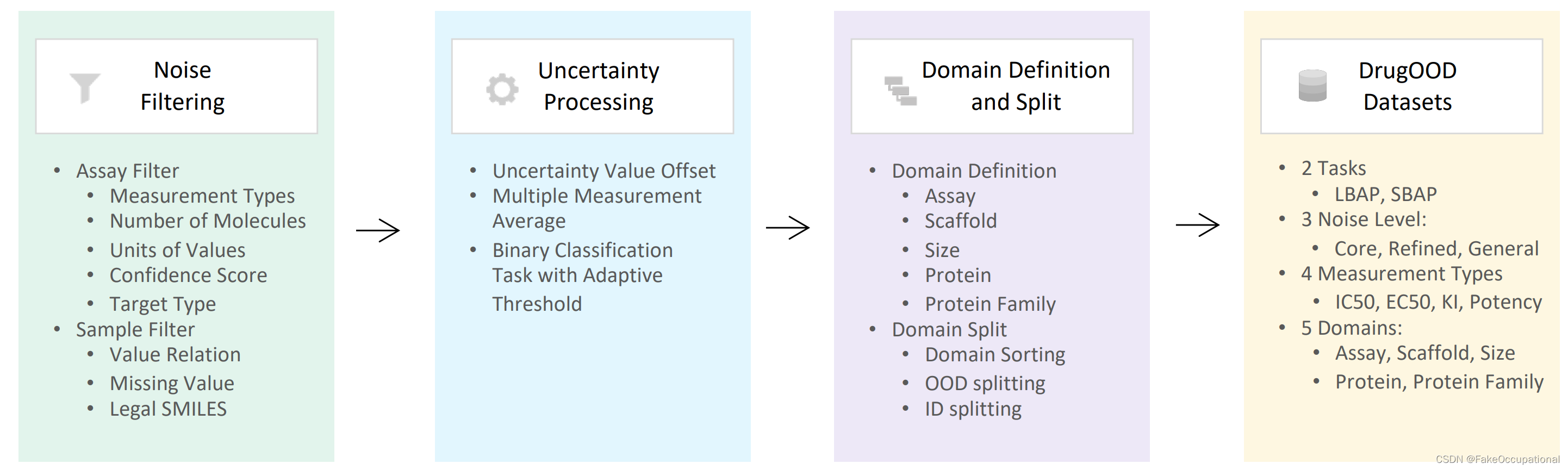
????????自动化数据集管理器概述。我们主要基于ChEMBL数据源实现三个主要步骤:噪声滤波、不确定性处理和域分裂。我们内置了 96 个配置文件,用于生成已实现的数据集,其中包含两个任务、三个噪声水平、四种测量类型和五个域的配置。
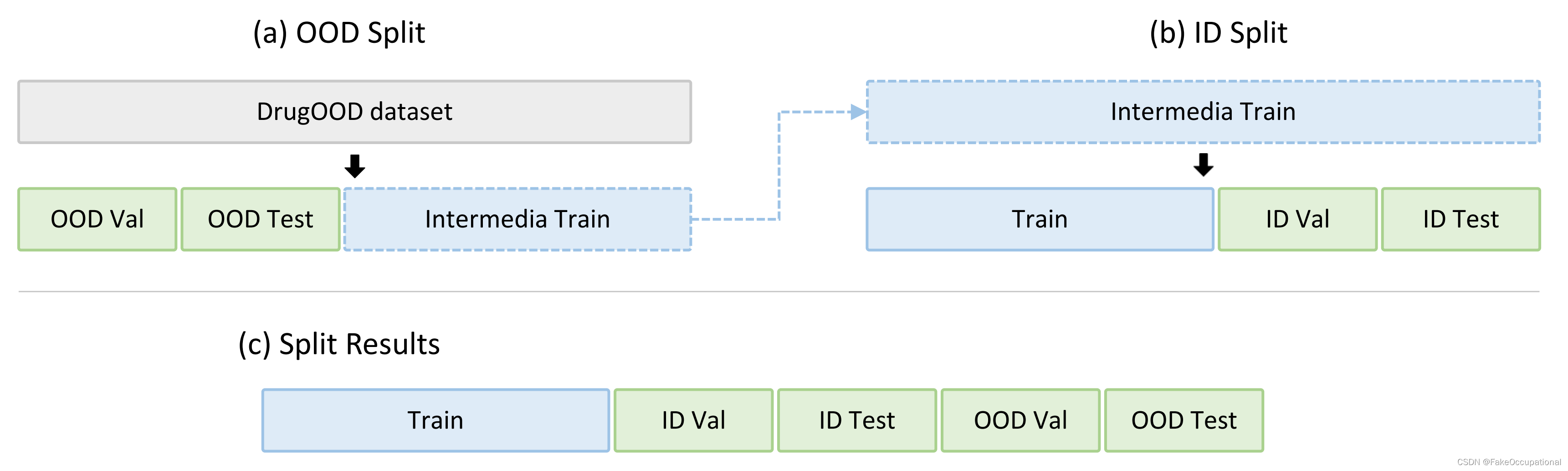
????????OOD 验证和测试 我们的域拆分过程图示: (a) OOD 拆分:根据排序后的数据,我们依次将它们拆分为中间训练集、OOD 验证和测试集。我们尝试将训练、验证和测试样本的比例保持在 6:2:2 左右。(b) ID 拆分:从中间训练集开始,我们进一步分离最终训练集、ID 验证集和 ID 测试集。(c) 执行上述步骤后,我们得到训练、ID 验证、ID 测试、OOD 验证和 OOD 测试集。
CG
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!